為了專案后續資料需要做準備,開始漸進深入去學習爬蟲,最近做了一個實戰樣例demo,寫了一個爬蟲,獲取全國統計用區劃代碼,資料來源,國家統計局:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/
整體分析一下,這個網站的布局樣式簡直不忍直視,可以說是一覽無遺,基本上啥都沒有,突出了政府網站一貫的簡潔高效風格,
我將按照代碼順序,差穿插著說明開發思路程序,
代碼目錄:
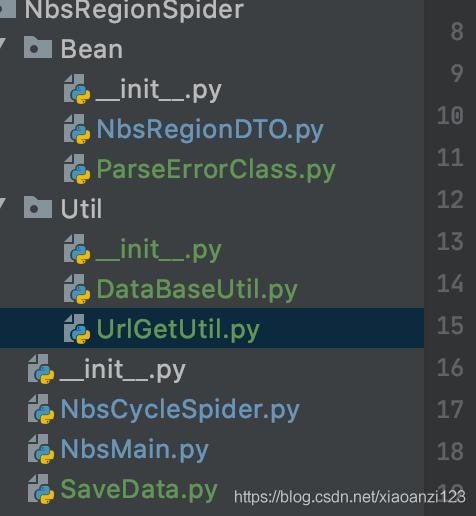
資料庫表設計:
CREATE TABLE `nbs_region` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`nbs_code` varchar(20) DEFAULT NULL COMMENT '國家統計局統計用區劃code',
`nbs_parent_code` varchar(20) DEFAULT NULL COMMENT '國家統計局父級統計用區劃code',
`nbs_level` varchar(16) DEFAULT NULL COMMENT '國家統計局區域層級',
`nbs_name` varchar(128) DEFAULT NULL COMMENT '國家統計局名稱',
`nbs_town_country_code` varchar(10) DEFAULT NULL COMMENT '國家統計局城鄉分類代碼【五級才有值】',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '資料記錄創建時間',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '資料記錄修改時間',
PRIMARY KEY (`id`) USING BTREE,
KEY `nbs_code` (`nbs_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='國家統計局全國五級行政區劃【http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/】';
先介紹下用到的基礎python檔案,
Bean包下兩個類,NbsRegionDTO用于存放爬取決議后的資料,便于最后存庫,欄位和資料庫對應,
'''
國家統計局行政區劃物體類
'''
class NbsRegionDTO:
# 統計用區劃代碼
nbs_code = ''
#'國家統計局父級統計用區劃code',
nbs_parent_code = ''
# '國家統計局區域層級', 1 - 5
nbs_level = 0
# '國家統計局名稱',
nbs_name = ''
# 城鄉分類代碼 五級才有資料
nbs_town_country_code = ''
#定義構造方法
def __init__(self,nbs_code,nbs_parent_code,nbs_level,nbs_name,nbs_town_country_code):
self.nbs_code = nbs_code
self.nbs_parent_code = nbs_parent_code
self.nbs_level = nbs_level
self.nbs_name = nbs_name
self.nbs_town_country_code = nbs_town_country_code
ParseErrorClass 用于封裝爬取程序中出現問題的資料資訊,便于最后集中處理,'''
決議暫時出現例外的資料物體類
'''
class ParseErrorClass:
# 當前 父節點code
parent_code = ''
# 當前 父節點區劃等級
parent_level = 0
# 當前待決議url
to_parse_url = ''
# 定義構造方法
def __init__(self, parent_code, parent_level, to_parse_url):
self.parent_code = parent_code
self.parent_level = parent_level
self.to_parse_url = to_parse_url
util包下有兩個工具類檔案
UrlGetUtil 用于抓取相關url頁面,里面提供兩種方法,request.get() 和 urlopen() ,兩種方式都是可行的,
import sys
from urllib.request import urlopen
from pip._vendor import requests
'''
工具類
'''
class UrlGetUtil:
'''
url 待抓取url
tarBianMa 目標編碼,eg: 'gbk'
'''
def getByRequestGet(self,url,tarBianMa):
response = requests.get(url)
#print(response.encoding) #查看現有編碼
response.encoding = tarBianMa # 改變編碼
#print(response.encoding)#查看改變后的編碼
html = response.text
return html
'''
url 待抓取url
tarBianMa 目標編碼,eg: 'gbk'
'''
def getByUrlOpen(self,url,tarBianMa):
#10s超時
html_obj = urlopen(url,timeout = 10)
html = html_obj.read().decode(tarBianMa)
return htmlDataBaseUtil 提供兩個方法,用于獲取連接物件和游標物件import pymysql
'''
資料庫操作工具類
'''
class DataBaseUtil:
'''獲取連接物件'''
def getConnObj(self,host_param,unix_socket_param,user_param,passwd_param,db_param):
