前一段假期期間,博主已經自學完了Python反爬蟲的相關內容,面對各大網站的反爬機制也都有了一戰之力,可惜因實戰經驗不足,所以總體來說還是一個字——菜,前兩天,在學習并實戰爬取了博主最愛看的騰訊動漫后,博主對于js逆向的相關反爬技術有了更加深入的理解,
目錄
- 目標網站爬取分析
- 反爬思路分析
- 反爬解密分析
- Python代碼實戰分析
- 解密資料獲取
- JavaScript逆向
- 漫畫資料決議
- 整體代碼優化
- 整體代碼
- Pyinstaller打包
- 效果展示
- 總結
目標網站爬取分析
反爬思路分析
首先打開騰訊漫畫《一人之下》的第一話(目標網址:https://ac.qq.com/ComicView/index/id/531490/cid/1),打開開發者工具(F12),切換到網路選項卡(Network)下,下拉滾動漫畫可以發現其中的圖片不斷地加載出來(類似微博的滾動機制),
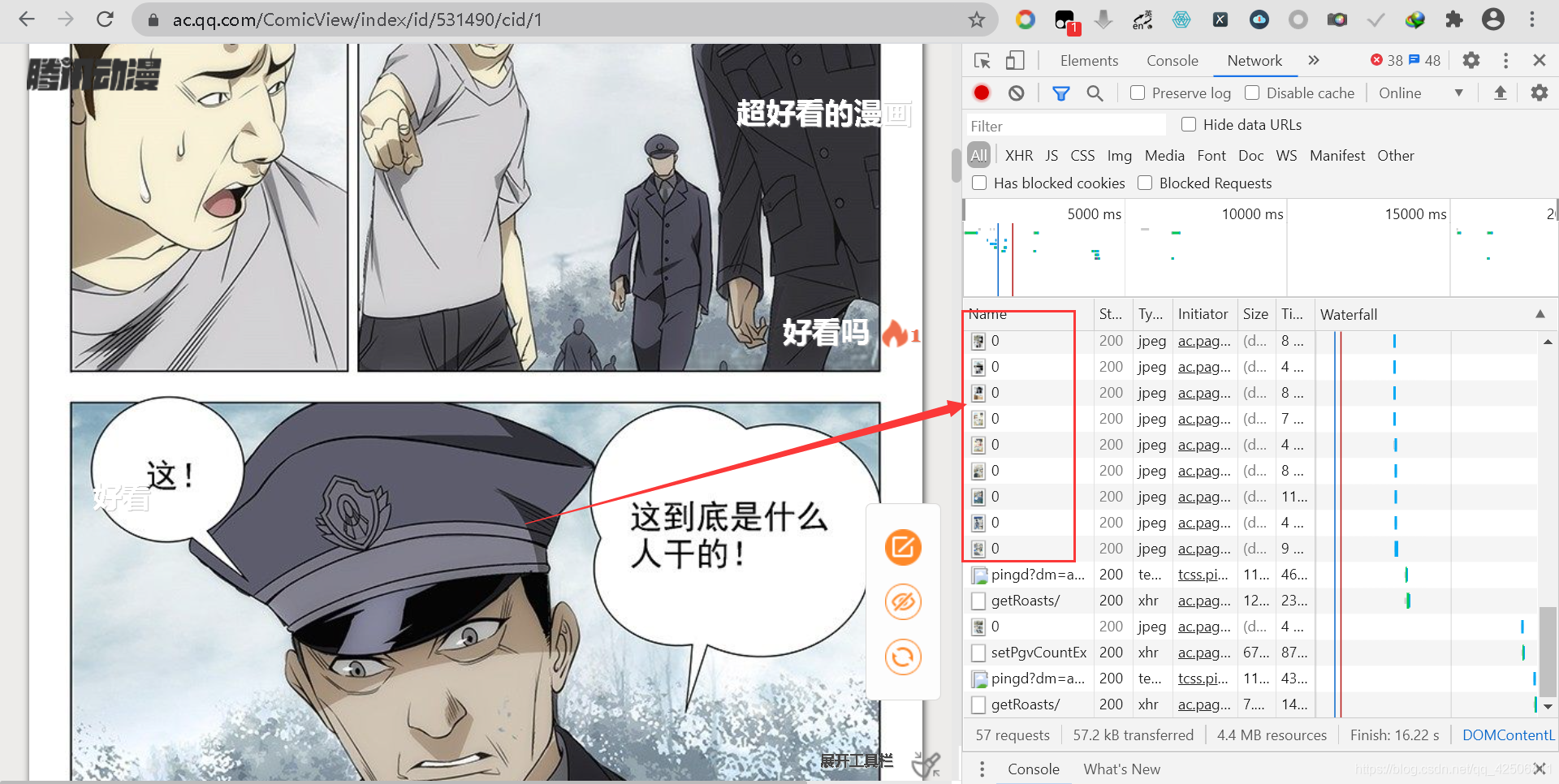
因此,初步判斷騰訊動漫可能是動態加載的,所以此時切換至XHR標簽下,
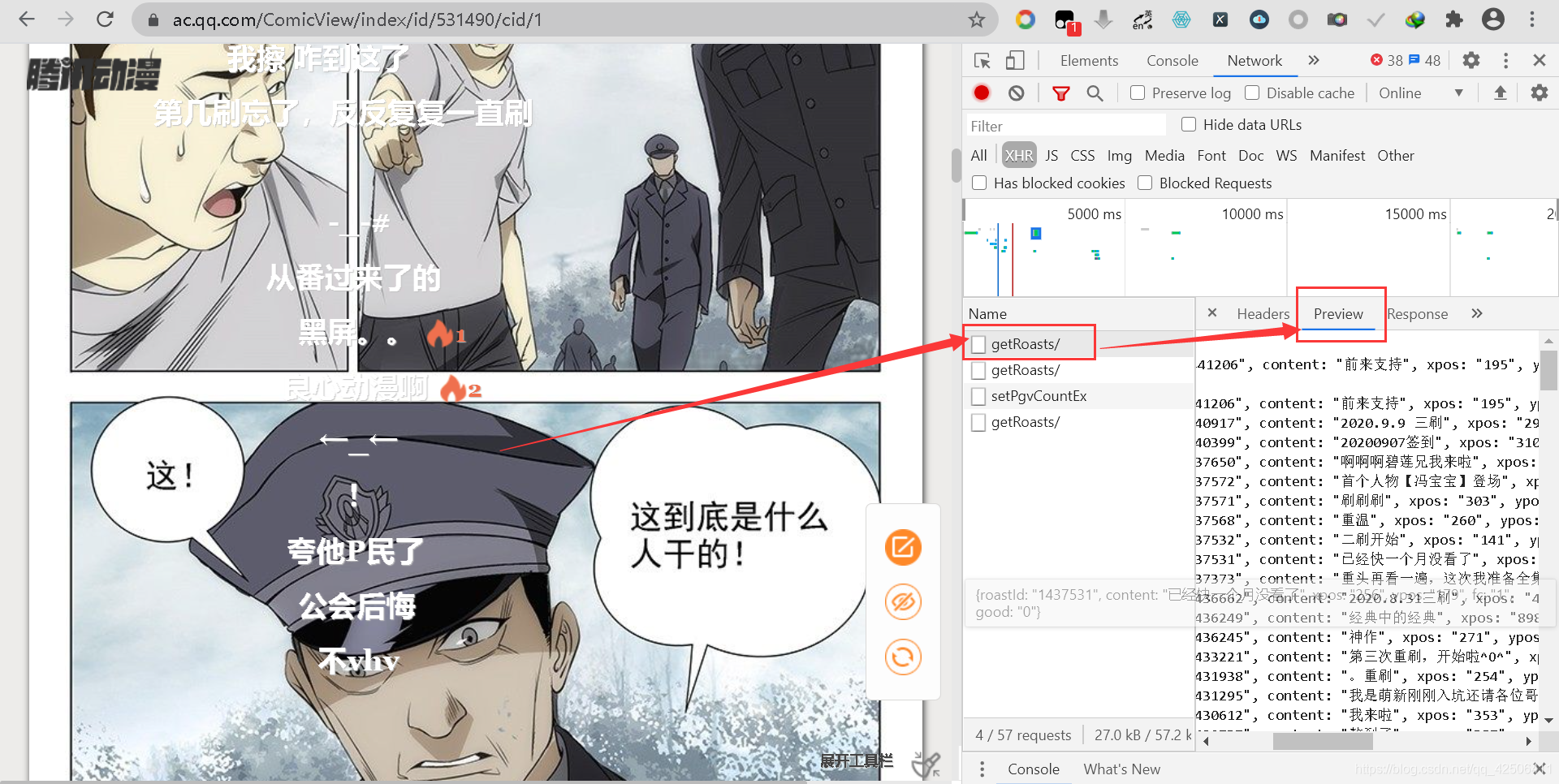
然而,在XHR標簽下,我們只能通過Preview發現騰訊漫畫中的彈幕資訊,其他則是什么都沒有,
此路不可行,那么我們復制圖片的地址在全域進行搜索(CTRL+F),
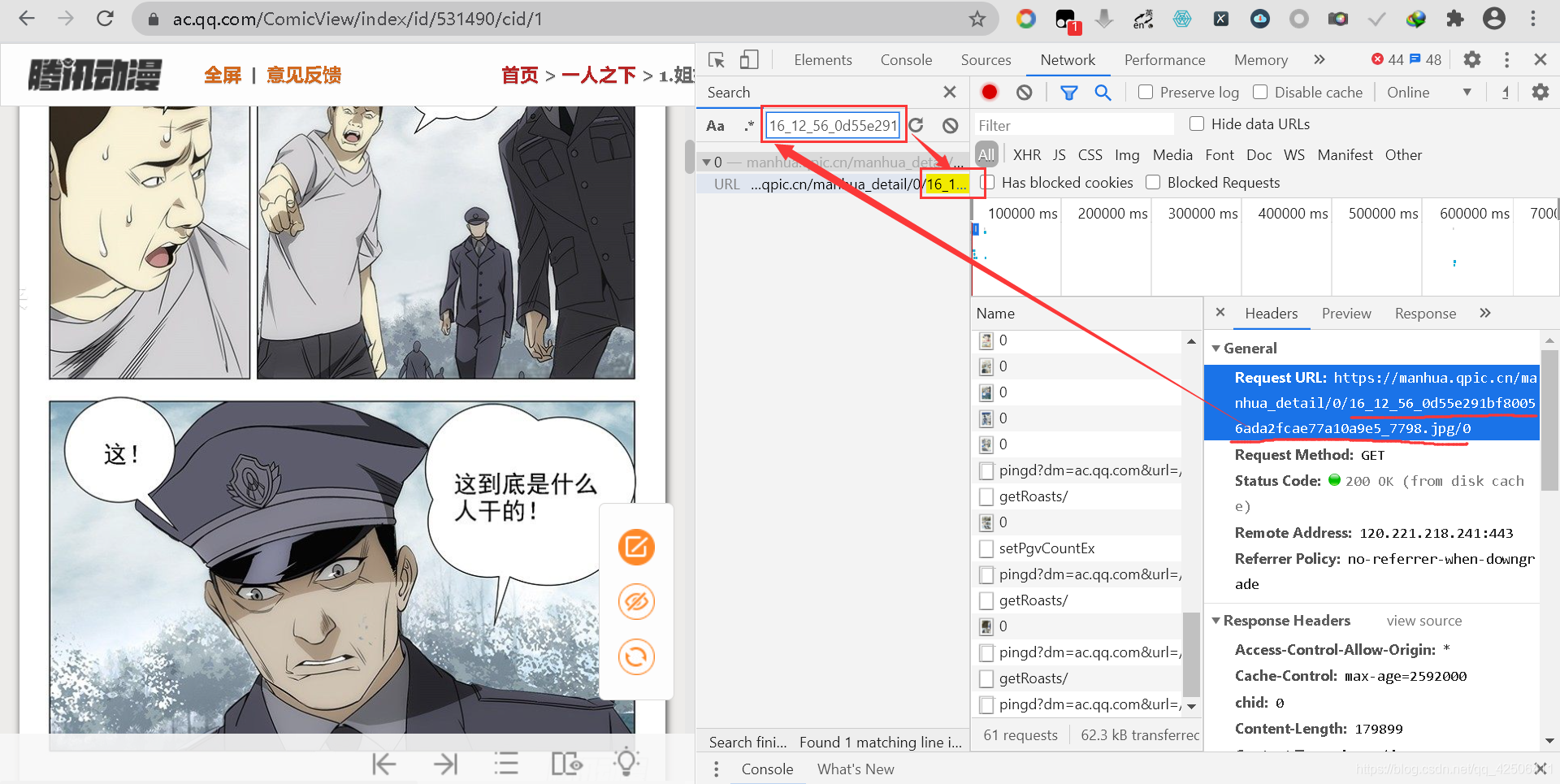
通過搜索可發現,除了Network中加載的圖片自身,圖片地址不存在于其他的任何地方,因此,我們得出這么一條結論:圖片地址既沒有動態加載,也沒有在其他源代碼中,說明圖片地址被加密存放到了某個地方,除去圖片、css、js這些,唯一剩下的可能性便是在主頁了,所以我們直接切換到Element選項卡中去觀察主頁的源代碼,并且重點關注script標簽下的內容,
縱觀整個主頁的源代碼,唯一可能存放加密資料的只有body結尾處的script標簽下(顯眼的DATA資料),
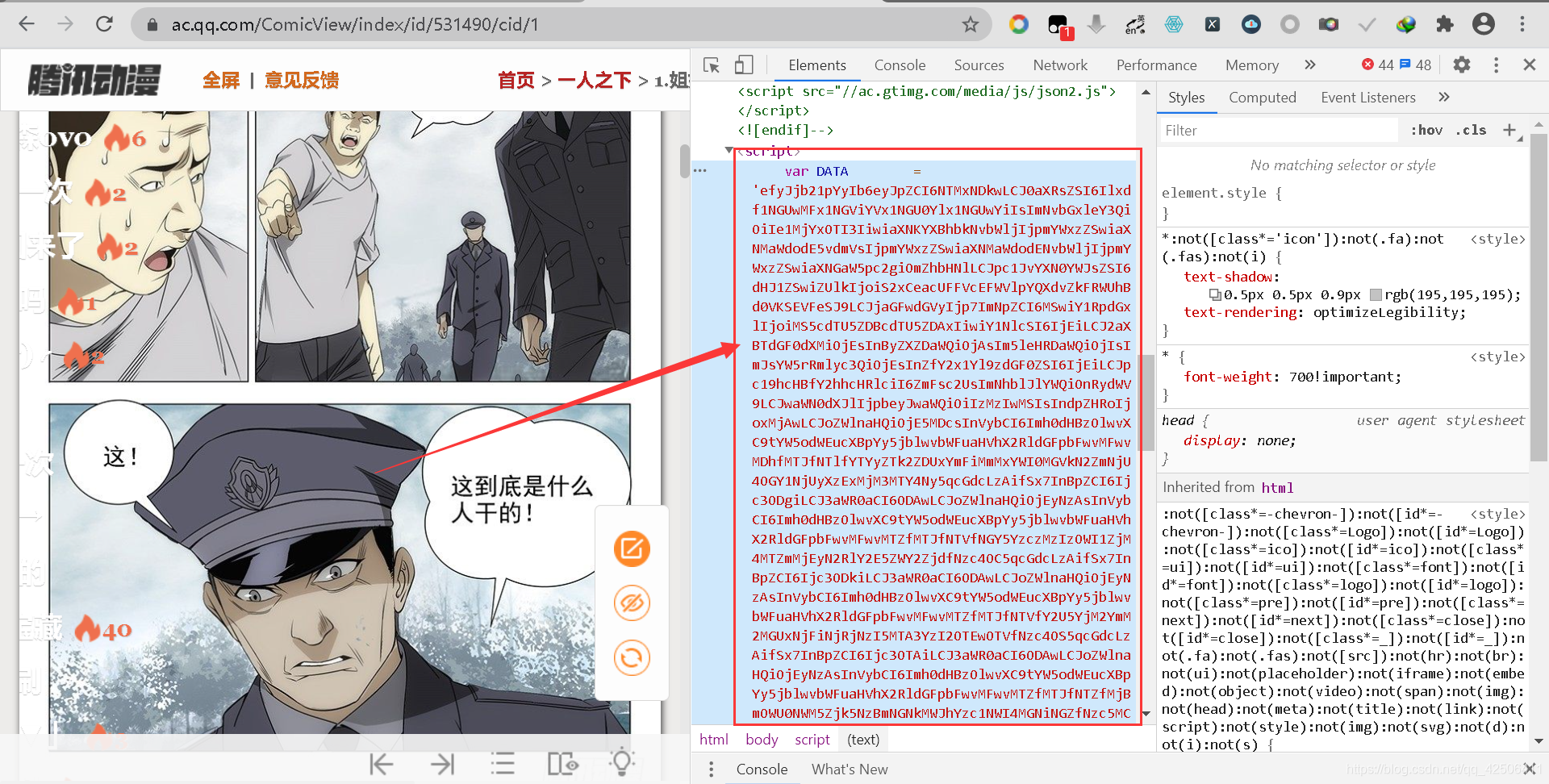
反爬解密分析
經過上述分析后,我們確定了scrpit標簽下的目標內容,初步判斷DATA變數有可能就是加密后的資料,
var DATA = 'efyJjb21pYyIb6eyJpZCI6NTMxNDkwLCJ0aXRsZSI6Ilxdf1NGUwMFx1NGViYVx1NGU0Ylx1NGUwYiIsImNvbGxleY3QiOiIe1MjYxOTI3IiwiaXNKYXBhbkNvbWljIjpmYWxzZSwiaXNMaWdodE5vdmVsIjpmYWxzZSwiaXNMaWdodENvbWljIjpmYWxzZSwiaXNGaW5pc2giOmZhbHNlLCJpc1JvYXN0YWJsZSI6dHJ1ZSwiZUlkIjoiS2xCeacUFFVcEFWVlpYQXdvZkFRWUhBd0VKSEVFeSJ9LCJjaGFwdGVyIjp7ImNpZCI6MSwiY1RpdGxlIjoiMS5cdTU5ZDBcdTU5ZDAxIiwiY1NlcSI6IjEiLCJ2aXBTdGF0dXMiOjEsInByZXZDaWQiOjAsIm5leHRDaWQiOjIsImJsYW5rRmlyc3QiOjEsInZfY2x1Yl9zdGF0ZSI6IjEiLCJpc19hcHBfY2hhcHRlciI6ZmFsc2UsImNhblJlYWQiOnRydWV9LCJwaWN0dXJlIjpbeyJwaWQiOiIzMzIwMSIsIndpZHRoIjoxMjAwLCJoZWlnaHQiOjE5MDcsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMDhfMTJfNTlfYTYyZTk2ZDUxYmFiMmMxYWI0MGVkN2