1 什么是lifelong learning
Lifelong learning終生學習,又名continuous learning,increment learning,never ending learning,通常機器學習中,單個模型只解決單個或少數幾個任務,對于新的任務,我們一般重新訓練新的模型,而LifeLong learning,則先在task1上使用一個模型,然后在task2上仍然使用這個模型,一直到task n,Lifelong learning探討的問題是,一個模型能否在很多個task上表現都很好,如此下去,模型能力就會越來越強,這和人類不停學習新的知識,從而掌握很多不同知識,是異曲同工的,
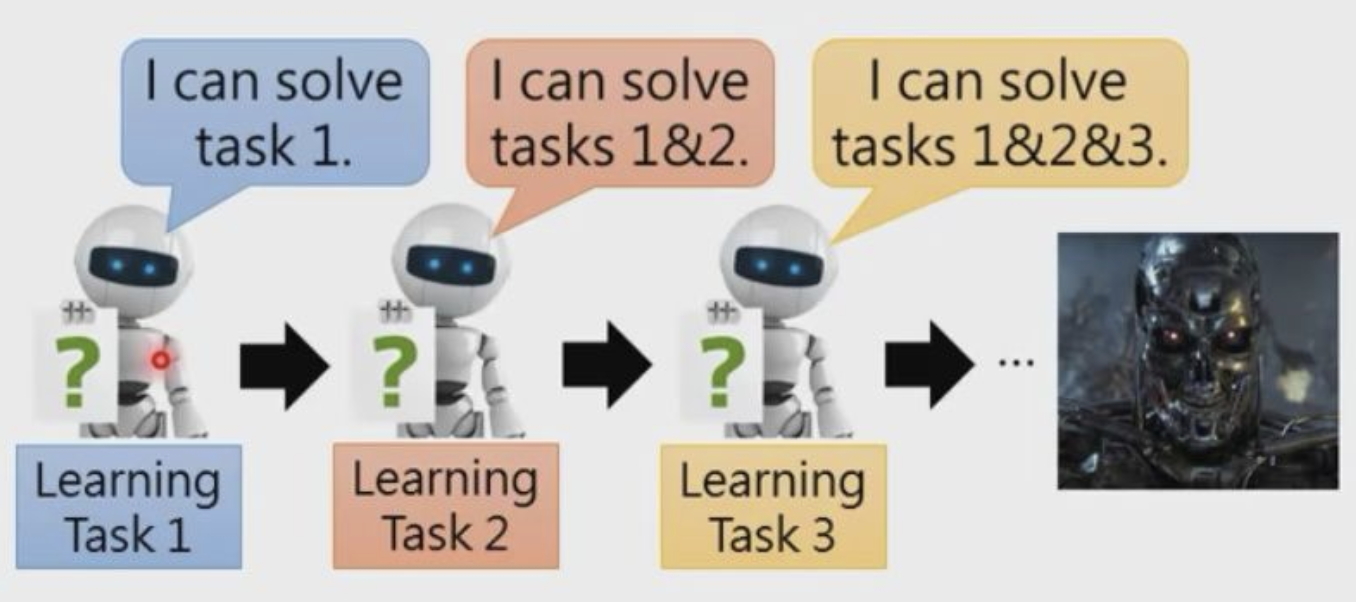
LifeLong learning需要解決三個問題
- Knowledge Retention 知識記憶,我們不希望學完task1的模型,在學習task2后,在task1上表現糟糕,也就是希望模型有一定的記憶能力,能夠在學習新知識時,不要忘記老知識,但同時模型不能因為記憶老知識,而拒絕學習新知識,總之在新老task上都要表現比較好,
- Knowledge Transfer 知識遷移,我們希望學完task1的模型,能夠觸類旁通,即使不學習task2的情況下,也能夠在task2上表現不錯,也就是模型要有一定的遷移能力,這個和transfer learning有些類似,
