原標題 :運用Python爬蟲下載漫畫碼上面的漫畫
前言
看過小編博客的讀者應該知道,小撰寫的這篇博客:Python爬蟲經常爬不到資料,或許你可以看一下小編的這篇文章 有一點不足,就是最后講到的那個動態加載問題,那里沒有給出一個好一點的實體,現在,小編把那個空缺補全一下,希望讀者喜歡!
首先,先講明一點,
文章目錄
- 原標題 :運用Python爬蟲下載漫畫碼上面的漫畫
- 1.需要的Python模塊和基本用法
- 2.實作程式代碼的思路
- 3.完整代碼和運行結果
- 4.總結
1.需要的Python模塊和基本用法
selenium、requests、os、time模塊
其中selenium模塊我不講相信讀者也已經知道了吧!requests模塊在這里主要的作用是負責下載漫畫圖片,本來小編打算是運用urllib.request里面的urlretrieve方法下載的,但是這個程式代碼比較特別,需要添加一個請求頭,不然就會出現403錯誤,所以小編選擇了requests模塊,
os模塊在這里的作用是創建檔案夾,time模塊主要是用來休眠,這個模塊是必須有的,否則有個時候程式會報錯,為了避免出現,所以小編在這里用了time模塊,
2.實作程式代碼的思路
在這里,首先給出這個網址:漫畫碼
在實作整個程序當中,除了最后那個下載漫畫圖片是用了requests模塊之外,其他基本是運用selenium模塊實作的,也就是說完成整個程序基本上是爬取動態網址的資料,

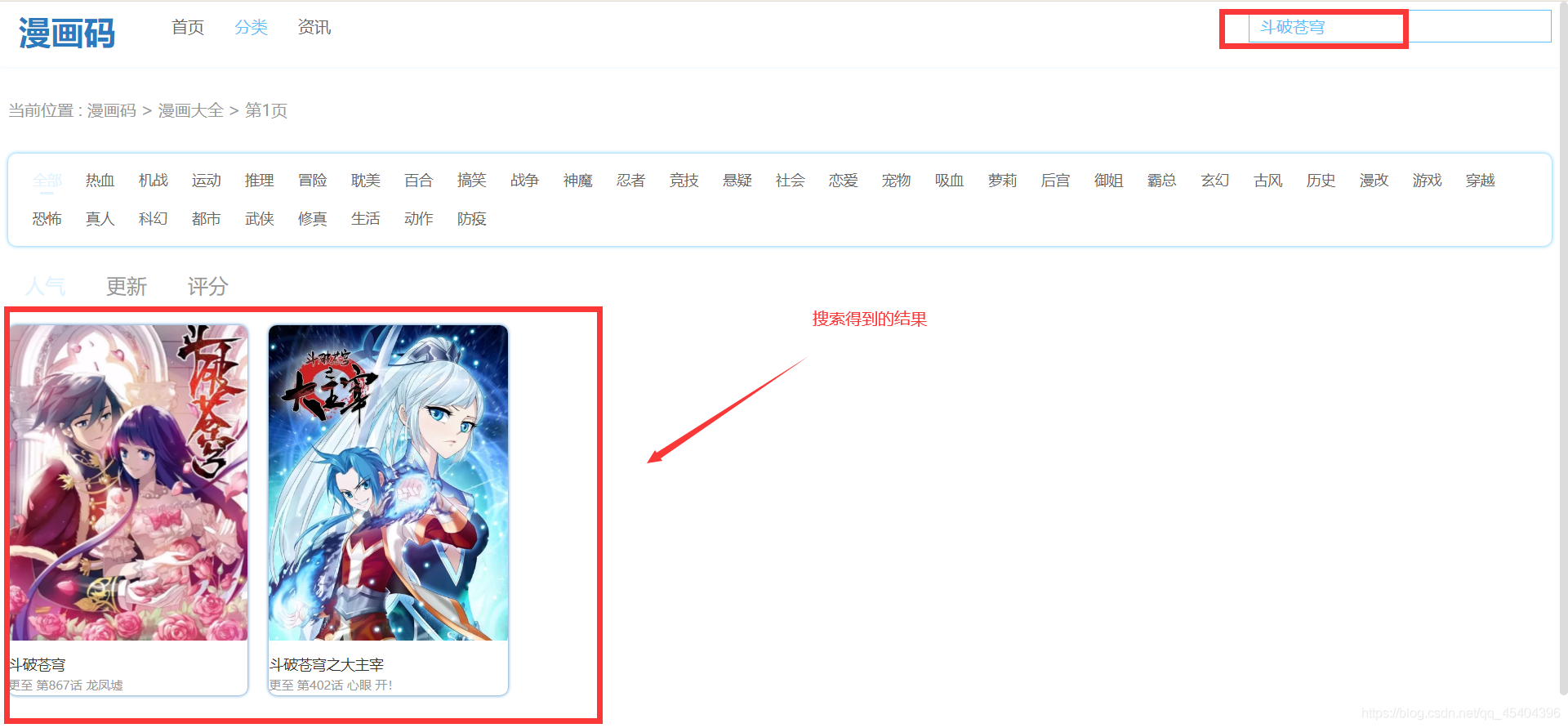
首先,應該模擬瀏覽器在搜索框中輸入相應的內容,然后再按電腦鍵盤的Enter 鍵來到另外一個界面,小編輸入的是:斗破蒼穹 ,接下來就是這個界面了,
怎樣實作呢?
按電腦鍵盤的F12鍵或者滑鼠右鍵 檢查 ,來到開發者模式,得到搜索框的位置,再這里小編用的是xpath語法,如下:
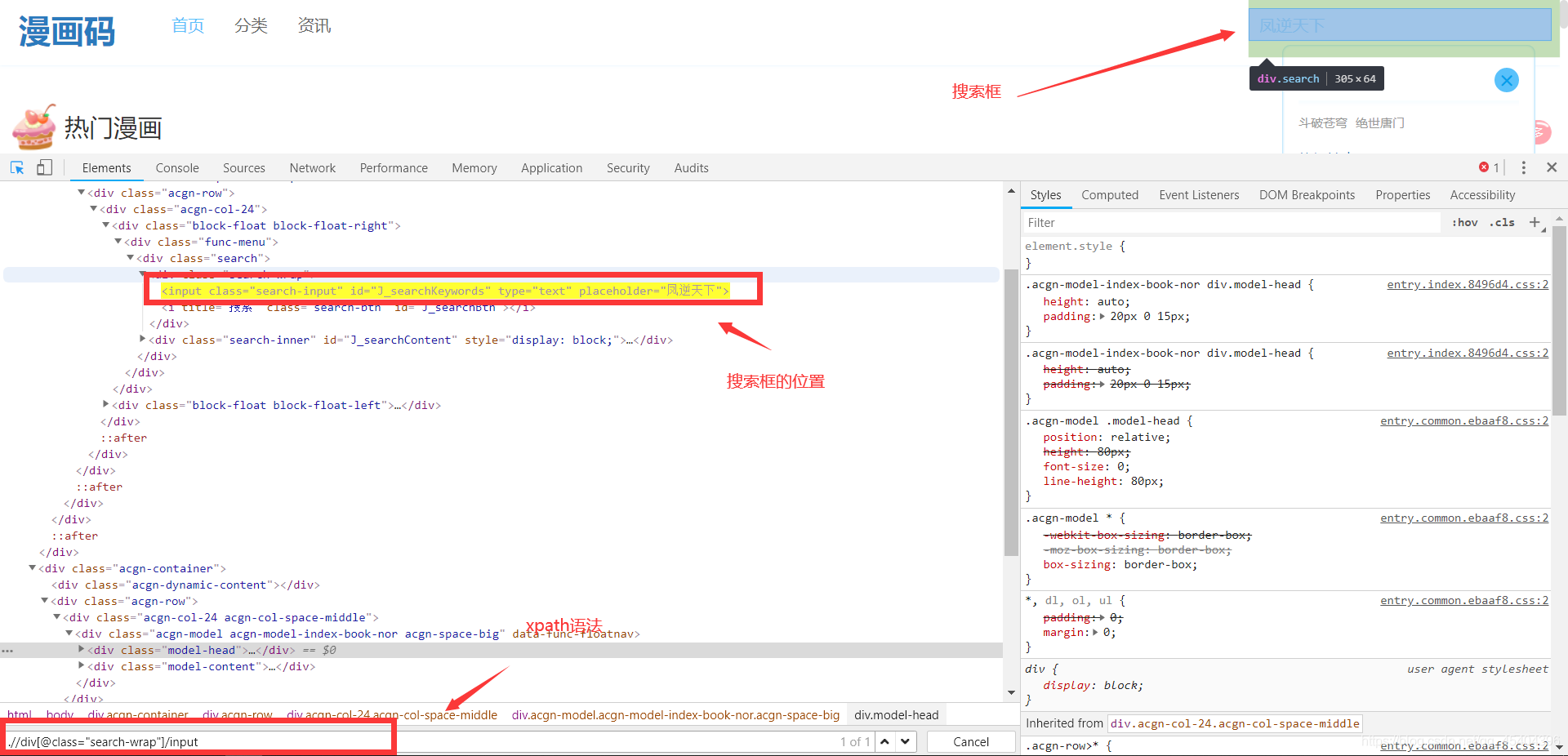
可以發現,這個搜索框中默認是有內容的,如何處理呢?
seek = self.driver.find_element_by_xpath('.//div[@class="search-wrap"]/input') # 搜索輸入框
seek.clear() # 清空輸入框中的內容
也就是這樣了,在這個輸入框中輸入相應的內容,由于這個網址沒有搜索按鈕,所以這里需要匯入這個
from selenium.webdriver.common.keys import Keys
然后使用其中的一個屬性,如下:
seek.send_keys(Keys.ENTER)
這樣就可以模擬瀏覽器按Enter鍵了,
那么怎樣再搜索得到內容中選擇自己想看的內容呢?和上面一樣,找到相應的位置,如下:
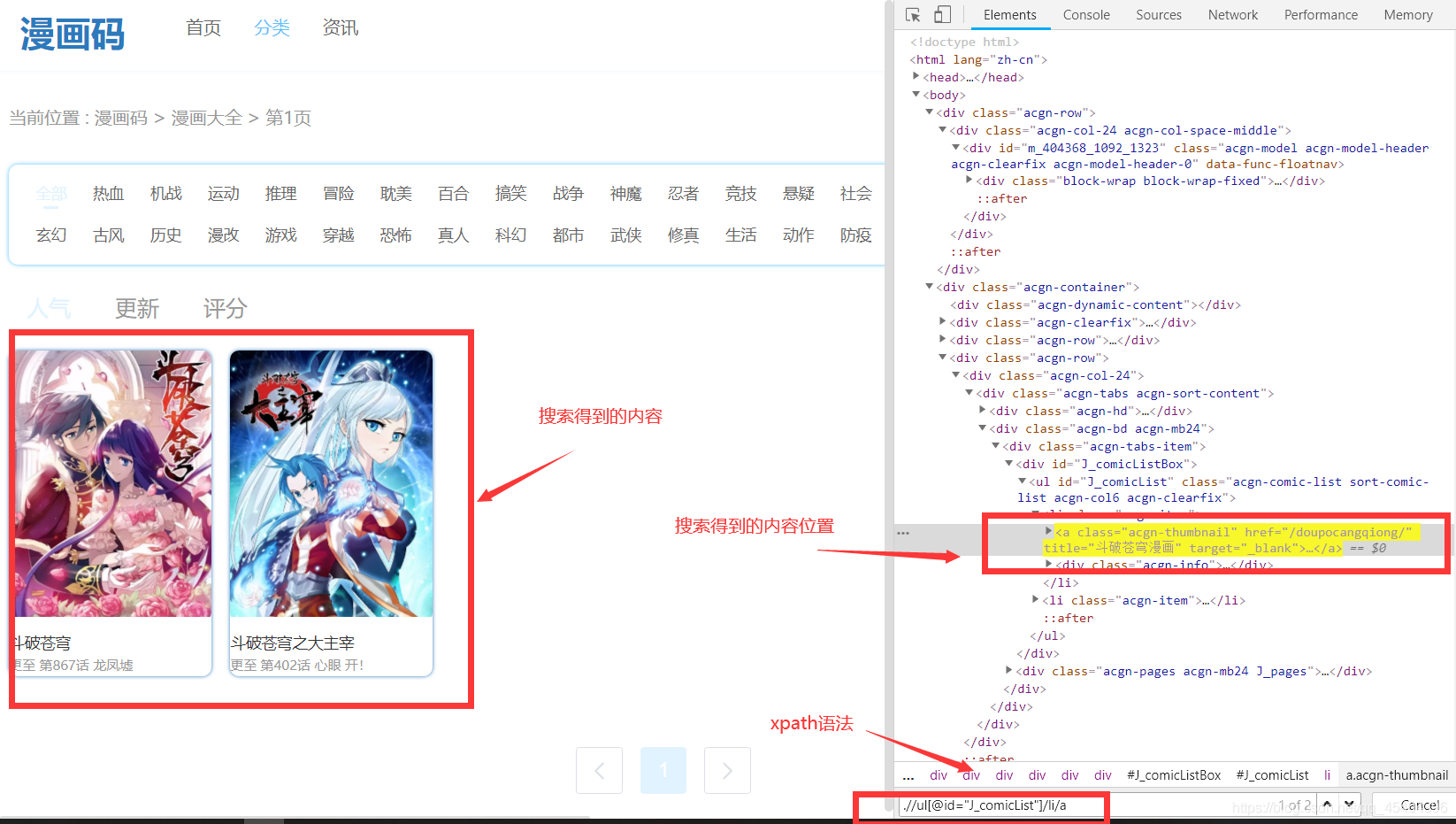
由于這里搜索得到的結果不可能是一個,所以使用的方法如下:
seek_out = self.driver.find_elements_by_xpath('.//ul[@id="J_comicList"]/li/a') # 搜索結果
這里的find_elements_by_xpath 得到的結果是一個串列格式的資料
之后再使用.click()方法選擇其中的一個就可以了,小編選擇的是第一個,來到接下來的這個界面,
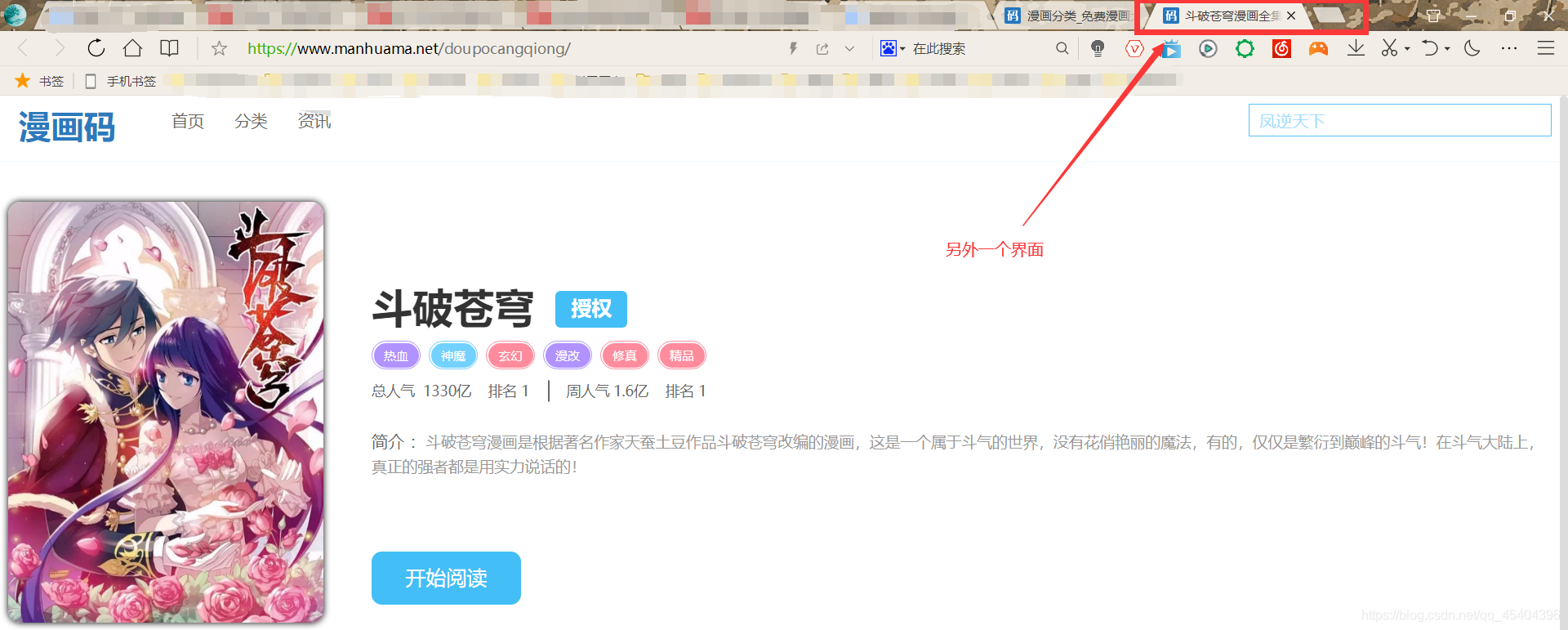
這個時候可以發現這是一個新的界面,也就是這里要變化一下這個視窗,代碼如下:
self.driver.switch_to.window(self.driver.window_handles[-1])