ZmNjU4OGY1NjUyXzExMjM3MTY4Ny5qcGdcLzAifSx7InBpZCI6Ijc3ODgiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTVfNGY5YzczMzIzOWI1ZjM4MTZmMjEyN2RlY2E5ZWY2ZjdfNzc4OC5qcGdcLzAifSx7InBpZCI6Ijc3ODkiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTVfY2U5YjM2YmM2MGUxNjFiNjRjNzI5MTA3YzI2OTEwOTVfNzc4OS5qcGdcLzAifSx7InBpZCI6Ijc3OTAiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMjBmOWU0NWM5Zjk5NzBmNGNkMWJhYzc1NWI4MGNiNGZfNzc5MC5qcGdcLzAifSx7InBpZCI6Ijc3OTEiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYTM0ODEyNGUyYzBlZTJkYjg5NTVmOWI4YTNhYjVkODhfNzc5MS5qcGdcLzAifSx7InBpZCI6Ijc3OTIiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzAyOWU5MjU4NTI3M2MzNzMwN2MyZTE5Mjk0OTEwNzdfNzc5Mi5qcGdcLzAifSx7InBpZCI6Ijc3OTMiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMDUwNDAxYjdlNjMyNDFhODhhMjYwYzgxM2FlODIzNGZfNzc5My5qcGdcLzAifSx7InBpZCI6Ijc3OTQiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfZmYzMzNhNWRmYTA1NzdmMTExODE1ZDFiODVjMzdhM2NfNzc5NC5qcGdcLzAifSx7InBpZCI6Ijc3OTUiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNDVhYTAwMTAyYTVjNzk0Yzg2ZWY1MDE3YzFhNDZkYWNfNzc5NS5qcGdcLzAifSx7InBpZCI6Ijc3OTYiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzZhNDI0MjM4NTUwNmZhMDE3MGY5M2E2YWNhYWQwMWRfNzc5Ni5qcGdcLzAifSx7InBpZCI6Ijc3OTciLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfZGNlMGM3YjU4NWQyMDhlNjY0Y2JhMjg1MDEzM2EwZWRfNzc5Ny5qcGdcLzAifSx7InBpZCI6Ijc3OTgiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMGQ1NWUyOTFiZjgwMDU2YWRhMmZjYWU3N2ExMGE5ZTVfNzc5OC5qcGdcLzAifSx7InBpZCI6Ijc3OTkiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYzhhZDNkMzI2OGYyMGVlNDU5YzU3NGU1NDRmYjQxMzVfNzc5OS5qcGdcLzAifSx7InBpZCI6Ijc4MDAiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMjBkZTExNWNkZTNhYzlmOTJlMjc0MWQ0MzY3OWM4N2NfNzgwMC5qcGdcLzAifSx7InBpZCI6Ijc4MDEiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzEsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzBmMmEwNDE3NTViNjc2ODcwNjNmMzJlMTJlN2NkMWRfNzgwMS5qcGdcLzAifSx7InBpZCI6Ijc4MDIiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYzQxZWI2M2JiNTZmNTRhNDcyMzk4ZjhlYjBlZGE4MmNfNzgwMi5qcGdcLzAifSx7InBpZCI6Ijc4MDMiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfOTVlMzVlM2FiMGQ2OWY2NTk0NTMyZjA3NDAzZmYyZGZfNzgwMy5qcGdcLzAifV0sImFkcyI6eyJ0b3AiOnsidGl0bGUiOiJcdTUxNmNcdTc2Y2EiLCJ1cmwiOiJodHRwczpcL1wvd2VpYm8uY29tXC81NjE2NTQ5MzY5XC9KamNKNWI1aTU/ZnJvbT1wYWdlXzEwMDIwNjU2MTY1NDkzNjlfcHJvZmlsZSZ3dnI9NiZtb2Q9d2VpYm90aW1lJnR5cGU9Y29tbWVudCNfcm5kMTU5OTUzNDY0NTIwNSIsInBpYyI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvb3BlcmF0aW9uXC8wXC8wOF8xMV8yNV82MTk2ODNjMDYyNGNjNjhkYjExYmVjZTVhNzA2ZmYzOV8xNTk5NTM1NTUxNzMxLmpwZ1wvMCJ9LCJib3R0b20iOiIifSwiYXJ0aXN0Ijp7ImF2YXRhciI6Imh0dHBzOlwvXC9cL3EzLnFsb2dvLmNuXC9nP2I9cXEmaz01aHZlUkRSRGNxenZVeURFSE95TnFnJnM9MTAwJnQ9MTQ5NzcwMTk2NSIsIm5pY2siOiJcdTUyYThcdTZmMmJcdTU4MDJcdTVjMGZcdTRlZDkiLCJ1aW5DcnlwdCI6Ik1YZzFVRUZFY0RaS1lqWnBjSEZqYnl0ellrbG5kejA5In19',
PRELOAD_NUM = 2,
NOTICE_TIME = 15,
ROAST_SIZE = 1000,
ROAST_PRE = 20,
ROAST_VIEW = 20,
TUCAO_INTERVAL = 8000,
DANMU_INTERVAL = 2000,
DANMU_TIME = 10000;
我們需要想辦法解密這段DATA資料,因此,切換到Network選項卡并繼續在全域中搜素“DATA”,這里注意要區分大小寫!
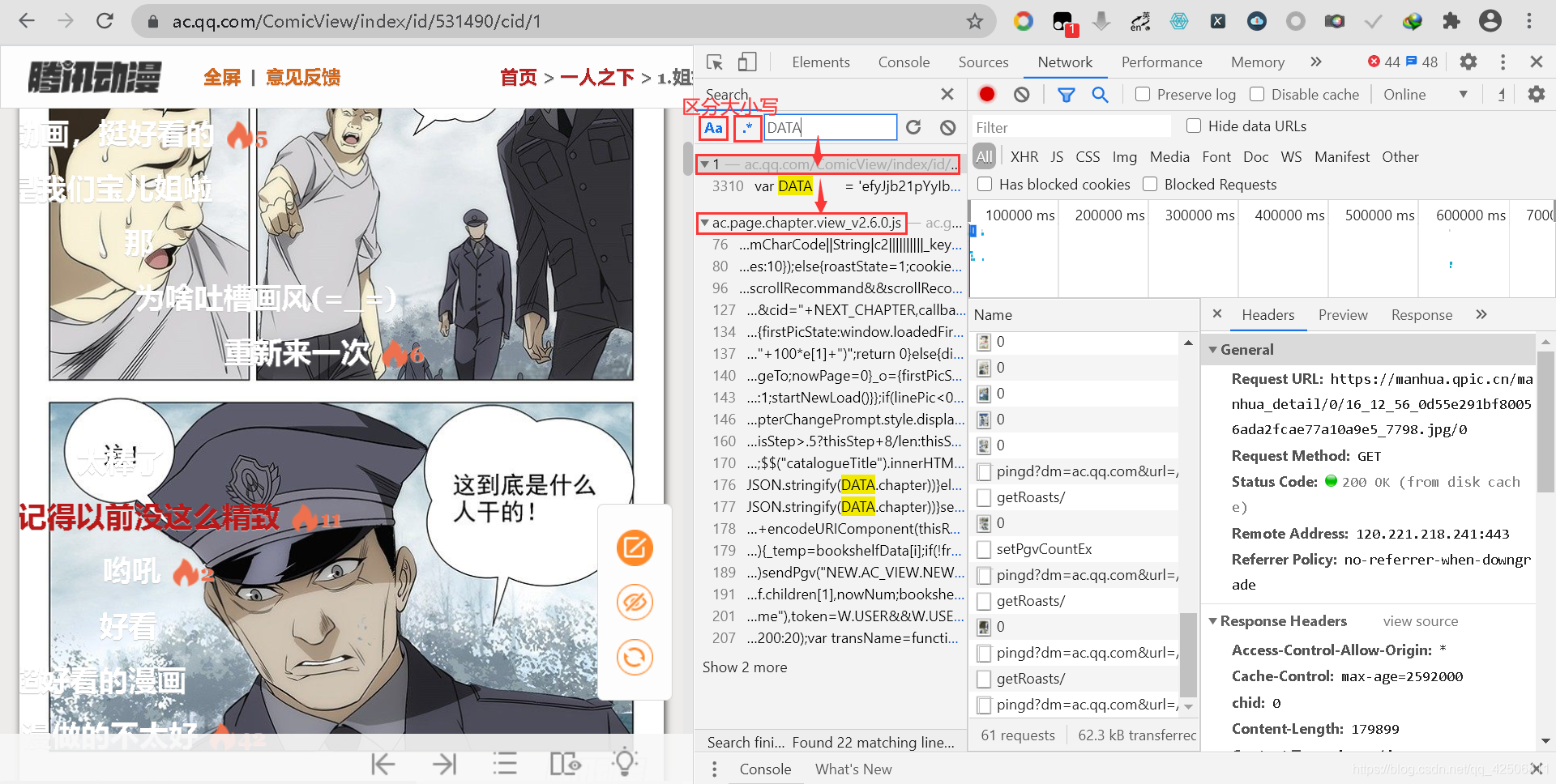
觀察發現,除了主頁scrpit標簽下的DATA變數自身之外,只剩下一個js檔案記憶體在“DATA”(https://ac.gtimg.com/media/js/ac.page.chapter.view_v2.6.0.js?v=20200907),因此,我們在Network選項卡中找到并進入這個js檔案,切換到Preview下繼續(CTRL+F)搜索“DATA”,同樣注意要區分大小寫!

