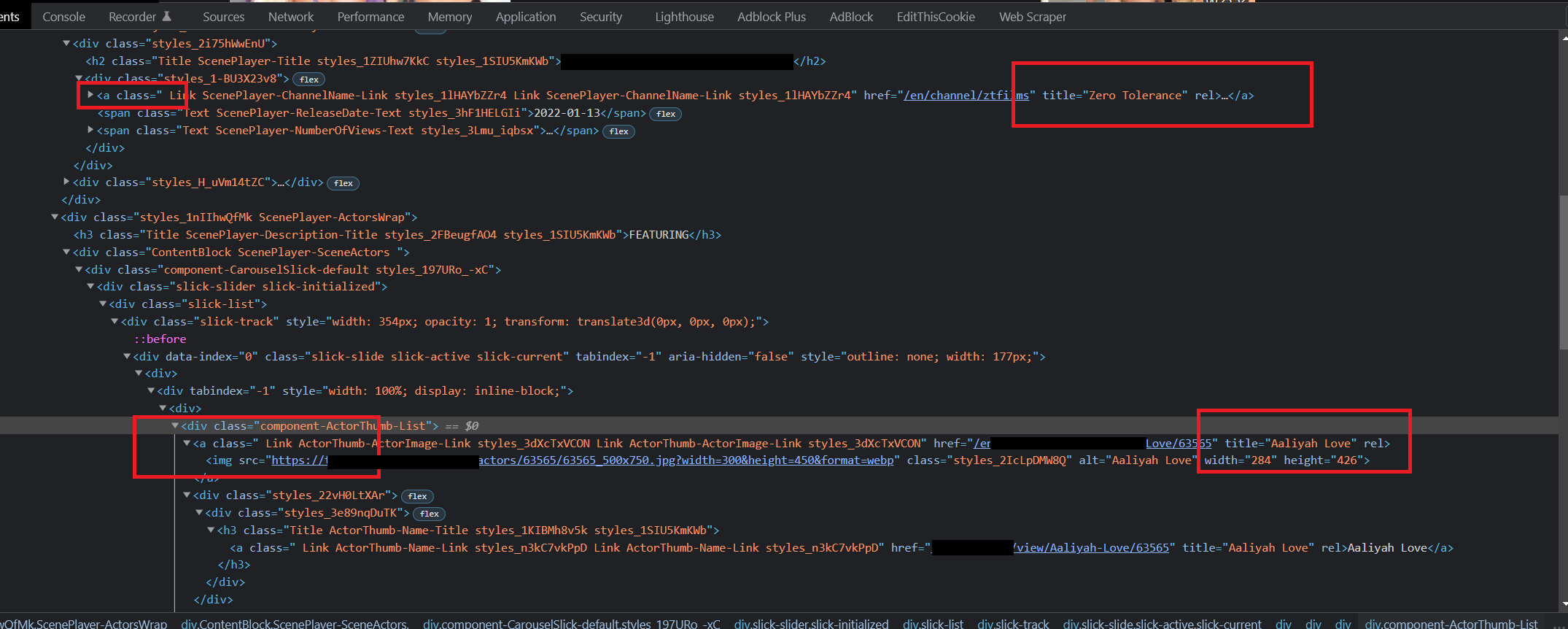
我正在嘗試使用 Selenium 按 ID 列印。據我所知,“a”是標簽,“title”是屬性。請參閱下面的 HTML。
當我運行以下代碼時:
print(driver.find_elements(By.TAG_NAME, "a")[0].get_attribute('title'))
我得到輸出:
Zero Tolerance
所以我得到了正確的第一個屬性。當我增加上面的代碼時:
print(driver.find_elements(By.TAG_NAME, "a")[1].get_attribute('title'))
我的預期輸出是:
Aaliyah Love
但是,我只是變得空白。沒有錯誤。我做錯了什么?請不要建議使用 xpath 或 css,我正在嘗試學習 Selenium 標簽。
HTML:
<a class=" Link ScenePlayer-ChannelName-Link styles_1lHAYbZZr4 Link ScenePlayer-ChannelName-Link styles_1lHAYbZZr4" href="/en/channel/ztfilms" title="Zero Tolerance" rel="">Zero Tolerance</a>
...
<a class=" Link ActorThumb-ActorImage-Link styles_3dXcTxVCON Link ActorThumb-ActorImage-Link styles_3dXcTxVCON" href="/[RETRACTED]/Aaliyah-Love/63565" title="Aaliyah Love"
uj5u.com熱心網友回復:
Selenium 定位器是一個工具箱,您說您只想By.TAG_NAME對所有作業使用螺絲刀 ( )。我們并不是說您不應該使用By.TAG_NAME,我們是說您應該為正確的作業使用正確的工具,有時(大多數情況下)By.TAG_NAME不是適合該作業的工具。CSS 選擇器是更強大的定位器,因為它們不僅可以搜索標簽,還可以搜索類、屬性等。
如果沒有訪問站點/頁面,很難確定發生了什么。可能是整個頁面未加載,您需要添加等待頁面完成加載(也許計算頁面上預期的鏈接?)。可能是您的定位器不夠具體,并且正在捕獲其他沒有標題屬性的 A 標簽。
我會先做一些除錯。
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
print(link.get_attribute('title'))
這個列印什么?
如果它在整個實際標題中列印出一些空白行,則您的定位器可能不夠具體。試試 CSS 選擇器
links = driver.find_elements(By.CSS_SELECTOR, "a[title]") for link in links: print(link.get_attribute('title'))相反,如果它回傳一些標題,然后只回傳空白行,則頁面可能沒有完全加載。嘗試類似的東西
count = 20 # the number of expected links on the page link_locator = (By.TAG_NAME, "a") WebDriverWait(driver, 10).until(lambda wd: len(wd.find_elements(link_locator)) == count) links = driver.find_elements(link_locator) for link in links: print(link.get_attribute('title'))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/411732.html
標籤:
上一篇:嘗試用Python的Beautifulsoup和Selenium刮桌子
下一篇:當我將全域變數“Driver”宣告為None時,它??說Cannotfindreference'find_elements'in'None',也沒有建議