預測GDP應用:Numpy 線性回歸+Matplotlib 作圖
需求
通過2000~2019年中美兩國的GDP資料,預測后續幾年GDP的發展趨勢:
- 讀取.csv檔案,并將字串調整為浮點型
- 進行二階線性回歸模擬
- 支持資料可視化
保命宣告:用線性回歸預測GDP發展并不合理,只是作為python學習參考,
如果想要了解更有意義的GDP對比可以參考b站翟老師的:https://b23.tv/6aYFVf
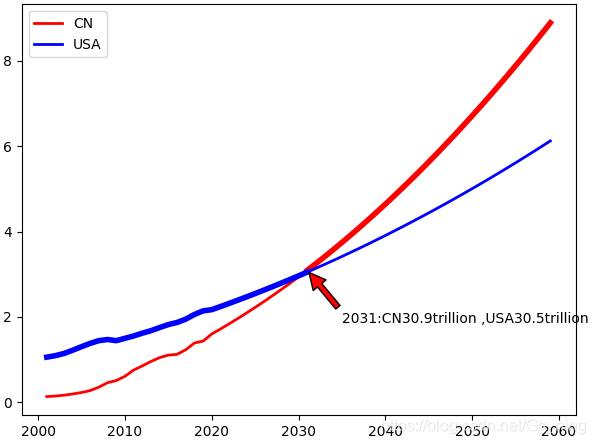
成品效果
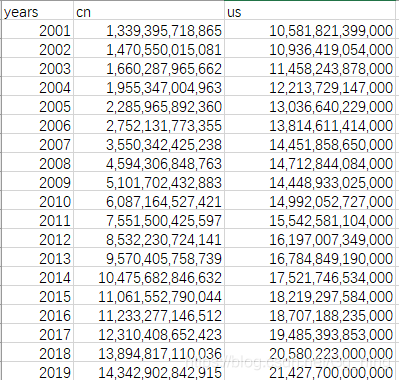
原資料格式
.csv 檔案(“testgdp.csv”),gdp資料每千位均被 “,” 隔開
需求拆解
1、csv檔案讀取
以測驗檔案"testgdp.csv"為例,目標將csv資料讀取成適合進行線性回歸的格式ndarray
方法一:pandas的 read_csv()函式
import pandas as pd
import numpy as np
data = pd.read_csv("testgdp.csv")
df = pd.DataFrame(data)
print(df.head())
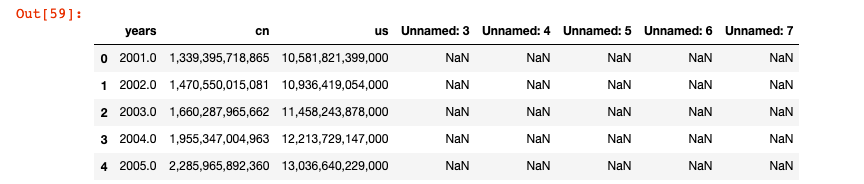
years = np.array(df.years) #可以轉化為 ndarray
years

方法二: python自帶的 open()函式
import csv
import numpy as np
data_list = []
with open("testgdp.csv",encoding = 'utf-8') as csvfile:
csv_reader = csv.reader(csvfile)
for row in csv_reader:
data_list.append(row[0:3])#第3~7列為空資料,需要排除
data1 = np.array(data_list)
data2 = np.delete(data1,-1,axis=0)#洗掉最后一行空值行,axis=1時可洗掉列
data2