- Model Expansion 模型擴張,一般來說,由于需要學習越來越多的任務,模型引數需要一定的擴張,但我們希望模型引數擴張是有效率的,而不是來一個任務就擴張很多引數,這會導致計算和存盤問題,
2 Knowledge Retention 知識記憶
出現知識遺忘其實很容易理解,試想一下,訓練完task1后,我們得到了一個模型,再利用這個模型在task2上進行訓練時,會對模型引數進行一定調整,如果引數調整方向和task1的gradient方向相反,則會導致模型在task1上表現變差,那怎么讓task1的知識能夠得到保留呢?顯然我們需要對模型引數更新做一些限制,讓它不要偏離task1太遠,
2.1 EWC
EWC(Elastic Weight Consolidation)就是用來解決這個問題的,它在Loss函式上加入了一個正則,使得模型引數更新必須滿足一定條件,如下
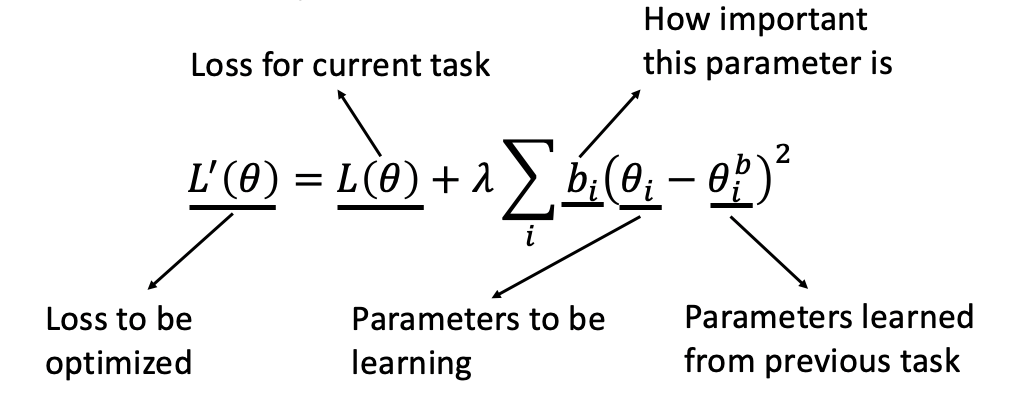
- L(θ)為原始的loss function,后面一項為正則項,
- bi為引數更新權重,表示引數θi有多重要,能不能變化太多
- θi為需要更新的引數,θib為該引數在之前任務上學到的數值,
