宣告:本博客只是簡單的爬蟲示范,并不涉及任何商業用途,
一.前言
最近博主在瀏覽淘寶時突然萌發了一個想爬它的念頭,于是說干就干,我便開始向淘寶“下毒手”了,由于本人平時經常喜歡在淘寶上瀏覽各種手機的資訊,于是我便以“手機”為關鍵詞進行搜索,最后我利用爬蟲獲取了所有相關的手機資訊,并對各種廠家生成手機的銷量進行了一波可視化,下面是完整的記錄程序,
二.爬蟲程序
2.1 解決淘寶的登錄問題
首先,我在瀏覽器中打開淘寶,然后登錄后以手機為關鍵詞進行搜索,得到如下鏈接:
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200911&ie=utf8
但當我用requests庫請求該url時,結果卻發現要先登錄,即會出現下述界面:

這個問題要如何解決呢?我首先想到的是利用cookie,于是我便在登錄淘寶時,通過Chrome瀏覽器的開發者工具獲取到了登錄淘寶的cookie,然后我將該cookie作為引數傳入reqeusts庫的相關函式,結果發現成功獲取到想要的頁面!
2.2 頁面URL分析
在頁面的下方可以看到手機售賣的頁面共有100頁,那么要如何獲取到對應的頁面呢?我先點擊下方的按鈕獲取到了幾個頁面的url,展示如下:
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200911&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200911&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200911&ie=utf8&bcoffset=-3&ntoffset=-3&p4ppushleft=1%2C48&s=132
根據觀察上述url中變化的只有bcoffset,ntoffset以及s,但是只有最后一個引數s改變才會使得頁面翻轉,而最后一個引數s是遞增的,每次增加44,因此我們可以通過改變s來獲取翻頁的URL,
2.3 資料提取
在淘寶頁面右鍵->查看源代碼,可以發現資料資料隱藏在名為g_page_config的json物件里面:

因此,可以先通過正則運算式將其過濾出來,然后利用json模塊將其加載為python物件,之后便可以對其進行資料提取(詳細的提取程序參加后面的完整代碼),需要提取的資料展示如下:

2.4 爬蟲完整流程
綜合以上幾點,淘寶手機資訊爬取的流程圖如下圖所示:
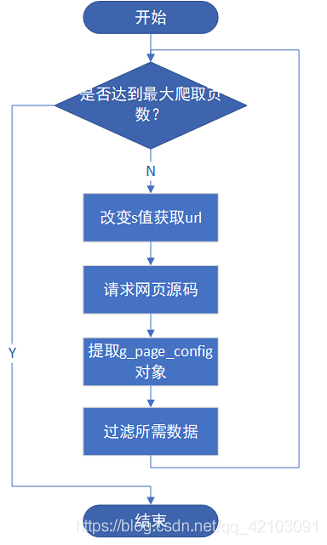
2.5 爬取程式及結果展示
完整的爬蟲程式展示如下:
from bs4 import BeautifulSoup
import requests
import re
import json
import random
import pandas as pd
import traceback
IPRegular = r"(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])"
headers = {
"User-Agent": "換成自己的User-Agent",
"cookie": "換成自己登錄的淘寶cookie"
}
def ExtractIP(url="https://ip.ihuan.me/"):
"""
功能:抓取IP,回傳IP串列
url:抓取IP的網站
"""
IPs = []
response = requests.get(url)
soup = BeautifulSoup(response.content,"lxml")
tds = soup.find_all("a",attrs = {'target':'_blank'})
for td in tds:
string = td.text
if re.search(IPRegular,string) and string not in IPs:
IPs.append(string)
print(IPs)
return IPs
def Filter(mobile_infos):
"""
功能:過濾出手機的相關資訊
mobile_infos:
"""
mobile_list = [] #存盤手機資訊的串列
for mobile_info in mobile_infos:
title = mobile_info['raw_title']
price = mobile_info['view_price']
loc = mobile_info['item_loc'].replace(' ','')
shop = mobile_info['nick']
#print(mobile_info['view_sales'])
sales = re.search(r'(\d+.?\d*).*人付款',mobile_info['view_sales']).group(1)
if sales[-1] == '+':#去掉末尾的加號
sales = sales[:-1]
if '萬' in mobile_info['view_sales']:
sales = float(sales) * 10000
print(title,price,loc,shop,int(sales),mobile_info['view_sales'])
mobile_list.append([title,price,loc,shop,int(sales)])
return mobile_list
def Saver(mobiles):
"""
功能:保存爬取資訊
mobiles:手機資訊串列
"""
mdata = pd.DataFrame(mobiles,columns=['手機名','價格','店鋪位置','店鋪名','銷量'])
mdata.to_csv('mobile_info.csv',index=False)
def Spider(page_nums = 100):
"""
功能:爬蟲主程式
page_nums:待爬取的頁數
"""
#爬取代理IP
IPs = ExtractIP()
length,mobiles,i = len(IPs),[],0
while i < page_nums:
try:
print('--------------------正在爬取第{}頁--------------------'.format(i + 1))
url = "https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=0&p4ppushleft=1%2C48&data-key=s&data-value={}".format(i*44)
#設定代理ip
index = random.randint(0,length - 1)
proxies = {"http":"{}:8080".format(IPs[index])}
#請求網頁
response = requests.get(url,headers=headers,proxies=proxies)
#利用正則運算式獲取包含手機資訊json資料
match_obj = re.search(r'g_page_config = (.*?)};',response.text)
#將json物件加載為python字典
mobile_infos= json.loads(match_obj.group(1) + '}')['mods']['itemlist']['data']['auctions']
#過濾出字典中的有用資訊
mobiles += Filter(mobile_infos)
i += 1
except Exception:
traceback.print_exc()
print('手機資訊第{}頁爬取失敗'.format(i + 1))
i += 1
#保存手機資訊為csv檔案
Saver(mobiles)
if __name__ == "__main__":
Spider()
利用上述方式將爬取的資料保存為csv檔案,部分結果截圖展示如下:

三.資料處理及分析
3.1 資料去重
通過爬蟲一共獲取到4400多條記錄,但其中有沒有重復資料呢,于是我通過pandas來對其進行重復行統計,結果確實返現不少重復行,對應處理代碼如下:
import pandas as pd
mdata = pd.read_csv('mobile_info.csv')
print(mdata[mdata.duplicated()])
"""
手機名 價格 店鋪位置 店鋪名 銷量
61 【限時限量搶】Apple/蘋果iPhone SE全網通手機蘇寧易購官方旗艦店Store國行正... 3299.00 江蘇南京 蘇寧易購官方旗艦店 2998
92 糖果手機Sugar Y9指紋識別全網通5 399.00 廣東深圳 sugar手機旗艦店 6
93 現貨OnePlus/一加 A6010一加6T手機1+6T手機 1439.00 廣東深圳 港柏數碼 301
136 糖果手機Sugar Y9指紋識別全網通5 399.00 廣東深圳 sugar手機旗艦店 6
137 現貨OnePlus/一加 A6010一加6T手機1+6T手機 1439.00 廣東深圳 港柏數碼 301
180 糖果手機Sugar Y9指紋識別全網通5 399.00 廣東深圳 sugar手機旗艦店 6
181 現貨OnePlus/一加 A6010一加6T手機1+6T手機 1439.00 廣東深圳 港柏數碼 301
... ... ... ... ...
"""
因此我在這里進行了相應的去重處理,代碼為:
mdata.drop_duplicates(inplace=True)
3.2 統計各手機的銷量
在完成去重后,我對各手機的銷量進行了統計,最后利用matplotlib將統計資料繪制成了直方圖,下面是對應的結果:
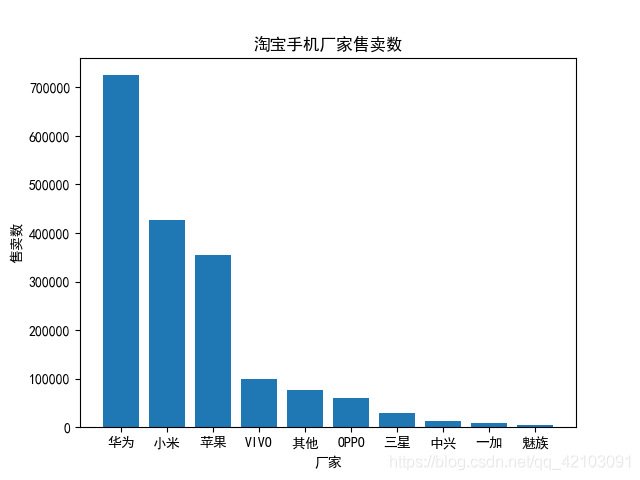
可以看出華為,小米和蘋果占據了銷量的前三甲,
四.結語
完整專案地址:taobao_mobileInfo_demo
以上便是本文的全部內容,要是決定不錯的話就點個贊支持一下吧,你們的支持是博主創作的不竭動力!另外在這里需要說明一下,我爬取的資料可能不齊全,最后的各手機廠家銷量展示也不具有權威性,僅僅是博主的自娛自樂,敬請批評指正,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/20076.html
標籤:其他
上一篇:selenium 知網爪巴蟲
下一篇:【Python爬蟲+js逆向】使用Python爬取騰訊漫畫的逆向分析(典型簽名驗證反爬蟲的解決方案)——以騰訊動漫《一人之下》第一話為例