conn = pymysql.connect(host=host_param,unix_socket=unix_socket_param,user=user_param,passwd=passwd_param,db=db_param,charset='utf8')
return conn
'''
獲取游標物件
引數:連接物件conn
'''
def getCurObj(self,conn):
return conn.cursor()
另外還有三個檔案,NbsMain是程式運行入口,NbsCycleSpider用于深層次遞回爬取下級行政區劃資料,SaveData用于存盤資料到資料庫,
★SaveData中主要就是一個批量插入資料到mysql的方法,
1,方法引數傳進來是一個集合,里面存放一個個封裝好的資料NbsRegionDTO物件,為了便于后面批量插入,先把集合引數tar_obj_set處理轉成串列套元組的形式,
2,準備資料庫連接引數,用戶名,密碼,資料庫,ip等老幾樣資料,獲取連接物件和游標物件,
3,執行sql,關于批量插入的注意事項,代碼中的注釋有詳述
4,最后,記得關閉連接和游標,防止泄露,
'''
國家統計局 資料入庫存盤
'''
from NbsRegionSpider.Util.DataBaseUtil import DataBaseUtil
#批量插入
def nbsDataToSaveBatch(tar_obj_set):
#引數處理成串列套元組的形式
tar_list = list() #或 tar_list = []
for tar_obj in tar_obj_set:
tar_tuple = (tar_obj.nbs_code,tar_obj.nbs_parent_code,tar_obj.nbs_level,tar_obj.nbs_name,tar_obj.nbs_town_country_code)
tar_list.append(tar_tuple)
# 資料庫資訊
dataBaseUtilObj = DataBaseUtil()
host_param = 'xxxx.xx.xx.xx'
unix_socket_param = ''
user_param = 'root'
passwd_param = 'xxxxx'
db_param = 'qqq'
conn = dataBaseUtilObj.getConnObj(host_param,unix_socket_param,user_param,passwd_param,db_param)
cur = dataBaseUtilObj.getCurObj(conn)
#執行sql
cur.execute("use qqq")
# 注意這里使用的是executemany而不是execute,下邊有對executemany的詳細說明
'''
另外,針對executemany
execute(sql) : 接受一條陳述句從而執行
executemany(templet,args):能同時執行多條陳述句,執行同樣多的陳述句可比execute()快很多,強烈建議執行多條陳述句時使用executemany
templet : sql模板字串, 例如 ‘insert into table(id,name,age) values(%s,%s,%s)’
args: 模板字串中的引數,是一個list,在list中的每一個元素必須是元組!!! 例如: [(1,‘mike’),(2,‘jordan’),(3,‘james’),(4,‘rose’)]
'''
cur.executemany('insert into nbs_region(nbs_code,nbs_parent_code,nbs_level,nbs_name,nbs_town_country_code) values (%s,%s,%s,%s,%s)',tar_list)
conn.commit()
cur.close()
conn.close()★NbsMain:
基本邏輯
在NbsMain中決議省一級資料,然后在NbsCycleSpider中遞回該省的下級資料的深度爬蟲,把每一層的爬取結果集合,回傳到上一級,再同本級結果集合取并集來合并所有結果,同時把出現爬取例外的資料暫存到錯誤資料集合全域變數error_data_set,最侄訓傳爬取結果集到NbsMain中,然后執行該省資料的存盤入庫,然后回圈下一個省份的處理,最后再處理上述程序中產生的錯誤資料集合error_data_set,進行重試爬取并入庫,進行回圈,每次回圈,創建一個error_data_set_second 來保存出現的錯誤資料,本次資料入庫后,更新error_data_set = error_data_set_second,直到最后,error_data_set容量為0 為止,
之所以不直接操作error_data_set 而是每次用一個新的error_data_set_second,是為了避免再迭代error_data_set的時候,又對其進行洗掉、添加的操作,導致出現迭代例外,
import time
from urllib.request import urlopen
from bs4 import BeautifulSoup
from NbsRegionSpider.Bean.NbsRegionDTO import NbsRegionDTO
from NbsRegionSpider.NbsCycleSpider import cycleSpider
from NbsRegionSpider.SaveData import nbsDataToSaveBatch
from NbsRegionSpider.Util.UrlGetUtil import UrlGetUtil
'''國家統計局省級區域資料爬取 程式入口'''
base_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
urlGetUtilObj = UrlGetUtil()
#兩種方式二選一來爬取url頁面
#urlopern方式
html = urlGetUtilObj.getByUrlOpen(base_url,'gbk')
# request.get 方式
#html = urlGetUtilObj.getByRequestGet(base_url,'gbk')
'''
例外:Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.
