GFS分布式檔案系統
- 一、概述
- 二、作業流程
- 三、卷型別
- 1、分布式卷
- 2、條帶卷
- 3、復制卷
- 4、分布式條帶卷
- 5、分布式復制卷
- 四、部署 GlusterFS 群集
- 1、環境準備
- 2、yum安裝glusterfs軟體
- 3、開啟GlusterFS服務
- 4、配置時間同步
- 5、 添加節點
- 6、創建卷
- (1)創建分布式卷
- (2)創建條帶卷
- (3)創建復制卷
- (4)創建分布式條帶卷
- (5)創建分布式復制卷
- 6、部署客戶端
- 7、驗證資料存盤
- 8、破壞測驗
一、概述
在企業中,一些重要的資料一般存盤在硬碟上,雖然硬碟本身的性能也在不斷提高,但 是無論硬碟的存取速度有多快,企業所追尋的首先是可靠性,然后才是效率,如果資料面臨 丟失的風險,再好的硬體也無法挽回企業的損失,加之近幾年云計算的出現,對存盤提出了更高的要求,而分布式存盤逐漸被人們所接受,它具有更好的性能、高擴展性以及可靠性, 大部分分布式解決方案都是通過元服務器存放目錄結構等元資料,元資料服務器提供了整個分布式存盤的索引作業,但是一旦元資料服務器損壞,整個分布式存盤業將無法作業,
二、作業流程
GlusterFS 的作業流程如下
(1) 客戶端或應用程式通過 GlusterFS 的掛載點訪問資料,
(2) Linux 系統內核通過 VFS API 收到請求并處理,
(3) VFS 將資料遞交給 FUSE 內核檔案系統,并向系統注冊一個實際的檔案系統 FUSE, 而 FUSE 檔案系統則是將資料通過/dev/fuse 設備檔案遞交給了 GlusterFS client 端,可以 將 FUSE 檔案系統理解為一個代理,
(4) GlusterFS client 收到資料后,client 根據組態檔對資料進行處理,
(5) 經過 GlusterFS client 處理后,通過網路將資料傳遞至遠端的 GlusterFS Server, 并且將資料寫入服務器存盤設備
三、卷型別
GlusterFS 支持七種卷,即分布式卷、條帶卷、復制卷、分布式條帶卷、分布式復制卷、 條帶復制卷和分布式條帶復制卷,這七種卷可以滿足不同應用對高性能、高可用的需求,
- 分布式卷(Distribute volume):檔案通過 HASH 演算法分布到所有 Brick Server 上, 這種卷是Glusterf 的基礎;以檔案為單位根據 HASH 演算法散列到不同的Brick,其實只是擴大了磁盤空間,如果有一塊磁盤損壞,資料也將丟失,屬于檔案級的 RAID 0, 不具有容錯能力,
- 條帶卷(Stripe volume):類似 RAID0,檔案被分成資料塊并以輪詢的方式分布到多個 Brick Server上,檔案存盤以資料塊為單位,支持大檔案存盤,檔案越大,讀取效率越高,
- 復制卷(Replica volume):將檔案同步到多個 Brick 上,使其具備多個檔案副本, 屬于檔案級 RAID1,具有容錯能力,因為資料分散在多個 Brick 中,所以讀性能得 到很大提升,但寫性能下降,
- 分布式條帶卷(Distribute Stripe volume):Brick Server 數量是條帶數(資料塊分布 的 Brick數量)的倍數,兼具分布式卷和條帶卷的特點,