bi為引數更新權重,表示引數θi能不能變化太多,試想一下
- 如果bi很大,則表明θi不能和θib差距過大,也就是盡量不要動θi
- 如果bi很小,則表明θi的變化,不會對最終loss帶來很大的影響,
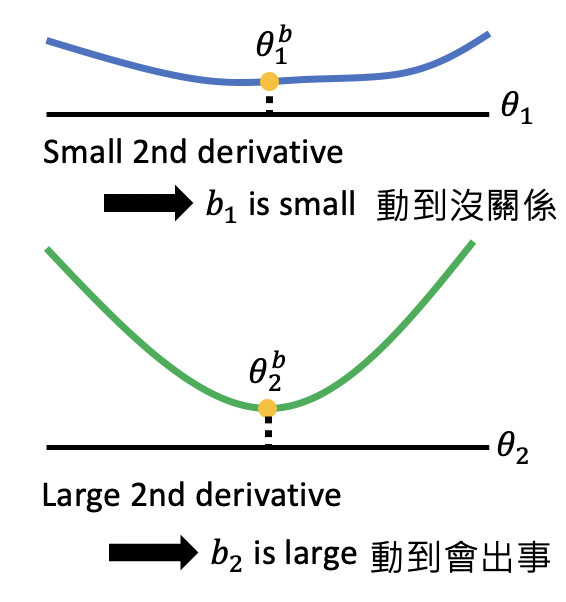
有了正則項和bi后,我們就能指導模型合理的更新引數,從而避免忘記之前的task,那問題來了,bi怎么得到呢?EWC給出了它的解決方案,它利用二階導數來確定bi,如果二階導數比較小,位于一個平坦的盆地中,則表明引數變化對task影響小,此時bi小,如果二階導數比較大,位于一個狹小的山谷中,則表明引數變化對task影響大,此時bi大,
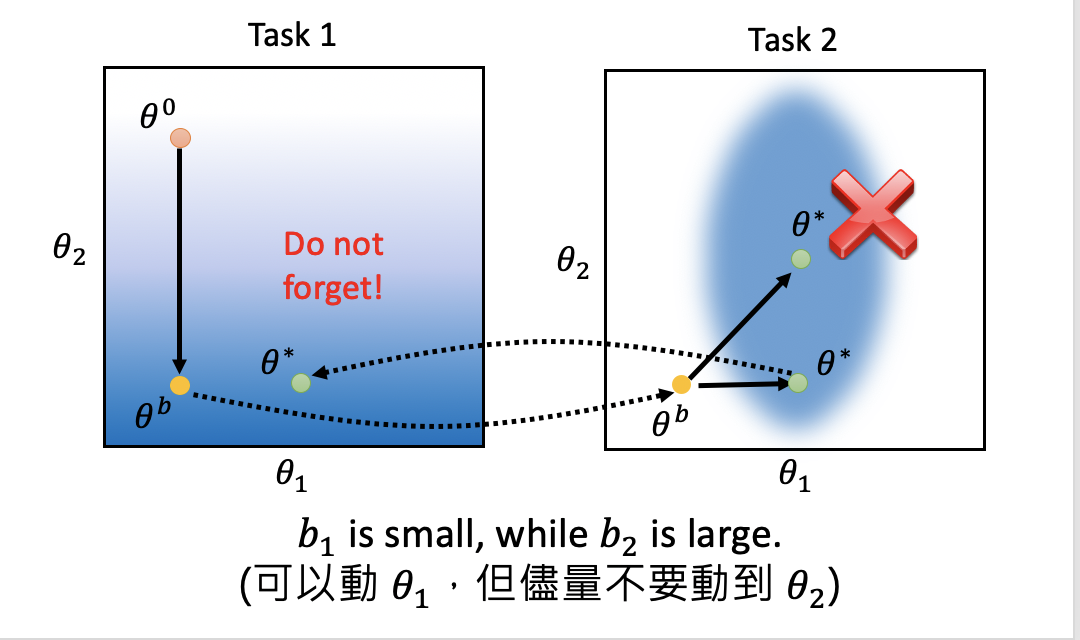
利用EWC后的效果如下圖所示,藍色越深代表模型效果越好,假如模型有兩個引數θ1和θ2,在task1上訓練后,引數更新為θb,在task2上更新引數時,有很多個不同的引陣列合,都可以在task2上表現很好(藍色區域),如果我們沿斜上方更新引數,雖然task2效果好,但在task1上效果卻很差,也就是出現了遺忘問題,如果我們沿水平方向更新引數,也就是θ1的方向,則task1上模型效果依然OK,這表明,通過EWC是可以做到讓模型記住以前學到的知識的,
2.2 生成樣本