經過區分大小寫搜索“DATA”后,我們發現有37處出現了“DATA”,全部瀏覽過后,發現除了第一個DATA進行了賦值以外,其他都是取的DATA變數的值,因此,判斷關鍵之處便在于第一個DATA的變數,
但是還沒有解密,那又要怎么取值呢?這里我們需要進行打斷點分析取值,
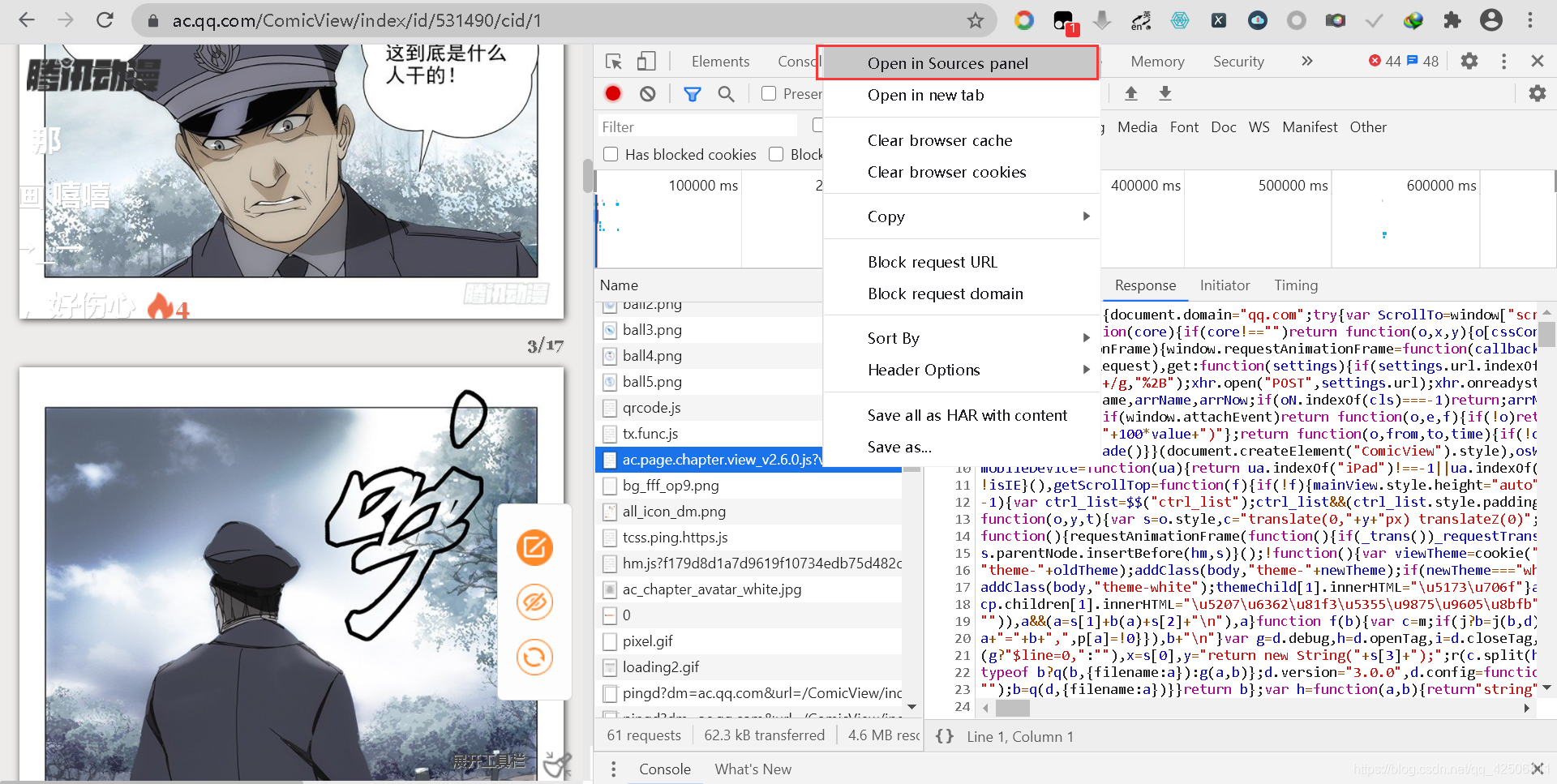
為了方便打斷點,這里我們右鍵點擊Network中的js檔案,選擇Open in Sources panel從Sources選項卡打開,再通過點擊Pretty-print將代碼格式化,
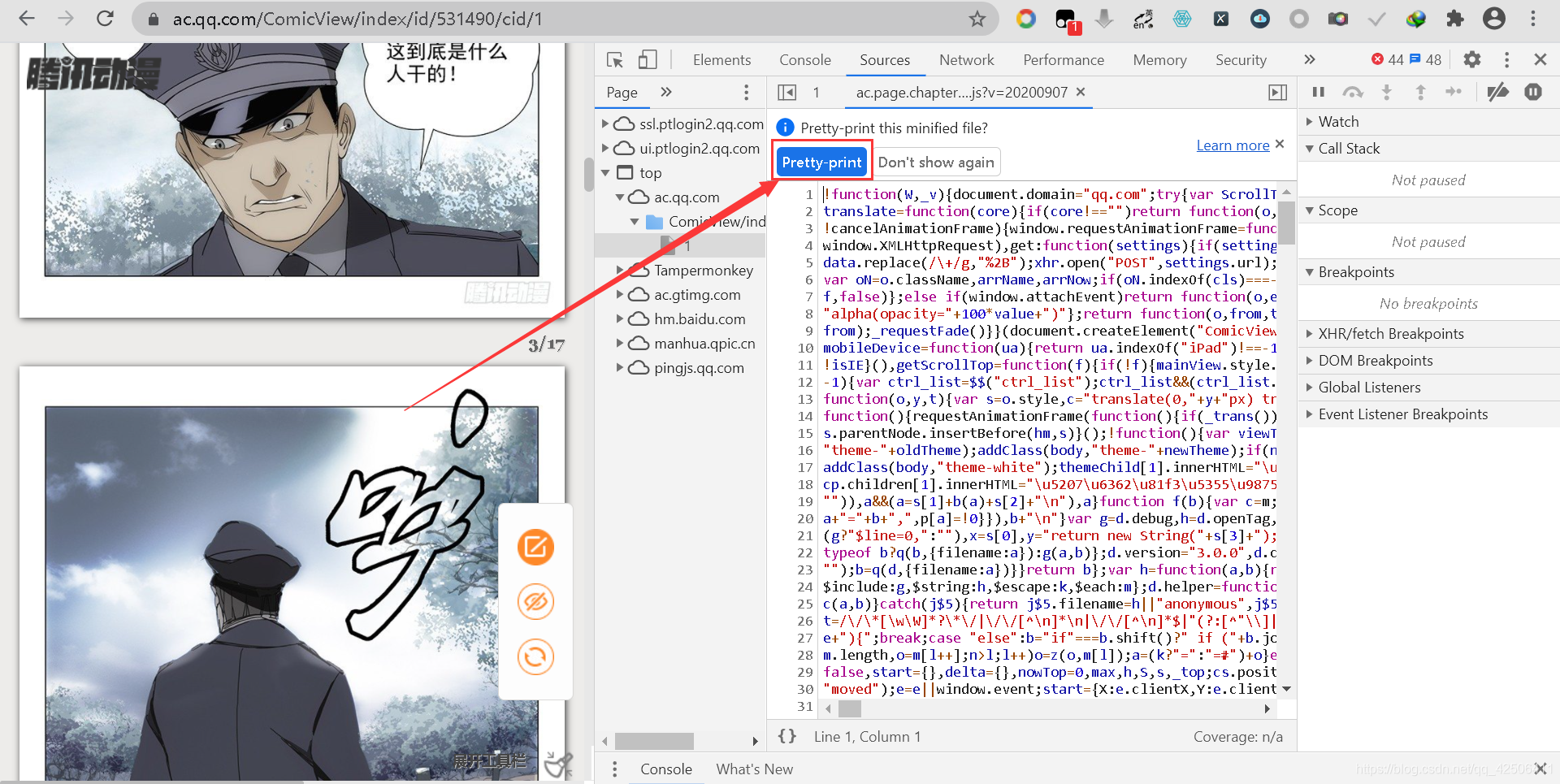
我們重新搜索找到第一個DATA的位置,直接在第一次出現的DATA變數的那一行打上斷點,然后重繪頁面,
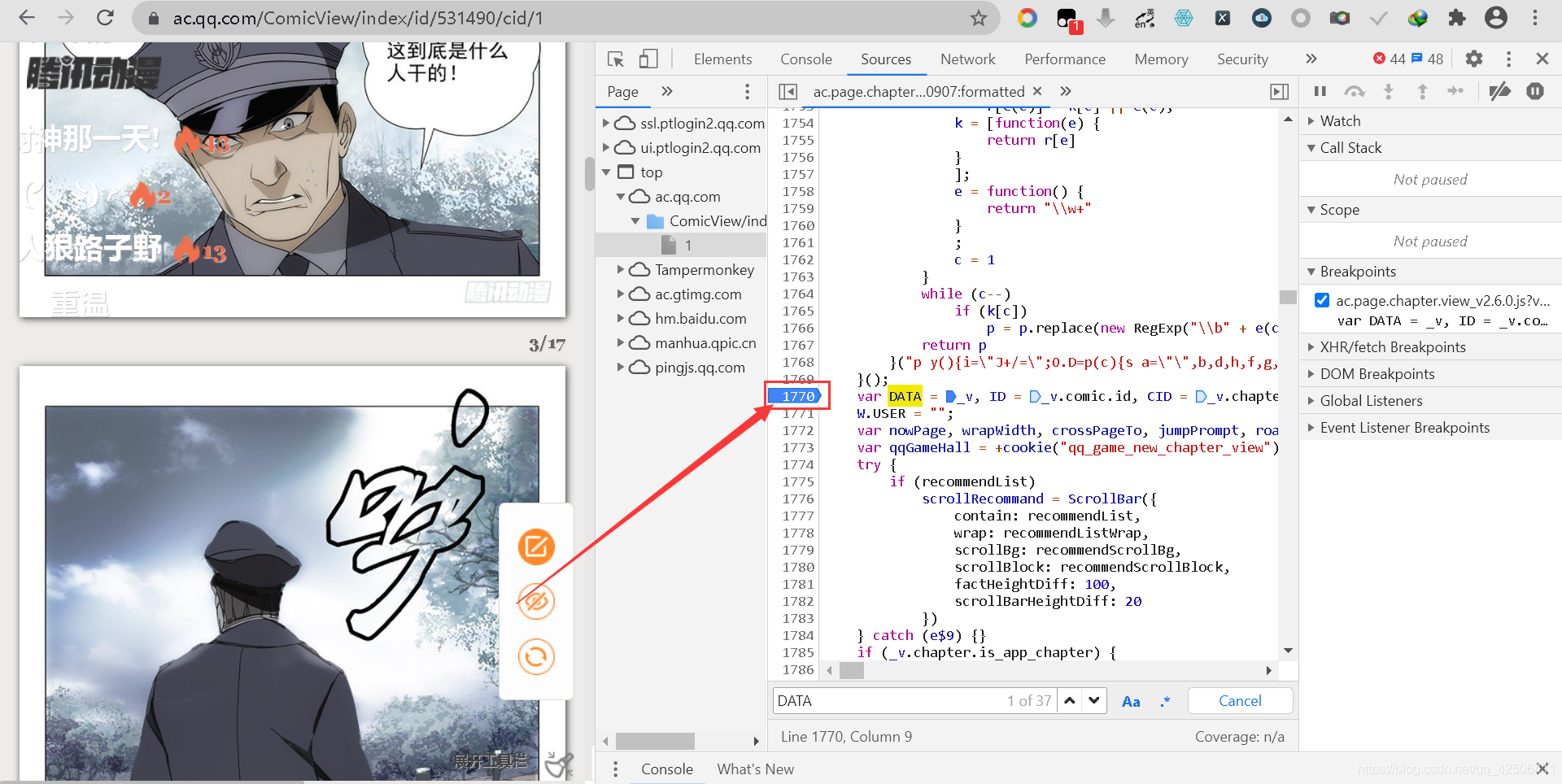
重繪頁面后,我們將滑鼠指標放在_v上,此時會顯示出_v的相關資料,(下拉右邊Scrope下的Local中的代碼,同樣觀察可發現第一次出現的DATA賦值中“DATA = _v”里面的_v變數,)
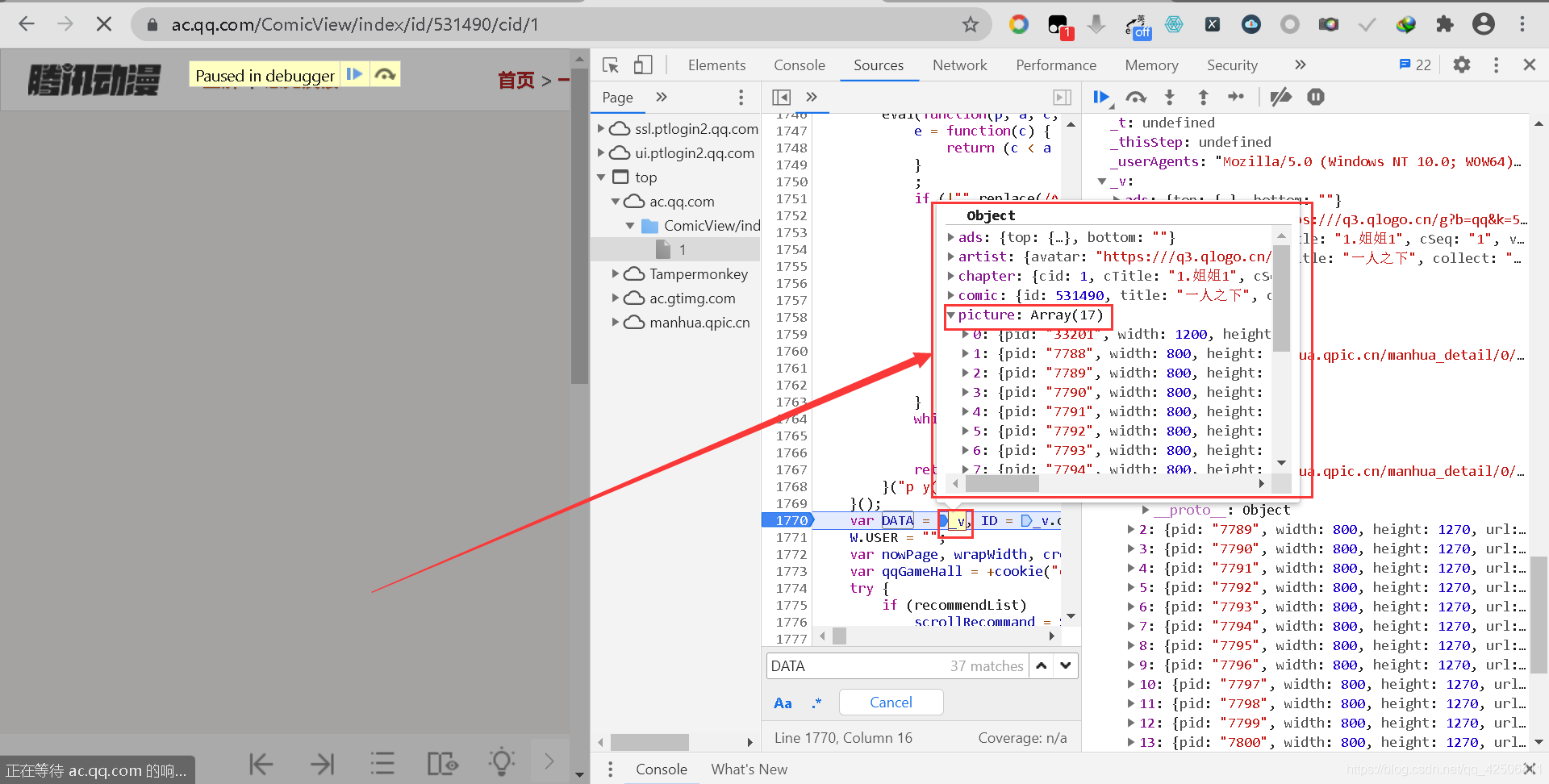
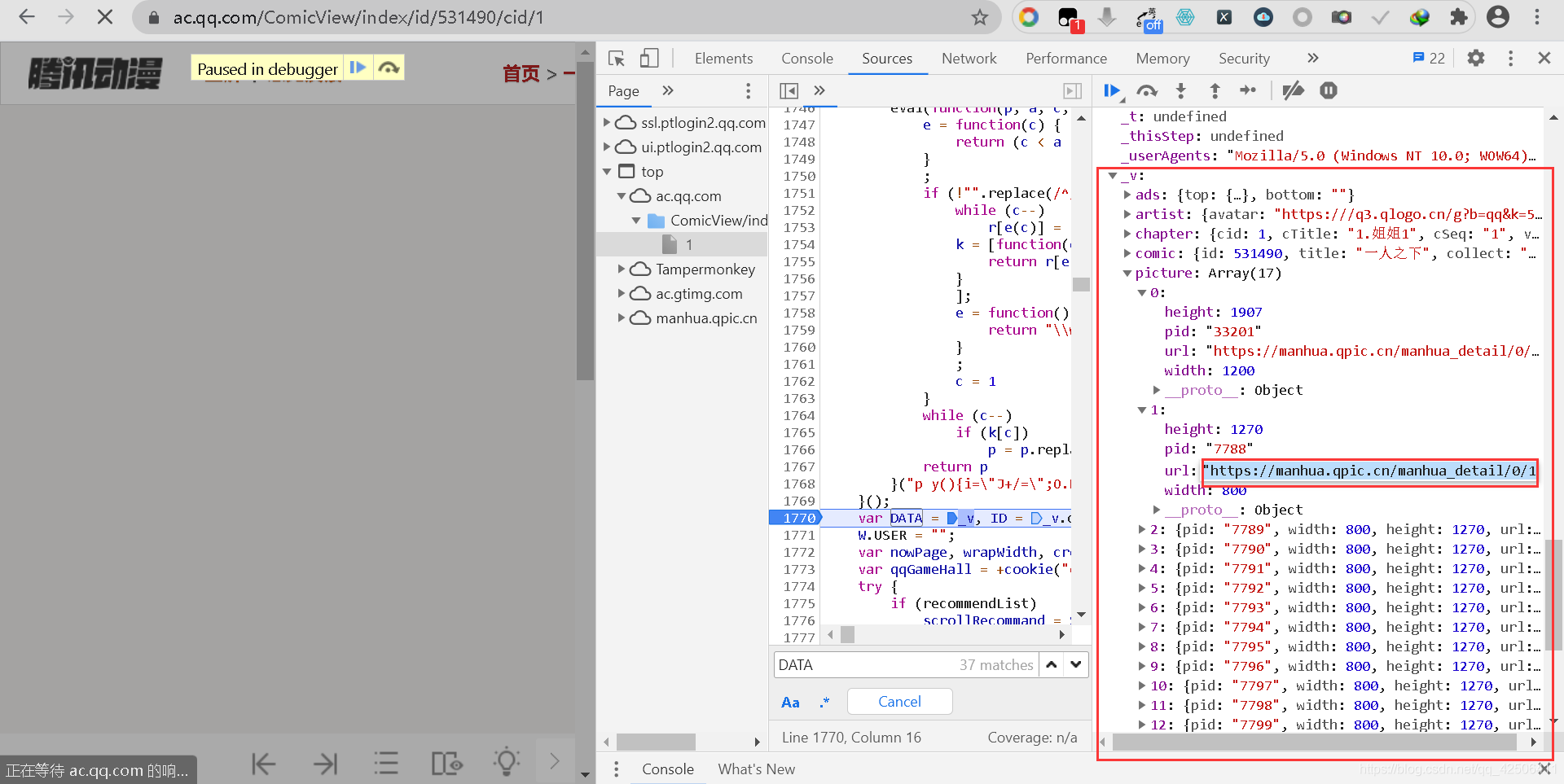
打開_v變數,可在picture下找到圖片的url,雙擊復制并去掉左右雙引號,在新的頁面運行后可以看到漫畫圖片,證明所有的圖片地址都存在于_v變數下面,
因此,接下來我們繼續區分大小寫搜索_v,可搜索到13個內容,
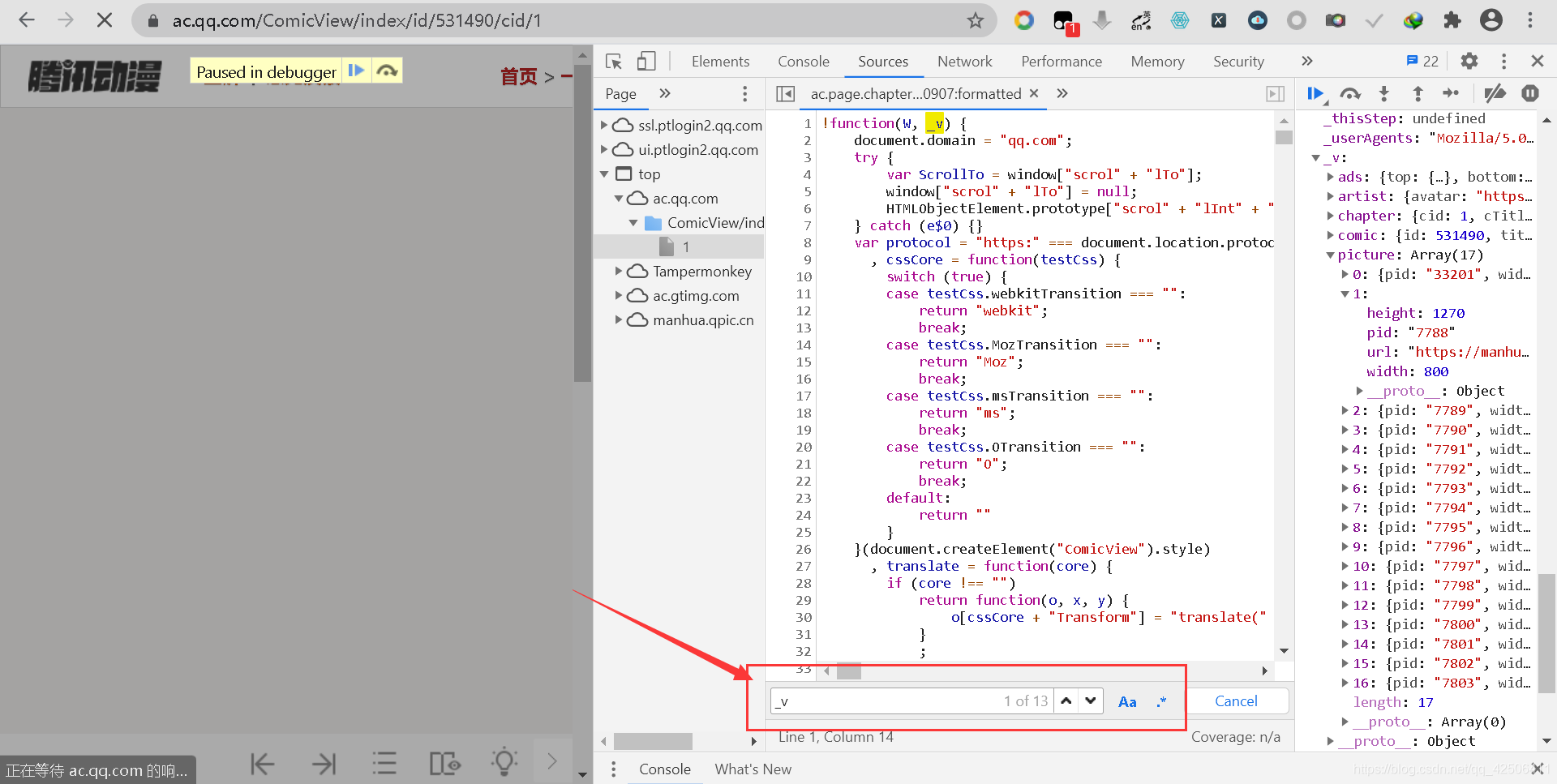
通過Search next簡單看一遍所有的_v,發現除了取值、函式變數以及一些其他的字串包含這個,剩下的一個在DATA = _v賦值陳述句上面的立即執行函式里面,立即執行函式如下所示:
eval(function(p, a, c, k, e, r) {
e = function(c) {
return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))
}
;
if (!"".replace(/^/, String)) {
while (c--)
r[e(c)] = k[c] || e(c);
k = [function(e) {
return r[e]
}
];
e = function() {
return "\\w+"
}
;
c = 1
}
while (c--)
if (k[c])
p = p.replace(new RegExp("\\b" + e(c) + "\\b","g"), k[c]);
return p
}("p y(){i=\"J+/=\";O.D=p(c){s a=\"\",b,d,h,f,g,e=0;C(c=c.z(/[^A-G-H-9\\+\\/\\=]/g,\"\");e<c.k;)b=i.l(c.m(e++)),d=i.l(c.m(e++)),f=i.l(c.m(e++)),g=i.l(c.m(e++)),b=b<<2|d>>4,d=(d&15)<<4|f>>2,h=(f&3)<<6|g,a+=7.5(b),w!=f&&(a+=7.5(d)),w!=g&&(a+=7.5(h));v a=u(a)};u=p(c){C(s a=\"\",b=0,d=17=8=0;b<c.k;)d=c.o(b),Q>d?(a+=7.5(d),b++):R<d&&S>d?