目錄
- 概述
- 直接看東西
- 被廣泛使用的倉儲
- 倉儲是反模式嗎
- 什么是存盤庫
- 如何運用存盤庫
- 存盤庫是為聚合提供操作
- 存盤庫對外提供哪些方法
- 存盤庫是一個明確的約定
- 審計追蹤
- 匯總
- 不要使用過多特性干擾您的領域物件
- 不要為了顯示而使用存盤庫
- 作業單元
- 持久化中的困難
- 總結
概述
在上一篇文章中,我們已經了解過領域驅動設計中一個很核心的物件-聚合,在現實場景中,我們往往需要將聚合持久化到某個地方,或者是從某個地方創建出聚合,此時就會使得領域物件與我們的基礎架構產生緊密的耦合,那么我們應該怎么隔絕這一層耦合關系,使它們自身的職責界限更加清晰呢?是的,這就要用到我們今天要講的內容 - 存盤庫,在很多地方,我們喜歡叫它為倉儲,特別是在現有的AspNetCore應用中,大量的應用都在引入Repository這種東西,那么究竟什么是存盤庫呢?我們現在的使用方式是正確的嗎?它在領域驅動設計中又扮演著怎樣的角色呢?本文將從不同的角度來帶大家重新認識一下“存盤庫”這個概念,并且給出相應的代碼片段(本教程的代碼片段都使用的是C#,后期的實戰專案也是基于 DotNet Core 平臺),
直接看東西

“少啰嗦,直接看東西”,是的,在本次的文章中,居然!居然!居然! 附帶了Github的代碼,本次代碼其實是演示作業單元的實作,但是它確實又結合了存盤庫的一些內容,所以就在這里提供給大家參考,
GitHub 地址,點擊直達喲
這是一個作業單元的超簡易版本,您可以在github中看到它的描述和簡介,這里我就不再重復了,下一次的文章會對作業單元的實作進行決議和優化,可能它就不屬于 《如何運用領域驅動設計》 系列的正傳系列了(算個番外吧 ( ̄▽ ̄)"),所以為了您不錯過這一部分,可以點擊博客園右上角的關注,有了動態之后就能夠第一時間收到啦!
哦,對了!在Github代碼中,您可能會看到一個叫做MiCake(米蛋糕)的東西,它是我們一步一步實作的DDD組件,它會讓您的 aspnet core 應用更輕松的融合DDD的思想,并且它包含了我們該系列博文中所提到的所有戰略組件,以及它們之間的約束和處理,
被廣泛使用的倉儲
是的,說存盤庫模式您可能還不能一下想到這是個什么東西,但是一說到倉儲,您可能就會有一種豁然開朗的感覺:“哦!就是這個東西呀!”,回顧一下,您現有的AspNet Core專案,是否已經引入了一個叫做Repository的物件,并且它為您提供了與資料基礎架構互動的方法,
仿佛從某一天開始,以往我們使用的BLL,DLL這種東西就逐漸開始消失了,替換它們的是一個叫做Repository的東西,特別是從傳統的AspNet演化為AspNetCore的階段,大量的應用都開始使用倉儲了,即使您在使用類似于EF這樣的ORM框架,
倉儲是反模式嗎
關于存盤厙模式存在非常多的誤解和混淆,許多人認為它是多余的儀式以及不必要的抽象,它隱藏了底層持久化框架的能力,特別是當您正在使用類似于Entity FrameWork Core這樣的ORM框架的時候,您是否發現明明EFCore直接就可以實作的東西,為什么我又在它的基礎上套了一層,而且這一層中我并沒有執行任何邏輯,只是簡單的呼叫DbContext(EF中的資料背景關系)這種東西,那為什么我不能直接呼叫DbContext呢?是的,這樣的疑問相信不止很多同學都遇到了,所以在微軟EF Core 3.x的官方教程中,提到了這樣的一句話:

該內容位于 ASP.NET Core 官方教程 - 資料訪問 - 高級教程 中,
那么我們真的不需要存盤庫這種東西嗎?答案是否定的,至少在實踐領域驅動設計的應用中,還記得在上一篇文章 如何運用領域驅動設計 - 聚合 中,我們不止一次的提到了倉儲這個概念,因為它是為聚合而服務的,而隨著領域的深入,使得領域模型越來越復雜的時候,存盤庫將慢慢變成模型的擴展,它將描述您每一個用例檢索聚合的意圖,
思考一下,您現有的應用中是否包含了一個全能的ORM框架(比如EF),那您引入倉儲的原因是什么呢?
