爬蟲大家或多或少的都應該接觸過的,爬蟲有風險,抓數需謹慎,
本著研究學習的目的,記錄一下在 .NET Core 下抓取資料的實際案例,爬蟲代碼一般具有時效性,當我們的目標發生改版升級,規則轉換后我們寫的爬蟲代碼就會失效,需要重新應對,抓取資料的主要思路就是去分析目標網站的頁面邏輯,利用xpath、正則運算式等知識去決議網頁拿到我們想要的資料,
本篇主要簡單介紹三個組件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前兩個可以處理傳統的頁面,無法抓取單頁應用,如果需要抓取單頁應用可以使用PuppeteerSharp,
關于這三個組件庫的實際應用可以參考一下定時任務最佳實戰系列文章,
新建一個控制臺專案,抓取幾個站點的資料來試試,先做準備作業,添加一個IHotNews的介面,
using System.Collections.Generic;
using System.Threading.Tasks;
namespace SpiderDemo
{
public interface IHotNews
{
Task<IList<HotNews>> GetHotNewsAsync();
}
}
HotNews模型,包含標題和鏈接
namespace SpiderDemo
{
public class HotNews
{
public string Title { get; set; }
public string Url { get; set; }
}
}
最終我們通過依賴注入的方式,將抓取到的資料展示到控制臺中,
HtmlAgilityPack
- https://html-agility-pack.net/
- https://github.com/zzzprojects/html-agility-pack
在專案中安裝HtmlAgilityPack組件
Install-Package HtmlAgilityPack
這里以博客園為抓取目標,我們抓取首頁的文章標題和鏈接,
using HtmlAgilityPack;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
namespace SpiderDemo
{
public class HotNewsHtmlAgilityPack : IHotNews
{
public async Task<IList<HotNews>> GetHotNewsAsync()
{
var list = new List<HotNews>();
var web = new HtmlWeb();
var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/");
var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList();
foreach (var item in node)
{
list.Add(new HotNews
{
Title = item.InnerText,
Url = item.GetAttributeValue("href", "")
});
}
return list;
}
}
}
添加HotNewsHtmlAgilityPack.cs實作IHotNews介面,訪問博客園網址,拿到HTML資料后,使用xpath語法決議HTML,這里主要是拿到a標簽即可,
通過查看網頁分析可以得到這個xpath://*[@id='post_list']/article/section/div/a,
然后在Program.cs中注入IHotNews,回圈遍歷看看效果,
using Microsoft.Extensions.DependencyInjection;
using System;
using System.Linq;
using System.Threading.Tasks;
namespace SpiderDemo
{
class Program
{
static async Task Main(string[] args)
{
IServiceCollection service = new ServiceCollection();
service.AddSingleton<IHotNews, HotNewsHtmlAgilityPack>();
var provider = service.BuildServiceProvider().GetRequiredService<IHotNews>();
var list = await provider.GetHotNewsAsync();
if (list.Any())
{
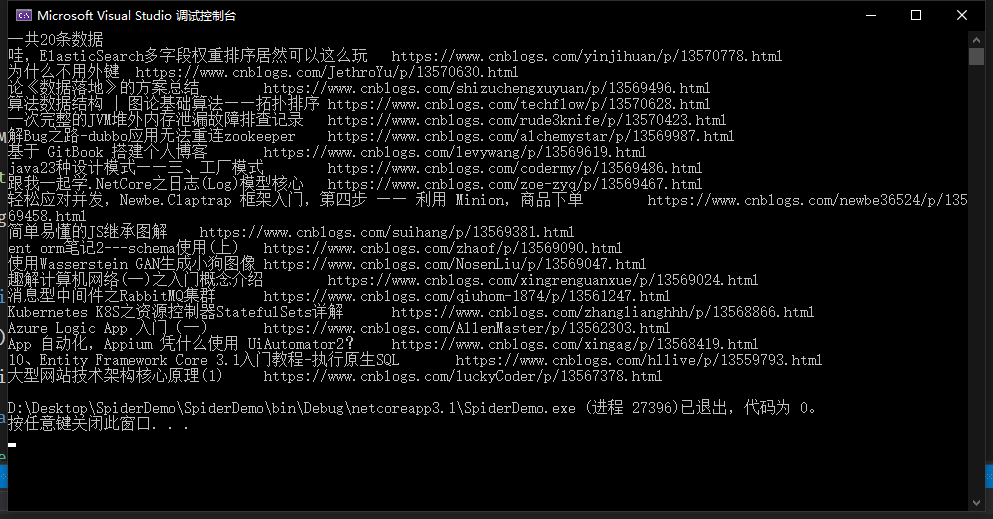
Console.WriteLine($"一共{list.Count}條資料");
foreach (var item in list)
{
Console.WriteLine($"{item.Title}\t{item.Url}");
}
}
else
{
Console.WriteLine("無資料");
}
}
}
}
AngleSharp
- https://anglesharp.github.io/
- https://github.com/AngleSharp/AngleSharp
在專案中安裝AngleSharp組件
Install-Package AngleSharp
同樣的,新建一個HotNewsAngleSharp.cs也實作IHotNews介面,這次使用AngleSharp抓取,