(8=c.o(b+1),a+=7.5((d&F)<<6|8&r),b+=2):(8=c.o(b+1),x=c.o(b+2),a+=7.5((d&15)<<12|(8&r)<<6|x&r),b+=3);v a}}s B=I y(),T=W['K'+'L'].M(''),N=W['n'+'P'+'e'],j,t,q;N=N.U(/\\d+[a-V-Z]+/g);j=N.k;X(j--){t=Y(N[j])&10;q=N[j].z(/\\d+/g,'');T.11(t,q.k)}T=T.13('');14=16.E(B.D(T));", 62, 70, "|||||fromCharCode||String|c2||||||||||_keyStr|len|length|indexOf|charAt||charCodeAt|function|str|63|var|locate|_utf8_decode|return|64|c3|Base|replace|||for|decode|parse|31|Za|z0|new|ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789|DA|TA|split||this|onc|128|191|224||match|zA||while|parseInt||255|splice||join|_v||JSON|c1".split("|"), 0, {}))
很明顯,這一段js代碼是加密過后的,因此,我們需要使用解密工具對這一段立即執行函式進行解密,這里,我們使用的解密工具是:JavaScript Eval 在線加密/解密, 編碼/解碼工具(https://wangye.org/tools/scripts/eval/),經過解密,可以得到下面的js代碼:
function Base() {
_keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
this.decode = function(c) {
var a = "",
b, d, h, f, g, e = 0;
for (c = c.replace(/[^A-Za-z0-9\+\/\=]/g, ""); e < c.length;) b = _keyStr.indexOf(c.charAt(e++)),
d = _keyStr.indexOf(c.charAt(e++)),
f = _keyStr.indexOf(c.charAt(e++)),
g = _keyStr.indexOf(c.charAt(e++)),
b = b << 2 | d >> 4,
d = (d & 15) << 4 | f >> 2,
h = (f & 3) << 6 | g,
a += String.fromCharCode(b),
64 != f && (a += String.fromCharCode(d)),
64 != g && (a += String.fromCharCode(h));
return a = _utf8_decode(a)
};
_utf8_decode = function(c) {
for (var a = "",
b = 0,
d = c1 = c2 = 0; b < c.length;) d = c.charCodeAt(b),
128 > d ? (a += String.fromCharCode(d), b++) : 191 < d && 224 > d ? (c2 = c.charCodeAt(b + 1), a += String.fromCharCode((d & 31) << 6 | c2 & 63), b += 2) : (c2 = c.charCodeAt(b + 1), c3 = c.charCodeAt(b + 2), a += String.fromCharCode((d & 15) << 12 | (c2 & 63) << 6 | c3 & 63), b += 3);
return a
}
}
var B = new Base(),
T = W['DA' + 'TA'].split(''),
N = W['n' + 'onc' + 'e'],
len,
locate,
str;
N = N.match(/\d+[a-zA-Z]+/g);
len = N.length;
while (len--) {
locate = parseInt(N[len]) & 255;
str = N[len].replace(/\d+/g, '');
T.splice(locate, str.length)
}
T = T.join('');
_v = JSON.parse(B.decode(T));
觀察發現,第40行中的“_v = JSON.parse(B.decode(T));”便是解密后的_v變數,第27行“T = W[‘DA’ + ‘TA’].split(’’),”便是前面的DATA加密資料,那么,我們可以肯定這段js代碼就是最為關鍵的解密函式,
分析這段代碼,_v呼叫了B的decode方法(B是Base的物件),傳入的引數是T,而T又是通過前面的T引數(T = W[‘DA’ + ‘TA’].split(’’))和N引數(N = W[‘n’ + ‘onc’ + ‘e’])計算出來的,
所以,我們切換到Console選項卡,在控制臺Console界面分別輸入W[‘DA’ + ‘TA’]和W[‘n’ + ‘onc’ + ‘e’],注意:W在解密后的js里面,如果執行時報錯,則可能是因為沒有下斷點,因此必須在斷點斷下的時候執行,
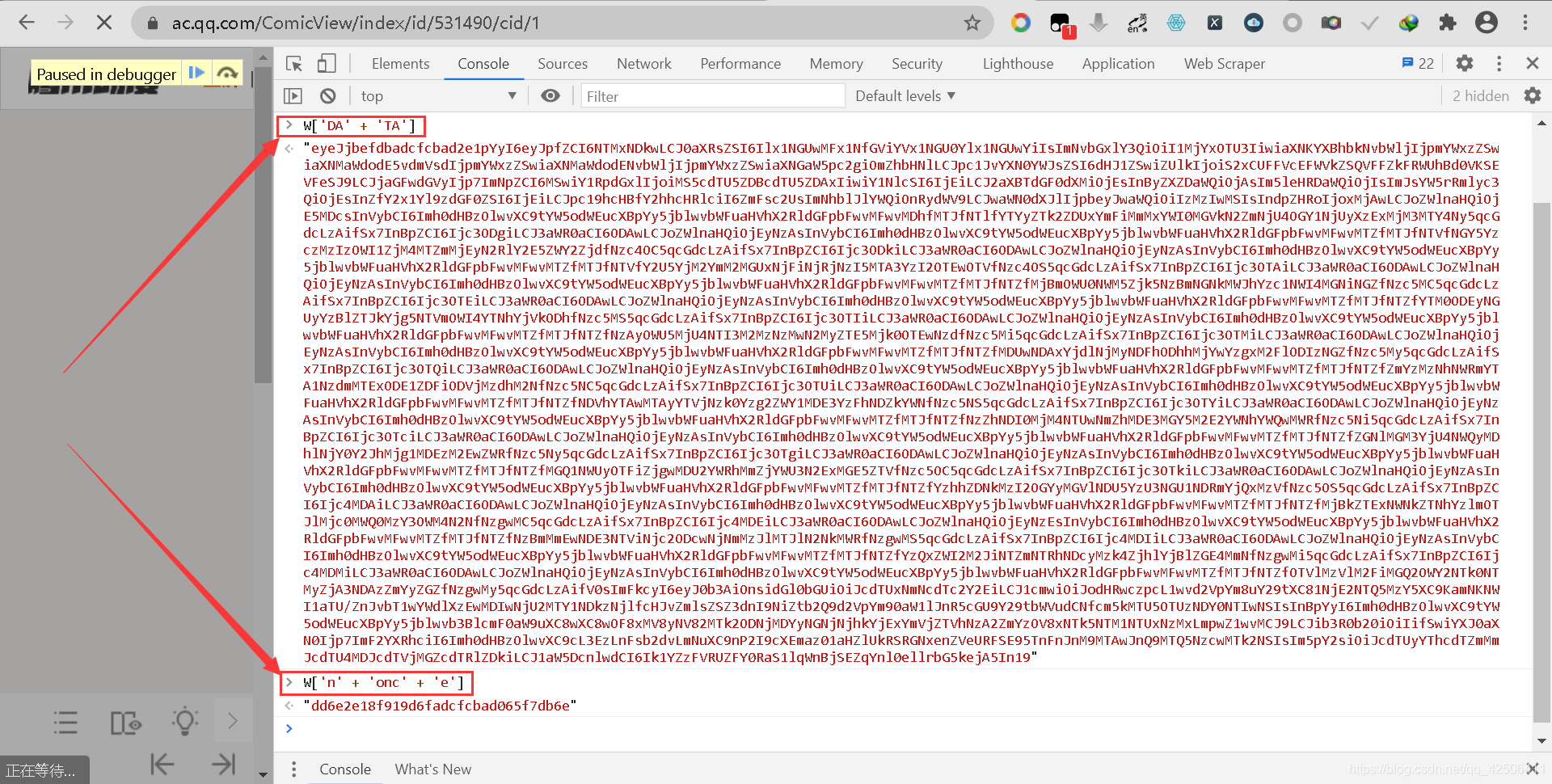
通過控制臺輸出后,我們通過搜索可以發現,W[‘DA’ + ‘TA’]就是前面的DATA加密資料,W[‘n’ + ‘onc’ + ‘e’]可以在主頁源代碼中找到(主頁源代碼中的字串被拆分了,需要搜索部分字串才能找到),
分析完畢,接下來我們開始撰寫Python代碼,
Python代碼實戰分析
解密資料獲取
我們首先來獲取以上所分析的T引數和N引數對應的兩個資料:
import requests
import re
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
print(data)
print(nonce)
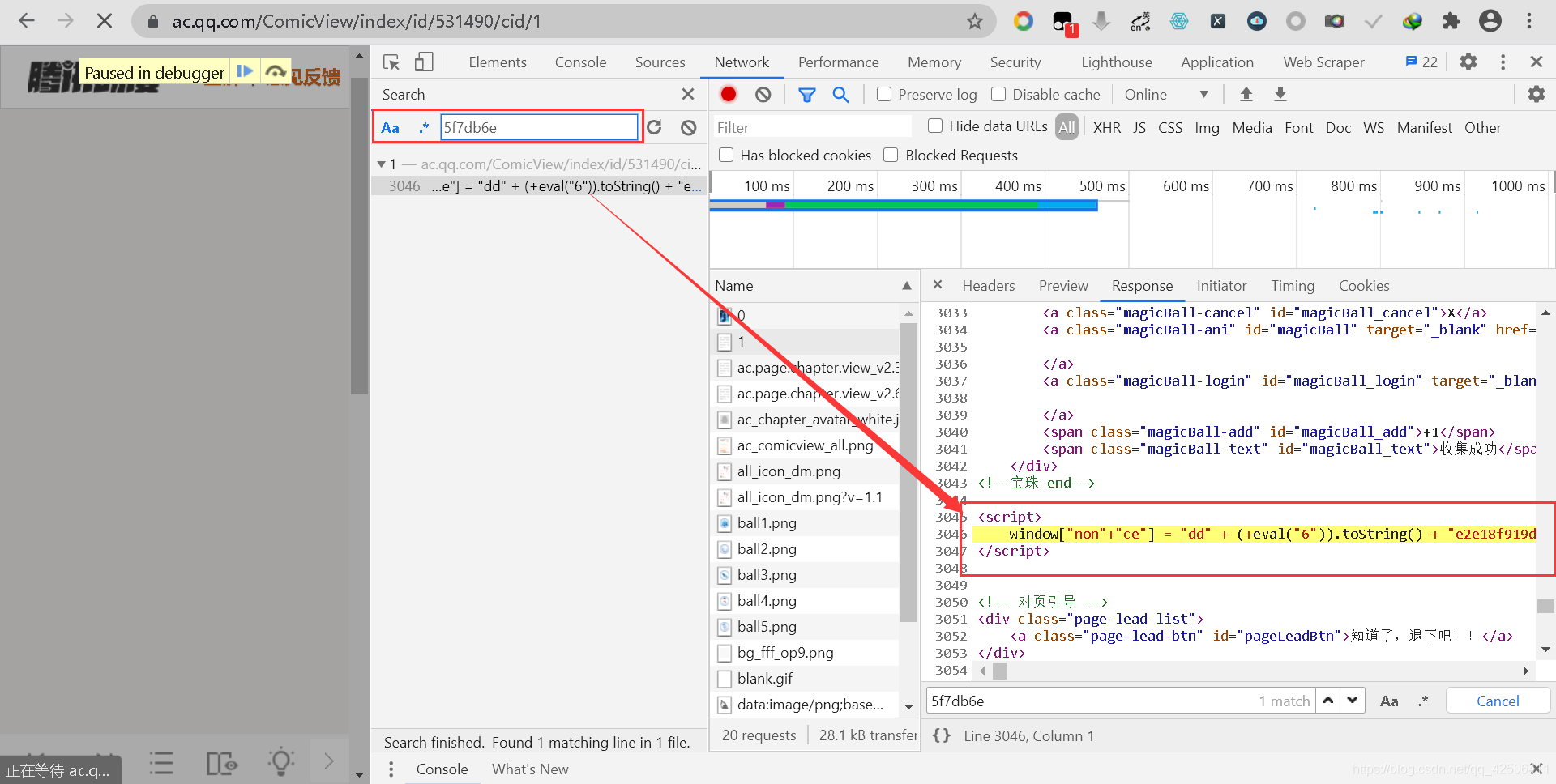
但是,經過輸出測驗后而可發現,nonce仍舊是一段js代碼而不是字串,nonce的輸出內容如下所示:
window["non"+"ce"] = "c477c" + (+eval("1/2 + 5/2")).toString() + "59" + (+eval("1 * (!window.Array) + 1")).toString() + "354" + (+eval("0 * 0")).toString() + "6" + (+eval("Math.pow(1,3)+1+1")).toString() + "a78e474" + (+eval("2 + 2")).toString() + "e919dea2d";
這里我們具有兩種解決方式:① 呼叫nodejs來計算;② 使用python第三方庫execjs模塊來計算,
我們主要來介紹第二種方式,因此首先需要安裝Python的第三方庫:
pip install PyExecJS
然后,對nonce的js代碼段進行“掐頭去尾”,即分別刪去“window[“non”+“ce”] = ”和“;”,最后通過execjs模塊計算js代碼,
import requests
import re
import execjs
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐頭去尾
nonce = execjs.eval(nonce) # 通過execjs模塊計算js代碼