2、對“xxx,xxx,xxx”格式字串轉化為數字
split():用指定分隔符對 字串 進行切片,變為 list
strr.split (str="", num=string.count(str))
- strr 為原字串
- str 為分隔符號
- num – 分割次數,默認為 -1, 即分隔所有
def intt(list,exc_rate=1):#將"xxx,xxx,xxx,xxx,xxx"格式的str轉化為 整型,exc_rate為匯率
list_new = []
for strr in list:
int_list = strr.split(',') # 分割str,轉化為串列
lenth = len(int_list)
result = 0
for n in range(lenth):
ii = int(int_list[n])
result = result + ii*1000**(lenth-n-1)*exc_rate
list_new.append(result)
return list_new
list = ['11,061,552,790,044','14,342,902,842,915','234,322,342,111','123,212,231']
intt(list)
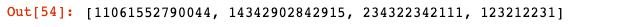
3、線性回歸:np.polyfit()多項式擬合、np.polyval()多項式曲線求值
P = np.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)
x, y:一般是array格式的陣列,分別代表自變數和因變數deg:階數(需要整型),即需要進行幾階線性回歸- 其他資料不太常用,可以不輸入,即使用默認引數,如果需要了解可以參考:numpy.polyfit
輸出引數 P為擬合多項式
P
(
1
)
x
n
+
P
(
2
)
x
n
?
1
+
.
.
.
+
P
(
n
)
x
+
P
(
n
+
1
)
的
系
數
組
合
P(1)x^n + P(2)x^{n-1} +...+ P(n)x + P(n+1) 的 系陣列合
P(1)xn+P(2)xn?1+...+P(n)x+P(n+1)的系數組合
如 P 為[ 1, 2, 3]時,代表多項式線性回歸的結果為
Y
=
x
2
+
2
x
+
3
Y = x^2+2x+3
Y=x2+2x+3
可以用np.polyval()方法輸出預測結果Y,即
Y = np.polyval(P, x)
4、模塊輸出可視化圖表
要用到matplotlib.pyplot,這個模塊內容非常非常多,現在根據需求選取幾個易用的函式
官方檔案:https://matplotlib.org/api/pyplot_api.html
功能一:繪制關系曲線
繪制一條x,y關系曲線,紅色,寬度為2,標簽為label
plt.plot(x, y, color="red”,linestyle="-", linewidth=2.0, label=‘label')
x, y:與前面的x, y相同,支持array格式的陣列,分別代表自變數和因變數- 設定
label標簽有助于后續生成圖例
import matplotlib.pyplot as plt
x=[1,2,3,5]
y=[2,3,5,9]
plt.plot(x, y,color="red",linestyle="-", linewidth=2.0,label='label1')
plt.show()
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-JbJa664r-1599808354505)(/Users/zhangning/Library/Application Support/typora-user-images/image-20200911145804341.png)]](https://img.uj5u.com/2020/09/13/60713130425397.png)
功能二:新增圖例
plt.legend(loc=*'best'*,label=lable_list)
loc=‘best’時圖例自動‘安家’在一個坐標面內的資料圖表最少的位置,可以設定為指定位置,
參考鏈接:https://zhuanlan.zhihu.com/p/111108841

功能三:箭頭標注關鍵資訊
對第三個坐標點用紅色箭頭標注,箭頭離坐標相差0.05個單位,同時在(4,2)提醒’this is the annotate’.
plt.annotate('this is the annotate', xy=(x[2],y[2]), xycoords='data', xytext=(4,2),
arrowprops=dict(facecolor='red', shrink=0.05))
可以參考https://blog.csdn.net/wizardforcel/article/details/54782628
實體代碼
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def intt(list,exc_rate=1):#將"xxx,xxx,xxx,xxx,xxx"格式的str轉化為 整型,exc_rate為匯率
list_new = []
for strr in list:
int_list = strr.split(',') # 分割str,轉化為串列
lenth = len(int_list)
result = 0
for n in range(lenth):
ii = int(int_list[n])
result = result + ii*1000**(lenth-n-1)*exc_rate
list_new.append(result)
return list_new
def pre(n):#n為預測時間(年)
data = pd.read_csv("testgdp.csv")
df = pd.DataFrame(data)
df = df.drop([19])#洗掉空行
years = np.array(df.years)
cn = intt(np.array(df.cn))
usa = intt(np.array(df.us))
model_cn = np.polyfit(years,cn,2)#階線性回歸cn
model_usa = np.polyfit(years,usa,2)#2階維線性回歸usa
overyear_list = []
overusa_list = []
overcn_list = []
for i in range(n):#預測n年后gdp資料表現
yy=2020+i
cn_gdp=np.polyval(model_cn,yy)
usa_gdp=np.polyval(model_usa,yy)
if cn_gdp>usa_gdp:#判斷何時中國gdp超過美國,并記錄下來
overyear_list.append(yy)
overusa_list.append(usa_gdp)
overcn_list.append(cn_gdp)
cn = np.append(cn,cn_gdp)
usa = np.append(usa,usa_gdp)
years=np.append(years,yy)
plt.plot(years, cn,color="red",linestyle="-", linewidth=2.0,label='CN')
plt.plot(overyear_list, overcn_list, color="red", linestyle="-", linewidth=4.0)#加粗超過美國的部分
plt.plot(years, usa,color="blue",
linestyle="-", linewidth=2.0,label='USA')
plt.plot(years[0:len(years)-len(overyear_list)+1],
usa[0:len(years)-len(overyear_list)+1],
color="blue", linestyle="-", linewidth=4.0)
plt.legend(loc='upper left')#圖例,位置左上
plt.annotate(s=("%d:CN%.1ftrillion ,USA%.1ftrillion"%(overyear_list[0],overcn_list[0]/(10**12),overusa_list[0]/(10**12))),xy=(overyear_list[0],overcn_list[0]),
xytext=(overyear_list[0]+n/10,overcn_list[0]*0.6)
,arrowprops=dict(facecolor='red', shrink=0.05))#arrowprops箭頭
plt.show()
pre(40)
后續進階
- 增加爬蟲功能(合法的那種!)
- 優化可視化圖表(增加圖表樣式,增加影像互動能力,如呼叫Pyecharts)
- 增加更多緯度資料,采用邏輯回歸
- 增加與資料庫對接的功能
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/20056.html
標籤:其他