https://www.cnblogs.com/HANYI7399/p/6080070.html
'''
#bs = BeautifulSoup(html, 'html.parser', from_encoding = "iso-8859-1")
bs = BeautifulSoup(html,'html.parser')
#找出存放省資訊的tr行
trs = bs.findAll('tr',{'class':'provincetr'})
#先取出所有的省資料節點
data_item_set = set()
for tr in trs:
tds = tr.findAll('td')
for td in tds:
a_flag = td.a
if a_flag is None:
continue
data_item_set.add(a_flag)
#全域變數,存盤爬取程序中出現錯誤的資料
error_data_set = set()
# 每一輪節點的回圈都是對一個省的資料處理
for a_flag in data_item_set:
# 本省所有行政區劃結果集
tar_obj_set = set()
#決議資料
province_name = a_flag.get_text()# 獲取省名稱
print('-'*12 +province_name+'---爬取開始'+ '-'*12)
province_code = ''
to_spider_url = a_flag['href']
if len(province_name) == 0:
continue
if len(to_spider_url) != 0:
province_code = ''.join(filter(str.isdigit, to_spider_url))#串列轉字串,獲取省一級code
# 省一級資料封裝成物體
tarObj = NbsRegionDTO(province_code,'',1,province_name,'')
grade_2_url = base_url + to_spider_url #基礎路徑拼接當前路徑 相當于 下一級的url決議路徑
tar_obj_set.add(tarObj)
#呼叫回圈方法,去決議子層級區域
tar_obj_set_result = cycleSpider(province_code,1,grade_2_url,error_data_set)
# 合并兩個集合結果集【取并集】
tar_obj_set = tar_obj_set | tar_obj_set_result
print('-'*12 +province_name+'---爬取結束'+'-'*12)
time.sleep(10)
#本省資料入庫存盤
try:
nbsDataToSaveBatch(tar_obj_set)
except Exception as e:
print('-'*12 +province_name+'---資料入庫存盤例外')
print(e)
#全國資料初次處理完畢,開始處理整體程序中失敗的資料,重試
print('------開始處理初次全國爬取失敗的資料,共------'+str(len(error_data_set))+'條')
while(len(error_data_set) > 0):
error_data_set_second = set()
for item in error_data_set:
tar_save_set = cycleSpider(item.parent_code, item.parent_level, item.to_parse_url,error_data_set_second)
#存盤入庫
try:
nbsDataToSaveBatch(tar_save_set)
except Exception as e:
print('---全國爬取程序的錯誤資料重試爬取后入庫存盤例外,---')
print(e)
for item in tar_save_set:
print(item.nbs_code + '-'*6 + item.nbs_parent_code + '-'*6 + str(item.nbs_level) + '-'*6 + item.nbs_name + '-'*6 + item.nbs_town_country_code)
#更新error_data_set
print('------再次失敗的資料,共------' + str(len(error_data_set_second)) + '條')
error_data_set = error_data_set_second
time.sleep(10)NbsCycleSpider:
'''
多層級回圈遞回呼叫決議區域,然后回傳資料集合
'''
import socket
import time
from urllib.error import HTTPError
from urllib.request import urlopen
from bs4 import BeautifulSoup
from NbsRegionSpider.Bean.NbsRegionDTO import NbsRegionDTO
from NbsRegionSpider.Bean.ParseErrorClass import ParseErrorClass
from NbsRegionSpider.Util.UrlGetUtil import UrlGetUtil
def cycleSpider(parent_code,parent_level,to_parse_url,error_data_set):
# 本次爬取行政區劃資料結果集
tar_obj_set = set()
#按層級使用不同的決議標簽關鍵字
tr_flag = ''
current_level = parent_level + 1#級別級別