print(data)
print(nonce)
注意:因為nonce是經過計算得來的,所以每次的值并不相同,有時execjs計算可能也會報錯拋出例外,再次重新執行請求即可,
JavaScript逆向
成功獲取到T引數和N引數兩個重要的引數后,可以根據js代碼進行逆向,我們可以通過nodejs呼叫解密,也可以模仿js的邏輯用python進行改寫,這里我們使用python代碼,對前面解密出來的js代碼進行改寫:
import requests
import re
import execjs
import json
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐頭去尾
nonce = execjs.eval(nonce) # 通過execjs模塊計算js代碼
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
print(_v)
此時,解密后的地址都在_v變數里面了,
針對execjs計算時可能會報錯拋出例外的問題,需要重新獲取源代碼請求處理,與此同時,我們用函式對代碼段進行封裝:
import requests
import re
import execjs
import json
def getdata():
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
while True:
try:
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐頭去尾
nonce = execjs.eval(nonce) # 通過execjs模塊計算js代碼
break
except:
pass
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
print(_v)
if __name__ == '__main__':
getdata()
漫畫資料決議
在前面的步驟中,通過_v變數已經可以獲取到騰訊漫畫的url了,所以接下來我們需要對騰訊漫畫進行決議,
def parseData(alldata): # 漫畫資料決議函式
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫畫串列
print(f"騰訊漫畫【{title}】-{chapter}")
for picture in pictures:
print(picture['url']) # 輸出每個漫畫的url
其中,我們需要將騰訊漫畫保存到指定的檔案夾中,因此需要對檔案夾是否存在進行判定,不存在則創建檔案夾,最后將爬取到的騰訊漫畫url通過二進制形式進行保存:
def parseData(alldata): # 漫畫資料決議函式
i = 0
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫畫串列
# print(f"騰訊漫畫【{title}】-{chapter}")
folder = f"D://WorkSpace/騰訊漫畫/{title}/{chapter}"
if not os.path.exists(folder):
os.makedirs(folder)
for picture in pictures:
i = i + 1
f = open(f'{folder}/{title}-{chapter}-{i}.jpg', 'wb')
f.write(requests.get(picture['url']).content) # 二進制圖片下載用content
f.close()
print(f"騰訊漫畫《{title}》-[{chapter}]下載成功!")
至此,我們已經完成了騰訊漫畫的爬取和存盤了,
整體代碼優化
為了方便用戶進行體驗、并且能夠爬取任意自己想看的騰訊漫畫,寫死的資料是肯定不行的,所以,我們需要將資料寫活,即:死去活來法,
通過對多個不同漫畫的url進行分析,我們可以找到相應的規律:
https://ac.qq.com/ComicView/index/id/漫畫編號/cid/章節編號
所以,我們可以先對騰訊漫畫按照熱門人氣榜單爬取指定頁面的漫畫名稱和漫畫編號,以便于用戶一鍵下載所需要的漫畫和章節,
from pyquery import PyQuery as pq
def popularlist(popularity): # 熱門人氣漫畫榜函式
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
doc = pq(res)
comics_li = doc('.ret-search-item.clearfix .ret-works-info .ret-works-title.clearfix a').items()
for li in comics_li:
comics_title = li.attr.title # 騰訊漫畫名稱
comics_href = li.attr.href # 漫畫短鏈接
comics_id = re.match('.*?(\d+)', comics_href) # 漫畫id匹配
print(f"{comics_title}: {comics_id.group(1)}")
由于pyinstaller不支持打包pyquery決議庫,所以博主后來又將這部分代碼用正則運算式進行了改寫:
def popularlist(popularity): # 熱門人氣漫畫榜函式
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
comics_lists = re.findall('<a href="/Comic/comicInfo/id/(.*?)".*?title="(.*?)".*?</a>', res)
for comics_list in comics_lists:
print(f"《{comics_list[1]}》漫畫編號: {comics_list[0]}")
最后,我們再對呼叫各個函式的主函式進行優化:
def main(): # 主函式
while True:
scan = input("是否需要查詢騰訊動漫的熱門人氣排行榜?(y/n)")
if scan == "y":
popularity = input("請輸入您所需查詢的騰訊動漫熱門人氣榜的頁數:")
print("="*30)
print("騰訊動漫熱門排行榜如下所示:(漫畫名稱:漫畫ID)")
print("-"*30)
popularlist(popularity)
print("-" * 30)
comics_id = input("請輸入漫畫編號:") # 漫畫ID(一人之下531490)
chapter_id = input("請輸入章節ID:") # 章節ID
url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
url_title = re.findall("<title>《(.*?)》(.*?)-.*?</title>", requests.get(url).text)
if input(f'溫馨提示:您想要下載的[{url_title[0][0]}]的章節名稱是:[{url_title[0][1]}],\n按回車鍵可繼續,輸入Q可取消下載!') == "Q":
break
alldata = getData(url)
parseData(alldata)
print("="*30)
cont = input("是否繼續?(y/n)")
if cont == "n":
break
elif cont == "y":
pass
else:
print("警告:請輸入正確的選項!(y/n)")
整體代碼
import requests
import re
import execjs
import json
import os
def getData(url): # 漫畫資料獲取函式
# url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
while True:
try:
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐頭去尾
nonce = execjs.eval(nonce) # 通過execjs模塊計算js代碼
break
except:
pass
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
# print(_v)
return _v
def parseData(alldata): # 漫畫資料決議函式
i = 0
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫畫串列
# print(f"騰訊漫畫【{title}】-{chapter}")
folder = f"D://WorkSpace/騰訊漫畫/{title}/{chapter}"
if not os.path.exists(folder):
os.makedirs(folder)
for picture in pictures:
# print(requests.get(picture['url']).text.encode())
i = i + 1
f = open(f'{folder}/{title}-{chapter}-{i}.jpg', 'wb')
f.write(requests.get(picture['url']).content) # 二進制圖片下載用content
f.close()
print(f"騰訊漫畫《{title}》-[{chapter}]下載成功!")
def popularlist(popularity): # 熱門人氣漫畫榜函式
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
comics_lists = re.findall('<a href="/Comic/comicInfo/id/(.*?)".*?title="(.*?)".*?</a>', res)
for comics_list in comics_lists:
print(f"《{comics_list[1]}》漫畫編號: {comics_list[0]}")
def main(): # 主函式
while True:
scan = input("是否需要查詢騰訊動漫的熱門人氣排行榜?(y/n)")
if scan == "y":
popularity = input("請輸入您所需查詢的騰訊動漫熱門人氣榜的頁數:")
print("="*30)
print("騰訊動漫熱門排行榜如下所示:(漫畫名稱:漫畫ID)")
print("-"*30)
popularlist(popularity)
print("-" * 30)
comics_id = input("請輸入漫畫編號:") # 漫畫ID(一人之下531490)
chapter_id = input("請輸入章節ID:") # 章節ID
url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
url_title = re.findall("<title>《(.*?)》(.*?)-.*?</title>", requests.get(url).text)
if input(f'溫馨提示:您想要下載的[{url_title[0][0]}]的章節名稱是:[{url_title[0][1]}],\n按回車鍵可繼續,輸入Q可取消下載!') == "Q":
break
alldata = getData(url)
parseData(alldata)
print("="*30)
cont = input("是否繼續?(y/n)")
if cont == "n":
break
elif cont == "y":
pass
else:
print("警告:請輸入正確的選項!(y/n)")
if __name__ == '__main__':
main()
Pyinstaller打包
使用命令提示行,可在騰訊漫畫爬取程式(TencentComics.py)程式所在檔案夾內輸入以下指令對Python代碼進行打包:
pyinstaller.exe -F TencentComics.py
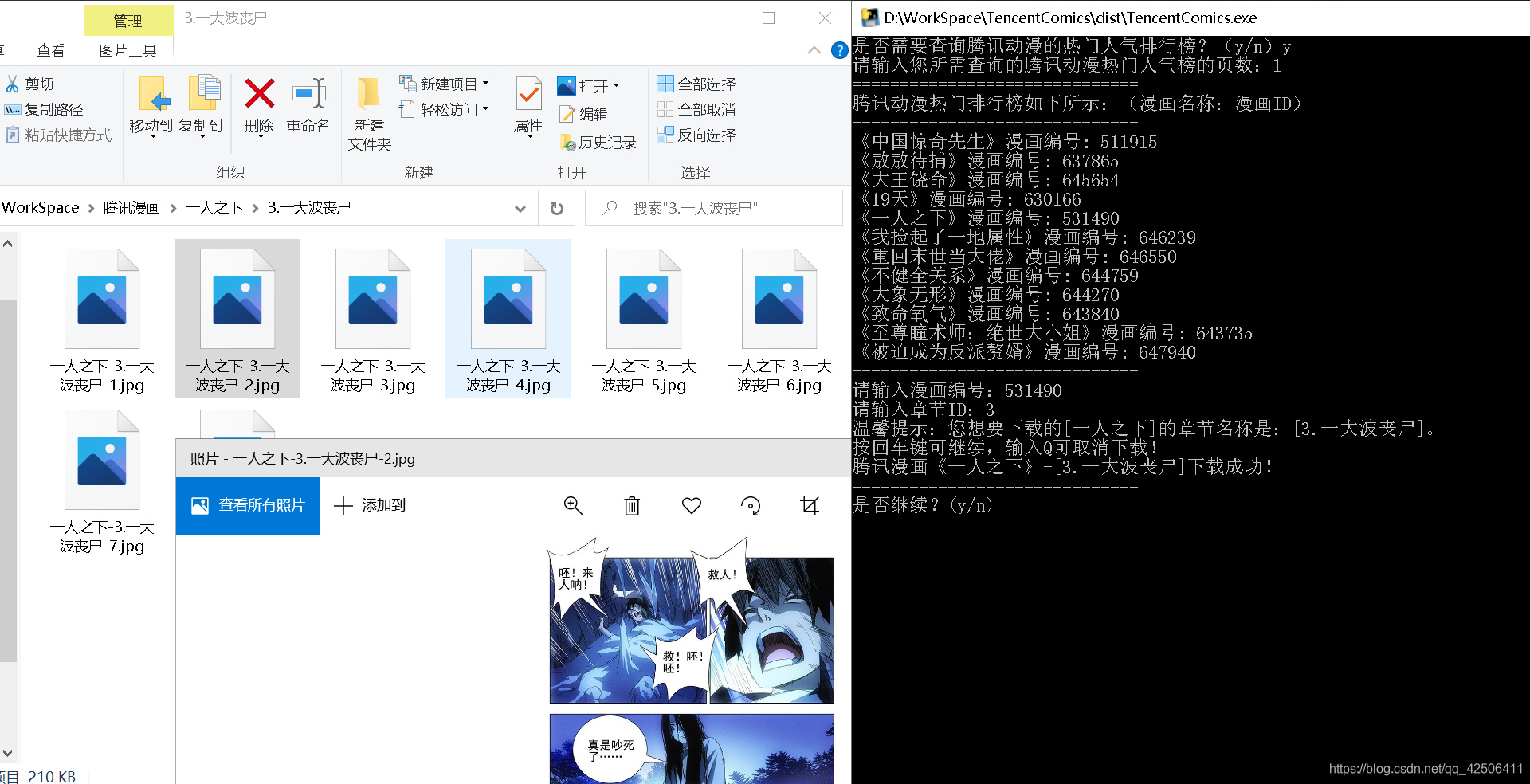
效果展示
總結
本次爬蟲實戰所遭遇的反爬蟲應該算是典型的簽名驗證反爬蟲了,簽名驗證反爬蟲原理:由客戶端生成一些隨機值和不可逆的MD5加密字串,并在發起請求時將這些值發送給服務器端,服務器端使用相同的方式對隨機值進行計算以及MD5加密,如果服務器端得到的MD5值與前端提交的MD5值相等,就代表是正常請求,否則回傳403,
爬蟲學習者面對簽名驗證反爬蟲,必須具備javascript的基礎知識,哪怕是博主兩年前已經自學完了javascript,面對js逆向還是很容易一臉懵逼,爬蟲學習,任重而道遠啊!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/20085.html
標籤:其他