接下來,就是得到這個界面下的所有漫畫章節了,
別看這個界面只有十多章節的漫畫,可是查看一下源代碼可以發現,所有漫畫章節都是在這個界面下,不過也是動態加載的,讀者看一下就知道了,
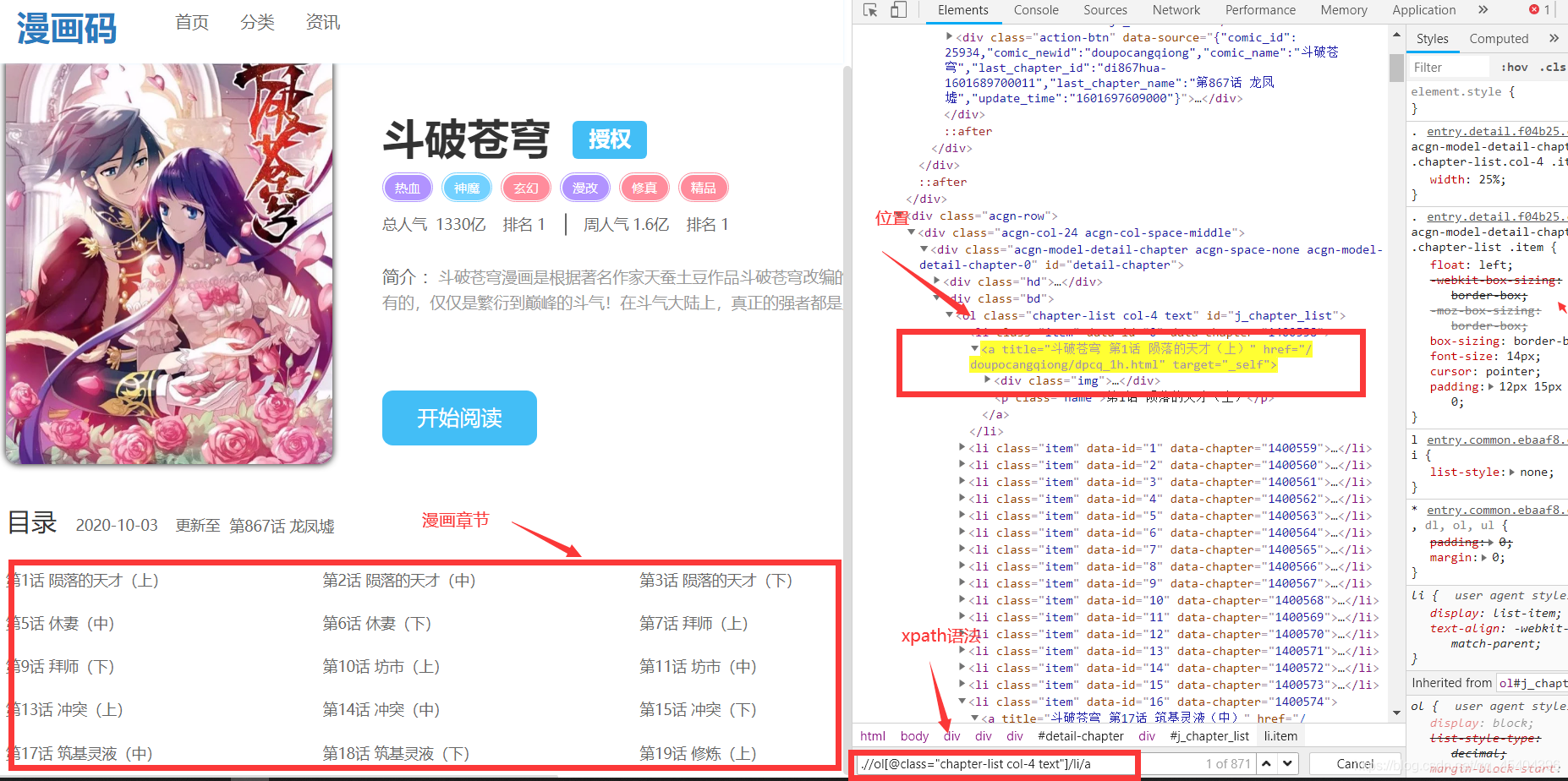
Hrefs_List = self.driver.find_elements_by_xpath('.//ol[@class="chapter-list col-4 text"]/li/a')
選擇其中的一章節漫畫進入,可以發現就是漫畫了,不過也是動態加載的,另外,如果直接使用xpath語法得到這些圖片位置的話,輸出的時候只能有部分圖片的下載網址,或許 這就是動態網址的神奇之處了,只有在滾動條下滑的時候,才可能得到全部下載網址,難道沒有簡單的方法了嗎?
肯定是有的,那就是得到一章節漫畫下面的漫畫頁數,然后運用字串拼接就可以基本實作了,
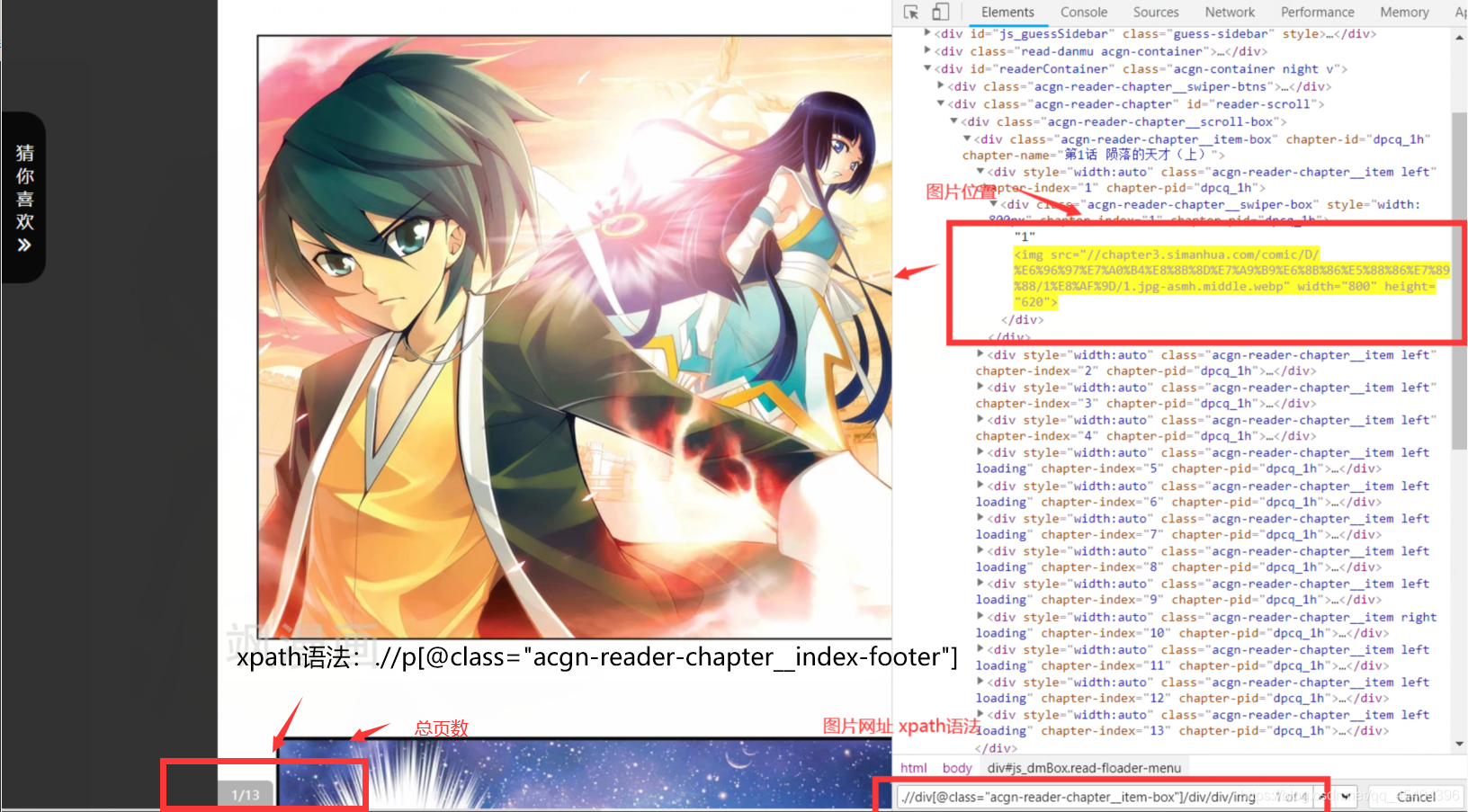
實作下載代碼如下:
str2=driver.find_element_by_xpath('.//p[@class="acgn-reader-chapter__index-footer"]').text
end=int(str2.split('/')[-1]) # 得到一節漫畫中的總頁數
List2=driver.find_elements_by_xpath('.//div[@class="acgn-reader-chapter__item-box"]/div/div/img')
url=List2[0].get_attribute('src') # 網址
path2 = self.path + '\{}'.format(self.Name[i])
try:
os.mkdir(path=path2)
except Exception as e:
print(e)
# 下載一節漫畫中的所有圖片
self.headers['referer']=self.List[i]
for j in range(1,end+1): # 對網址進行字串的拼接
url_start=url.rfind('/')+1
url_end=url.rfind('.jpg')
url=url[:url_start]+str(j)+url[url_end:] # 圖片下載網址
response=requests.get(url=url,headers=self.headers)
with open(file=path2+'\{}.jpg'.format(j),mode='wb') as f:
f.write(response.content)
driver.close()
time.sleep(1)
print('*'*int(random()*10)+'->已下載{}'.format(self.Name[i]))
3.完整代碼和運行結果
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from random import random
import requests
import time
import os
class Cartoon(object):
def __init__(self, keyword,path):
self.url2 = 'https://www.manhuama.net/'
self.driver = webdriver.Chrome()
self.keyword = keyword
self.List=list()
self.Name=list()
self.headers={'referer':''}
self.path=path
def GetOutcome(self):
self.driver.get(self.url2)
self.driver.implicitly_wait(30)
seek = self.driver.find_element_by_xpath('.//div[@class="search-wrap"]/input') # 搜索輸入框
seek.clear() # 清空輸入框中的內容
seek.send_keys(self.keyword)
seek.send_keys(Keys.ENTER)
time.sleep(1) # 休眠一秒
seek_out = self.driver.find_elements_by_xpath('.//ul[@id="J_comicList"]/li/a') # 搜索結果
name_list = list()
for i in range(len(seek_out)):
print('[{}]-#$&@>{}'.format(i + 1, seek_out[i].get_attribute('title')))
name_list.append(seek_out[i].get_attribute('title'))
id = int(input('請輸入想看的漫畫序號:'))
print('你選擇的是:{}'.format(name_list[id - 1]))
seek_out[id - 1].click()
def GetHrefs(self): # 定義方法,用于得到一部漫畫下面的所以章節的鏈接和名稱
self.GetOutcome()
self.driver.switch_to.window(self.driver.window_handles[-1])
