我有一個熊貓一個包含兩列的資料框。1) 關鍵字 2) TopicID。
關鍵字是字典型別。我想以每個主題將針對每個關鍵字及其值重復的方式來規范化這個資料框。
我的資料框

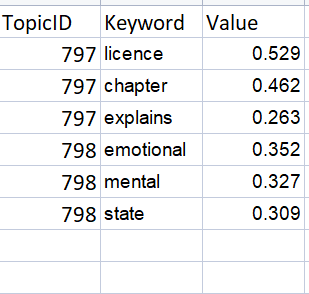
預期的資料框(對于示例,我只發布了幾個關鍵字)
我試過這段代碼
df_final = pd.json_normalize(df.keywords.apply(json.loads))
輸出 -> 列印 (df[['TopicID','keywords']].head(2).to_dict())
{'TopicID': {0: 797, 1: 798}, 'keywords': {0: {'licence': 0.529, 'chapter': 0.462, 'explains': 0.263, 'visitor': 0.244, 'resident': 0.22, 'applying': 0.205, 'privileges': 0.199, 'graduated': 0.188, 'tests': 0.184, 'licensing': 0.18}, 1: {'emotional': 0.352, 'mental': 0.327, 'state': 0.309, 'operate': 0.295, 'drive': 0.242, 'motor': 0.227, 'ability': 0.227, 'next': 0.176, 'illness': 0.176, 'diminish': 0.176}}}
uj5u.com熱心網友回復:
首先通過在串列理解中展平字典來創建元組串列,然后傳遞給DataFrame建構式:
L = [(a, k, v) for a, b in zip(df['TopicID'], df['keywords']) for k, v in b.items()]
df_final = pd.DataFrame(L, columns=['TopicID','Keyword','Value'])
print (df_final)
TopicID Keyword Value
0 797 licence 0.529
1 797 chapter 0.462
2 797 explains 0.263
3 797 visitor 0.244
4 797 resident 0.220
5 797 applying 0.205
6 797 privileges 0.199
7 797 graduated 0.188
8 797 tests 0.184
9 797 licensing 0.180
10 798 emotional 0.352
11 798 mental 0.327
12 798 state 0.309
13 798 operate 0.295
14 798 drive 0.242
15 798 motor 0.227
16 798 ability 0.227
17 798 next 0.176
18 798 illness 0.176
19 798 diminish 0.176
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/496102.html
標籤:python-3.x 熊猫 数据框
上一篇:在陣列中查找單詞并在Pandas的Dataframe中獲取它們的索引
下一篇:資料框存盤重復的標頭