在這一章,我們將建立一個垃圾郵件過濾分類模型,我們將使用一個包含垃圾郵件和非垃圾郵件的原始電子郵件資料集,并使用它來訓練我們的ML模型,我們將開始遵循上一章討論的開發ML模型的步驟,這將幫助我們理解作業流程,
在本章中,我們將討論以下主題:
l 定義問題
l 準備資料
l 資料分析
l 構建資料的特征
l 邏輯回歸與樸素貝葉斯的Email垃圾郵件過濾
l 驗證分類模型
定義問題
讓我們從定義本章要解決的問題開始,我們可能已經對垃圾郵件很熟悉了;垃圾郵件過濾是眾電子郵件服務的基本功能,垃圾郵件對用戶來說可能是惱人的,但它們除此之外,也會帶來更多的問題和風險,例如,可以設計垃圾郵件來獲取信用卡號或銀行帳戶資訊,這些資訊可用于信用卡欺詐或洗錢,垃圾郵件也可以用來獲取個人資料,然后可以用于身份盜竊和各種其他犯罪,垃圾郵件過濾技術是電子郵件服務避免用戶遭受此類犯罪的重要一步,然而,有正確的垃圾郵件過濾解決方案是困難的,我們想過濾掉可疑的郵件,但同時,我們又不想過濾太多,以至于非垃圾郵件進入垃圾郵件檔案夾,永遠不會被用戶看到,為了解決這個問題,我們將讓我們的ML模型從原始電子郵件資料集中學習,并使用主題行將可疑電子郵件歸類為垃圾郵件,我們將著眼于兩個性能指標來衡量我們的成功:準確度和召回率,我們將在以下幾節中詳細討論這些指標,
總結我們的問題定義:
n 需要解決的問題時什么?我們需要一個垃圾郵件過濾解決方案,以防止我們的用戶成為欺詐活動的受害者,同時改善用戶體驗,
n 為什么這是個問題?在過濾可疑郵件和不過濾太多郵件之間取得適當的平衡是很困難的,這樣垃圾郵件仍然會進入收件箱,我們將依靠ML模型來學習如何對這些可疑郵件進行統計分類,
n 解決這個問題的方法有哪些?我們將建立一個分類模型,根據郵件的主題行,標記潛在的垃圾郵件,我們將使用準確性和召回率來平衡被過濾的郵件數量,
n 成功的標準是什么?我們想要高回復率(實際垃圾郵件檢索的百分比占垃圾郵件的總數),而不犧牲太多的精確率(正確分類的垃圾郵件的百分比中預測為垃圾郵件),
準備資料
現在,我們已經清楚地描述和定義了將要用ML解決的問題,接下來我們需要準備資料,通常,我們需要在資料準備步驟之前采取額外的步驟來收集我們需要的資料,但是現在,我們將使用一個預先編譯并標記為公共可用的資料集,在本章中,我們將使用CSDMC2010垃圾資料集來訓練和測驗我們的模型,我們將看到一個名為SPAMTrain.label的文本檔案,SPAMTrain.label檔案對訓練檔案夾中的每封郵件都進行了編碼,0代表垃圾郵件,1代表非垃圾郵件,我們將使用此文本檔案和訓練檔案夾中的電子郵件資料來構建垃圾郵件分類模型,
我們現在擁有的是一個原始資料集,其中包含許多EML檔案,其中包含關于單個電子郵件的資訊,以及一個包含標記資訊的文本檔案,為了使這個原始資料集可用來構建垃圾郵件分類模型,我們需要做以下作業:
- 從EML檔案中提取主題行:為將來的任務準備資料的第一步是從各個EML檔案中提取主題和正文,我們將使用一個名為EAGetMail的包來加載和提取EML檔案中的資訊,使用EAGetMail包,我們可以輕松地從EML檔案中加載和提取主題和正文內容,一旦從電子郵件中提取了主題和正文,就需要將每行資料作為一行附加到Deedle資料框架中,
- 將提取的資料與標簽結合起來:在從各個EML檔案中提取主題和正文內容之后,我們還需要做一件事,我們需要將經過編碼的標簽(垃圾郵件為0,而非垃圾郵件為1)映射到我們在前一步中創建的資料幀的每一行,如果我們打開垃圾郵件,標簽檔案與任何文本編輯器,您可以看到編碼的標簽在第一列和相應的電子郵件檔案名在第二列,由一個空格分隔,使用Deedle frame的ReadCsv函式,我們可以通過指定一個空格作為分隔符來輕松地將這個標簽資料加載到資料框架中,一旦我們將這個標記的資料加載到一個資料框架中,我們就可以簡單地將這個資料框架的第一列添加到前面步驟中使用Deedle框架的AddColumn函式創建的其他資料框架中,
- 將合并后的資料匯出為CSV檔案:現在我們已經有了一個包含電子郵件和標簽資料的資料框架,現在可以將該資料框架匯出為CSV檔案,以供將來使用,使用Deedle frame的SaveCsv函式,您可以輕松地將資料幀保存為CSV檔案,
這個準備資料步驟的代碼如下:


1 using Deedle; 2 using EAGetMail; 3 using System; 4 using System.IO; 5 using System.Linq; 6 7 namespace 準備資料 8 { 9 internal class Program 10 { 11 private static void Main(string[] args) 12 { 13 // 獲取所有原始的電子郵件格式的檔案 14 // TODO: 更改指向資料目錄的路徑 15 string rawDataDirPath = @"D:\作業\代碼庫\AI\垃圾郵件過濾\raw-data"; 16 string[] emailFiles = Directory.GetFiles(rawDataDirPath, "*.eml"); 17 18 // 從電子郵件檔案中決議出主題和正文 19 var emailDF = ParseEmails(emailFiles); 20 // 獲取每個電子郵件的標簽(spam vs. ham) 21 var labelDF = Frame.ReadCsv(rawDataDirPath + "\\SPAMTrain.label", hasHeaders: false, separators: " ", schema: "int,string"); 22 // 將這些標簽添加到電子郵件資料框架中 23 emailDF.AddColumn("is_ham", labelDF.GetColumnAt<String>(0)); 24 // 將決議后的電子郵件和標簽保存為CSV檔案 25 emailDF.SaveCsv("transformed.csv"); 26 27 Console.WriteLine("準備資料步驟完成!"); 28 Console.ReadKey(); 29 } 30 31 