正如標題所示,我正在嘗試使用 Beautifulsoup 和 Selenium 來刮一張桌子。我知道我很可能不需要這兩個庫,但是我想嘗試使用 Selenium 的 xpathselectors 是否會有所幫助,不幸的是他們沒有。
該網站可以在這里找到:
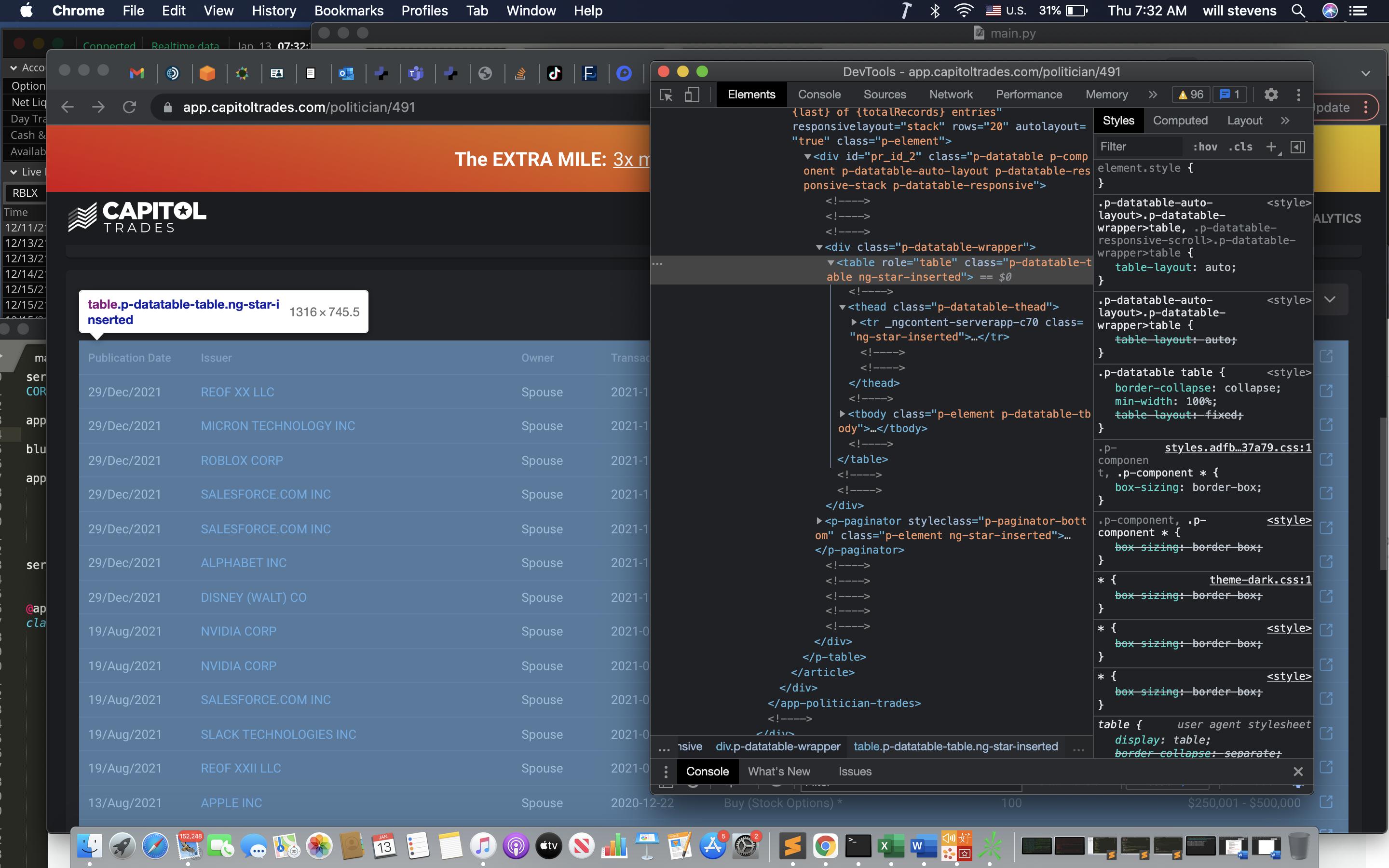
一旦我可以抓取表格,我將收集表格行內的 td 資料。
因此,例如,我想要在“發布日期”下的“29/Dec/2021”。不幸的是,我沒能走到這一步,因為我抓不到桌子。
這是我的代碼:
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
url = 'https://app.capitoltrades.com/politician/491'
resp = requests.get(url)
#soup = BeautifulSoup(resp.text, "html5lib")
soup = BeautifulSoup(resp.text, 'lxml')
table = soup.find("table", {"class": "p-datatable-table ng-star-
inserted"}).findAll('tr')
print(table)
這會產生錯誤訊息“AttributeError: 'NoneType' object has no attribute 'findAll'
使用 'soup.findAll' 也不起作用。
如果我嘗試使用 Selenium 的 xpathselector 路由...
DRIVER_PATH = '/Users/myname/Downloads/capitol-trades/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.implicitly_wait(1000)
driver.get('https://app.capitoltrades.com/politician/491')
table = driver.find_element_by_xpath("//*[@id='pr_id_2']/div/table").text
print(table)
Chrome 繼續打開,我的 Jupyter 筆記本內沒有列印任何內容(可能是因為表格元素內沒有直接文本[?])
我更希望能夠使用 Beautifulsoup 來獲取表格元素,但歡迎所有答案。感謝您為我提供的任何幫助。
uj5u.com熱心網友回復:
該站點有一個可以很容易地訪問的后端 api:
import requests
import pandas as pd
url = 'https://api.capitoltrades.com/senators/trades/491/false?pageSize=20&pageNumber=1'
resp = requests.get(url).json()
df = pd.DataFrame(resp)
df.to_csv('naughty_nancy_trades.csv',index=False)
print('Saved to naughty_nancy_trades.csv ')
要查看所有資料的來源,請打開瀏覽器的開發者工具 - 網路 - 獲取/XHR 并重新加載頁面,您會看到它們觸發。我已經抓取了其中一個網路呼叫,該頁面上的所有資料還有其他呼叫
uj5u.com熱心網友回復:
根據您的 Selenium 代碼:??您錯過了等待。
這
driver.find_element_by_xpath("//*[@id='pr_id_2']/div/table")
命令在剛剛創建時回傳您的 web 元素,即已經存在,但仍未完全呈現。
這應該會更好:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
DRIVER_PATH = '/Users/myname/Downloads/capitol-trades/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
wait = WebDriverWait(driver, 20)
driver.get('https://app.capitoltrades.com/politician/491')
table = wait.until(EC.visibility_of_element_located((By.XPATH, "//*[@id='pr_id_2']//tr[@class='p-selectable-row ng-star-inserted']"))).text
print(table)
根據您的 BS4 代碼,您似乎使用了錯誤的定位器。
這:
table = soup.find("table", {"class": "p-datatable-table ng-star-inserted"})
看起來更好(您的班級名稱中有額外的空格)。
上面的行回傳 5 個元素。
所以這應該作業:
table = soup.find("table", {"class": "p-datatable-table ng-star-inserted"}).findAll('tr')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/411731.html
標籤: