問題 1
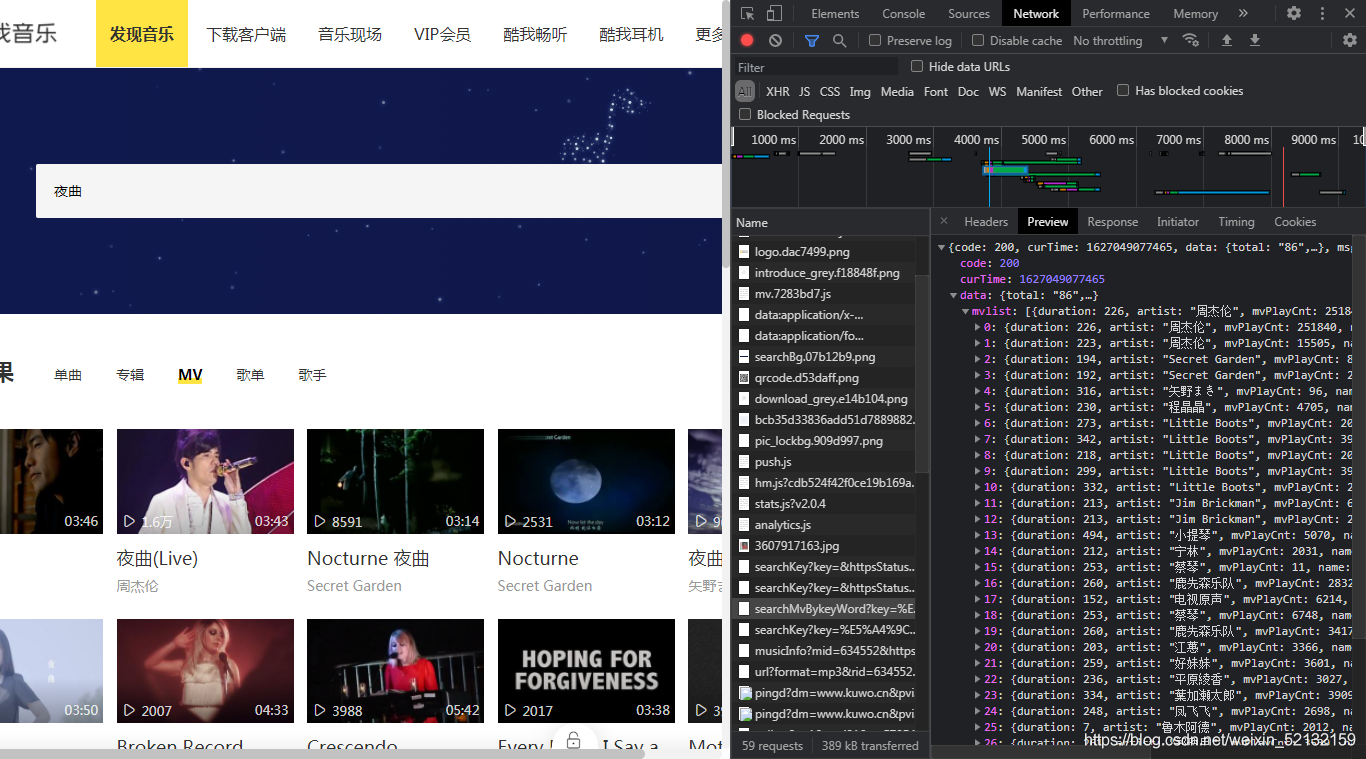
在我用 Python 的 requests 爬取酷我音樂MV資訊時報錯:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
代碼如下:
url = 'https://www.kuwo.cn/api/www/search/searchMvBykeyWord'
headers = {
'cookie': '...',
'user-agent': '...',
}
params = {'key': '夜曲',
'pn': '1',
'rn': '30',
'httpsStatus': '1'
}
respond = requests.get(url=url, headers=headers, params=params)
print(respond.text)
text = respond.json()
列印出來的HTML內容如下,出現友好錯誤界面:
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.16.0</center>
</body>
</html>
<!-- a padding to disable MSIE and Chrome friendly error page -->
<!-- a padding to disable MSIE and Chrome friendly error page -->
<!-- a padding to disable MSIE and Chrome friendly error page -->
<!-- a padding to disable MSIE and Chrome friendly error page -->
<!-- a padding to disable MSIE and Chrome friendly error page -->
<!-- a padding to disable MSIE and Chrome friendly error page -->
解決辦法:請求頭除cookie外,再加上Referer和csrf:
headers = {
'Referer': 'https://www.kuwo.cn/search/list',
'cookie': 'kw_token=GY3EWHPDHD',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 OPR/77.0.4054.203',
'csrf': 'GY3EWHPDHD'
}
問題 2
解決問題 1 之后爬取酷我音樂的MV資訊時,列印出爬取到的資料是這樣子的:
{"success":false,"message":"CSRF Token Not Found!","now":"2021-07-23T13:15:45.683Z"}
根據上面的資訊我們可以得出是 csrf 這里出了問題:
url = 'https://www.kuwo.cn/api/www/search/searchMvBykeyWord'
headers = {
'Referer': 'https://www.kuwo.cn/search/list',
'cookie': '...',
'user-agent': 'Mozilla/5.0...',
'csrf': 'GY3EWHPDHD',
}
params = {'key': '夜曲',
'pn': '1',
'rn': '30',
'httpsStatus': '1'
}
respond = requests.get(url=self.url, headers=self.headers, params=self.params)
print(respond.text)
接著我發現 csrf 的內容和 cookie 中的kw_token是一樣的,因此這兩個都不能缺少
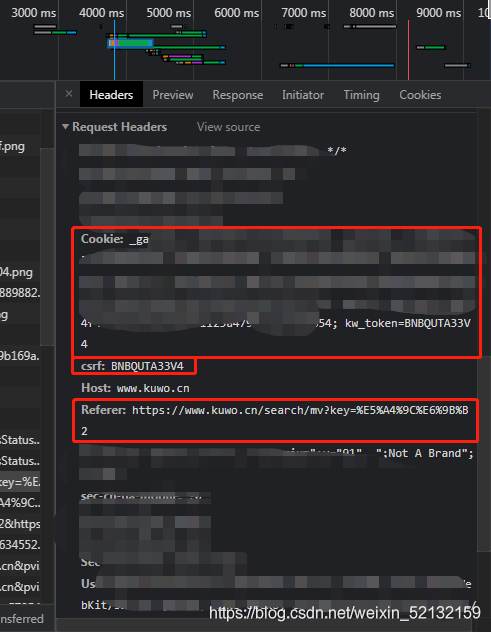
我正好就是 cookie 中缺少了此部分,加上去即可:
headers = {
'Referer': 'https://www.kuwo.cn/search/list',
'cookie': 'kw_token=GY3EWHPDHD',
'user-agent': 'Mozilla/5.0...',
'csrf': 'GY3EWHPDHD',
}
根據試驗我得出在這里爬取音樂資料,請求頭只需要Referer、csrf和cookie的kw_token部分即可,
問題 3
爬取音樂MV鏈接,遇到了 javascript 渲染的動態網頁:
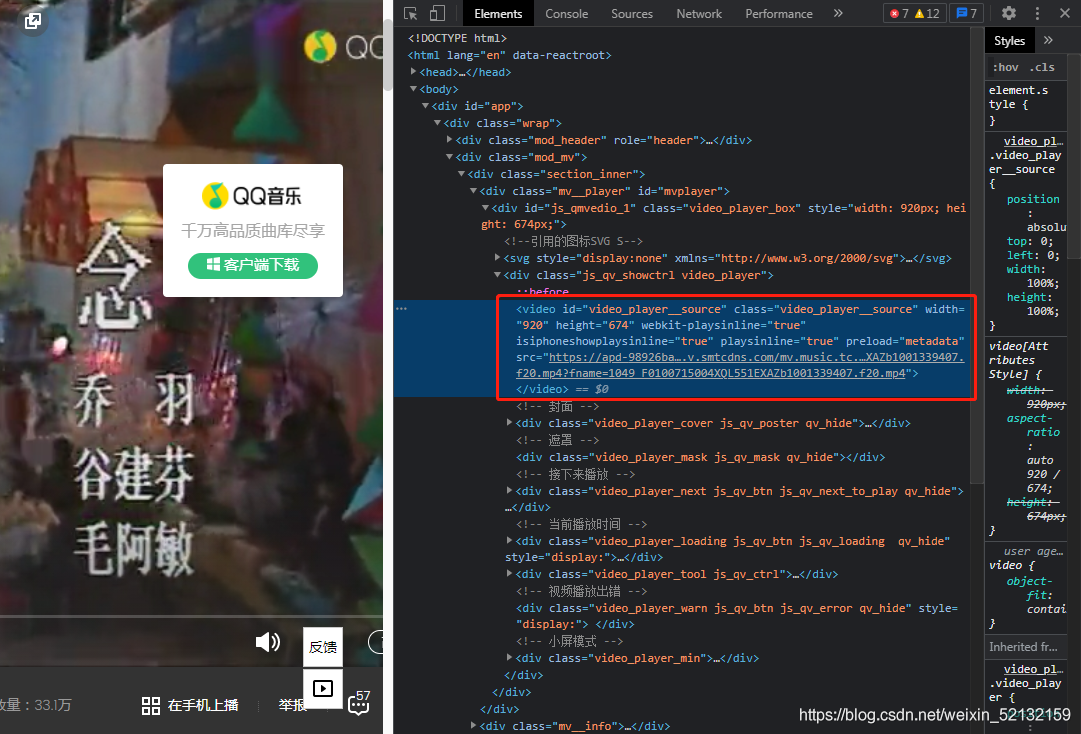
爬取視頻鏈接的部分代碼:
from pyquery import PyQuery as pq
url_mv = pq(url='https://y.qq.com/n/ryqq/mv/d0023bpqirq')
url_mp4 = url_mv.find('#video_player__source').attr('src')
print(url_mp4)
這時候我們會發現我們爬到的資訊為None
我試著用requests獲取HTML原始碼,但得到的內容與我在網頁中看到的不一樣,內容有缺失:
import requests
url_mv = 'https://y.qq.com/n/ryqq/mv/d0023bpqirq'
url_mp4 = requests.get(url_mv).text
print(url_mp4)
為什么爬到的網頁內容和我們看到的不一樣呢?這是因為:這個網頁的資料是JavaScript渲染的,我們從html的原始碼中無法獲得這些資料,這些資料是在執行JavaScript腳本之后,異步地渲染到頁面上的,我們獲得的HTML原始碼為網頁初始化的時候的原始碼,就像下面這樣,當然沒有視頻鏈接:

這時候怎么辦呢,我上網查了很多方法,要么是用 selenium 等的庫模擬瀏覽器操作,或者就是渲染引擎等的東西,但 selenium 庫耗時又耗記憶體,我并不想用它,而身為大懶人的我又絕對不會搞什么引擎,這時候我找到了一個絕佳的解決辦法(只適用于爬取音樂和MV,其他網頁我沒有試過,并不清楚),
解決
如果你在QQ音樂爬取,建議你放棄QQ音樂,它并不適用于我的這個方法,我用的是酷我音樂,
首先進入酷我音樂主頁,搜索歌曲(這里以“思念”為例),然后點擊 MV 欄后開始錄制行為,我們隨便點擊進入一部MV,這時候我們可以發現這邊多了一個以url?rid=... 開頭的檔案,檔案內容就是我們需要的鏈接:
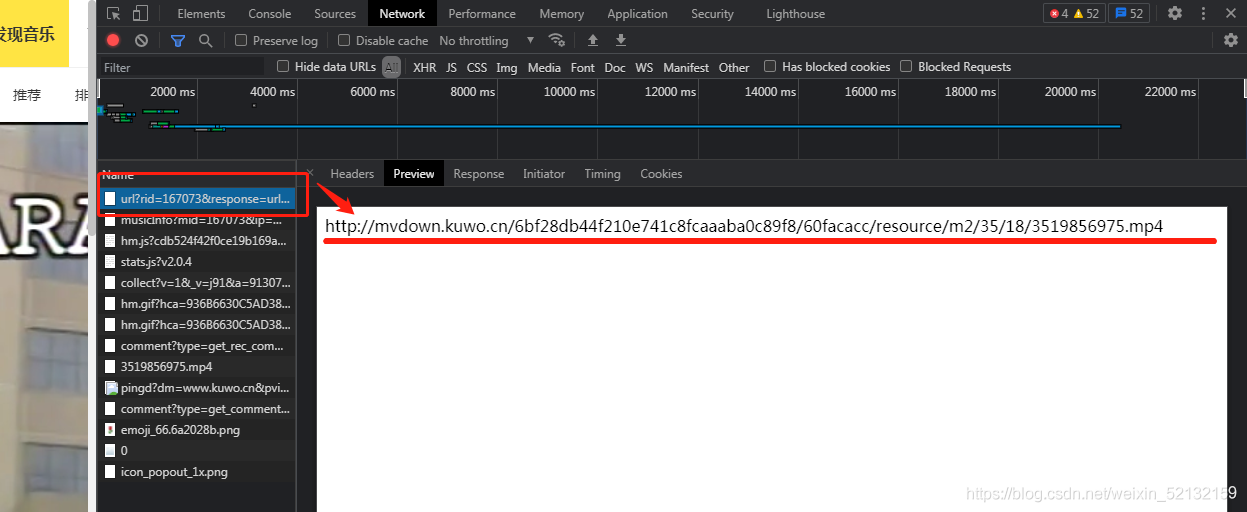