還有一種思路,在學習task2時,我們可以利用生成模型,生成task1的樣本,然后利用task1和task2的樣本,進行多任務學習,使得模型在兩個task上均表現很好,這里的難點在于,生成樣本,特別是復雜的樣本,目前難度是很大的,可以作為一個idea參考,但個人認為可行性不高,
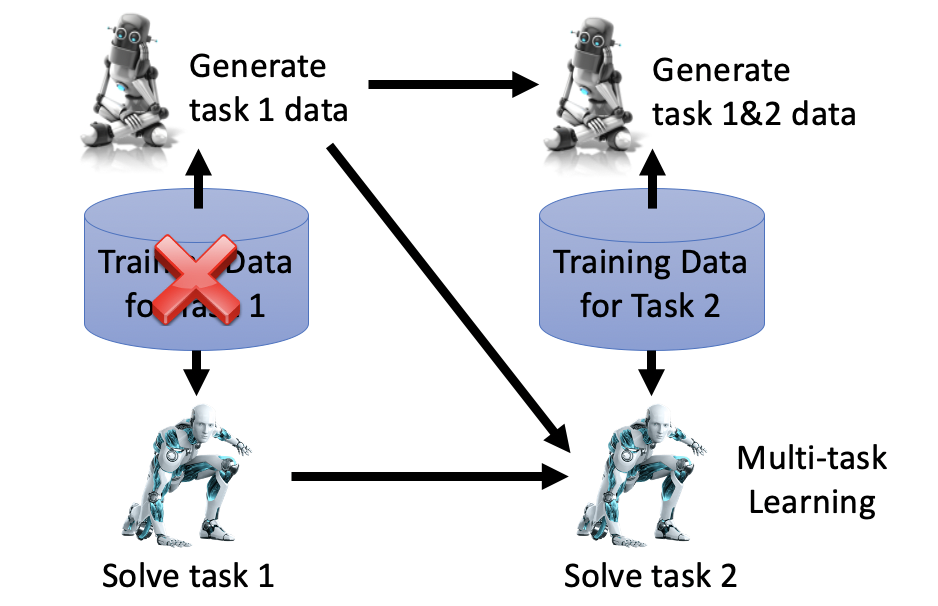
3 Knowledge Transfer 知識遷移
終生學習也對模型提出了另一個要求,那就是遷移能力,通過學習task1、task2等多個task,在不學習task n的情況下,模型是否能舉一反三,表現仍然不錯呢,
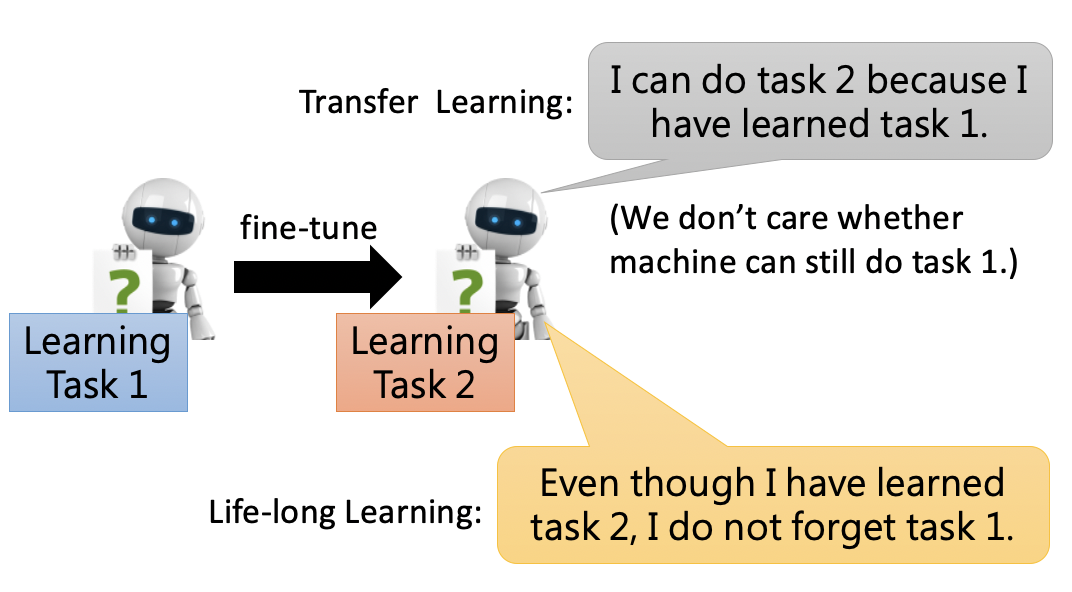
終生學習和遷移學習有一些類似的地方,區別在于遷移學習只關注遷移后模型在target task上要表現好,至于source task則不關心,而終生學習則需要模型在兩個task上都表現好,不能出現遺忘,可以將終生學習理解為更嚴格的遷移學習,
4 Model Expansion 模型擴張
一般來說,由于需要學習越來越多的任務,模型引數需要一定的擴張,但我們希望模型引數擴張是有效率的,而不是來一個任務就擴張很多引數,這會導致計算和存盤問題,所以怎么對模型引數進行有效率的擴張,就顯得十分關鍵了,