private static Frame<int, string> ParseEmails(string[] files) 32 { 33 // 我們將決議每個電子郵件的主題和正文,并將每個記錄存盤到鍵值對中 34 var rows = files.AsEnumerable().Select((x, i) => 35 { 36 // 將每個電子郵件檔案加載到郵件物件中 37 Mail email = new Mail("TryIt"); 38 email.Load(x, false); 39 40 // 提取主題和正文 41 string EATrialVersionRemark = "(Trial Version)"; // EAGetMail在試用版本中附加主題“(試用版本)” 42 string emailSubject = email.Subject.EndsWith(EATrialVersionRemark) ? 43 email.Subject.Substring(0, email.Subject.Length - EATrialVersionRemark.Length) : email.Subject; 44 string textBody = email.TextBody; 45 46 // 使用電子郵件id (emailNum)、主題和正文創建鍵-值對 47 return new { emailNum = i, subject = emailSubject, body = textBody }; 48 }); 49 50 // 根據上面創建的行創建一個資料幀 51 return Frame.FromRecords(rows); 52 } 53 } 54 }View Code
運行這段代碼后,程式將會創建一個名為transformed.csv的檔案,它將包含四列(emailNum、subject、body和is_ham),我們將使用此輸出資料作為后面步驟的輸入,以構建垃圾郵件過濾專案的ML模型,但是,我們也可以嘗試使用Deedle框架和EAGetMail包,以不同的方式調整和準備這些資料,我在這里提供的代碼是準備這些原始電子郵件資料以供將來使用的一種方法,以及我們可以從原始電子郵件資料中提取的一些資訊,使用EAGetMail包,我們也可以提取其他特征,比如發件人的電子郵件地址和電子郵件中的附件,這些額外的特征可能有助于改進垃圾郵件分類模型,
資料分析
在準備資料步驟中,我們將原始資料集轉換為更具可讀性和可用性的資料集,我們現在有一個檔案可以查看,以找出哪些郵件是垃圾郵件,哪些不是,此外,我們可以很容易地找到垃圾郵件和非垃圾郵件的主題行,有了這些轉換后的資料,讓我們開始看看資料實際上是什么樣子的,看看我們能否在資料中找到任何模式或問題,
因為我們正在處理文本資料,所以我們首先要看的是垃圾郵件和非垃圾郵件的單詞分布有什么不同,為此,我們需要將上一步的資料輸出轉換為單詞出現次數的矩陣表示,讓我們以資料中的前三個主題行為例,一步步地完成這一作業,我們的前三個主題如下:

如果我們轉換這些資料,使每一列對應于每一個主題行中的每個單詞,并將每個單元格的值編碼為1,如果給定的主題行有單詞,則編碼為0,如果沒有,則生成的矩陣如下所示:

這種特定的編碼方式稱為one-hot編碼,我們只關心特定的單詞是否出現在主題行中,而不關心每個單詞在主題行中實際出現的次數,在前面的例子中,我們還去掉了所有的標點符號,比如冒號、問號和感嘆號,要以編程方式做到這一點,我們可以使用regex將每個主題行拆分為只包含字母-數字字符的單詞,然后用one-hot編碼構建一個資料框架,完成這個編碼步驟的代碼如下:
1 private static Frame<int, string> CreateWordVec(Series<int, string> rows) 2 { 3 var wordsByRows = rows.GetAllValues().Select((x, i) => 4 { 5 var sb = new SeriesBuilder<string, int>(); 6 7 ISet<string> words = new HashSet<string>( 8 Regex.Matches( 9 // 只字母字符 10 x.Value, "[a-zA-Z]+('(s|d|t|ve|m))?" 11 ).Cast<Match>().Select( 12 // 然后,將每個單詞轉換為小寫字母 13 y => y.Value.ToLower() 14 ).ToArray() 15 ); 16 17 // 對每行出現的單詞進行1的編碼 18 foreach (string w in words) 19 { 20 sb.Add(w, 1); 21 } 22 23 return KeyValue.Create(i, sb.Series); 24 }); 25 26 // 從我們剛剛創建的行創建一個資料框架 并將缺失的值編碼為0 27 var wordVecDF = Frame.FromRows(wordsByRows).FillMissing(0); 28 29 return wordVecDF; 30 }View Code
有了這種one-hot編碼矩陣表示的單詞,使我們的資料分析程序變的更容易,例如,如果我們想查看垃圾郵件中出現頻率最高的10個單詞,我們可以簡單地對垃圾郵件的一個one-hot編碼單詞矩陣的每一列的值進行求和,然后取求和值最高的10個單詞,這正是我們在以下代碼中所做的:
1 var hamTermFrequencies = subjectWordVecDF.Where( 2 x => x.Value.GetAs<int>("is_ham") == 1 3 ).Sum().Sort().Reversed.Where(x => x.Key != "is_ham"); 4 5 var spamTermFrequencies = subjectWordVecDF.Where( 6 x => x.Value.GetAs<int>("is_ham") == 0 7 ).Sum().Sort().Reversed; 8 9 // 查看排名前十的垃圾郵件和非垃圾郵件 10 var topN = 10; 11 12 var hamTermProportions = hamTermFrequencies / hamEmailCount; 13 var topHamTerms = hamTermProportions.Keys.Take(topN); 14 var topHamTermsProportions = hamTermProportions.Values.Take(topN); 15 16 System.IO.File.WriteAllLines( 17 dataDirPath + "\\ham-frequencies.csv", 18 hamTermFrequencies.Keys.Zip( 19 hamTermFrequencies.Values, (a, b) => string.Format("{0},{1}", a, b) 20 ) 21 ); 22 23 var spamTermProportions = spamTermFrequencies / spamEmailCount; 24 var topSpamTerms = spamTermProportions.Keys.Take(topN); 25 var topSpamTermsProportions = spamTermProportions.Values.Take(topN); 26 27 System.IO.File.WriteAllLines( 28 dataDirPath + "\\spam-frequencies.csv", 29 spamTermFrequencies.Keys.Zip( 30 spamTermFrequencies.Values, (a, b) => string.Format("{0},{1}", a, b) 31 ) 32 );View Code
從這段代碼可以看出,我們使用Deedle的資料框架的求和方法來對每一列中的值求和,并按相反的順序排序,我們對垃圾郵件這樣做一次,對非垃圾郵件這樣做一次,然后,我們使用Take方法獲得垃圾郵件和非垃圾郵件中出現頻率最高的十個單詞,當問運行這段代碼時,它將生成兩個CSV檔案:ham-frequency-cies.csv和spam-frequency-cies.csv,這兩個檔案包含關于垃圾郵件和非垃圾郵件中出現的單詞數量的資訊,我們將在稍后的構造資料特征和模型構建步驟中使用這些資訊,
現在讓我們將一些資料可視化,以便進一步分析,首先,看一下資料集中ham電子郵件中出現頻率最高的10個術語:
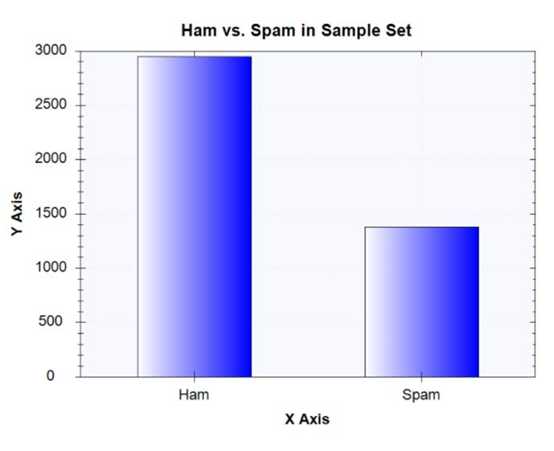
從這個柱狀圖中可以看出,資料集中的非垃圾郵件比垃圾郵件要多,就像在現實世界中一樣,我們的收件箱里收到的非垃圾郵件比垃圾郵件要多,
我們使用以下代碼來生成這個柱狀圖,以可視化資料集中的ham和spam電子郵件的分布:
1 var barChart = DataBarBox.Show( 2 new string[] { "Ham", "Spam" }, 3 new double[] { 4 hamEmailCount, 5 spamEmailCount 6 } 7 ); 8 barChart.SetTitle("Ham vs. Spam in Sample Set");View Code
使用Accord.Net中的DataBarBox類,我們可以很容易地在柱狀圖中可視化資料,現在讓我們來看看在ham和spam郵件中出現頻率最高的十個詞,可以使用下面的代碼來為ham和spam郵件中排名前十的術語生成柱狀圖:
1 var hamBarChart = DataBarBox.Show( 2 topHamTerms.ToArray(), 3 new double[][] { 4 topHamTermsProportions.ToArray(), 5 spamTermProportions.GetItems(topHamTerms).Values.ToArray() 6 } 7 ); 8 hamBarChart.SetTitle("Top 10 Terms in Ham Emails (blue: HAM, red: SPAM)"); 9 System.Threading.Thread.Sleep(3000); 10 hamBarChart.Invoke( 11 new Action(() => 12 { 13 hamBarChart.Size = new System.Drawing.Size(5000, 1500); 14 }) 15 ); 16 17 var spamBarChart = DataBarBox.Show( 18 topSpamTerms.ToArray(), 19 new double[][] { 20 hamTermProportions.GetItems(topSpamTerms).Values.ToArray(), 21 topSpamTermsProportions.ToArray() 22 } 23 ); 24 spamBarChart.SetTitle("Top 10 Terms in Spam Emails (blue: HAM, red: SPAM)");View Code
類似地,我們使用DataBarBox類來顯示條形圖,當運行這段代碼時,我們將看到下面的圖,其中顯示了在ham電子郵件中出現頻率最高的10個術語:

spam郵件中最常出現的十大術語的柱狀圖如下:
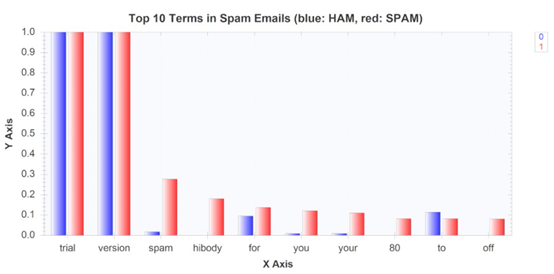
正如所料,垃圾郵件中的單詞分布與非垃圾郵件有很大的不同,例如,如果你看一下上上邊的圖表,spam和hibody這兩個詞在垃圾郵件中出現的頻率很高,但在非垃圾郵件中出現的頻率不高,然而,有些事情并沒有多大意義,如果你仔細觀察,你會發現所有的垃圾郵件和非垃圾郵件都有trial和version這兩個單詞,是不太可能的,如果你在文本編輯器中打開一些原始的EML檔案,你會很容易發現并不是所有的電子郵件的標題行都包含這兩個詞,
那么,到底發生了什么?我們的資料是否被之前的資料準備或資料分析步驟污染了?