if current_level == 2:
tr_flag = 'citytr'
elif current_level == 3:
tr_flag = 'countytr'
elif current_level == 4:
tr_flag = 'towntr'
elif current_level == 5:
tr_flag = 'villagetr'
else:
pass
#決議
try:
urlGetUtilObj = UrlGetUtil()
# urlopern方式
html = urlGetUtilObj.getByUrlOpen(to_parse_url,'gbk')
# request.get 方式
# html = urlGetUtilObj.getByRequestGet(to_parse_url,'gbk')
except socket.timeout:
print('parent_code = '+parent_code+'---待決議URL:' + to_parse_url + '請求超時')
# 暫時跳過,將出現例外的待決議資料暫存起來
error_data_set.add(ParseErrorClass(parent_code, parent_level, to_parse_url))
return tar_obj_set
except HTTPError as e:
print('parent_code = '+parent_code+'---待決議URL:' + to_parse_url + '出現http錯誤:')
print(e)
# 暫時跳過,將出現例外的待決議資料暫存起來
error_data_set.add(ParseErrorClass(parent_code, parent_level, to_parse_url))
return tar_obj_set
except Exception as e:
print('parent_code = '+parent_code+'---待決議URL:'+to_parse_url+'請求出現例外')
print(e)
#暫時跳過,將出現例外的待決議資料暫存起來
error_data_set.add(ParseErrorClass(parent_code,parent_level,to_parse_url))
return tar_obj_set
else:
pass
bs = BeautifulSoup(html, 'html.parser')
#獲取本頁所有資料節點
trs = bs.findAll('tr', {'class': tr_flag})
for tr in trs:
#注意,5極頁面有三個td,和別的等級頁面中的相同td位置,存放資料不是一樣的型別,所以進行判斷
td_1 = tr.find('td')#第一個td節點
current_code = td_1.get_text()
current_url = ''
current_name = ''
current_town_country_code = ''
td_2 = td_1.next_sibling#第二個td節點
if(current_level == 5):
current_town_country_code = td_2.get_text()
current_name = td_2.next_sibling.get_text()
else:
td_1_a = td_1.a
if td_1_a is not None: #比如青海省西寧市市轄區 ,才到三級,就咩有下級了,所以a標簽為None物件
current_url = td_1_a['href']
current_name = td_2.get_text()
#列印開始日志
if (current_level == 2):
print('-'*8 + current_name)
elif(current_level == 3):
print('-' * 4 + current_name)
#封裝資料
tarObj = NbsRegionDTO(current_code, parent_code, current_level, current_name, current_town_country_code)
tar_obj_set.add(tarObj)
# 遞回呼叫,獲取下級資料
tar_obj_set_result = set()
if (current_level != 5 and current_url != ''): # 五級一定沒有下級
# 當前決議頁面截取最后一個'/'之前的url ,再拼接當前頁面的href 就是下一級別的決議url
pos = to_parse_url.rfind("/")
next_url_data = to_parse_url[:pos] + '/' + current_url
tar_obj_set_result = cycleSpider(current_code,current_level,next_url_data,error_data_set)
# 合并兩個集合結果集【取并集】 并回傳
tar_obj_set = tar_obj_set | tar_obj_set_result
if(current_level == 2 or current_level == 3):
time.sleep(10)
return tar_obj_set
部分運行日志:
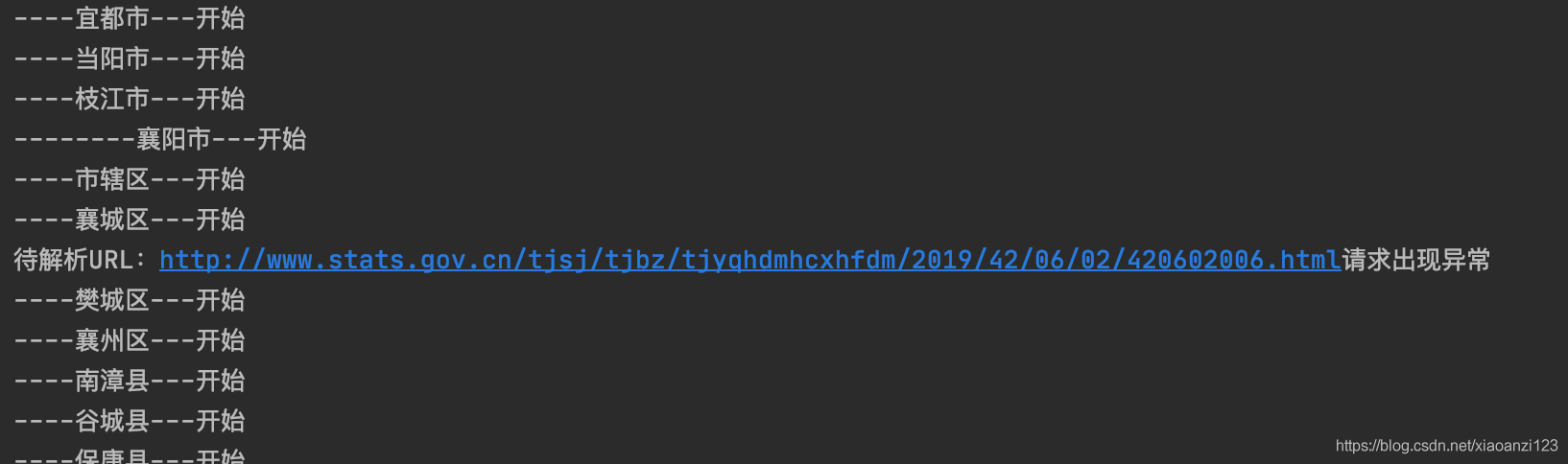
代碼中已經寫了詳細的步驟注釋,理解起來應該沒有什么問題,不過還有很大的改進空間,比如改當前的深度爬取為廣度爬取,可以有效降低服務器負載等,后續不斷積累經驗,越來越好吧,歡迎批評指正交流,
