目錄
- 概述
- 開篇
- 欄位 Or 表
- 來說一下持久化為欄位的情況
- 來說一下持久化為表的情況
- 怎么持久化集合值物件
- 將集合值物件存為欄位
- 將集合值物件存為表
- 基于快照的資料存盤物件
- 比較
- 總結
概述
在實踐領域驅動設計(DDD)的程序中,我們會根據專案的所在領域以及需求情況捕獲出一定數量的領域物件,設計得足夠好的領域物件便于我們更加透徹的理解業務,方便系統后期的擴展和維護,不至于隨著需求的擴展和代碼量的累積,系統逐漸演變為大泥球(Big Ball of Mud),
雖然領域驅動設計的思想很誘人,但我們依然會面臨各種隱藏的困難,就比如今天我們要講的主題“持久化”:即使前期我們設計了足夠完整的領域物件,但是依然需要持久化它們到資料庫中,而普通的關系型資料庫可能很難維持領域物件的原有結構,所以我們必須要使用一些特有的手段來處理它,
開篇
本篇文章屬于《如何運用領域驅動設計》系列的一個補充,如果您閱讀過該系列的其它文章,您就會發現關于“持久化”的這個問題已經不止在一篇博文中提及到了,
那么,到底是什么原因讓我們面臨這個問題呢? 是的!值物件! 如果您認真的了解過值物件的話(如果還不了解值物件,您可以參考 如何運用領域驅動設計 - 值物件),您會發現值物件是由許多基元型別構成的(比如string,int,double等),所以我們可以理解它為對細粒度基元型別的包裹,構成我們所在領域中的一個基礎型別,比如說下面這個例子:
public sealed class City : ValueObject
{
public string Name { get; }
public int Population { get; }
public City(string name, int population)
{
Name = name;
Population = population;
}
}
我們假設現在有一個叫做City的值物件,它是由名稱(Name)和人口數量(Population)構成,通常我們這樣建立值物件的原因很簡單,在該領域中我們一聯系到“人口”數量就會和“城市”連同在一起(你不會說我想知道人口數量,而你會說我想知道紐約的人口數量),所以“城市”這一概念成為我們該領域中的小顆粒物件,而該物件在代碼實作中是由多個小基元型別構成的,比如該例子就是由一個string和一個int,
這樣建模的好處之一就是我們考慮的問題是一個整體,將零碎的點構建為一個整體物件,如果該物件的行為需要發生改變,只需要修改該物件本身就可以了,而不是代碼散落在各處需要到處查找(這也是滾成大泥球的原因之一),
如果您喜歡捕獵有關DDD的知識,您可能不止一次會看到這樣一條建議規則:
In the world of DDD, there’s a well-known guideline that you should prefer Value Objects over Entities where possible. If you see that a concept in your domain model doesn’t have its own identity, choose to treat that concept as a Value Object.
該建議的內容就是提倡DDD實踐者多使用值物件,當然也不是說無論什么東西都建立成值物件,只是要我們多去發現領域中的值物件,
但是這往往給持久化帶來了難度,先來想一下傳統的編碼持久化方式:一個物件(或者POCO)里面包含了各個基元型別的屬性,當需要持久化時,每個屬性都對應資料庫的一個欄位,而該物件就成為了一個表, 但是這在領域驅動設計中就不好使用了,值物件成了我們考慮問題的小顆粒,而它在代碼中成了一個類,如果直接持久化它是什么樣子呢?表,使用它的物體或者聚合根也是一個表,兩個表通過主外鍵關系鏈接,
那么這樣持久化方式好不好呢? 答案是不確定的,可能了解了下文的這些方案后,您會有自己的見解,
本篇文章的持久化方案都是基于關系型資料庫,如果您是非關系型資料庫(比如mongodb),那么您應該不會面臨這樣的問題,
欄位 Or 表
將值物件持久化成欄位好呢?還是將值物件持久化為表好呢? 這個問題其實也有很多廣泛的討論,就好比.NET好還是Java好(好吧,我php天下**),目前其實也沒有個明確的結果:
- 覺得持久化為表欄位的原因是 如果持久化為表,必須給表添加一個ID供參考的物體或者聚合關聯,這就不滿足值物件不應該有ID的準則了,
- 覺得持久化為表的原因是 資料表模型并不代表代碼層面的模型,代碼里面的值物件其實并沒有ID的說法,所以它是符合值物件的,而持久化為欄位的話,同一個值物件資料會被復制為多份導致資料冗余,
當然哈,各有各的道理,我們也不用特別偏向于使用哪個結論,應該站在客觀的角度,實際的專案需要哪種手段就根據切實的情況來選擇,
來說一下持久化為欄位的情況
該手段其實在近期來說比較流行,特別是在EFCore2.0之后,為什么呢?因為EF Core2.0提供了一個叫做 從屬物體型別 的概念,其實這個技術手段在EF中很早就有了,在EF中有一個叫做Complex的東西,只是在EF Core 1.x時代沒有引入而已,
在EFCore引入了Owned之后,微軟那個最著名的微服務教程 eShopOnContainers 也順勢推出了用于該特性來持久化值物件的方案:

所以這也是為什么大家都在使用Owned持久化值物件的原因,(當然,大家專案中只有Address被建立為值物件的習慣不知道是不是從這兒養成的 ??),
來看看Owned好不好使:
首先是一個物體中包含一個值物件的情況,該情況在微軟的那個案例中已經實作了,所以我們不用糾結它的功能,肯定是能夠實作的,
但是有其它的情況,一個物體包含了一個值物件,該值物件中又包含了另外一個值物件, 您可能會問,怎么可能會有這么復雜,但是如果您按照上面那個多使用值物件的準則的話,這種情況在您的專案中非常的常見,我參考了《如何運用領域驅動設計》中的案例來測驗這種實作,代碼大致是這樣:
public class Itinerary : AggregateRoot<Guid>
{
public ItineraryNote Note { get; private set; }
}
public class ItineraryNote : ValueObject
{
public string Content { get; private set; }
public DateTime NoteTime { get; private set; }
public NotePerson NotePerson { get; private set; }
}
public class NotePerson
{
public string FirstName { get; private set; }
public string LastName { get; private set; }
}
為了達到演示效果,我剔除了有關聚合根的其它屬性和行為方法,我們可以清楚的看到聚合根Itinerary 包含了值物件 ItineraryNote ,ItineraryNote 又包含了值物件 NotePerson, 接下來我們來使用EF Core的Owned來看它能否完成這種映射關系:
modelBuilder.Entity<Itinerary>().OwnsOne(s => s.Note).OwnsOne(s => s.NotePerson);
當能夠連續打出兩個Owns**的時候我就覺得這事兒應該成了,結果看資料庫的關系圖吧:
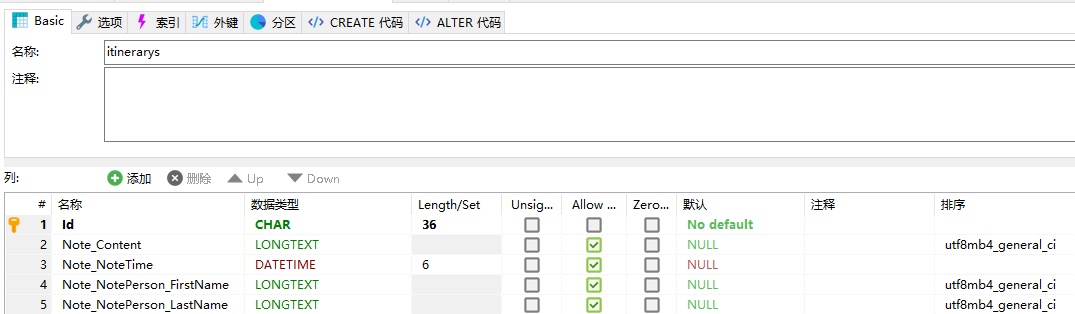
是的,它可以!而EFCore對于該持久化的格式是:Entity_Valueobject1_Valueobject2,也就是說我們的值物件可以一直嵌套下去,只是欄位名也會跟著一直嵌套而已,
此時,使用其它orm框架的同學們可能就要說了:我沒有使用EF,那么我怎么映射,比如是Dapper,對于這種嵌套多層值物件的我怎么辦? 別慌哈,后文的另外的方案可能適合您,
來說一下持久化為表的情況
其實這種情況很簡單了,如果您不配置Owned的話,EF會為您默認生成表,這種場景我想您可能深有體會,我這里就不再過多闡述了,
怎么持久化集合值物件
是的,如果值物件是一個集合呢?我們又將如何處理它呢?