進一步的研究表明,我們使用的其中一個軟體包導致了這個問題,我們用來加載和提取電子郵件內容的EAGetMail包在使用其試用版本時,會自動將(Trial Version)附加到主題行末尾,現在我們知道了這個資料問題的根本原因,我們需要回去修復它,一種解決方案是回傳到資料準備步驟,用以下代碼更新ParseEmails函式,它只是從主題行洗掉附加的(Trial Version)標志:
1 private static Frame<int, string> ParseEmails(string[] files) 2 { 3 // 我們將決議每個電子郵件的主題和正文,并將每個記錄存盤到鍵值對中 4 var rows = files.AsEnumerable().Select((x, i) => 5 { 6 // 將每個電子郵件檔案加載到郵件物件中 7 Mail email = new Mail("TryIt"); 8 email.Load(x, false); 9 10 // 提取主題和正文 11 string EATrialVersionRemark = "(Trial Version)"; // EAGetMail在試用版本中附加主題“(試用版本)” 12 string emailSubject = email.Subject.EndsWith(EATrialVersionRemark) ? 13 email.Subject.Substring(0, email.Subject.Length - EATrialVersionRemark.Length) : email.Subject; 14 string textBody = email.TextBody; 15 16 // 使用電子郵件id (emailNum)、主題和正文創建鍵-值對 17 return new { emailNum = i, subject = emailSubject, body = textBody }; 18 }); 19 20 // 根據上面創建的行創建一個資料幀 21 return Frame.FromRecords(rows); 22 }View Code
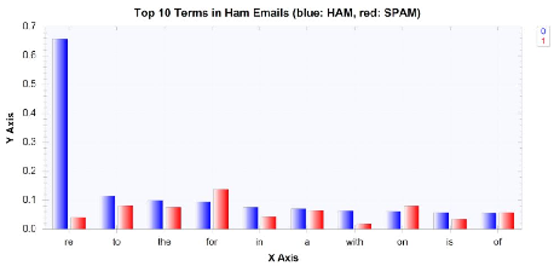
在更新了這段代碼并再次運行之前的資料準備和分析代碼之后,word分布的柱狀圖就更有意義了,
下面的條形圖顯示了修復和洗掉(Trial Version)標記后,ham郵件中出現頻率最高的10個術語:
下面的條形圖顯示了修復和洗掉(Trial Version)標志后spam郵件中出現頻率最高的10個術語

這是一個很好的例子,說明了在構建ML模型時資料分析步驟的重要性,在資料準備和資料分析步驟之間進行迭代是非常常見的,因為我們通常會在分析步驟中發現資料的問題,通常我們可以通過更新資料準備步驟中使用的一些代碼來提高資料質量,現在,我們已經有了主題行中使用的單詞的矩陣表示形式的清晰資料,是時候開始研究我們將用于構建ML模型的實際特性了,
構建資料的特征
在前面的步驟中,我們簡要地查看了垃圾郵件和非垃圾郵件的單詞分類,我們注意到了一些事情,首先,大量的最頻繁出現的單詞是經常使用的單詞,沒有什么意義,例如,像to、the、For和a這樣的單詞是常用的單詞,而我們的ML演算法不會從這些單詞中學到什么,這些型別的單詞被稱為停止單詞,它們經常被忽略或從功能集中洗掉,我們將使用NLTK的停止單詞串列從功能集中過濾出常用的單詞,
過濾這些停止字的一種方法是如下代碼所示:
1 //讀停詞表 2 ISet<string> stopWords = new HashSet<string>(File.ReadLines(<path-to-your-stopwords.txt>); 3 //從詞頻序列中過濾出停止詞 4 var spamTermFrequenciesAfterStopWords = spamTermFrequencies.Where( 5 x => !stopWords.Contains(x.Key) 6 );View Code
經過濾后,非垃圾郵件常出現的十大新詞語如下:
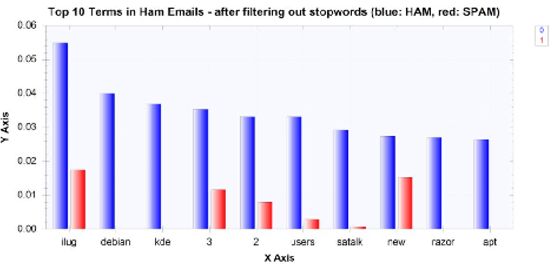
過濾掉停止詞后,垃圾郵件最常出現的十大詞語如下:
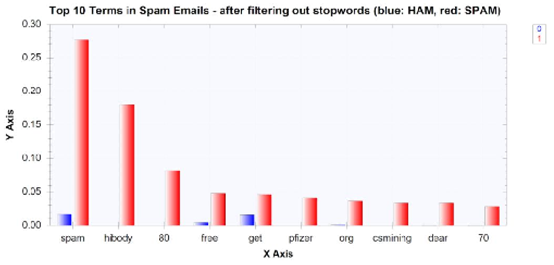
從這些柱狀圖中可以看出,過濾掉特性集中的停止詞,使得更有意義的詞出現在頻繁出現的單詞串列的頂部,然而,我們還注意到一件事,數字似乎是最常出現的單詞之一,例如,數字3和2進入了非垃圾郵件中出現頻率最高的10個單詞,數字80和70進入了垃圾郵件中出現頻率最高的10個單詞,然而,很難確定這些數字是否有助于訓練ML模型將電子郵件歸類為垃圾郵件或垃圾郵件,