using AngleSharp;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace SpiderDemo
{
public class HotNewsAngleSharp : IHotNews
{
public async Task<IList<HotNews>> GetHotNewsAsync()
{
var list = new List<HotNews>();
var config = Configuration.Default.WithDefaultLoader();
var address = "https://www.cnblogs.com";
var context = BrowsingContext.New(config);
var document = await context.OpenAsync(address);
var cellSelector = "article.post-item";
var cells = document.QuerySelectorAll(cellSelector);
foreach (var item in cells)
{
var a = item.QuerySelector("section>div>a");
list.Add(new HotNews
{
Title = a.TextContent,
Url = a.GetAttribute("href")
});
}
return list;
}
}
}
AngleSharp決議資料和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css規則去獲取資料,用起來也是挺方便的,
在Program.cs中注入IHotNews,回圈遍歷看看效果,
using Microsoft.Extensions.DependencyInjection;
using System;
using System.Linq;
using System.Threading.Tasks;
namespace SpiderDemo
{
class Program
{
static async Task Main(string[] args)
{
IServiceCollection service = new ServiceCollection();
service.AddSingleton<IHotNews, HotNewsAngleSharp>();
var provider = service.BuildServiceProvider().GetRequiredService<IHotNews>();
var list = await provider.GetHotNewsAsync();
if (list.Any())
{
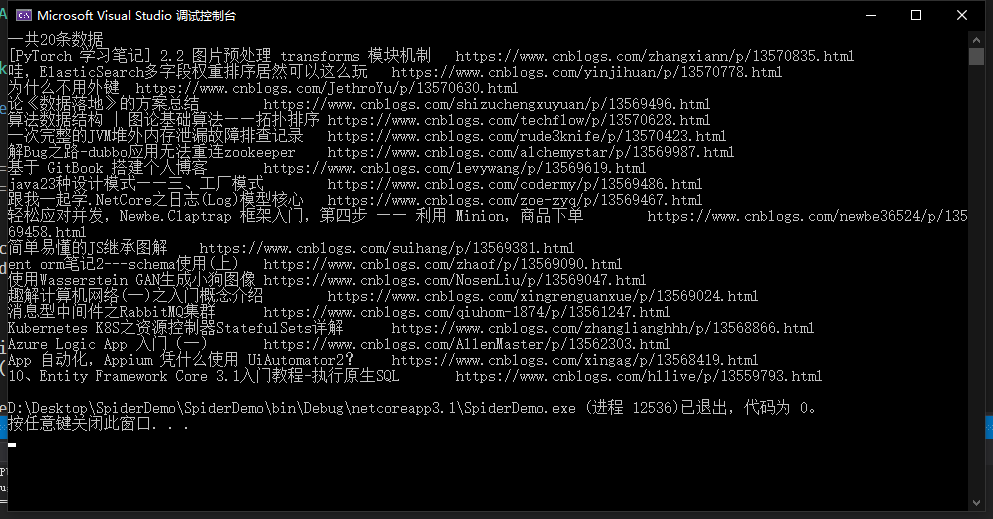
Console.WriteLine($"一共{list.Count}條資料");
foreach (var item in list)
{
Console.WriteLine($"{item.Title}\t{item.Url}");
}
}
else
{
Console.WriteLine("無資料");
}
}
}
}
PuppeteerSharp
- https://www.puppeteersharp.com/
- https://github.com/hardkoded/puppeteer-sharp
PuppeteerSharp是基于Puppeteer的,Puppeteer 是一個Google 開源的NodeJS 庫,它提供了一個高級API 來通過DevTools協議控制Chromium 瀏覽器,Puppeteer 默認以無頭(Headless) 模式運行,但是可以通過修改配置運行“有頭”模式,
PuppeteerSharp可以干很多事情,不光可以用來抓取單頁應用,還可以用來生成頁面PDF或者圖片,可以做自動化測驗等,
在專案中安裝PuppeteerSharp組件
Install-Package PuppeteerSharp
使用PuppeteerSharp第一次會幫我們在專案根目錄中下載瀏覽器執行程式,這個取決于當前網速的快慢,建議手動下載后放在指定位置即可,
using PuppeteerSharp;
using System.Threading.Tasks;
namespace SpiderDemo
{
class Program
{
static async Task Main(string[] args)
{
// 下載瀏覽器執行程式
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);
// 創建一個瀏覽器執行實體
using var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true,
Args = new string[] { "--no-sandbox" }
});
// 打開一個頁面
using var page = await browser.NewPageAsync();
// 設定頁面大小
await page.SetViewportAsync(new ViewPortOptions
{
Width = 1920,
Height = 1080
});
}
}
}
上面這段代碼是初始化PuppeteerSharp必要的代碼,可以根據實際開發需要進行修改,下面以"https://juejin.im"為例,演示幾個常用操作,
獲取單頁應用HTML
...