print('referer:{}'.format(self.driver.current_url))
Hrefs_List = self.driver.find_elements_by_xpath('.//ol[@class="chapter-list col-4 text"]/li/a')
# print(len(Hrefs_List))
for i in range(len(Hrefs_List)):
if (i+1)%2==0:
print()
print('[{}]-#$@->{}'.format(i + 1, Hrefs_List[i].get_attribute('title')),end='\t\t\t')
self.List.append(Hrefs_List[i].get_attribute('href'))
self.Name.append(Hrefs_List[i].get_attribute('title'))
id2, id3 = 0, 0
print()
str2 = input('請輸入想看的漫畫序號\n(注意格式:1. 2,3 表示 2~3 中間是英文逗號 \n 2. 單獨輸入一個 n 表述 1~n)\n輸入:')
List = str2.split(',')
if len(List) == 1:
id3 = int(List[0])
else:
id2, id3 = int(List[0]) - 1, int(List[1])
return id2,id3
def Download(self):
id2,id3=self.GetHrefs()
self.driver.quit() # 關閉瀏覽器
for i in range(id2,id3):
driver = webdriver.Chrome()
driver.get(url=self.List[i])
driver.implicitly_wait(30)
str2=driver.find_element_by_xpath('.//p[@class="acgn-reader-chapter__index-footer"]').text
end=int(str2.split('/')[-1]) # 得到一節漫畫中的總頁數
List2=driver.find_elements_by_xpath('.//div[@class="acgn-reader-chapter__item-box"]/div/div/img')
url=List2[0].get_attribute('src') # 網址
path2 = self.path + '\{}'.format(self.Name[i])
try:
os.mkdir(path=path2)
except Exception as e:
print(e)
# 下載一節漫畫中的所有圖片
self.headers['referer']=self.List[i]
for j in range(1,end+1): # 對網址進行字串的拼接
url_start=url.rfind('/')+1
url_end=url.rfind('.jpg')
url=url[:url_start]+str(j)+url[url_end:] # 圖片下載網址
response=requests.get(url=url,headers=self.headers)
with open(file=path2+'\{}.jpg'.format(j),mode='wb') as f:
f.write(response.content)
driver.close()