- 分布式復制卷(Distribute Replica volume):Brick Server 數量是鏡像數(資料副本數量)的倍數,兼具分布式卷和復制卷的特點,
- 條帶復制卷(Stripe Replica volume):類似 RAID 10,同時具有條帶卷和復制卷的特點,
- 分布式條帶復制卷(Distribute Stripe Replicavolume):三種基本卷的復合卷,通常用于類 Map Reduce應用,
1、分布式卷
分布式卷是 GlusterFS 的默認卷,在創建卷時,默認選項是創建分布式卷,在該模式下, 并沒有對檔案進行分塊處理,檔案直接存盤在某個 Server 節點上,直接使用本地檔案系統進行檔案存盤,大部分 Linux 命令和工具可以繼續正常使用,需要通過擴展檔案屬性保存 HASH 值,目前支持的底層檔案系統有 EXT3、EXT4、ZFS、XFS 等,由于使用的是本地檔案系統,所以存取效率并沒有提高,反而會因為網路通信的原因而 有所降低;另外支持超大型檔案也會有一定的難度,因為分布式卷不會對檔案進行分塊處理
分布式卷具有如下特點:
- 檔案分布在不同的服務器,不具備冗余性,
- 更容易且廉價地擴展卷的大小,
- 存在單點故障會造成資料丟失,
- 依賴底層的資料保護,
2、條帶卷
Stripe 模式相當于 RAID0,在該模式下,根據偏移量將檔案分成 N 塊(N 個條帶節點), 輪詢地存盤在每個 Brick Server 節點,節點把每個資料塊都作為普通檔案存入本地檔案系統 中,通過擴展屬性記錄總塊數(Stripe-count)和每塊的序號(Stripe-index),在配置時指定的條帶數必須等于卷中 Brick 所包含的存盤服務器數,在存盤大檔案時,性能尤為突出, 但是不具備冗余性
條帶卷具有如下特點,
- 資料被分割成更小塊分布到塊服務器群中的不同條帶區,
- 分布減少了負載且更小的檔案加速了存取的速度,
- 沒有資料冗余
3、復制卷
復制模式,也稱為 AFR(AutoFile Replication),相當于 RAID1,即同一檔案保存一份 或多份副本,每個節點上保存相同的內容和目錄結構,復制模式因為要保存副本,所以磁盤 利用率較低,如果多個節點上的存盤空間不一致,那么將按照木桶效應取最低節點的容量作為該卷的總容量,在配置復制卷時,復制數必須等于卷中 Brick 所包含的存盤服務器數,復 制卷具備冗余性,即使一個節點損壞,也不影響資料的正常使用,
復制卷具有如下特點,
- 卷中所有的服務器均保存一個完整的副本,
- 卷的副本數量可由客戶創建的時候決定,
- 至少有兩個塊服務器或更多服務器,
- 具備冗余性
4、分布式條帶卷
分布式條帶卷兼顧分布式卷和條帶卷的功能,主要用于大檔案訪問處理,創建一個分布 式條帶卷最少需要 4 臺服務器
5、分布式復制卷
分布式復制卷兼顧分布式卷和復制卷的功能,主要用于需要冗余的情況下
四、部署 GlusterFS 群集
1、環境準備
node1:192.168.245.203
node2:192.168.245.204
node3:192.168.245.205
node4:192.168.245.206
client:192.168.245.201
確定firewall防火墻和selinux已經關閉
iptables -F是沒有用的,一定要關閉firewall防火墻!!!
每臺node新添加4塊磁盤,大小20G
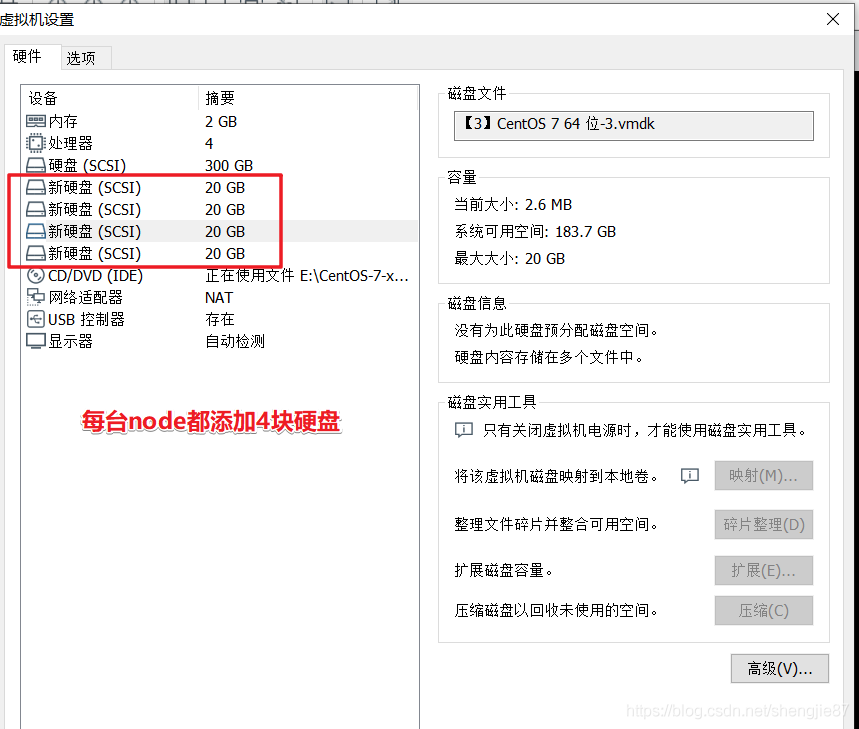
給這些新添加的磁盤磁區并格式化
創建掛載點
[root@node1 ~]# mkdir -p /data/sd{b,c,d,e}1
[root@node1 ~]# ls /data
sdb1 sdc1 sdd1 sde1
掛載磁區
[root@node1 ~]# mount /dev/sdb1 /data/sdb1
[root@node1 ~]# mount /dev/sdc1 /data/sdc1
[root@node1 ~]# mount /dev/sdd1 /data/sdd1
[root@node1 ~]# mount /dev/sde1 /data/sde1
[root@node1 ~]#
[root@node1 ~]# df -Th
檔案系統 型別 容量 已用 可用 已用% 掛載點
/dev/mapper/centos-root xfs 50G 4.2G 46G 9% /
devtmpfs devtmpfs 894M 0 894M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 11M 900M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 179M 836M 18% /boot
/dev/mapper/centos-home xfs 247G 37M 247G 1% /home
tmpfs tmpfs 182M 12K 182M 1% /run/user/42
tmpfs tmpfs 182M 0 182M 0% /run/user/0
/dev/sdb1 ext4 20G 45M 19G 1% /data/sdb1
/dev/sdc1 ext4 20G 45M 19G 1% /data/sdc1
/dev/sdd1 ext4 20G 45M 19G 1% /data/sdd1
/dev/sde1 ext4 20G 45M 19G 1% /data/sde1
修改節點的主機名,因為它是用主機名來識別各節點的
[root@node1 ~]# echo "192.168.245.203 node1" >> /etc/hosts
[root@node1 ~]# echo "192.168.245.204 node2" >> /etc/hosts
[root@node1 ~]# echo "192.168.245.205 node3" >> /etc/hosts
[root@node1 ~]# echo "192.168.245.206 node4" >> /etc/hosts
- 配置yum本地源
gfsrepo目錄里是本地rpm包,里面包含了gfs軟體包和依賴包
[root@node1 ~]# mkdir /abc
[root@node1 ~]# cd /abc
[root@node1 abc]# ll
總用量 12
drwxr-xr-x 3 root root 8192 9月 13 23:47 gfsrepo
把之前的yum網路源的組態檔備份一下
[root@node1 abc]# cd /etc/yum.repos.d/
[root@node1 yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Media.repo CentOS-Vault.repo
CentOS-CR.repo CentOS-fasttrack.repo CentOS-Sources.repo epel.repo
[root@node1 yum.repos.d]# mkdir bak
[root@node1 yum.repos.d]# mv * bak
mv: 無法將目錄"bak" 移動至自身的子目錄"bak/bak" 下
[root@node1 yum.repos.d]#
[root@node1 yum.repos.d]# ls
bak
編輯本地yum源
[root@node1 yum.repos.d]# vim GLFS.repo
[glfs]
name=glfs
baseurl=file:///abc/gfsrepo
gpgcheck=0
enabled=1
把yum本地源組態檔推送給其他node節點(為了節省時間)
[root@node1 yum.repos.d]# scp GLFS.repo root@192.168.245.204:/etc/yum.repos.d/
The authenticity of host '192.168.245.204 (192.168.245.204)' can't be established.