var url = "https://juejin.im";
await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);
var content = await page.GetContentAsync();
Console.WriteLine(content);
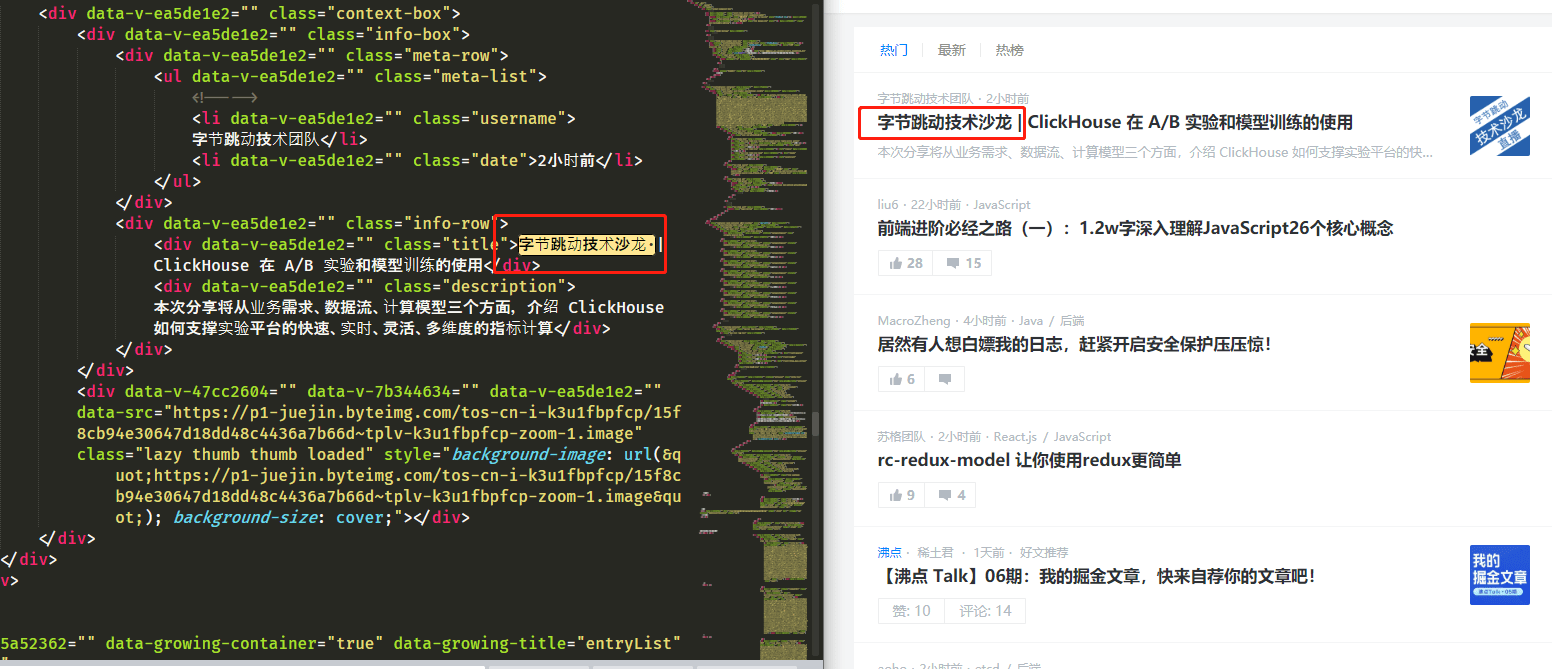
可以看到頁面上的HTML全部被獲取到了,這時候就可以利用規則決議HTML,拿到我們想要的資料了,
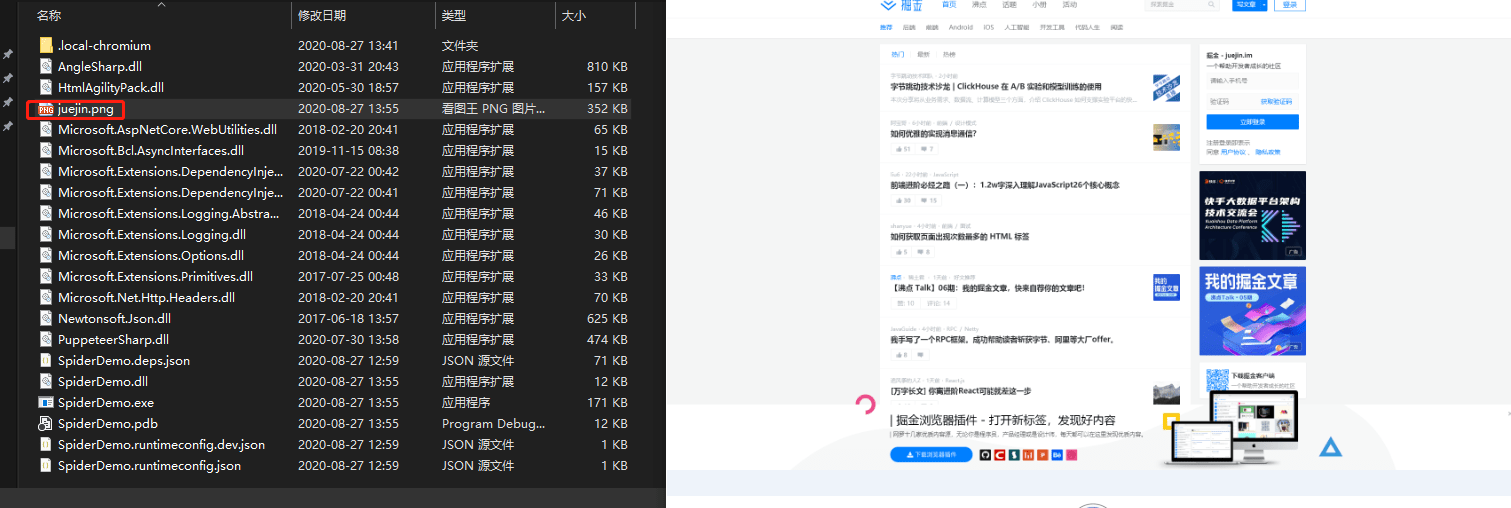
保存為圖片
...
var url = "https://juejin.im/";
await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);
await page.ScreenshotAsync("juejin.png");
