想知道如何通過減少獼猴桃的數量來對 y 軸上的簇進行排序?
df = data.frame()
df = data.frame(matrix(df, nrow=200, ncol=2))
colnames(df) <- c("cluster", "name")
df$cluster <- sample(20, size = nrow(df), replace = TRUE)
df$fruit <- sample(c("banana", "apple", "orange", "kiwi", "plum"), size = nrow(df), replace = TRUE)
p = ggplot(df, aes(x = as.factor(cluster), fill = as.factor(fruit)))
geom_bar(stat = 'count')
theme_classic()
coord_flip()
theme(axis.text.y = element_text(size = 20),
axis.title.x = element_text(size = 20),
axis.title.y = element_text(size = 20),
axis.text=element_text(size=20))
theme(legend.text = element_text(size = 20))
xlab("Cluster")
ylab("Fruit count")
labs( fill = "")
p
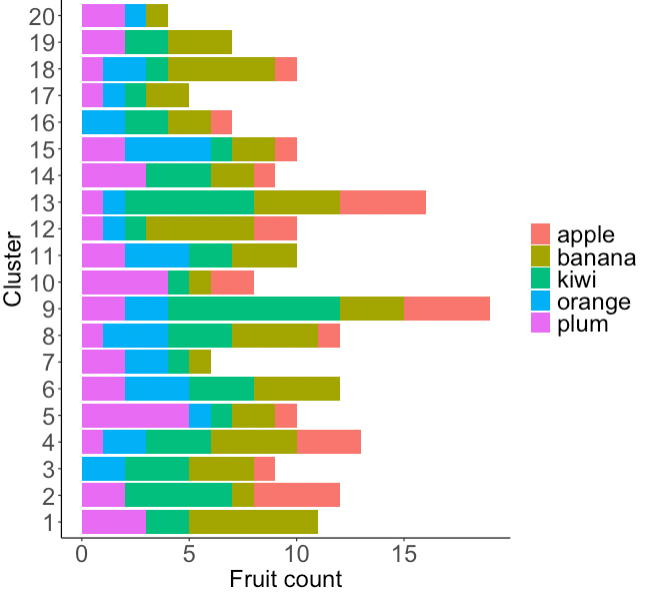
uj5u.com熱心網友回復:
我可能會在繪圖之前將其作為資料操作來執行。請注意,我已將 kiwi 移動到堆疊順序的第一個位置,因此我們可以看到隨著我們沿 y 軸向下移動,條形變小。
library(tidyverse)
df %>%
mutate(cluster = factor(cluster,
names(sort(table(fruit == 'kiwi', cluster)[2,]))),
fruit = factor(fruit, c('kiwi', 'apple', 'banana',
'orange', 'plum'))) %>%
ggplot(aes(x = cluster, fill = fruit))
geom_bar(position = position_stack(reverse = TRUE))
theme_classic()
coord_flip()
theme(axis.text.y = element_text(size = 20),
axis.title.x = element_text(size = 20),
axis.title.y = element_text(size = 20),
axis.text=element_text(size=20))
theme(legend.text = element_text(size = 20))
scale_fill_manual(values = c('olivedrab', 'yellowgreen', 'yellow2',
'orange2', 'plum4'))
xlab("Cluster")
ylab("Fruit count")
labs( fill = "")

uj5u.com熱心網友回復:
無需修改資料,只需使用x = reorder(cluster, fruit=='kiwi', sum)in aes()(而不是as.factor(cluster))。
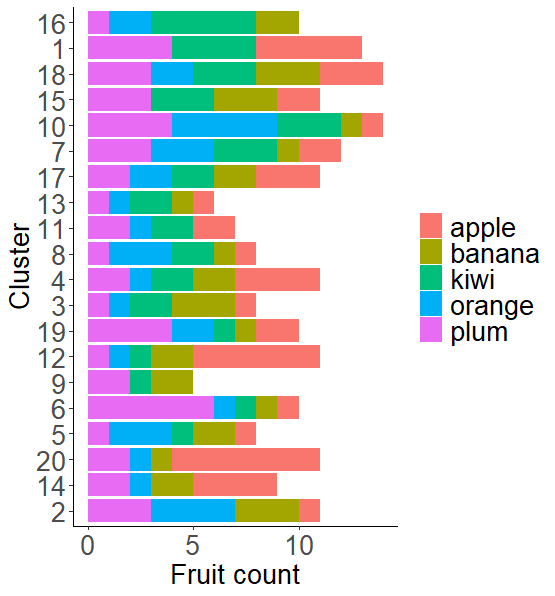
ggplot(df, aes(x = reorder(cluster, fruit=='kiwi', sum),