time.sleep(1)
print('*'*int(random()*10)+'->已下載{}'.format(self.Name[i]))
print('下載完畢!')
if __name__ == '__main__':
print('----------------------漫畫碼------------------------')
keyword = input('請輸入你想看的漫畫名稱:')
path=input('請輸入你想創建的檔案夾的絕對路徑:')
try:
os.mkdir(path=path)
except Exception as e:
print(e)
a = Cartoon(keyword=keyword,path=path)
a.Download()
運行結果如下:
運用Python爬蟲下載漫畫碼網址的漫畫
注意:讀者在運行代碼時,注意輸入格式問題,否則會報錯的,還有,讀者如果要運行小編的這個代碼時注意下載頁數盡量輸入小點,這樣運行時間會少點,而且不會出現錯誤(小編在這里沒有進行例外處理),最好的還是不會對服務器造成很大的負擔,作為一名合格的Python爬蟲愛好者,文明爬蟲,從我做起!
4.總結
看了一下運行結果,讀者是不是覺得很神奇,
另外,小編覺得運用selenium模塊的 page_source方法輸出代碼,讀者看到的那個代碼不一定是正確的,這個時候運用find_element_方法里面的一種可以得到輸出代碼中沒有那部分資料,讀者可以自行完成這個程式代碼試一試,可以發現的,哈哈!如果讀者覺得小編的這篇博客還不錯!點個贊在走吧!謝謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/157802.html
標籤:其他
下一篇:從頭構建神經網路