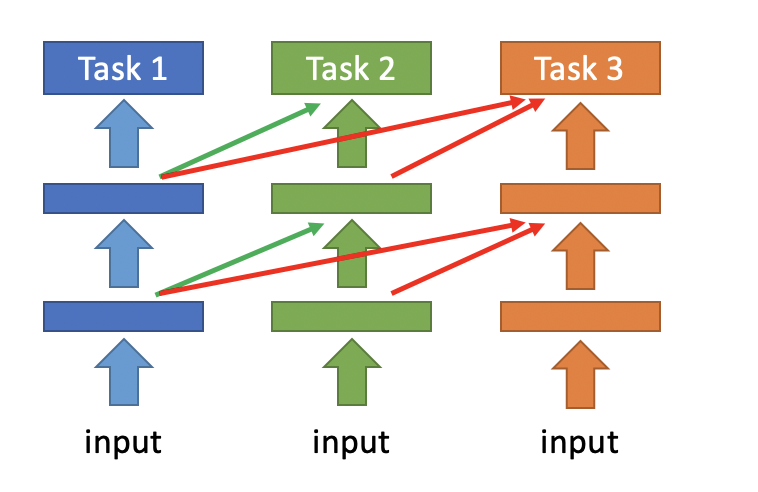
一種方法是progressive neural network,它將task1每層輸出的feature,作為task2對應層的輸入,從而讓模型在學習后面task的時候,能夠記住之前task的一些資訊,如下圖
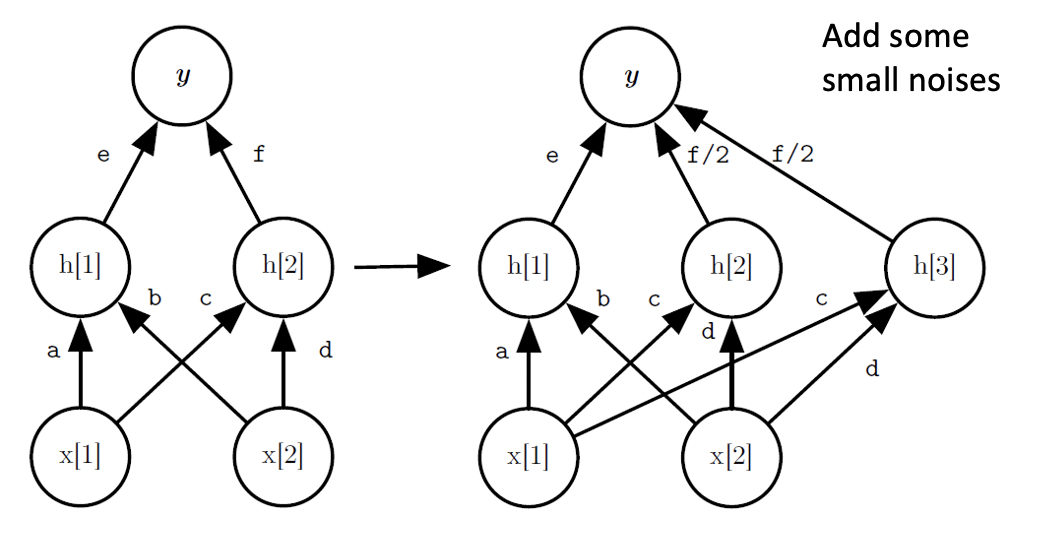
另一種方法是Net2Net,它對網路進行加寬,如下圖所示,由神經元h2分裂得到一個神經元h3,初始時和h2一樣,h2和h3權重均為之前h2權重的一半,為了防止h2和h3訓練程序中始終保持一致,故在h3上添加一些小噪聲,使二者能夠獨立更新,
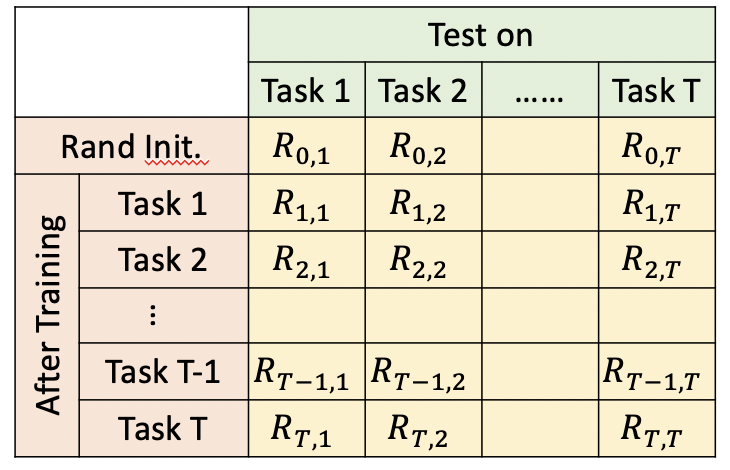
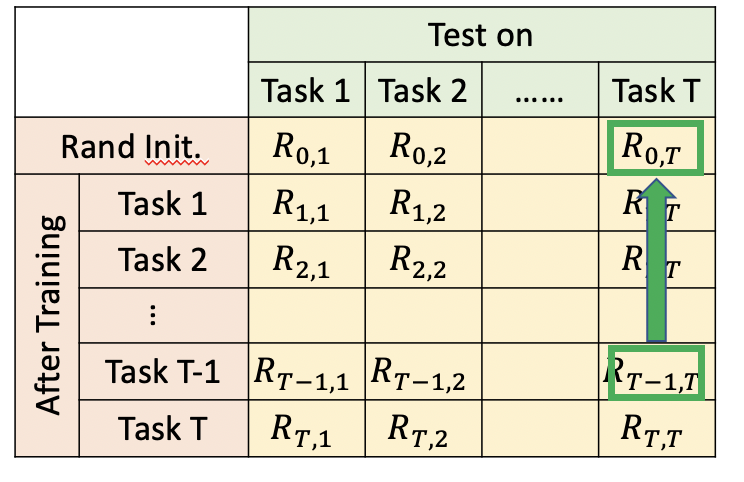
5 評價方法
終生學習模型的評價,也很重要,如下圖我們構建一個table,橫軸表示學習完某個task后,在其他task上的表現,縱軸表示某個task,在其他task學習完后的表現,綜合下來
- 當i>j時,表示學習完task i后,task j有沒有被忘記,代表模型記憶能力
- 當i<j時,表示學習完task i后,模型在還沒有學習的任務task j,上的表現,代表模型遷移能力,
評估主要包括三個指標
