先說結論,Encoding下面有7個兒子,
其中6個分別是:UTF7,BigEndianUnicode,Unicode,Default,ASCII,UTF8,UTF32
還有一個最重要的兒子:ANSI,這個兒子下面又有140個兒子,其中一個是 ”簡體中文(GB2312)“
---------------------------------割--------------------------------
結合System.Text.Encoding類,說下發現程序
由屬性
public static Encoding UTF7 { get; }
public static Encoding BigEndianUnicode { get; }
public static Encoding Unicode { get; }
public static Encoding Default { get; }
public static Encoding ASCII { get; }
public static Encoding UTF8 { get; }
public static Encoding UTF32 { get; }知道編碼方式有6種,而Default肯定獲得的是這6種的其中一種;
運行后發現獲得的“簡體中文(GB2312)“,還真不是上述6種之一,
度娘知“簡體中文(GB2312)”是ANSI其中的一種;
由此知,ANSI是Encoding的一種編碼方式(文后附參考文獻),只是不知道為什么原始屬性中沒列出。
二、于是想知道ANSI到底有多少兒子,在Encoding中找到了GetEncodings方法,運行后
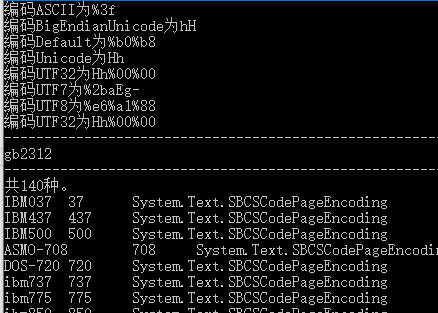
列出了140種。
附件一:
C# 運行代碼
string Str = "案";
Console.WriteLine("編碼ASCII為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.ASCII));
Console.WriteLine("編碼BigEndianUnicode為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.BigEndianUnicode));
Console.WriteLine("編碼Default為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.Default));
Console.WriteLine("編碼Unicode為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.Unicode));
Console.WriteLine("編碼UTF32為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.UTF32));
Console.WriteLine("編碼UTF7為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.UTF7));
Console.WriteLine("編碼UTF8為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.UTF8));
Console.WriteLine("編碼UTF32為" + HttpUtility.UrlEncode(Str, System.Text.Encoding.UTF32));
Console.WriteLine("----------------------------------------------------------");
var DefaultCode = System.Text.Encoding.Default;
Console.WriteLine(DefaultCode.BodyName);
Console.WriteLine("----------------------------------------------------------");
var ss = System.Text.Encoding.GetEncodings();
Console.WriteLine($"共{ss.GetLength(0).ToString() }種。");
foreach (var item in ss)
{
Console.WriteLine($"{item.Name }\t{item.CodePage }\t{item.GetEncoding()}");
}
運行結果:
二、參考文獻:

來自鏈接:https://www.iteye.com/blog/wallimn-539595
最后,雖然是付出了一下午努力得出的結論;
但總感覺心虛,覺得上面說法不對(第六感),
請各位大神確認一下。
uj5u.com熱心網友回復:
鼓勵。所謂的編碼,就是把一個字符用一種方法表示出來,比如我自己發明:
一:0001
二:0002
九:0003
十:0010
你:1234
我:1235
它:1236
...
也一種編碼。但這種編碼流行不來,只有我自己在使用。
有些大家經常使用,比較知名的編碼,就被收錄到Encoding的靜態屬性下,也就是提到的七種Encoding。
這七種里面,有4種完全支持Unicode(后面解釋):
Encoding.Unicode (名字實際有誤,會誤導,應該寫成Encoding.UTF16)
Encoding.BigEndianUnicode
Encoding.UTF8
Encoding.UTF32
其他三種中,ASCII和UTF7是歷史遺留編碼,不能完全表示所有Unicode的碼點。
而Encoding.Default實際上不是具體的一種編碼,它是當前機器的MBCS的代碼頁(也是歷史遺留造成的)決定的。
所有它可能是iso-8859-1,也可能是gb2312,將來也可能是UTF8等等。
舊的系統(比如Windows3.0)只支持某些編碼,需要知道編碼方式,這就是當前機器MBCS的代碼頁的由來。但這種方法通用性很差。隨著技術的進步,人們意識到需要有個統一的碼點方案,這就是Unicode的出現。Unicode也可以叫做統一碼 - 在Unicode下,具體的一個字符的碼點是固定的,比如(如果你第三行看不到字符,可能你的系統/瀏覽器不支持):
的:U+7684
A: U+0041
??:U+1F495
用UTF-16來表示就是:
的:Encoding.Unicode.GetString(new byte[]{ 0x84, 0x76 });
A: Encoding.Unicode.GetString(new byte[] { 0x41, 0x00 });
??:Encoding.Unicode.GetString(new byte[] { 0x3D, 0xD8, 0x95, 0xDC });
可以看到,UTF-16下,大部分編碼可以用兩個位元組表示,它就直接用了碼點的數字,比如{ 0x41, 0x0 }就是0x0041,{ 0x84, 0x76 }就是0x7684。但是,有些碼點兩個位元組放不下,比如那個U+1F495,UFT-16就使用了特定的前綴表示需要4個位元組。有興趣的朋友可以自行參考UTF-16編碼。
用UTF-32來表示就是:
的:Encoding.UTF32.GetString(new byte[]{ 0x84, 0x76, 0x00, 0x00 });
A: Encoding.UTF32.GetString(new byte[] { 0x41, 0x00, 0x00, 0x00 });
??:Encoding.UTF32.GetString(new byte[] { 0x95, 0xF4, 0x01, 0x00 });
UTF-32固定用32位元,4個位元組來表示碼點,可以和Unicode碼點直接轉換。比如{ 0x95, 0xF4, 0x01, 0x00 }就是U+1F495
用BigEndianUnicode來表示就是:。
的:Encoding.BigEndianUnicode.GetString(new byte[]{ 0x76, 0x84 });
A: Encoding.BigEndianUnicode.GetString(new byte[] { 0x00, 0x41 });
??:Encoding.BigEndianUnicode(new byte[] { 0xD8, 0x3D, 0xDC, 0x95, });
BigEndian表示“大端在前”,就是在每16位元內,大端位元組在前。有興趣的朋友自行和UTF-16比較。
用UTF8表示就是:
的:Encoding.UTF8.GetString(new byte[] { 0xE7, 0x9A, 0x84 });
A: Encoding.UTF8.GetString(new byte[] { 0x41 });
??:Encoding.UTF8.GetString(new byte[] { 0xF0, 0x9F, 0x92, 0x95 });
UTF8是變長編碼,傳統的Ascii字符如果在127以內,都可以用一個位元組表示,所以{ 0x41 }表示U+0041。
很多字符在UTF8可以編碼為兩個位元組,但UTF8的中文編碼效率不高,往往要用3個位元組表示。有興趣的朋友可以自行參閱UTF8標準。
用GB2312表示就是:
的:Encoding.GetEncoding("GB2312").GetString(new byte[] { 0xB5, 0xC4 });
A: Encoding.GetEncoding("GB2312").GetString(new byte[] { 0x41 });
??:<無法表示>
GB2312沒有完全支持Unicode,因此無法表示U+1F495。但GB2312的優點是對常用中文支持很好,只要兩個位元組。也一定上兼容Ascii,可以用一個位元組來支持常用的字母和數字。
用GB18030表示就是:
的:Encoding.GetEncoding("GB18030").GetString(new byte[] { 0xB5, 0xC4 });
A: Encoding.GetEncoding("GB18030").GetString(new byte[] { 0x41 });
??:Encoding.GetEncoding("GB18030").GetString(new byte[] { 0x94, 0x39, 0xd8, 0x33 });
GB18030用來替代GB2312,它支持Unicode。
uj5u.com熱心網友回復:
謝謝,看完了又琢磨了好久,才明白為何你開頭用的“鼓勵”二字....
敢情正確的表述應該是:Encoding下面有140個兒子,其中有6個是全球范圍內常用的UTF7,BigEndianUnicode,Unicode,Default,ASCII,UTF8,UTF32,有1個國內常用的,叫GB2312。
這回理解對了吧?
uj5u.com熱心網友回復:
是真心鼓勵。
原創的技術分享值得鼓勵,特別看到有思考,有參考的文章。
閱讀者可以重復你的試驗,有機會借鑒和修正,對技術理解和觀點。
至于常用編碼,個人覺得UTF8,UTF16(即微軟說的Encoding.Unicode),稱得上常用。
UTF7幾乎已經死寂了,它以前是用來克服email中不能正常顯示的問題。
ASCII的范圍太小,幾十歲的老協議可能還用。
UTF32不流行,一個字符要用4個位元組編碼,浪費很大。
uj5u.com熱心網友回復:
你參考的參考文獻對ANSI的理解有點問題。ANSI code pages就是Windows code pages,在Windows里ANSI編碼指的是除了Unicode編碼以外所有的編碼。而且ANSI這個名稱是一個誤用(misnomer)。
ANSI應用程式指的是哪些不是為Unicode撰寫的應用程式(非Unicode程式),具體來說就是用char *單位元組字串,并呼叫相應的單位元組API(例如:
size_t strlen ( const char * str );
)的應用程式。與此相對的是使用wchar_t *雙位元組字串,并呼叫的是雙位元組API(一般帶個w開頭,例如:
size_t wcslen (const wchar_t* wcs);
的Unicode應用程式。
ANSI應用程式依賴于Windows的默認code page,因此同樣的資料可能在不同的電腦上表示的意義不同。這個設定在控制面板->時鐘和區域->區域->管理選項卡->非Unicode程式的語言 里面修改。
ANSI既有單位元組編碼,如code page 1252,也有雙位元組編碼,例如GB2312(code page 936),參考文獻對此理解不準確。
Unicode應用程式可以保證相同的資料在所有的電腦上顯示相同意義的字符。
.NET的String是Unicode字串。
uj5u.com熱心網友回復:
所以ANSI也不是最重要的兒子,而是應該被遺棄的兒子轉載請註明出處,本文鏈接:https://www.uj5u.com/net/71679.html
標籤:C#