正則運算式的模式匹配
正則運算式是一個描述字符模式的物件
正則運算式的定義
-
使用正則運算式字面量定義(腳本加載后,會被編譯,不變時,性能更好)
- var pattern = /s$/;
-
呼叫RegExp物件的建構式定義(在腳本運行程序中,會被編譯)
- var pattern = new RegExp(“s$”);
直接量字符
- 正則運算式所有字母和數字都是按照字面含義進行匹配的
- JavaScript正則運算式語法也支持非字母的字符匹配,這些字符需要通過反斜線(\)作為前綴進行轉義
正則運算式直接量的每次計算都會創建一個新的RegExp物件,每個新的物件都有自己的lastIndex屬性
正則運算式中的直接量字符
| 字符 | 匹配 |
|---|---|
| 字母和數字字符 | 自身 |
| \o | NUL字符(\u0000) |
| \t | 制表符(\u0009) |
| \n | 換行符(\u000A) |
| \v | 垂直制表符(\u000B) |
| \f | 換頁符(\u000C) |
| \r | 回車符(\u000D) |
| \xnn | 由十六進制數nn指定的拉丁字符,例如,\x0A等價于\n |
| \uxxxx | 由十六進制數xxxx指定的Unicode字符,例如,\u0009等價于\t |
| \cx | 控制字符^X,例如,\cJ等價于換行符\n |
字符類
將直接量字符單獨放進方括號內就組成了字符類
-
一個字符類可以匹配它所包含的任意字符
-
字符類可以使用連字符來表示字符范圍 例如,要匹配拉丁字母表中的小寫字母 /[a-z]/
正則運算式中的字符類
| 字符 | 匹配 |
|---|---|
| […] | 方括號內的任意字符 |
| [^…] | 不在方括號內的任意字符 |
| . | 除換行符和其他Unicode行終止符之外的任意字符 |
| \w | 任何ASCII字符組成的單詞等價于 [a-zA-Z0-9] |
| \W | 任何不是ASCII字符組成的單詞等價于 [^a-zA-Z0-9] |
| \s | 任何Unicode空白符 |
| \S | 任何非Unicode空白符 |
| \d | 任何ASCII數字等價于 [0-9] |
| \D | 除了ASCII數字之外的任何字符,等價于 [^0-9] |
| [\b] | 退格直接量(特例) |
重復
貪婪的 非貪婪后面加+
正則運算式的重復字符語法
| 字符 | 含義 | 特殊 |
|---|---|---|
| {n , m} | 匹配前一項至少n次,但不能超過m次 | |
| {n , } | 匹配前一項n次或者更多次 | |
| {n} | 匹配前一項n次 | |
| ? | 匹配前一項0次或者1次,等價于 {0 , 1} | 可能與其匹配0個字串 |
| + | 匹配前一項1次或者多次,等價于 {1, } | |
| * | 匹配前一項0次或者多次,等價于 {0, } | 可能與其匹配0個字串 |
選擇,分組的參考
正則運算式的選擇,分組的參考字符
| 字符 | 含義 | 例 |
|---|---|---|
| 選擇,匹配的是該字串左邊的子運算式或右邊的子運算式(從左到右) | ||
| (…) | 組合,將幾個項組合為一個單元,這個單元可通過“*” “+” “?”和 “ | ”等符號加以修飾,而且可以記住和這個組合相匹配的字串以供此后的參考參考 |
| (?:…) | 只組合,把項組合到一個單元,但不記憶和這個組合相匹配的字串 | /([Jj]ava(?:[Ss]cript)?)\sis\s(fun\w*)/在這個正則運算式中\2參考了與(fun\w*)匹配的文本 |
| \n | 和第n個分組第一次匹配的字符相匹配,組是圓括號中的子運算式(也有可能是嵌套的),組索引是從左到右的左括號數,“(?:”形式的分組不編碼 | /(’")[^’"]*\1/要求左右側引號相匹配 |
指定匹配位置
正則運算式中的錨字符
| 字符 | 含義 | 例 |
|---|---|---|
| ^ | 匹配字串的開頭,在多行檢索中,匹配一行的開頭 | /^Script$/匹配單詞 Script 啥都不可以多 |
| $ | 匹配字串的結尾,在多行檢索中,匹配一行的結尾 | /^Script$/匹配單詞 Script 啥都不可以多 |
| \b | 匹配一個單詞的邊界,就是位于字符\w和\W之間的位置(注意!,[\b] 匹配的是退格符) | |
| \B | 非邊界 | /\B[Ss]cript/與Javascript匹配但不與 script匹配 |
| (?=p) | 零寬正向先行斷言,要求接下來的字符都與p匹配,但不能包括匹配p的那些字符 | var reg8 = /1cript(?=:)/g;var str = “Script:”;console.log(str.match(reg8)) |
| (?!p) | 零寬負向先行斷言,要求接下來的字符都不與p匹配 |
修飾符
正則運算式修飾符
| 字符 | 含義 | |
|---|---|---|
| i | 執行不區分大小寫的匹配 | |
| g | 執行一個全域匹配 | |
| m | 多行匹配模式 ^ $ 代表每行的開頭和結尾 |
用于模式匹配的String方法
search()方法
回傳第一個與之匹配的子串的起始位置
特性:
1.不支持全域檢索忽略正則運算式引數中的修飾符g
2.如果引數不是正則運算式,則首先會通過RegExp建構式轉換為正則運算式
例: “JavaScript”.search(/script/i); //4
replace()方法
執行檢索與替換操作
特性:
1.支持全域檢索
2.如果引數不是正則運算式,則直接搜索這個字串,不會轉換
例: str.replace(/javascript/ig, “JavaScript”); //str字串中所有javascript替換為JavaScript

match()方法
回傳一個由匹配結果組成的陣列
特性:
1.支持全域檢索
2.如果執行的不是全域檢索,也回傳一個陣列,陣列的第一個元素是匹配的字串,余下的元素是正則運算式中用圓括號括起來的子運算式,
例:
“1 wwx 3 qwer rwe 2”.match(/\d+/g); //[“1”, “3”, “2”]

split()方法
將指定字串拆分成由子串組成的陣列
例: “1, 2, 3, 4, 5”.split(/\s*,\s*/); //[“1”, “2”, “3”, “4”, “5”]
RegExp物件
RegExp建構式有兩個引數
var pattern = new RegExp(“s$”, “g”);
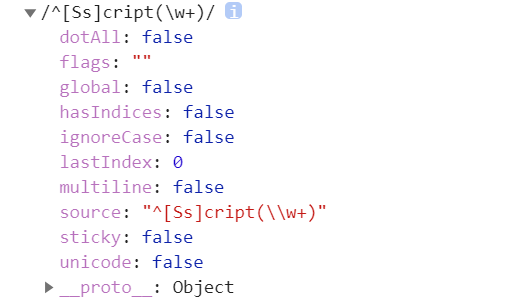
RegExp的屬性
- source屬性
是一個只讀的字串,包含正則運算式的文本
- global屬性
只讀的布林值,說明該正則運算式是否帶有修飾符g
- ignoreCase屬性
只讀的布林值,說明該正則運算式是否帶有修飾符i
- multiline屬性
只讀的布林值,說明該正則運算式是否帶有修飾符m
- lastIndex屬性
可讀可寫的整數,如果有修飾符g,這個屬性儲存在整個字串中下一次檢索開始的位置
會被exec() test()方法 用到
RegExp的方法
- exec()

- test()

Ss ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/291750.html
標籤:其他