有多種方法可以從特性集中過濾掉這些數字,但是我們將只在這里展示一種方法,我們更新了上一步中使用的正則運算式,以匹配只包含字母字符而不包含字母數字字符的單詞,下面的代碼展示了我們如何更新CreateWordVec函式來過濾掉特性集中的數字,
1 private static Frame<int, string> CreateWordVec(Series<int, string> rows) 2 { 3 var wordsByRows = rows.GetAllValues() 4 .Select((x, i) => 5 { 6 var sb = new SeriesBuilder<string, int>(); 7 ISet<string> words = new HashSet<string>( 8 //僅字母字符 9 Regex.Matches(x.Value, "[a-zA-Z]+('(s|d|t|ve|m))?") 10 .Cast<Match>() 11 //然后,將每個單詞轉換為小寫字母 12 .Select(y => y.Value.ToLower()) 13 .ToArray() 14 ); 15 //對每行出現的單詞進行1的編碼 16 foreach (string w in words) 17 { 18 sb.Add(w, 1); 19 } 20 return KeyValue.Create(i, sb.Series); 21 }); 22 //從我們剛剛創建的行中創建一個資料幀,并用0對缺失的值進行編碼 23 var wordVecDF = Frame.FromRows(wordsByRows).FillMissing(0); 24 return wordVecDF; 25 }View Code
一旦我們從功能集過濾掉這些數字,非垃圾郵件的單詞分布如下:
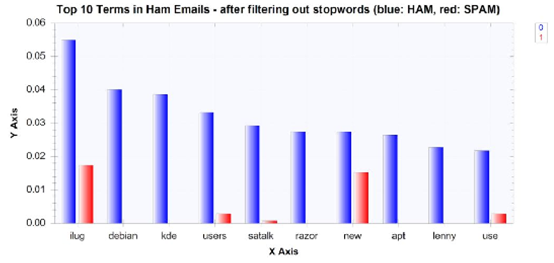
而垃圾郵件的單詞分布,在過濾掉來自功能集的數字后,看起來像這樣:
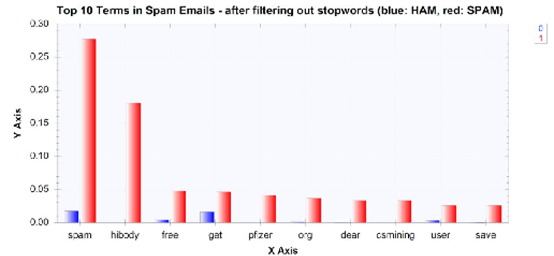
可以從這些柱狀圖中看到,我們有更多的有意義的詞在頂部的名單上,這似乎和之前有一個很大的區別,在垃圾郵件和非垃圾郵件的單詞分布,那些經常出現在垃圾郵件中的單詞在非垃圾郵件中似乎并不多見,反之亦然,
一旦您運行這段代碼時,它將生成柱狀圖顯示垃圾郵件單詞分布和非垃圾郵件和兩個單詞串列的CSV files-one非垃圾郵件與相應項出現和另一個電子郵件在垃圾郵件單詞串列和相應的項出現,在下面的模型構建部分中,當我們為垃圾郵件過濾構建分類模型時,我們將使用這個術語頻率輸出來進行特征選擇程序,
邏輯回歸與樸素貝葉斯的Email垃圾郵件過濾
我們已經走了很長的路,最終在c#中構建了我們的第一個ML模型,在本節中,我們將訓練邏輯回歸和樸素貝葉斯分類器來將電子郵件分為垃圾郵件和非垃圾郵件,我們將使用這兩種學習演算法來進行交叉驗證,以更好地了解我們的分類模型在實踐中的表現,如前一章所簡要討論的,在k-fold交叉驗證中,訓練集被劃分為k個大小相等的子集,其中一個子集作為驗證集,其余的k-1子集用于訓練模型,然后重復這個程序k次,在每次迭代中使用不同的子集或折疊作為測驗的驗證集,然后對相應的k驗證結果求平均值以報告單個估計,
讓我們首先看看如何使用Accord在c#中用邏輯回歸來實體化交叉驗證演算法,代碼如下:
1 var cvLogisticRegressionClassifier = CrossValidation.Create<LogisticRegression, 2 IterativeReweightedLeastSquares<LogisticRegression>, double[], int>( 3 // 折疊數量 4 k: numFolds, 5 // 學習演算法 6 learner: (p) => new IterativeReweightedLeastSquares<LogisticRegression>() 7 { 8 MaxIterations = 100, 9 Regularization = 1e-6 10 }, 11 // 使用0 - 1損失函式作為成本函式 12 loss: (actual, expected, p) => new ZeroOneLoss(expected).Loss(actual), 13 // 合適的分類器 14 fit: (teacher, x, y, w) => teacher.Learn(x, y, w), 15 // 輸入 16 x: input, 17 // 輸出 18 y: output 19 ); 20 // 運行交叉驗證 21 var result = cvLogisticRegressionClassifier.Learn(input, output);View Code