對了,說到這里還有一個DDD的準則:“盡量少用集合值物件,” 當然,這個觀點我覺得很有爭議,該觀點在 《領域驅動設計模式、原理與實踐》 這本權威DDD教材中有被提及,該觀點認為我們需要仔細的捕獲領域中的值物件,教程中用了“電話號碼”來舉例,一個人可能有多個號碼比如移動電話、座機、傳真等,我們可能需要將電話號碼建立為值物件,然后建立一個集合值物件,但是教程中認為這樣并不好,而是單獨將各個類別建立為了值物件,比如移動電話值物件,傳真值物件等,
這種做法雖然更貼近于現實建模,但是某些時刻我們真的需要建立一個集合值物件,比如開篇提到的City,如果我在某個場景會用到多個城市資訊呢?還有ItineraryNote 里面的 NotePerson 呢,如果是多個人呢? 所以我們的領域或多或少會遇到集合值物件,
將集合值物件存為欄位
這種手段非常的常見,最切實的實踐方案就是…………………………!對 json! 將集合序列化成json,特別是現在新sqlserver等資料庫已經支持json格式的欄位了,所以序列化和反序列化的手段也非常容易讓我們去持久化值物件,
但是……我的資料庫不支持json呢?沒關系,還有辦法用string,存為strng格式進行反序列化操作也不會消耗太多性能,
還有一種方式:制定屬于自己的格式,下面將大家舉例為大家說明,用開頭的那個City吧:
public sealed class City : ValueObject
{
public string Name { get; }
public int Population { get; }
public City(string name, int population)
{
Name = name;
Population = population;
}
}
假如我們有一個物體中存在一個集合值物件:
public class User : Entity
{
public List<City> Cities { get; set; }
}
第一步,抽象我們的City為另外一個可迭代物件,比如CityList:
public class CityList : ValueObject<CityList>, IEnumerable<City>
{
private List<City> _cities { get; }
public CityList(IEnumerable<City> cities)
{
_cities = cities.ToList();
}
protected override bool EqualsCore(CityList other)
{
return _cities
.OrderBy(x => x.Name)
.SequenceEqual(other._cities.OrderBy(x => x.Name));
}
protected override int GetHashCodeCore()
{
return _cities.Count;
}
public IEnumerator<City> GetEnumerator()
{
return _cities.GetEnumerator();
}
IEnumeratorIEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
第二步:讓CityList能夠轉換成為string的能力,這個能力怎么來呢? C#為我們提供了explicit和implicit的關鍵字,方便我們對強型別進行互轉(如果您還不了解該關鍵字,戳這里),
public static explicit operator CityList(string cityList)
{
List<City> cities = cityList.Split(';')
.Select(x => (City)x)
.ToList();
return new CityList(cities);
}
public static implicit operator string(CityList cityList)
{
return string.Join(";", cityList.Select(x => $"{(string)x.Name}|{(string)x.Population}"));
}
最后,外層的User物體改寫為醬紫:
public class User : Entity
{
private string _cities = string.Empty;
public virtual CityListCities
{
get { return (CityList)_cities; }
set { _cities = value; }
}
}
這樣提供給ORM的映射的話,可能就會得到像下面的結果:
#Table User
UserID: 1,
CityList: "City1|10;City2|20;"
這種方法的缺點:
當然這種方法雖然能夠持久化值物件,但是依然有些很顯著的缺點:
- 無法在集合中的單個項中執行有效搜索
- 如果集合中有很多項,這種方法可能會影響性能
- 不支持多層值物件
當然這也并不是說我們就完全不能使用它,在某些簡單的值物件場合,該方法可能也是個好的方案,
將集合值物件存為表
這種方案和直接將值物件存為表是一樣的,那么還是來看看用EFCore是什么效果吧,EFCore為這種情況推出了OwnsMany的方法,如果我們將上面OwnsOne的案例改為一個值物件集合是什么樣子呢?