什么是存盤庫
好吧,這次的開篇太長了,終于回到了正題:什么是存盤庫? 原著《領域驅動設計:軟體核心復雜性應對之道》 中對存盤庫的有關解釋:
為每種需要全域訪問的物件型別創建一個物件,這個物件就相當于該型別的所有物件在記憶體中的一個集合的“替身”,通過一個眾所周知的介面來提供訪問,提供添加和洗掉物件的方法,用這些方法來封裝在資料存盤中實際插入或洗掉資料的操作,提供根據具體標準來挑選物件的方法,并回傳屬性值滿足查詢標準的物件或物件集合(所回傳的物件是完全實體化的),從而將實際的存盤和查詢技術封裝起來,只為那些確實需要直接訪問的Aggregate提供Repository,讓客戶始終聚焦于型,而將所有物件存盤和訪問操作交給Repository來完成,
國際慣例,讓我們來看看這一段話大致講了什么,Repository提供了一個增刪改查的操作,它抽象了資料訪問的部分,是的,這個理解是很正確的,因為這是存盤庫很重要的特性,所以有很多同學就開始瘋狂的使用存盤庫了,在專案中大量的引入Repository,而嵌套于ORM之上,
但是!!!!! 我們忽略了上面的其它幾點:“確實需要直接訪問的Aggregate提供Repository” ,“提供根據具體標準來挑選物件” , 注意,這很重要,下文將一一為大家解釋,
如何運用存盤庫
存盤庫是為聚合提供操作
這一點是非常關鍵的,存盤庫是為聚合而服務的,有關于聚合的部分,可以查看上一篇文章 如何運用領域驅動設計 - 聚合,為什么呢它一定要為聚合服務? 它不能為物體服務嗎? 因為聚合是一個整體,在上一文中我們已經說過了,當凝練出一個聚合根的時候,就證明外界只能通過聚合根來訪問聚合內的物體,所以我們沒有理由在任何一個地方需要穿透聚合根去訪問物體,這是錯誤并且沒有意義的,那么很自然的就可以衍生出:我們什么時候需要使用存盤庫單獨來提取物體呢?好像確實沒有,不過有的同學會說了,我在做**報表的時候,我就確實需要只訪問某個物體呀?那么請思考兩個點:1、該物體是否需要提升為聚合根, 2、如果是廣泛查詢的報表,可能并不需要通過倉儲來獲取物件,需要專門的查詢框架來完成,
因此,我們建立出來的倉儲的介面可能是這個樣子的:
public interface IRepository<TAggregateRoot>
where TAggregateRoot : class, IAggregateRoot
{
}
此處使用了C#的介面泛型約束,將倉儲的服務者約束為了一個聚合根,該代碼在上文介紹的 MiCake 中您也可以看到,
存盤庫對外提供哪些方法
到目前為止,我們已經知道一個存盤庫至少應該包含根據ID來對聚合的增刪改查方法,可能有一些時候我們只需要查,不需要刪,但是就一個通用的存盤庫來說,它能具有這些方法是毫無疑問的,所以我們的倉儲介面可以增加一些通用方法:
public interface IRepository<TAggregateRoot>
where TAggregateRoot : class, IAggregateRoot
{
TAggregateRoot Find(TKey Id);
void Add(TAggregateRoot aggregateRoot);
void Update(TAggregateRoot aggregateRoot);
void Delete(TAggregateRoot aggregateRoot);
}
存盤庫是一個明確的約定
雖然存盤庫提供了基礎的提取方法,但是在許多場景下,我們可能更需要根據某種條件來從資料庫中讀取對應的模型并將其轉換為領域聚合物件,比如在之前的一篇文章 如何運用領域驅動設計 - 領域服務 中就有一個地方出現了使用存盤庫的情況:我們需要根據當前的位置來查找附近的飯店:
var nearbyRestaurants = restaurantRepository.GetNearbyRestaurant(currentAddress);
采用了類似于這樣的寫法,該存盤庫對外提供了一個GetNearbyRestaurant的方法出來,外界的應用服務就可以通過該方法來獲取對應的結果,
這是一個很好的方法簽名,我們通過傳入一個當前位置就能夠獲取到附近的飯店,通過閱讀存盤庫提供出來的方法就能理解領域中的檢索意圖,從側面也反應了領域的某些用例,
但是,現在有部分的同學熱愛另外一種寫法:通過Lambda作為方法引數,傳遞給下層的ORM框架來進行查詢,該方法簽名類似于這樣:
IQueryable<TEntity> FindMatch(params Expression<Func<TEntity, object>>[] propertySelectors);
這樣做的好處是所有的存盤庫都可以復用這個介面,以后所有的查詢都可以通過使用該方來來完成,而不需要再去單獨寫各種Find方法,通過回傳一個IQueryable物件,甚至可以將業務查詢邏輯直接放到應用層,這樣想怎么操作就怎么操作,
請注意!!!這非常的危險!!!! 您可能會問了:“我平時所接觸的框架或者倉儲不都是這樣寫的嗎?可以實作我任何的業務查詢,爽歪歪,” 但是這樣寫正在逐漸喪失存盤庫原有的作用,回到開篇提到的一個問題:假如使用了EF這樣的ORM框架,為什么還需要嵌套一層倉儲呢? 而現在,您可能正在這樣做,開放且靈活的約定,再加上延遲的IQueryable物件,讓倉儲層完全喪失了原有的作用,它反而成了負擔,為什么不直接使用DbContext物件呢? 為了倉儲而使用倉儲,為了看上去像DDD而DDD,那不是自己騙自己嗎?
