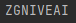
我正在使用 Tesseract OCR 嘗試將預處理的車牌影像轉換為文本,但是對于一些看起來非常不錯的影像,我并沒有取得太大的成功。可以在函式定義中看到 tesseract 設定。我在 Google Colab 上運行它。輸入影像ZG NIVEA 1如下。我不確定我是否使用了錯誤的東西,或者是否有更好的方法來做到這一點 - 我從這個特定的影像中得到的結果是A。

!sudo apt install -q tesseract-ocr
!pip install -q pytesseract
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
import cv2
import re
def pytesseract_image_to_string(img, oem=3, psm=7) -> str:
'''
oem - OCR Engine Mode
0 = Original Tesseract only.
1 = Neural nets LSTM only.
2 = Tesseract LSTM.
3 = Default, based on what is available.
psm - Page Segmentation Mode
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
11 = Sparse text. Find as much text as possible in no particular order.
12 = Sparse text with OSD.
13 = Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
'''
tess_string = pytesseract.image_to_string(img, config=f'--oem {oem} --psm {psm}')
regex_result = re.findall(r'[A-Z0-9]', tess_string) # filter only uppercase alphanumeric symbols
return ''.join(regex_result)
image = cv2.imread('nivea.png')
print(pytesseract_image_to_string(image))
編輯:接受的答案中的方法適用于ZGNIVEA1影像,但不適用于其他影像,例如 ,是否存在 Tesseract OCR 最適合使用的一般“字體大小”,或者是否有經驗法則?
,是否存在 Tesseract OCR 最適合使用的一般“字體大小”,或者是否有經驗法則?
uj5u.com熱心網友回復:
通過在 OCR 之前應用高斯模糊,我得到了正確的輸出。此外,您可能不需要通過添加-c tessedit_char_whitelist=ABC..到配置字串來使用正則運算式。
為我產生正確輸出的代碼:
import cv2
import pytesseract
image = cv2.imread("images/tesseract.png")
config = '--oem 3 --psm 7 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ'
image = cv2.resize(image, None, fx=2, fy=2, interpolation=cv2.INTER_CUBIC)
image = cv2.GaussianBlur(image, (5, 5), 0)
string = pytesseract.image_to_string(image, config=config)
print(string)
輸出:
答案 2:
這么晚才回復很抱歉。我在你的第二張圖片上測驗了相同的代碼,它給了我正確的輸出,你確定你洗掉了配置部分,因為它不允許我的白名單中的數字。
這里最準確的解決方案是在車牌字體 (FE-Schrift) 上訓練您自己的 tesseract 模型,而不是 tesseract 的默認 eng.traineddata 模型。它肯定會提高準確性,因為它只包含您案例的字符作為輸出類。作為對后一個問題的回答,tesseract 在識別程序(閾值、形態關閉等)之前進行了一些預處理,這就是為什么影像對字母大小如此敏感的原因。(較小的影像:輪廓彼此更接近,因此關閉不會將它們分開)。
要在自定義字體上訓練 tesseract,您可以遵循官方檔案
要閱讀有關 Tesseract 理論部分的更多資訊,您可以查看以下論文: 1(相對較舊) 2(較新)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/447030.html
標籤:Python python-3.x opencv 正方体 python-正方体
上一篇:使用OpenCV和matplotlib將影像列印到螢屏有什么區別?
下一篇:如果未設定會話,則無法執行腳本