上一篇文章用python實作了計算文本相似度計算的程序,這次用C#做個demo,
不得不說用python是真的方便,不懂計算程序也能實作結果,C#也有類似NumPy的庫:NumSharp,經過測驗還是有區別的,有些功能沒有(也可能是因為我沒看檔案),最后還是自己研究計算程序去寫,
用C#寫Excel公式有兩種開發方式:VSTO和ExcelDNA,看了一下VSTO的部署感覺比較麻煩,所以這里用ExcelDNA的方式,
求兩個詞向量的余弦相似度的C#代碼如下
/// <summary>
/// 求余弦相似度,輸入兩個只有1行且列數相同的二維陣列
/// </summary>
/// <param name="Vector_a">向量a</param>
/// <param name="Vector_b">向量b</param>
/// <returns>回傳兩個向量的余弦相似度</returns>
public static double cos_sim(int[,] Vector_a, int[,] Vector_b)
{
double num = 0;
//計算向量a和 向量b轉置 的乘積
//python中的:float(vector_a * vector_b.T)
for(int i = 0; i < Vector_a.GetLength(1); i++)
{
num += Vector_a[0, i] * Vector_b[0, i];
}
double denom = norm(Vector_a) * norm(Vector_b);
double sim = num / denom;
return sim;
}
/// <summary>
/// 求向量范數,輸入一個只有1行的二維陣列
/// </summary>
/// <param name="Vector">輸入的向量</param>
/// <returns>回傳向量的范數</returns>
//類似NumPy中的np.linalg.norm
public static double norm(int[,] Vector)
{
double SumI = 0;
foreach(int i in Vector)
{
SumI += i * i;
}
return Math.Sqrt(SumI);
}
這個只是初步實作了余弦相似度計算,還有優化的空間,比如這里輸入的向量是一行的二維陣列,改成用一維陣列或者list都可以,型別也可以不用int改成double,
輸入的部分先用Excel選區輸入,后面會改到資料庫中,實作效果如下:
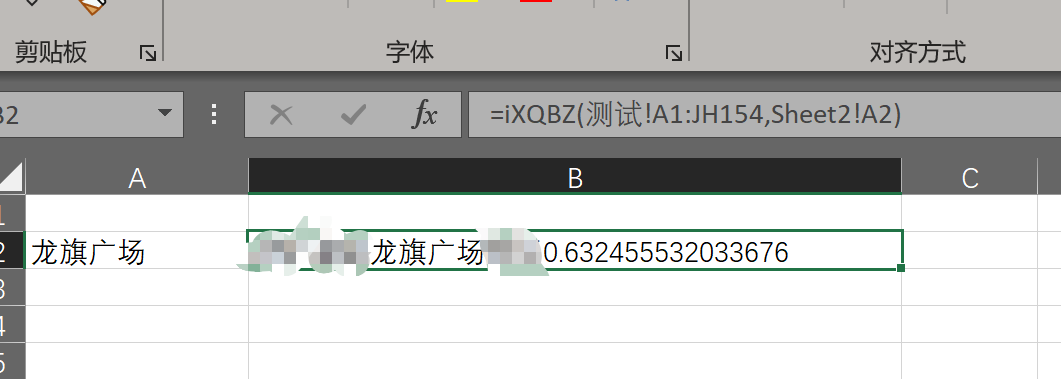
回傳的字串后面跟的數字是兩個詞的相似度,后續刪掉即可,
前面的單元格區域“測驗!A1:JH154”是目標關鍵詞和向量,之后會把這部分去掉,整理一下存盤到資料庫中,按照目前的one-hot編碼,后續增加關鍵詞時直接給每個關鍵詞后加一個值是0的維度即可,如果改成tf-idf編碼,就需要在增加關鍵詞后重新計算向量了,不過怎么說也比維護100多個elseif要方便,后續優化還可以把拆分字換成分詞,減少計算量,提高準確度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/52827.html
標籤:C#