讓我們更深入地看看這段代碼,通過提供要訓練的模型型別、適合模型的學習演算法型別、輸入資料型別和輸出資料型別,我們可以使用靜態create函式創建一個新的交叉驗證演算法,對于這個例子,我們創建了一個新的交叉驗證演算法,以邏輯回歸為模型,以IterativeReweightedLeastSquares作為學習演算法,以雙陣列作為輸入型別,以整數作為輸出型別(每個標簽),您可以嘗試使用不同的學習演算法來訓練邏輯回歸模型,在協議,您可以選擇使用隨機梯度下降演算法(LogisticGradientDescent)作為適合邏輯回歸模型的學習演算法,
對于引數,我們可以為k-fold交叉驗證(k)、帶有自定義引數的學習方法(learner)、選擇的損失/成本函式(loss)和一個知道如何使用學習演算法(fit)來擬合模型的函式(x)、輸入(x)和輸出(y)指定折疊數,為了在本節中進行說明,我們為k-fold交叉驗證設定了一個相對較小的數字3,此外,對于最大的迭代,我們選擇了一個相對較小的數字,100,而對于迭代加權最小二乘學習演算法的正則化,我們選擇了一個相對較大的數字,le-6或1/1,000,000,對于損耗函式,我們使用一個簡單的0 - 1損耗函式,它為正確的預測分配0,為錯誤的預測分配1,這就是我們的學習演算法試圖最小化的代價函式,所有這些引數都可以進行不同的調優,我們可以選擇一個不同的損耗/成本函式,k折疊交叉驗證中使用的折疊數,以及學習演算法的最大迭代次數和正則化次數,我們甚至可以使用不同的學習演算法來適應邏輯回歸模型,比如LogisticGradientDescent,它將迭代地嘗試找到損失函式的區域最小值,
我們可以用同樣的方法訓練樸素貝葉斯分類器,用k次交叉驗證,使用樸素貝葉斯學習演算法進行k-fold交叉驗證的代碼如下:
1 var cvNaiveBayesClassifier = CrossValidation.Create<NaiveBayes<BernoulliDistribution>, 2 NaiveBayesLearning<BernoulliDistribution>, double[], int>( 3 // 折疊的數量 4 k: numFolds, 5 // 二項分布的樸素貝葉斯分類器 6 learner: (p) => new NaiveBayesLearning<BernoulliDistribution>(), 7 // 使用0 - 1損失函式作為成本函式 8 loss: (actual, expected, p) => new ZeroOneLoss(expected).Loss(actual), 9 // 合適的分類器 10 fit: (teacher, x, y, w) => teacher.Learn(x, y, w), 11 // 輸入 12 x: input, 13 // 輸出 14 y: output 15 ); 16 // 運行交叉驗證 17 var result = cvNaiveBayesClassifier.Learn(input, output);View Code
之前的邏輯回歸模型代碼與這段代碼的唯一區別是我們選擇的模型和學習演算法,我們使用NaiveBayes作為模型,NaiveBayesLearning作為學習演算法來訓練我們的NaiveBayes分類器,而不是使用LogisticRegression和IterativeReweightedLeastSquares,由于所有的輸入值都是二進制的(0或1),所以我們使用BernoulliDistribution作為我們的樸素Byes分類器模型,
當你運行這段代碼,你應該看到一個輸出如下:
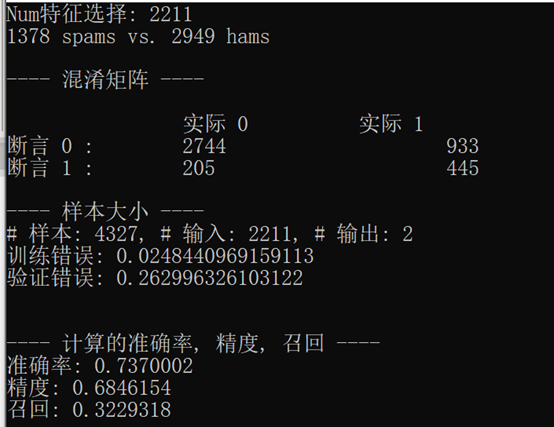
在下面討論模型驗證方法的小節中,我們將進一步研究這些數字所代表的內容,為了嘗試不同的ML模型,可以使用我們前面討論過的邏輯回歸模型代碼來替換它們,或者也可以嘗試選擇不同的學習演算法使用,
驗證分類模型
我們使用Accord.Net Framework在c#中建立了第一個ML模型,然而,我們還沒有完全完成,如果我們更仔細地查看以前的控制臺輸出,就會發現有一件事非常令人擔憂的情形,訓練誤差約為0.03,而驗證誤差約為0.26,這意味著我們的分類模型在訓練集中正確預測了100次中的87次,而在驗證或測驗集中正確預測了100次中的74次,這是一個典型的過度擬合的例子,其中模型與訓練集非常接近,以至于它對未預見資料集的預測是不可靠和不可預測的,如果我們將這個模型應用到垃圾郵件過濾系統中,那么實際用于過濾垃圾郵件的模型性能將是不可靠的,并且會與我們在訓練集中看到的有所不同,
過度擬合通常是因為模型對于給定的資料集來說太復雜,或者使用了太多的引數來擬合模型,我們在上一節中建立的樸素貝葉斯分類器模型的過擬合問題很可能是由于我們用來訓練模型的復雜性和特征的數量,