ECDSA key fingerprint is SHA256:5qVFPbfSJ8tArL82/yswIhMAg7vdiKoK4nZsexYkUX4.
ECDSA key fingerprint is MD5:aa:db:41:8e:a3:70:d8:44:ce:28:b7:88:fe:0c:63:bb.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.245.204' (ECDSA) to the list of known hosts.
root@192.168.245.204's password:
GLFS.repo 100% 66 36.9KB/s 00:00
yum安裝之前,顯示所有已經安裝和可以安裝的程式包
[root@node1 yum.repos.d]# yum list
2、yum安裝glusterfs軟體
yum安裝以下軟體包
[root@node1 yum.repos.d]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
3、開啟GlusterFS服務
[root@node1 yum.repos.d]# systemctl start glusterd.service
[root@node1 ~]# netstat -antp | grep gluster
tcp 0 0 0.0.0.0:24007 0.0.0.0:* LISTEN 8760/glusterd
tcp 0 0 0.0.0.0:49152 0.0.0.0:* LISTEN 64209/glusterfsd
tcp 0 0 0.0.0.0:49153 0.0.0.0:* LISTEN 64514/glusterfsd
tcp 0 0 0.0.0.0:49154 0.0.0.0:* LISTEN 64788/glusterfsd
tcp 0 0 0.0.0.0:49155 0.0.0.0:* LISTEN 64963/glusterfsd
4、配置時間同步
[root@node1 yum.repos.d]# ntpdate ntp1.aliyun.com
14 Sep 00:17:59 ntpdate[63937]: adjust time server 120.25.115.20 offset 0.007826 sec
5、 添加節點
只需要在一臺node上添加即可
[root@node1 ~]# gluster peer probe node2
peer probe: success.
[root@node1 ~]# gluster peer probe node3
peer probe: success.
[root@node1 ~]# gluster peer probe node4
peer probe: success.
通過以下命令在每個節點上查看群集狀態,正常情況下每個節點的輸出結果均為“State: Peer in Cluster(Connected)”,如果顯示 Disconnected,請檢查 hosts 檔案配置
[root@node1 ~]# gluster peer status
Number of Peers: 3
Hostname: node2
Uuid: bc421d97-5e05-43da-af1d-2b28c46acdd3
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: 7d4ccf9d-83b3-4b8d-8a30-42a9da6a78ee
State: Peer in Cluster (Connected)
Hostname: node4
Uuid: 4df47d8d-8dd4-4336-a411-9b96d996ae4a
State: Peer in Cluster (Connected)
6、創建卷
(1)創建分布式卷
使用gluster volume create創建卷,后面跟卷名稱,自己可識別即可,沒有指定型別,默認創建的是分布式卷,force表示強制,你想用哪些節點來存盤后面跟節點名和掛載點
[root@node1 ~]# gluster volume create fenbushi-vol node1:/data/sdb1 node2:/data/sdb1 force
volume create: fenbushi-vol: success: please start the volume to access data
gluster volume info 卷名可以查看卷的詳細資訊
[root@node1 ~]# gluster volume info fenbushi-vol
Volume Name: fenbushi-vol
Type: Distribute
Volume ID: 47978ec2-b7e0-4ede-8723-cabec845ca31
Status: Created <----還在創建狀態
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
查看所有GFS卷串列
[root@node1 ~]# gluster volume list
fenbushi-vol
啟用分布式卷,創建之后還不能使用,必須要啟用它
使用gluster volume start 卷名啟用卷
[root@node1 ~]# gluster volume start fenbushi-vol
volume start: fenbushi-vol: success
[root@node1 ~]# gluster volume info fenbushi-vol
Volume Name: fenbushi-vol
Type: Distribute
Volume ID: 47978ec2-b7e0-4ede-8723-cabec845ca31
Status: Started <----狀態改變
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
(2)創建條帶卷
這里指定型別為 stripe,數值為 2,而且后面跟了 2 個 node節點,所以創建的是條帶卷,
[root@node1 ~]# gluster volume create tiaodai-vol stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