所以請盡量避免在您的存盤庫中去寫這種靈活而沒有任何明確檢索意圖的方法介面,它可能確實會使您減少代碼書寫量,但隨著專案的復雜和領域物件的逐漸增多,它會使您的應用層越來越迷惑,所以存盤庫中所提供的應該是具有明確約定的方法,
這里我摘抄了 領域驅動設計模式、原理與實踐 中的一段話,我覺得它的描述非常好:
存盤庫不是一個物件,它是一個程式邊界以及一個明確的約定,在其上命名方法時它需要的作業量與領域模型中的物件所需的作業量一樣多,你的存盤庫約定應該是特定的以及能夠揭示意圖并對領域專家具有意義,
具有領域意圖的東西我們都應該領域層,而類似于資料庫的訪問實作這類基礎架構應該放在基礎設施層,所以可以看出我們抽象出來的倉儲介面是應該放在領域層的,而倉儲的實作可以放在基礎設施層 ,這個問題有很多小伙伴可能迷惑了很久,我上次看到一位同學將倉儲介面放在了應用層,因為它認為和領域無關,認為倉儲只是一個提供增刪改查的東西,而這也是因為忽略了倉儲也是領域行為的一部分的結果,
審計追蹤
在前面講值物件的文章中,有一位園友問了我一個問題,有一點是:類似于CreateDate,CreateUser這種審計資訊,我們許多時候都會依附在領域物件身上,那么是不是應該通過領域服務來做處理呢?
其實不然,它們雖然對我們有參考意義,其實并沒有在捕獲領域需求時捕獲出來,往往這類審計資訊都是我們按照以往的開發經驗所提煉出來的,所以它們對領域物件的影響很小,那么我們又很需要去操作它們,比如持久化一個聚合根的時候,為它附帶上創建時間,這樣便于我們去追蹤它的一些記錄,而此時,就可以依賴我們的存盤庫來完成了,當聚合根在領域服務或者領域用例中已經完成了操作時,將它傳遞給存盤庫持久化之前就可以讓存盤庫為它加上審計資訊,
匯總
存盤庫有時還可以擁有對集合匯總的功能,比如上面我們提到了飯店的一個倉儲,可能我們在系統中想得到我系統中到底有多少個飯店,或者在某個區域有多少個飯店,這種匯總的功能您也可以交給存盤庫來完成,這也完美的符合“存盤庫”中“庫”的含義,但還是請注意,這些匯總的方法依然得擁有一個明確的約定格式,不要因為是匯總就將存盤庫寫的開放而過于靈活,
有時候您可能需要形成一個報表,該報表它包含了各個領域物件的匯總情況,在此時,該匯總的職責可能并不屬于存盤庫了,它需要您使用另外的方式來完成,該內容可以看下面的小節,
不要使用過多特性干擾您的領域物件
在持久化的程序中,現在的主流方式我們都會依賴于類似于EF Core這樣的ORM框架來完成,當我們需要將領域物件轉換為資料庫的資料物件(可以理解為表吧)時,可能有時候就需要表明什么是主鍵,什么具有約束等情況,如果您正在使用EF Core,對于 Data annotations 您可能再熟悉不過了,它提供了通過特性來標記的寫法完成映射關系:
public class CustomerWithoutNullableReferenceTypes
{
public int Id { get; set; }
[Required] // Data annotations needed to configure as required
public string FirstName { get; set; }
[Required]
public string LastName { get; set; } // Data annotations needed to configure as required
public string MiddleName { get; set; } // Optional by convention
}
該代碼摘自 EF Core 教程 - 必需和可選屬性
這種寫法很誘人,因為只需要簡單的在屬性上增加一個特性就完成了配置,但是!!!這些特性對領域物件其實是沒有必要的,它可能還會干擾您的閱讀,因為我們在構建領域物件的時候不應該考慮資料持久層面的問題,而構建出來的領域物件也應該保持干凈,