fill = as.factor(fruit)))
geom_bar(stat = 'count')
theme_classic()
coord_flip()
theme(axis.text.y = element_text(size = 20),
axis.title.x = element_text(size = 20),
axis.title.y = element_text(size = 20),
axis.text=element_text(size=20))
theme(legend.text = element_text(size = 20))
xlab('Cluster')
ylab('Fruit count')
labs(fill = '')
uj5u.com熱心網友回復:
也許會有一種更有效的方法來做到這一點,但一種可能性是計算每個集群出現 kiwi 的次數,然后按此排列集群變數。請注意,在此示例中,獼猴桃的數量可能有 NA(因此我們將這些實體設定為 0)。
order <- df %>%
# count how many times kiwi occurs per cluster
count(fruit, cluster) %>% filter(fruit == 'kiwi')
df <- df %>%
# join the counts to the original df by cluster
left_join(order %>% select(cluster, n)) %>%
# if na make zero (otherwise NAs appear at the top of the plot)
mutate(n = ifelse(is.na(n), 0, n),
# arrange the clusters by n
cluster = fct_reorder(as.factor(cluster), n))
然后你的繪圖函式應該給出所需的輸出。
uj5u.com熱心網友回復:
按組計算奇異果總數,然后將聚類轉換為按此分組奇異果總數排序的因子。使用 dplyr 和forcats::fct_reorder():
set.seed(13)
library(dplyr)
library(forcats)
df <- df %>%
group_by(cluster) %>%
mutate(n_kiwi = sum(fruit == "kiwi")) %>%
ungroup() %>%
mutate(cluster = fct_reorder(factor(cluster), n_kiwi))
p = ggplot(df, aes(x = cluster, fill = fruit))
geom_bar(stat = 'count')
theme_classic()
coord_flip()
theme(axis.text.y = element_text(size = 20),
axis.title.x = element_text(size = 20),
axis.title.y = element_text(size = 20),
axis.text=element_text(size=20))
theme(legend.text = element_text(size = 20))
xlab("Cluster")
ylab("Fruit count")
labs( fill = "")
p
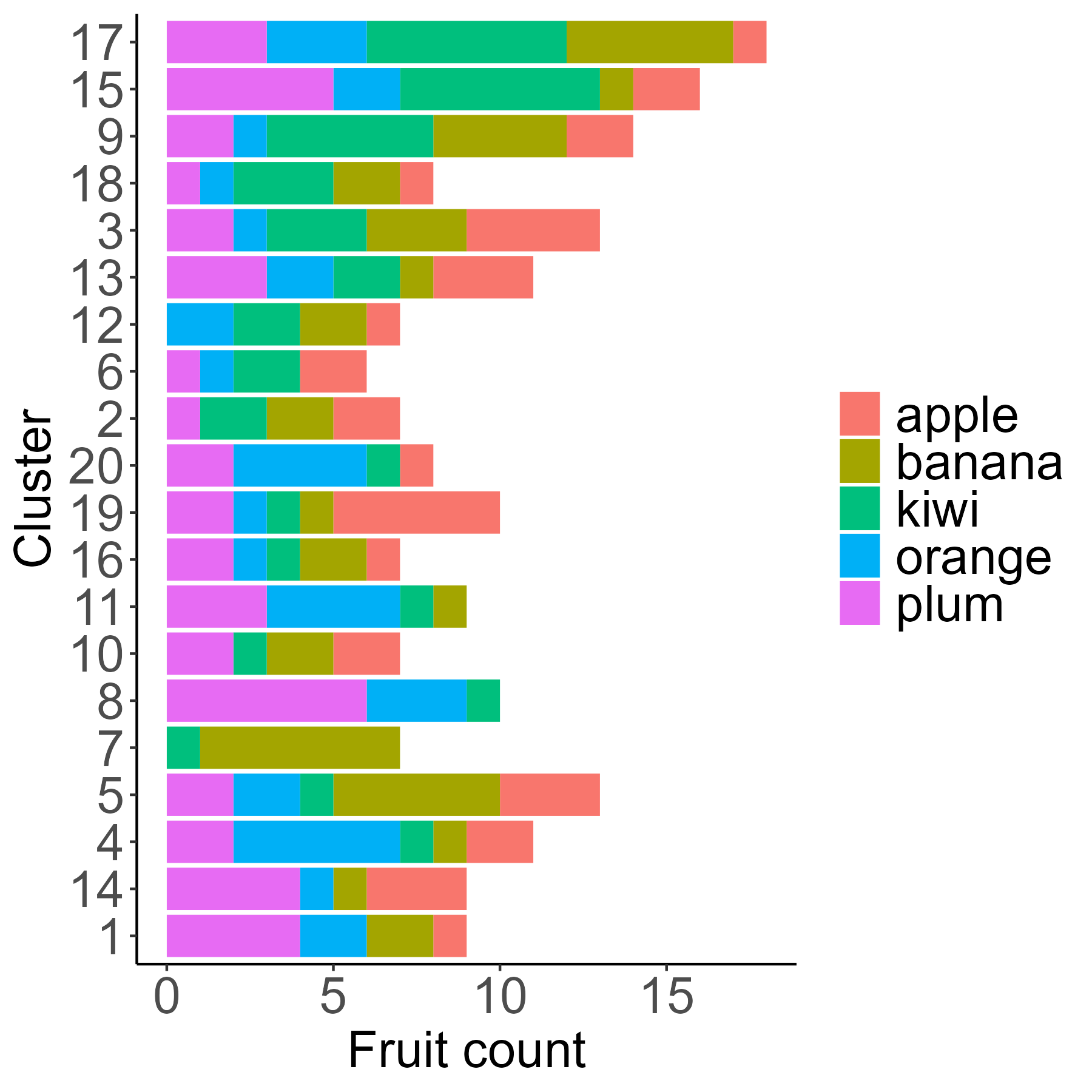
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/534931.html
標籤:r图表2几何条