如果再次查看上一節末尾的控制臺輸出,我們可以看到用于訓練樸素貝葉斯模型的特性的數量是2,212,這太多了,考慮到我們只有約4200封電子郵件記錄,在我們的樣本集只有三分之二(或大約3000條記錄)被用來訓練我們的模型(這是因為我們使用三倍交叉驗證,只有兩三個折疊用作訓練集在每個迭代),為了解決這個過擬合問題,我們必須減少用于訓練模型的特性的數量,為了做到這一點,我們可以過濾掉那些不經常出現的項,完成此任務的代碼,如下所示:
1 // 改變特征的數量以減少過度擬合 2 int minNumOccurences = 1; 3 string[] wordFeatures = indexedSpamTermFrequencyDF.Where( 4 x => x.Value.GetAs<int>("num_occurences") >= minNumOccurences 5 ).RowKeys.ToArray(); 6 Console.WriteLine("Num特征選擇: {0}", wordFeatures.Count());View Code
從這段代碼可以看出,我們在前一節中構建的Naive Bayes分類器模型至少使用了垃圾郵件中出現的所有單詞,
如果我們查看垃圾郵件中的單詞頻率,大約有1400個單詞只出現一次(查看在資料分析步驟中創建的spam-frequencies.csv檔案),直觀地說,那些出現次數少的單詞只會產生噪音,對我們的模型來說沒有多少資訊可以學習,這告訴我們,當我們在前一節中最初構建分類模型時,我們的模型將暴露在多少噪聲中,
現在我們知道了這個過度擬合問題的原因,讓我們來修復它,讓我們用不同的閾值來選擇特征,我們已經嘗試了5、10、15、20和25,以使垃圾郵件中出現的次數最少(也就是說,我們將minNumOccurrences設定為5、10、15等等),并使用這些閾值訓練Naive Bayes分類器,
首先,樸素貝葉斯分類器的結果至少出現5次,如下圖所示:
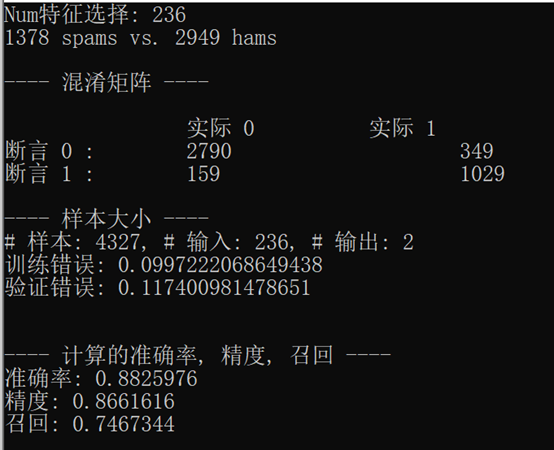
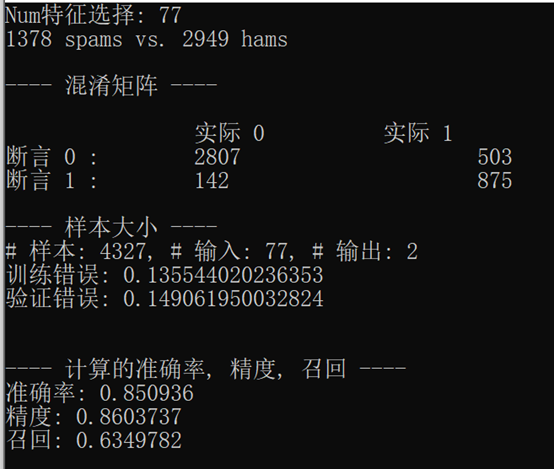
首先,樸素貝葉斯分類器的結果至少出現10次,如下圖所示:
首先,樸素貝葉斯分類器的結果至少出現15次,如下圖所示:

首先,樸素貝葉斯分類器的結果至少出現20次,如下圖所示:
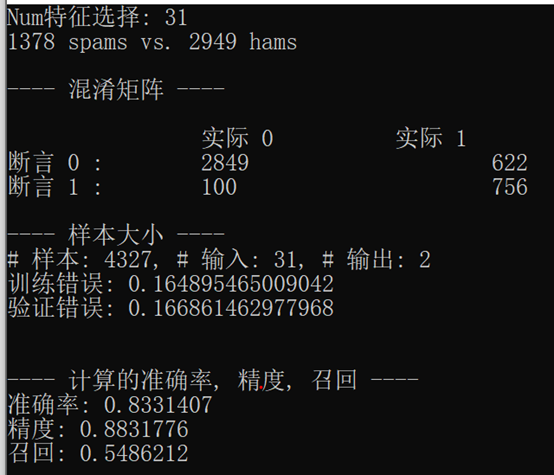
從這些實驗結果可以看到,當我們增加了最小數量的單詞出現次數和減少相應的特性數量用來訓練模型, 訓練誤差與驗證誤差之間的差距減小,訓練誤差開始與驗證誤差近似,當我們解決過擬合問題時,我們可以更加確信模型將如何處理未預見的資料和生產系統,
現在我們已經介紹了如何處理過擬合問題,我們希望看看更多的模型性能度量工具:
Confusion matrix(混淆矩陣): 混淆矩陣是一個表,它告訴我們預測模型的整體性能,每一串列示每個實際類,每一行表示每個預測類,對于二元分類問題,混淆矩陣是一個2×2的矩陣,其中第一行表示消極預測,第二行表示積極預測,第一串列示實際的否定,第二串列示實際的肯定,下表說明了一個二元分類問題的混淆矩陣中的每個單元格代表什么,
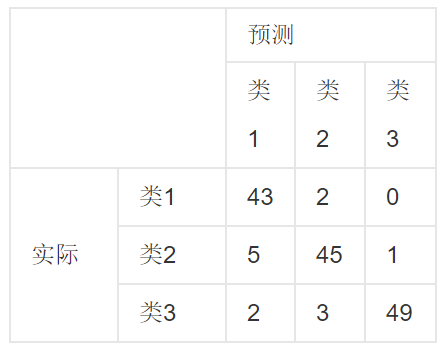
True Negative (TN) :
TP、True Positive 真陽性:預測為正,實際也為正
FP、False Positive 假陽性:預測為正,實際為負
FN、False Negative 假陰性:預測與負、實際為正
TN、True Negative 真陰性:預測為負、實際也為負,
從表中可以看出,混淆矩陣描述了整個模型的性能,在我們的例子中,如果我們看最后一個控制臺輸出在前面的螢屏截圖,顯示了控制臺輸出的邏輯回歸分類模型中,我們可以看到,TNs的數量是2847,fn的數量是606,FPs的數量是102,和76 tps的數量是772,根據這些資訊,我們可以進一步計算真實陽性率(TPR)、真實負性率(TNR)、假陽性率(FPR)和假陰性率(FNR),如下:
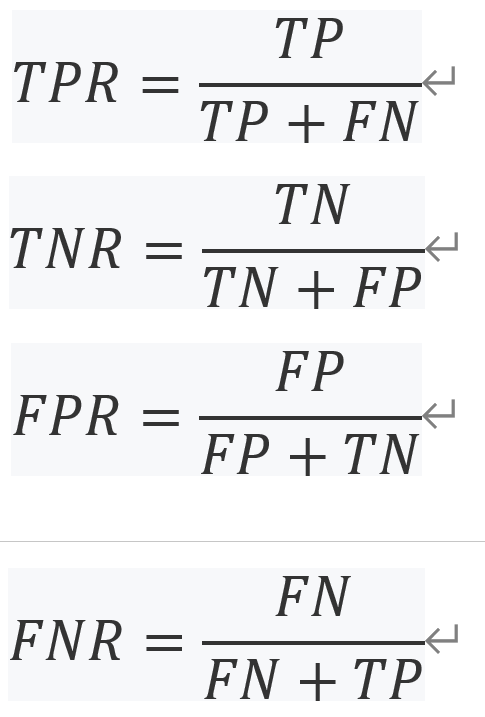
使用前面的例子,我們例子中的真實陽性率是0.56,TNR是0.97,FPR是0.03,FNR是0.44
Accuracy(準確性):準確性是正確預測的比例,使用與前面示例混淆矩陣相同的表示法,計算精度如下:
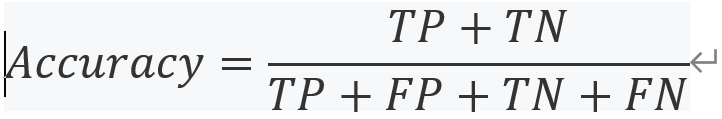