volume create: tiaodai-vol: success: please start the volume to access data
啟用條帶卷
[root@node1 ~]# gluster volume start tiaodai-vol
volume start: tiaodai-vol: success
[root@node1 ~]# gluster volume info tiaodai-vol
Volume Name: tiaodai-vol
Type: Stripe
Volume ID: d30c1262-a8bf-41eb-9200-8092209ca1fb
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdc1
Brick2: node2:/data/sdc1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]# gluster volume list
fenbushi-vol
tiaodai-vol
(3)創建復制卷
這里指定型別為 replica,數值為 2,而且后面跟了 2 個 node節點,所以創建的是復制卷
[root@node1 ~]# gluster volume create fuzhi-vol replica 2 node3:/data/sdb1 node4:/data/sdb1 force
volume create: fuzhi-vol: success: please start the volume to access data
啟用復制卷
[root@node1 ~]# gluster volume start fuzhi-vol
volume start: fuzhi-vol: success
[root@node1 ~]# gluster volume list
fenbushi-vol
fuzhi-vol
tiaodai-vol
[root@node1 ~]# gluster volume info fuzhi-vol
Volume Name: fuzhi-vol
Type: Replicate
Volume ID: 39d55d25-5b6c-4b2e-85a6-24678ecfab43
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node3:/data/sdb1
Brick2: node4:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
(4)創建分布式條帶卷
這里指定型別為 stripe,數值為 2,而且后面跟了 4 個 node節點,是 2 的 2 倍,所以創建的是分布式條帶卷
[root@node1 ~]# gluster volume create fbsstr-vol stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
volume create: fbsstr-vol: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbsstr-vol
volume start: fbsstr-vol: success
[root@node1 ~]# gluster volume info fbsstr-vol
Volume Name: fbsstr-vol
Type: Distributed-Stripe
Volume ID: b31d3cd6-38c4-46f6-b380-c8e39f17bf54
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdd1
Brick2: node2:/data/sdd1
Brick3: node3:/data/sdd1
Brick4: node4:/data/sdd1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]# gluster volume list
fbsstr-vol
fenbushi-vol
fuzhi-vol
tiaodai-vol
(5)創建分布式復制卷
這里指定型別為 replica,數值為 2,而且后面跟了 4 個 node節點,是 2 的 兩倍,所以創建的是分布式復制卷
[root@node1 ~]# gluster volume create fbsrep-vol replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
volume create: fbsrep-vol: success: please start the volume to access data
[root@node1 ~]# gluster volume start fbsrep-vol
volume start: fbsrep-vol: success
[root@node1 ~]# gluster volume info fbsrep-vol
Volume Name: fbsrep-vol
Type: Distributed-Replicate
Volume ID: bcb1f7f3-9d17-4702-935e-1dbd00da25fd
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 ~]# gluster volume list
fbsrep-vol
fbsstr-vol
fenbushi-vol
fuzhi-vol
tiaodai-vol
6、部署客戶端
在部署完分布式檔案系統后,需要對掛載的服務器安裝客戶端軟體,并創建掛載目錄, 將分布式檔案系統掛載到剛創建目錄即可,
客戶端上的準備作業:
[root@node1 yum.repos.d]# scp GLFS.repo root@192.168.245.201:/etc/yum.repos.d/
[root@client ~]# yum -y install glusterfs glusterfs-fuse
[root@client ~]# echo "192.168.245.203 node1" >> /etc/hosts
[root@client ~]# echo "192.168.245.204 node2" >> /etc/hosts
[root@client ~]# echo "192.168.245.205 node3" >> /etc/hosts