- ACC
- 記憶能力
- 遷移能力
5.1 ACC
模型準確率ACC為,學習完最后一個任務task T后,模型在task1、task2、task T-1上的平均準確率,
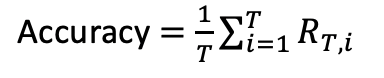
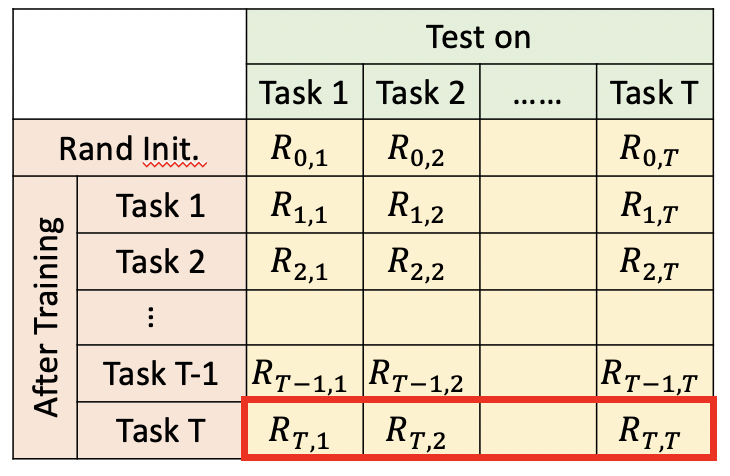
5.2 記憶能力
記憶能力衡量了模型學習完最后一個任務task T后,在之前task上的表現,一般來說,模型會忘記之前task,所以這個指標一般為負數
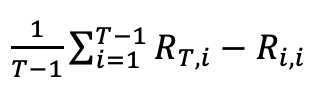
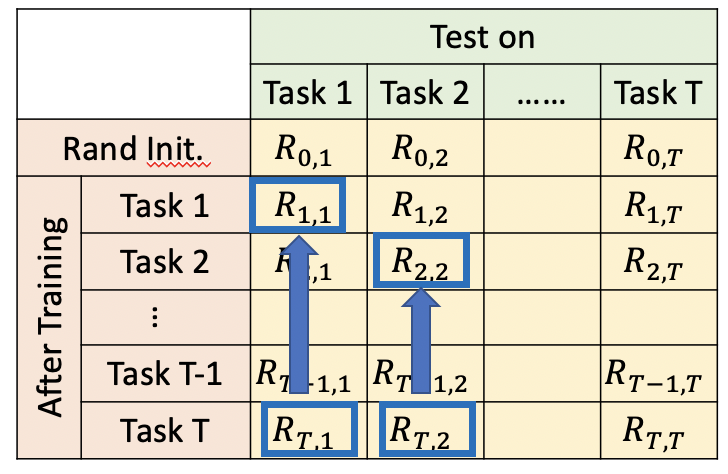
5.3 遷移能力
遷移能力衡量了模型在學習完一個任務后,在未學習的task上的表現,一般和隨機初始化的模型進行對比,
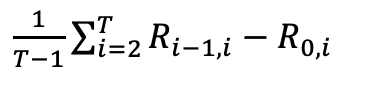
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/46082.html
標籤:其他
上一篇:一文搞定貸款利息計算
下一篇:What Does BERT Look At? An Analysis of BERT’s Attention 論文總結