在EFCore中,為我們提供了Fluent API的方式來配置模型,該方式可以很好的讓領域物件保持干凈,假如您沒有使用EFCore,另外的ORM框架也一定會為您提供類似于這樣的配置方法,
不要為了顯示而使用存盤庫
很多場景我們可能需要提供一個豐富的界面,或者一個完整的報表,比如在一個界面上顯示了某個聚合中的一個物體的資訊,又或者在報表中提供了各個物體和值物件的匯總和特定資訊,在這個情況下,倉儲可能就顯得有點隆重了,我必須要通過A、B、C……倉儲獲取所有聚合A,B,C,然后再來處理匯總資訊,要么就是將存盤庫的規則打破,直接查詢利用EF Core查詢出IQueryable集合物件,然后一頓輸出猛如虎來達到效果,
記住不要為了使用DDD而讓您的開發變得復雜而不順手,在這個時候我們甚至可以不使用存盤庫,我們可以利用另外的框架來直接查詢資料庫,也或者是使用ADO.NET運用原生Sql來達到查詢的效果,還有一種方法是將查詢單獨劃分為應用系統的一個分支,將修改(命令)單獨劃分為另外一個分支來操作領域物件,這是DDD的另外一種模式,可能您已經聽過它的英文簡寫了:CQRS,該模式的內容會在后期的文章中為大家介紹,MiCake后期也會增加對CQRS的支持,
作業單元
在持久化的程序中,我們必須保證一個聚合的所有的部分一同保持成功,或者一個用例的多個聚合同時保存成功(在分布式中可能只能追求最終一致性),所以我們必須得保證存盤庫是有事務的,而事務的管理是由作業單元來提供的,這也是為什么存盤庫每次都和作業單元這一概念一同出現,下面參考了微軟AspNet中的一張圖,方便您理解作業單元(UnitOfWork):
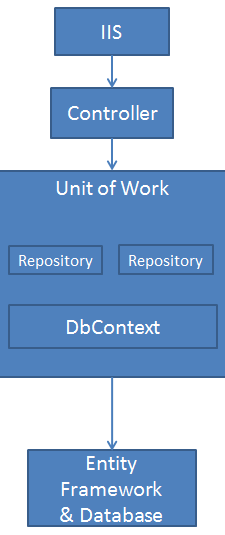
該圖片選取自 微軟 AspNet 教程 - 實作存盤庫和作業單元模式
本章附帶了關于作業單元和倉儲介面的演示代碼,關于作業單元的部分會在下篇文章為大家介紹,
持久化中的困難
關于持久化的問題已經是一個老生常談的話題了,在一篇關于值物件的博文中就已經說明了這個問題,如何將領域物件如何通過ORM來持久化到資料庫?在回答這個問題之前,我們得先理解一下什么是領域模型和資料模型:領域模型是問題域的抽象,富含行為和語言;資料模式是一種包含指定時間領域模型狀態的存盤結構,ORM可以將特定的物件(C#的類)映射到資料模型,資料模型和領域模型無關,存盤庫的作用就是保持這兩個模型的獨立并且不讓它們變得模糊不清,
也就是說我們在設計領域模型時應該僅僅關心領域中的物件,千萬不要讓框架(比如ORM)來驅動你的設計,關于這一點給了我一點靈感:既然我們只關心領域物件,那在持久化的時候能不能單獨建立一個持久化物件專門供ORM去映射到資料庫,而倉儲負責了聚合創建和保存的程序,在這個程序中讓倉儲自動去完成領域物件到持久化物件的轉換就行了,關于這個實作方法,準備在下下一起番外系列中為大家介紹,可能MiCake也會默認支持該方法來完成領域物件的持久化任務,當然,因為是番外的系列,所以為了您不錯過這一部分,可以點擊博客園右上角的關注,( 好吧,我又把上面的話不要臉的又復制了一遍 (? ?_?)?)
總結
本次我們介紹了有關領域驅動設計中“存盤庫”的內容,我們知道了什么是存盤庫,以及如何去使用一個存盤庫,由于存盤庫屬于一個很基礎的概念,所以在該章節中我們沒有使用旅行記賬的案例來為大家介紹,而更多的是希望大家能夠理解使用存盤庫的場景和規范,畢竟現在存盤庫模式是很常用的一個模式,如果只知其然而不知其所以然的去使用存盤庫模式,不僅體驗不到它的益處,反而會讓代碼變得越來越復雜,
最后,提前祝大家元旦快樂, (o?v?)ノ

轉載請註明出處,本文鏈接:https://www.uj5u.com/net/79145.html
標籤:.NET Core