我有條件填充在字串中定義的新列。
condition_string = "colA='yes' & colB='yes' & (colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
字串可以以任何其他格式(字典)重寫/結構化,然后輸入代碼以獲得最終結果。
資料框是
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB03', 'AB04','AB05', 'AB06'],
'colA': ["yes","yes",'yes',"no","no",'yes', np.nan],
'colB': [np.nan,'yes','yes',"no",'no', np.nan, "yes"],
'colC': ["yes",'yes', 'yes',"no", "no",np.nan,np.nan],
'colD': ["yes",'no', 'yes',"no",np.nan,"no",np.nan],
}
)
最終結果應該是這樣的
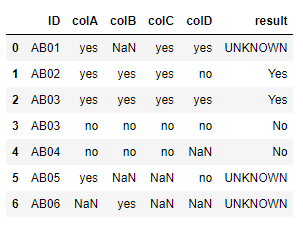
如何在不硬編碼condition_string. 或者你有什么方法condition_string可以重組然后應用于資料幀?
更新:如果字典是這樣的呢?
condition_string = "colA='yes' & (colB='yes' | colB='no)' &
(colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
資料框就像
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB03', 'AB04','AB05', 'AB06'],
'colA': ["yes","yes",'yes',"no","no",'yes', np.nan],
'colB': ["no",'yes','yes',"no",'no', np.nan, "yes"],
'colC': ["yes",'yes', 'yes',"no", "no",np.nan,np.nan],
'colD': ["yes",'no', 'yes',"no",np.nan,"no",np.nan]
}
)
uj5u.com熱心網友回復:
您可以使用np.where:
df['results'] = np.where((((df['colA']=='yes') & (df['colB']=='yes')) & ((df['colC']=='yes') | (df['colD']=='yes'))), 'Yes',np.where(((df['colA']=='no') & (df['colB']=='no')) & ((df['colC']=='no' )| (df['colD']=='no')), 'No','UNKNOWN'))
這使:
ID colA colB colC colD decision
0 AB01 yes NaN yes yes UNKNOWN
1 AB02 yes yes yes no Yes
2 AB03 yes yes yes yes Yes
3 AB03 no no no no No
4 AB04 no no no NaN No
5 AB05 yes NaN NaN no UNKNOWN
6 AB06 NaN yes NaN NaN UNKNOWN
uj5u.com熱心網友回復:
IIUC 你想為你的 創造任意條件df,這可以使用functools.reduce和來完成operator.and_。然后,您可以使用兩個串列(而不是 dict)來設定條件,第一個是列,第二個是要測驗的字串,最后是np.select:
from functools import reduce
from operator import and_
cols = ["colA", "colB", ["colC", "colD"]] # group the cols in a list if they belong to the same group
answer = ["yes", "no"]
conds = [reduce(and_, [df[i].eq(ans) if isinstance(i, str) else df[i].eq(ans).any(1)
for i in cols]) for ans in answer]
df["result"] = np.select(conds, answer, "Unknown")
print (df)
ID colA colB colC colD result
0 AB01 yes NaN yes yes Unknown
1 AB02 yes yes yes no yes
2 AB03 yes yes yes yes yes
3 AB03 no no no no no
4 AB04 no no no NaN no
5 AB05 yes NaN NaN no Unknown
6 AB06 NaN yes NaN NaN Unknown
現在您只需要編輯這兩個串列,cols以及answer是否需要調整您的條件。
uj5u.com熱心網友回復:
這是將您的條件轉換為 python 函式然后將其應用于 DataFrame 的行的解決方案:
import re
condition_string = "colA='yes' & colB='yes' & (colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
# formatting string as python function apply_cond
col_pattern = re.compile(r'(\w )=')
cond_form = re.sub(r', (?!ELSE)', '\n\telif ', condition_string) \
.replace(": ", ":\n\t\treturn ") \
.replace(", ELSE ", "\n\telse") \
.replace("&", "and") \
.replace('|', 'or')
cond_form = re.sub(col_pattern, r"row['\1']==", cond_form)
function_def = "def apply_cond(row):\n\tif " cond_form
#print(function_def) # uncomment to see how the function is defined
# executing the function definition of apply_cond
exec(function_def)
# applying the function to each row
df["result"]=df.apply(lambda x: apply_cond(x), axis=1)
print(df)
輸出:
ID colA colB colC colD result
0 AB01 yes NaN yes yes UNKNOWN
1 AB02 yes yes yes no Yes
2 AB03 yes yes yes yes Yes
3 AB03 no no no no No
4 AB04 no no no NaN No
5 AB05 yes NaN NaN no UNKNOWN
6 AB06 NaN yes NaN NaN UNKNOWN
您可能希望根據以下情況調整字串格式condition_string(我很快就完成了,可能有一些不受支持的組合)但是如果您自動獲取這些字串,它將使您免于重新定義它們。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/339734.html
下一篇:看不到2個資料幀之間的區別