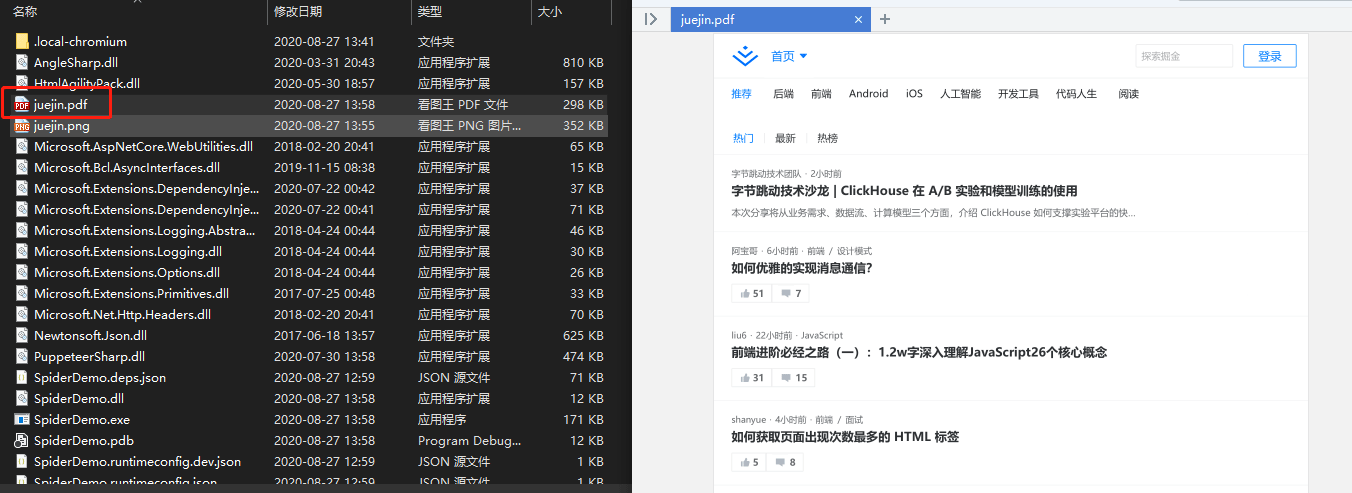
保存為PDF
var url = "https://juejin.im/";
await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);
await page.PdfAsync("juejin.pdf");
PuppeteerSharp的功能還有很多,比如頁面注入HTML、執行JS代碼等,使用的時候可以參考官網示例,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/56.html
標籤:.NET Core
上一篇:.NetCore·集成Ocelot組件之完全解決方案
下一篇:image operating system "windows" cannot be used on this platform