[root@client ~]# echo "192.168.245.206 node4" >> /etc/hosts
創建掛載點
[root@client ~]# mkdir -p /test/fbs <----分布式卷
[root@client ~]# mkdir /test/tiaodai <----條帶卷
[root@client ~]# mkdir /test/fuzhi <----復制卷
[root@client ~]# mkdir /test/fbsstr <----分布式條帶卷
[root@client ~]# mkdir /test/fbsrep <----分布式復制卷
[root@client ~]#
[root@client ~]#
[root@client ~]# mount.glusterfs node1:fenbushi-vol /test/fbs
[root@client ~]# mount.glusterfs node1:tiaodai-vol /test/tiaodai/
[root@client ~]# mount.glusterfs node1:fuzhi-vol /test/fuzhi
[root@client ~]# mount.glusterfs node1:fbsstr-vol /test/fbsstr/
[root@client ~]# mount.glusterfs node1:fbsrep-vol /test/fbsrep/
[root@client ~]#
[root@client ~]# df -TH
檔案系統 型別 容量 已用 可用 已用% 掛載點
/dev/sda3 xfs 317G 14G 303G 5% /
devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 2.0G 14M 2.0G 1% /run
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 xfs 1.1G 183M 881M 18% /boot
tmpfs tmpfs 396M 4.1k 396M 1% /run/user/42
tmpfs tmpfs 396M 25k 396M 1% /run/user/0
/dev/sr0 iso9660 4.6G 4.6G 0 100% /run/media/root/CentOS 7 x86_64
node1:fenbushi-vol fuse.glusterfs 43G 93M 40G 1% /test/fbs
node1:tiaodai-vol fuse.glusterfs 43G 93M 40G 1% /test/tiaodai
node1:fuzhi-vol fuse.glusterfs 22G 47M 20G 1% /test/fuzhi
node1:fbsstr-vol fuse.glusterfs 85G 186M 80G 1% /test/fbsstr
node1:fbsrep-vol fuse.glusterfs 43G 93M 40G 1% /test/fbsrep
在掛載時,所指定的 node1 只是為了從它那里獲取到必要的配置資訊,在掛載之后, 客戶機不僅僅會與 node1 進行通信,也會直接和邏輯存盤卷內其他 node所在的主機進行通信,
7、驗證資料存盤
產生5個測驗檔案,每個大小40M
[root@client ~]# dd if=/dev/zero of=/demo1.log bs=1M count=40
記錄了40+0 的讀入
記錄了40+0 的寫出
41943040位元組(42 MB)已復制,0.0238866 秒,1.8 GB/秒
[root@client ~]# dd if=/dev/zero of=/demo2.log bs=1M count=40
記錄了40+0 的讀入
記錄了40+0 的寫出
41943040位元組(42 MB)已復制,0.0317271 秒,1.3 GB/秒
[root@client ~]# dd if=/dev/zero of=/demo3.log bs=1M count=40
記錄了40+0 的讀入
記錄了40+0 的寫出
41943040位元組(42 MB)已復制,0.0369535 秒,1.1 GB/秒
[root@client ~]# dd if=/dev/zero of=/demo4.log bs=1M count=40
記錄了40+0 的讀入
記錄了40+0 的寫出
41943040位元組(42 MB)已復制,0.0357797 秒,1.2 GB/秒
[root@client ~]# dd if=/dev/zero of=/demo5.log bs=1M count=40
記錄了40+0 的讀入
記錄了40+0 的寫出
41943040位元組(42 MB)已復制,0.0162924 秒,2.6 GB/秒
將這些測驗檔案分別拷貝到掛載點
[root@client ~]# cp /demo* /test/tiaodai/
[root@client ~]# cp /demo* /test/fuzhi/
[root@client ~]# cp /demo* /test/fbs
[root@client ~]# cp /demo* /test/fbsrep/
[root@client ~]# cp /demo* /test/fbsstr/
驗證分布式卷存盤情況
檔案1-4存盤在了node1上,5存盤在了node2上
[root@node1 ~]# ll -h /data/sdb1
總用量 161M
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo4.log
[root@node2 yum.repos.d]# ll -h /data/sdb1
總用量 41M
-rw-r--r-- 2 root root 40M 9月 14 01:17 demo5.log
驗證條帶卷存盤情況
所有檔案都分成了兩半各自存盤在node1和node2上
[root@node1 ~]# ll -h /data/sdc1
總用量 101M
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo4.log
-rw-r--r-- 2 root root 20M 9月 14 01:17 demo5.log