public class ItineraryNote : ValueObject
{
public string Content { get; private set; }
public DateTime NoteTime { get; private set; }
//改為一個集合
public List<NotePerson> NotePersons { get; private set; }
}
然后將映射的OwnsOne改寫為OwnsMany:
modelBuilder.Entity<Itinerary>().OwnsOne(s => s.Note).OwnsMany(s => s.NotePersons);
最后資料庫的結果是這樣的:

用您的EFCore動手試試吧!
基于快照的資料存盤物件
前面的幾種方案都是通過EFCore這種重量框架來完成,那么如果使用輕量的ORM框架要自己完成映射配置的如何處理呢?如果自己去配置這種關系非常繁瑣,無論是sql操作還是映射操作,都無疑加大了很多的作業量,所以,我們可以嘗試引入專門的資料存盤物件來供持久化,
回顧一下我們在以前的文章《如何運用領域驅動設計 - 存盤庫》提到過的一句話:
“領域模型是問題域的抽象,富含行為和語言;資料模式是一種包含指定時間領域模型狀態的存盤結構,ORM可以將特定的物件(C#的類)映射到資料模型,”
所以當時我就在考慮,既然資料模型是專用于儲存的,而領域模型的結構復雜讓它難以完成原樣持久化,那為什么不在持久化的時候將領域模型轉換為專用的資料存盤模型呢?這樣對資料庫也友好,而且也不會破壞領域模型的結構,
還是看那個 Itinerary 例子:
public class Itinerary : AggregateRoot<Guid>
{
public ItineraryNote Note { get; private set; }
}
public class ItineraryNote : ValueObject
{
public string Content { get; private set; }
public DateTime NoteTime { get; private set; }
}
這時我們構建一個專用的資料存盤物件,供ORM框架使用:
public class ItinerarySnapshotModel
{
public Guid ID { get; set; }
public string Content { get; set; }
public DateTime NoteTime { get; set; }
}
這個結構您可能再熟悉不過了,是的,它對ORM框架超級友好,這也是面向資料庫編程的結構,
這時您可能會問了:“怎么我寫DDD,寫了半天又回去了?” 這個問題,待會來嚴肅回答!??
