作業中遇到一個需求,規范人為輸入的特定詞匯,大概有100多個詞匯,類似下面的情況(關鍵詞比地名復雜一些)
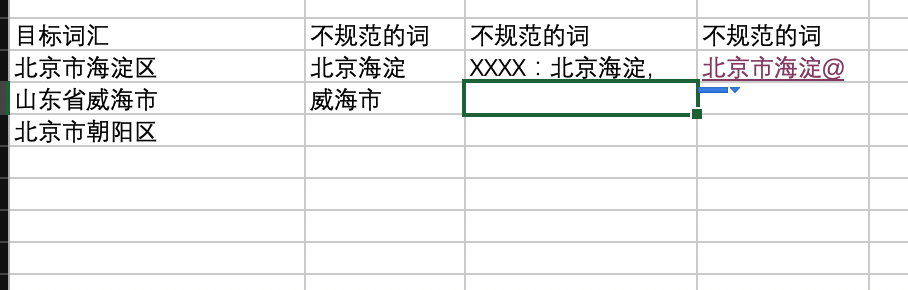
之前是用if else處理的,偽代碼如下:
string TempStr;
if(TempStr.Contains("海淀") && TempStr.Contains("北京") )
{
return "北京市海淀區";
}
else if(TempStr.Contains("山東") && TempStr.Contains("威海") )
{
return "山東省威海市";
}
……//等等一共兩百多個else,內容也比較復雜,甚至還有正則匹配之類的
else
{
return "匹配失敗";
}
因為我的作業是寫Excel插件的,這一百多個 else if 太影響運行效率了,而且維護起來也很不方便,增加詞匯也困難,
這兩天找了一些相關的知識,打算對這部分進行優化,用nlp中的tf-idf方法進行關鍵詞相似度的計算,
整個流程大致是:在資料庫中建立關鍵詞映射表,在插件啟動時讀取為字典,在使用時如果查詢不到,就計算相似度并上傳到映射表,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/52812.html
標籤:C#
下一篇:多執行緒之旅(Task 任務)