-----------------------------------20200911補充:
實際運行發行最后一直有三個url鏈接無法成功,一直在回圈重試、失敗著列印日志,別的資料都正常,這三個url為:
待決議URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/02/420602006.html
待決議URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/84/420684103.html
待決議URL:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/51/06/81/510681114.html
例外如下:'gbk' codec can't decode byte 0xfe in position 3068: illegal multibyte sequence
是編碼問題,然而別的資料都是用的gbk都沒問題,這個已經也在網頁源代碼中確認,說明這三個url有問題,
參考文章:https://blog.csdn.net/zangbianer/article/details/84526011 ,使用gb18030 問題解決,
為了針對這三個資料處理,我對原有代碼做了一點重構:
新建新的類M,代碼如下,專門用于處理一直失敗的資料,同時為了復用代碼,把原來NbsMain中的對錯誤資料處理的代碼抽取出來,放到下面的handle_error_retry()中,然后把爬取鏈接引數處的gbk改為gb18030,運行下面的M代碼,即可,
'''
對于一直處理報錯的url,最終手動處理
'''
import time
from NbsRegionSpider.Bean.ParseErrorClass import ParseErrorClass
from NbsRegionSpider.NbsCycleSpider import cycleSpider
from NbsRegionSpider.SaveData import nbsDataToSaveBatch
'''
出現錯誤的資料重試方法
'''
def handle_error_retry(error_data_set):
while (len(error_data_set) > 0):
error_data_set_second = set()
for item in error_data_set:
tar_save_set = cycleSpider(item.parent_code, item.parent_level, item.to_parse_url, error_data_set_second)
# 存盤入庫
try:
nbsDataToSaveBatch(tar_save_set)
except Exception as e:
print('---全國爬取程序的錯誤資料重試爬取后入庫存盤例外,---')
print(e)
for item in tar_save_set:
print(item.nbs_code + '-' * 6 + item.nbs_parent_code + '-' * 6 + str(
item.nbs_level) + '-' * 6 + item.nbs_name + '-' * 6 + item.nbs_town_country_code)
# 更新error_data_set
print('------再次失敗的資料,共------' + str(len(error_data_set_second)) + '條')
error_data_set = error_data_set_second
time.sleep(10)
data_set = set()
'''
所有的資料中就只有這三個一直失敗,別的都成功,例外如下:
'gbk' codec can't decode byte 0xfe in position 3068: illegal multibyte sequence
網頁編碼的確時gbk沒錯的,參考文章:https://blog.csdn.net/zangbianer/article/details/84526011
改為 gb18030成功解決,
又看了下這三個url網頁,發現每一頁中都有一條資料的地名中,包含特殊字符,網頁上顯示的是一個小方格,罪魁禍首就是他了,
一共這三個名字包含未知字符的地點的code是:510681114209 420684103005 420602006207
'''
data_set.add(ParseErrorClass('420602006000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/02/420602006.html'))
data_set.add(ParseErrorClass('420684103000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/42/06/84/420684103.html'))
data_set.add(ParseErrorClass('510681114000', 4,'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/51/06/81/510681114.html'))
handle_error_retry(data_set)
這三個url中的元兇被我給揪了出來;
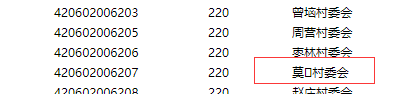
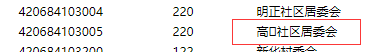

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/20052.html
標籤:其他