先來看看領域物件和資料存盤物件的互轉:
public class Itinerary : AggregateRoot<Guid>, IEntityHasSnapshot<ItinerarySnapshotModel>
{
public ItineraryNote Note { get; private set; }
//must have this ctor
public Itinerary(ItinerarySnapshotModel snapshot)
{
Note = new ItineraryNote(snapshot.Content);
Id = snapshot.ID;
}
public ItinerarySnapshotModel GetSnapshot()
{
return new ItinerarySnapshotModel()
{
Content = Note.Content,
ID = Id,
NoteTime = Note.NoteTime
};
}
}
/// <summary>
/// Provides the ability for entities to create snapshots
/// </summary>
/// <typeparam name="TEntity"><see cref="IEntity"/></typeparam>
public interface IEntityHasSnapshot<TSnapshot>
{
/// <summary>
/// Get a entity snapshot
/// </summary>
TSnapshot GetSnapshot();
}
這樣就完成了兩種模型的互轉,每當ORM需要持久化時,呼叫aggregateRoot.GetSnapshot()就能得到持久化模型了,而持久化模型的設計在于您自己,您可以根據資料庫的情況任意更改,而您只需保證它能和真正的領域物件完成映射就可以了,
好了,來談談這種方案的優缺點,以及上面的回到原始面向資料庫編程的問題:
先來考慮我們為什么使用領域驅動設計,為的是讓專案設計的更加清晰和干凈,而領域模型的設計是在設計的前期,甚至領域模型的基本確定還超越了編碼開始的時候,我們只捕獲領域中重要的物件,而不考慮其它問題(比如持久化、映射框架選擇等基礎問題),所以這樣考慮出來的領域物件才是足夠干凈和更符合業務實際情況的,
而考慮持久化是在什么時候做的呢?需要與基礎構件(比如ORM框架)互動的時期,這時領域物件編碼幾乎已經完成,其實在持久化之前我們已經完成了領域驅動設計的程序,所以并非是我們退回去使用面向資料庫的設計,如果在設計領域物件的時候又考慮資料庫等互動,那么想象一下這個打著領域驅動設計旗號的專案最后會成為什么樣呢?
那么這種基于快照的資料存盤物件方式的優點是什么呢?
- 它解決了持久化的問題,
- 甚至可以將物體OR聚合根的屬性完全私有化,這樣外界根本無法破壞它的資料,而外界是通過快照的這個資料結構來訪問的,
- 您可以隨意設計您的資料庫結構,哪怕有一天您切換了資料庫或者ORM框架,只要您保證轉換正確之后,領域的行為是不會被破壞的,
但是它也有個顯著的缺點:增大編碼量,每一個聚合根都需要增加一個資料儲存物件與之對應,而且還需要配置映射規則,但是!!!! 請您相信,這些代碼與您專案中的其它代碼比起來微不足道,并且它后期為您帶來的好處可能更加明顯,
比較
上面為大家提供了多種持久化的方案,那么到底哪種更好呢?就好比最初的問題,持久化為欄位好還是表好? 依然沒有答案,但是我相信您看了上面的內容后,能夠找到屬于您專案的特有方案,它也會讓您落地DDD專案邁出重要的一步,
Table 1
| 方案 | 優點 | 缺點 |
|---|---|---|
| 持久值物件到表欄位 | 資料依附于某條物體或者聚合根 | 資料冗余、會讓表擁有太多欄位 |
| 持久化值物件到表 | 資料量不冗余 | 會存在許多表、從資料庫層面很難看出它和物體的區別 |
Table 2
| 方案 | 優點 | 缺點 |
|---|---|---|
| 需要轉換物件用作持久化 | 領域物件和資料物件完全獨立,對資料物件的操作不會影響到領域物件 | 增大編碼量 |
| 不需要轉換物件用作持久化 | 直接將領域物件供給ORM持久化,簡單且不需要增加額外的東西 | 配置規則可能比較繁瑣,有時候為了讓領域模型適配資料而改動領域模型 |
總結
該篇文章文字比較多,也許花費了您太長的時間閱讀,但希望本文的這些方案能夠對您持久化領域物件有所幫助,這篇博文沒有攜帶GitHub的原始碼,如果您需要的話可以在下方留言,我寫一份上傳至Github,哦對了,關于正在寫的MiCake(米蛋糕),它也將支持上面所講的所有方案,
該篇文章屬于《如何運用領域驅動設計》的補充篇,為了便于您查看該系列文章和了解文章的更新計劃,我在博客首頁置頂了該系列的 匯總目錄文章(點擊跳轉),如果您有興趣的話可以跳轉至該文章查看,
對了,該系列的下次更新可能會到下個月了,畢竟還是要過年的嘛,在這兒提前祝大家新年快樂(好像有些太早了哈( ̄▽ ̄)"),但是現在我新增了一個系列博文叫《五分鐘的.NET》,是一些關于.NET的小知識,定于每周一和周五在博客園更新,如果您有興趣的話可以關注喲,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/73234.html
標籤:.NET Core