如果爬取的是音樂資訊,則要點擊播放后,看到一個以 url?format=...開頭的檔案,里面包含了音樂鏈接:
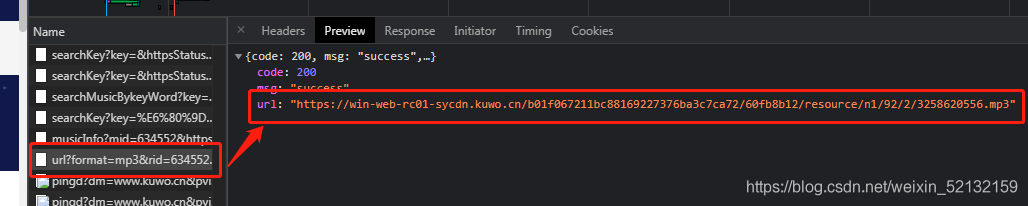
然后我們就可以直接用這個檔案的 url 地址發送請求:
url_mv = f'https://www.kuwo.cn/url?rid={id_mv}&response=url&format=mp4%7Cmkv&type=convert_url&t=1627025536974&httpsStatus=1&reqId=1b3945f0-eb88-11eb-8b47-0762a118c069'
params = {'rid': id_mv,
'response': 'url',
'format': 'mp4|mkv',
'type': 'convert_url',
't': '1627025536974',
'httpsStatus': '1',
'reqId': '1b3945f0-eb88-11eb-8b47-0762a118c069'}
url_mp4 = requests.get(url_mv, params=params).text
print(url_mp4)
with open ('思念.mp4','wb') as m:
m.write(mp4)
如果是爬音樂則需經json解碼后換為字典后取 url:
url_mp4 = requests.get(url_mv, params=params).json()['url']
注意代碼中的 url_mv 字串和 params 中的id_mv是視頻的 id,可以替換后獲取不同的MV的鏈接,比如《思念》的 id 為167073,id 可以在搜索界面中爬取資訊找到(問題1、問題2),你也可以點進MV后看網址的后幾位數字,
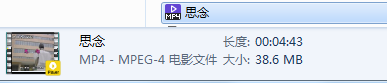
在寫入了mp4檔案后,來到檔案夾,可以看到 思念.mp4 已經生成了:
2021/7/23
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/290103.html
標籤:其他