準確性是一個經常使用的模型性能指標,但有時它并不能很好地代表整個模型的性能,例如,如果樣本集很大程度上是不平衡的,并且,假設在我們的樣本集中有5封垃圾郵件和95潭訓腿,那么一個簡單的分類器將每封郵件都歸類為火腿,那么它必須有95%的準確率,然而,它永遠不會捕捉垃圾郵件,這就是為什么我們需要查看混亂矩陣和其他性能指標,如精度和正確率
Precision rate(精度):精度是正確的正面預測數量占全部正面預測數量的比例,使用與之前相同的符號,我們可以計算出精度率如下:
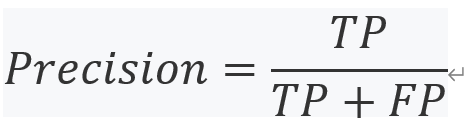
如果看看過去的控制臺輸出之前的截圖的邏輯回歸分類模型結果,精確率計算的數量除以TPs混淆矩陣,772年,由TPs的總和,FPs, 102年,772年從混淆矩陣,結果是0.88,
Recall rate(召回率):正確率是正確正面預測的數量占實際陽性總數的比例,這是告訴我們有多少實際的積極案例是由這個模型檢索到的一種方式,使用與前面相同的符號,我們可以計算召回率,如下所示:
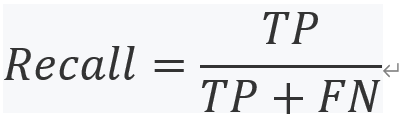
如果看看過去的控制臺輸出在前面的截圖為我們的邏輯回歸分類模式的結果,正確率計算的數量除以TPs混淆矩陣,通過TPs的總和,772年,772年和fn, 606年,混淆矩陣,其結果是0.56,
有了這些性能指標,我們就可以選擇最佳模型,在精度和正確率之間總是存在權衡,與其他模型相比,具有較高準確率的模型召回率較低,對于我們的垃圾郵件過濾問題,如果認為正確地過濾垃圾郵件更重要,并且可以犧牲一些通過用戶收件箱的垃圾郵件,那么我們可以優化精度,另一方面,如果認為過濾掉盡可能多的垃圾郵件更重要,即使我們可能會過濾掉一些非垃圾郵件,那么可以優化正確率,選擇正確的模型不是一個簡單的決定,仔細考慮需求和成功標準是做出正確選擇的關鍵,
總之,下面是我們可以用來從交叉驗證結果和混淆矩陣中計算性能指標的代碼:
1 // 運行交叉驗證 2 var result = cvNaiveBayesClassifier.Learn(input, output); 3 // 訓練錯誤 4 double trainingError = result.Training.Mean; 5 //驗證錯誤 6 double validationError = result.Validation.Mean; 7 混淆矩陣:真陽性與假陽性和真陰性與假陰性: 8 // 混淆矩陣 9 GeneralConfusionMatrix gcm = result.ToConfusionMatrix(input, output); 10 float truePositive = (float)gcm.Matrix[1, 1]; 11 float trueNegative = (float)gcm.Matrix[0, 0]; 12 float falsePositive = (float)gcm.Matrix[1, 0]; 13 float falseNegative = (float)gcm.Matrix[0, 1];View Code
訓練與驗證(測驗)錯誤:用于識別過擬合問題:
1 // 計算的準確率, 精度, 召回 2 float accuracy = (truePositive + trueNegative) / numberOfSamples; 3 float precision = truePositive / (truePositive + falsePositive); 4 float recall = truePositive / (truePositive + falseNegative);View Code
總結
在本章中,我們用c#構建了第一個可以用于垃圾郵件過濾的ML模型,我們首先定義并清楚地說明我們要解決的問題以及成功的標準,然后,我們從原始郵件資料中提取相關資訊,并將其轉換為一種格式,用于資料分析、特征工程和ML模型構建步驟,
在資料分析步驟中,我們學習了如何應用單一熱編碼并構建主題行中使用的單詞的矩陣表示,
我們還從資料分析程序中發現了一個資料問題,并了解了如何在資料準備和分析步驟之間來回迭代,
然后,我們進一步改進了我們的特性集,過濾掉停止單詞,并使用正則運算式將非字母數字或非字母單詞分隔開,
有了這個特征集,我們使用邏輯回歸和樸素貝葉斯分類器演算法建立了第一個分類模型,簡要介紹了過度擬合的危險,并學習了如何通過觀察準確性、精度和召回率來評估和比較模型性能,
最后,我們還學習了精度和召回之間的權衡,以及如何根據這些度量和業務需求選擇模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/net/79112.html
標籤:C#
上一篇:專案用到WebBrowser訪問頁面生成快照,訪問的頁面需要身份登錄,麻煩問下有沒有什么方法能把身份登錄注入進去呢
下一篇:ihandy2019筆記編程真題