[root@node2 yum.repos.d]# ll -h /data/sdc1
總用量 101M
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 20M 9月 14 01:12 demo4.log
-rw-r--r-- 2 root root 20M 9月 14 01:17 demo5.log
驗證復制卷
每個檔案都存在node3上一份,node4上一份
[root@node3 ~]# ll -h /data/sdb1
總用量 201M
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo4.log
-rw-r--r-- 2 root root 40M 9月 14 01:17 demo5.log
[root@node4 ~]# ll -h /data/sdb1
總用量 201M
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo4.log
-rw-r--r-- 2 root root 40M 9月 14 01:17 demo5.log
驗證分布式條帶卷
檔案1-4各分成一半存在了node1和node2上,檔案5分成兩半存在node3和node4上
[root@node1 ~]# ll -h /data/sdd1
總用量 81M
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo1.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo2.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo3.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo4.log
[root@node2 ~]# ll -h /data/sdd1
總用量 81M
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo1.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo2.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo3.log
-rw-r--r-- 2 root root 20M 9月 14 01:13 demo4.log
[root@node3 ~]# ll -h /data/sdd1
總用量 21M
-rw-r--r-- 2 root root 20M 9月 14 01:17 demo5.log
[root@node4 ~]# ll -h /data/sdd1
總用量 21M
-rw-r--r-- 2 root root 20M 9月 14 01:17 demo5.log
驗證分布式復制卷
檔案1-4存在node1上一份,node2上一份,而檔案5寸在node3一份,node4一份
[root@node1 ~]# ll -h /data/sde1
總用量 161M
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo3.log
-rw-r--r-- 2 root root 40M 9月 14 01:13 demo4.log
[root@node2 ~]# ll -h /data/sde1
總用量 161M
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo1.log
-rw-r--r-- 2 root root 40M 9月 14 01:12 demo2.log
-rw-r--r-- 2 root root 40M 9月 14 01:13 demo3.log
-rw-r--r-- 2 root root 40M 9月 14 01:13 demo4.log
[root@node3 ~]# ll -h /data/sde1
總用量 41M
-rw-r--r-- 2 root root 40M 9月 14 01:17 demo5.log
[root@node4 ~]# ll -h /data/sde1
總用量 41M
-rw-r--r-- 2 root root 40M 9月 14 01:17 demo5.log
8、破壞測驗
現在宕機node2觀察資料是否還完整
可以看到除了復制卷和分布式復制卷,其他的資料都不再完整
[root@client test]# ls /test
fbs fbsrep fbsstr fuzhi tiaodai
[root@client test]# ls /test/fbs
demo1.log demo2.log demo3.log demo4.log
[root@client test]# ls /test/tiaodai/
[root@client test]# ls /test/fuzhi/
demo1.log demo2.log demo3.log demo4.log demo5.log
[root@client test]# ls /test/fbsstr/
demo5.log
[root@client test]# ls /test/fbsrep/
demo1.log demo2.log demo3.log demo4.log demo5.log
如果有服務器宕機的話想要洗掉卷是無法洗掉的,必須都在線才可以
洗掉之前需要停止
[root@node1 ~]# gluster volume stop fuzhi-vol
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: fuzhi-vol: success
[root@node1 ~]# gluster volume delete fuzhi-vol
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: fuzhi-vol: failed: Some of the peers are down
創建卷時,存盤服務器的數量如果等于條帶或復制數,那么創建的是條帶卷或者復制卷;如果存盤服務器的數量是條帶或復制數的 2 倍甚至更多,那么將創建的是分布式條帶卷或分布式復制卷,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/104519.html
標籤:其他