小白學習:李航《統計學習方法》第二版第11章 條件隨機場(二)----條件隨機場
小提示:食用這篇文章前,務必需要搞懂一中的馬爾科夫隨機場的內容,因為條件隨機場在模型建立方面“依仗著”關于馬爾科夫隨機場的性質,所以大家可以去看看前一欄,
小白學習:李航《統計學習方法》第二版第11章 條件隨機場(一)----馬爾科夫隨機場
目錄
- 小白學習:李航《統計學習方法》第二版第11章 條件隨機場(二)----條件隨機場
- 前言
- 一、條件隨機場的定義與形式
- 條件隨機場的定義
- 線性鏈條件隨機場
- 線性鏈條件隨機場的定義
- 舉個栗子
- 線性鏈條件隨機場的向量形式
- 線性鏈條件隨機場的矩陣形式
- 二、條件隨機場的概率計算問題
- 1.條件隨機場的概率計算
- 2.條件隨機場的期望值的計算
- 三、條件隨機場的學習演算法
- 條件隨機場模型學習的改進的迭代尺度演算法
- 條件隨機場模型學習的預測的維特比演算法
- 舉個栗子
- 總結
前言
? ?在引入條件隨機場之前,我們先來看看為什么要使用條件隨機場,以及條件隨機場能帶來什么,
? ?條件隨機場是Lafferty于2001年提出的一種機器學習的理論,屬于判別模型的一種,最早被應用于自然語言的處理、資訊的檢索和詞性標注問題上,僅僅兩年之后,學者Kumar就將引入到影像處理領域,與經典的馬爾科夫隨機場(Markov Random Fields)不同,Kumar 等人通過考量影像像素自身攜帶的背景關系資訊以及像素被分配的語意類別與真實語意類別之間的關系,建立了一個反映像素位置關系的 CRF 模型,取得了優于傳統模型的分割效果,
條件隨機場中的條件:指的是判別式模型
判別式模型的概念就是給定樣本X可直接建模得到P(c|x)得到類別C,得到“判別式模型”
與判別式模型相對應的是生成式模型,生成式模型的概念是先對概率分布P(c,x)聯合概率建模,再獲得P(c|x)得到“生成式模型”
條件隨機場中的隨機場:指的是無向圖模型
一、條件隨機場的定義與形式
條件隨機場的定義
? ?條件隨機場(conditional random field)是給定隨機變數X的條件下,隨機變數Y的馬爾科夫隨機場,
設X與Y是隨機變數,P(Y|X)是給定X的條件下Y的概率分布,若隨機變數Y構成一個由無向圖G=(V,E)表示的馬爾科夫隨機場,即:
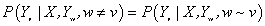
? ?對任意結點v成立稱為條件概率分布P(Y|X)為條件隨機場,式中w~v表示在圖中G=(V,E)中與結點v有邊連接的所有結點w,w不等于v表示結點v以外的所有結點,
? ?這個突然去理解可能比較難,結合上一講的一個不起眼的概念,區域馬爾科夫性質(所以說食用這篇文章前,務必需要搞懂一中的馬爾科夫隨機場的內容,)
? ? 區域馬爾科夫對應的就是設v∈V是無向圖G中任意一個結點,W是與v有邊連接的所有結點,o是除了v和W以外得到其他結點,其表示的是在給定w的條件下,v與o是獨立的,即表示為:P(Yv,Yo|Yw)=P(Yv|Yw)P(Yo|Yw),也就是說結點只條件依賴于相鄰結點,條件獨立于任何其他的結點,
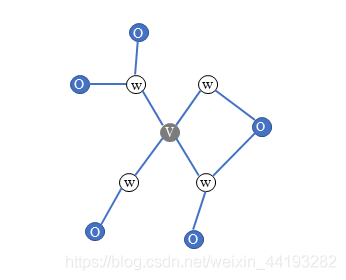
? ?所以說一般的條件隨機場就是滿足區域馬爾科夫性質的條件概率分布,這樣就更好的去理解了,
線性鏈條件隨機場
線性鏈條件隨機場的定義
? ?因為條件隨機場是無向圖模型,所以我們很難根據他們之間的拓撲關系得到條件概率,所以需要引入上一節中的一個定理:Hammersley-cilfford 定理
? ?為了簡便我們將指數上的能量函式exp[-Ei(xa)]用Fi(Xn)來代替,
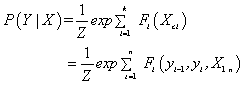
其中:
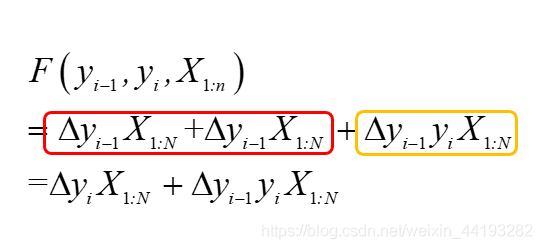
? ?這里解釋下為什么會少掉y(i-1)項,因為對i來說,在i項時,i-1時刻已經迭代過了,其中紅框中的部分稱為狀態函式,橙色的部分稱為轉移函式,這里具體的概念在HMM里面已經有過解釋,不再贅述,
其中狀態函式我們可以寫成以下形式:
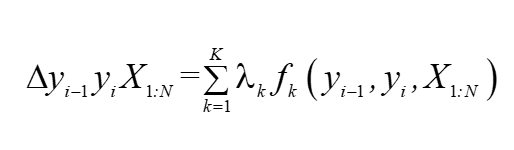
? ?fk表示的是一種特征函式,表示的是該特征的概率取值,例如介詞后一般加名次或者動名詞當我們進行詞性標注的時候就可以將一個介詞后的詞定義成動名詞的概率為0或者1,定義為名詞的概率為0或者1,寫起來就是如此:
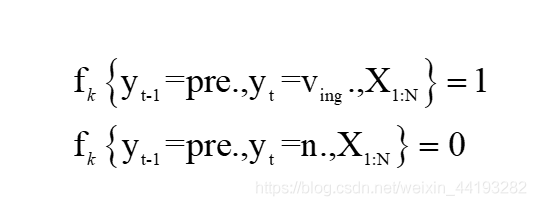 轉移函式可以寫為:
轉移函式可以寫為:
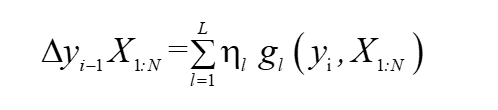
? ?最終得到條件隨機場的引數化形式為:
? ?其中fk、gl都是給定的特征函式,λk,ηl是需要進行學習的引數,最終得到條件隨機場的引數化形式為:
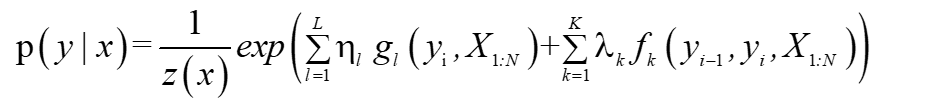
舉個栗子
做一個例題感受下:
? ?設有一個標注問題,輸入觀測為:X=(X1,X2,X3), 輸出標記為 Y=(Y1,Y2,Y3), Y1,Y2,Y3 取值于{1,2},實在懶的打字了,大家湊合看哈,就是書上的例11.1:

? ?首先,我們先根據線性鏈條件隨機場的定義得到該模型為:
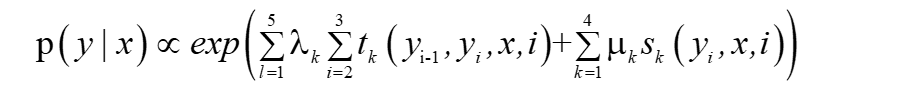
? ?因為這里沒有除以規范化因子所以這里是近似等于的條件概率,當標記序列y=(1,2,2)時我們先計算狀態函式,首先i=2,時,y1=1,y2=2得到第一個藍色圓角框內的特征值,λ=1,t=1,則λt=1,i=3時,y2=2,y3=2,下圖第二個藍色圓角框得到該函式的λt=0.2,則狀態函式的值等于1+0.2=1.2,同理可得到轉移函式的值等于1+0.5+0.5=2,
則給定
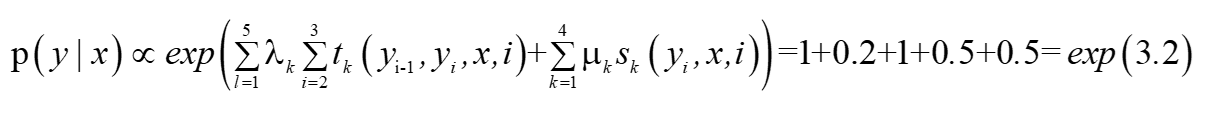
線性鏈條件隨機場的向量形式
? ?通過對條件隨機場引數化形式的研究,我們可以看出同一特征,在每個位置都有定義,再后面進行Learning和inference時進行積分運算時,如果有太多和的形式,進行積分時就不便于運算,所以我們將同一特征在各個位置求和,將區域特征函式轉化為一個全域特征函式,將條件隨機場寫成權值向量和特征向量的內積形式,在這里我為了更好和書上對應,所以將前面推導的變數換了一個名字,但變數的含義沒有改變:
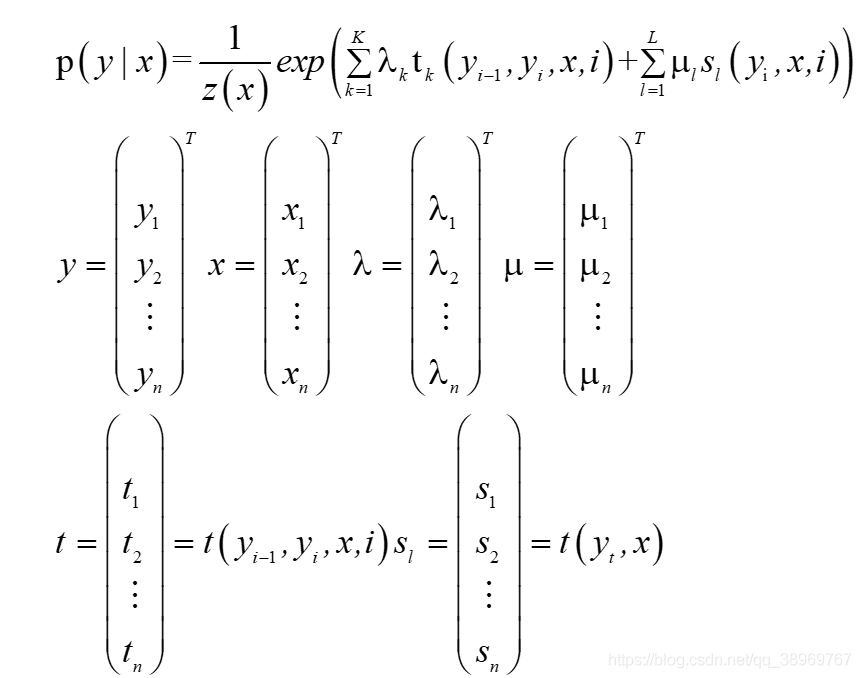
得到:
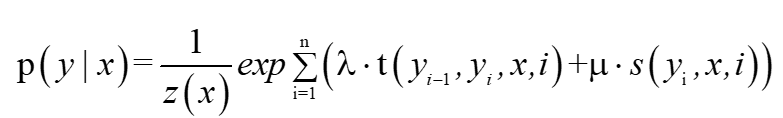
當我們將求和符號寫進每一項中,可以得到:
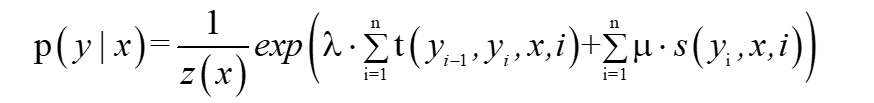
其中,定義w和F如下:
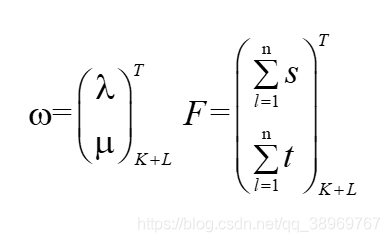
為此,我們就將條件隨機場的引數化形式的兩個求和號消掉,寫出如下形式:
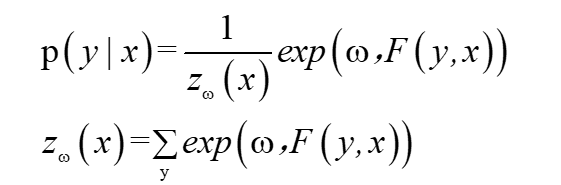
線性鏈條件隨機場的矩陣形式
? ?線性鏈條件隨機場有一個十分重要的性質,就是通過圖可以看出,他們之間是一個線性鏈接關系,每個節點只與自己左鄰和右鄰有邊的連接,為了方便描述,我們在鏈條的起始和終止位置引進一個特殊的起點和終點的狀態標記符,y0=start,y(n+1)=stop,將概率寫為矩陣的形式并進行計算,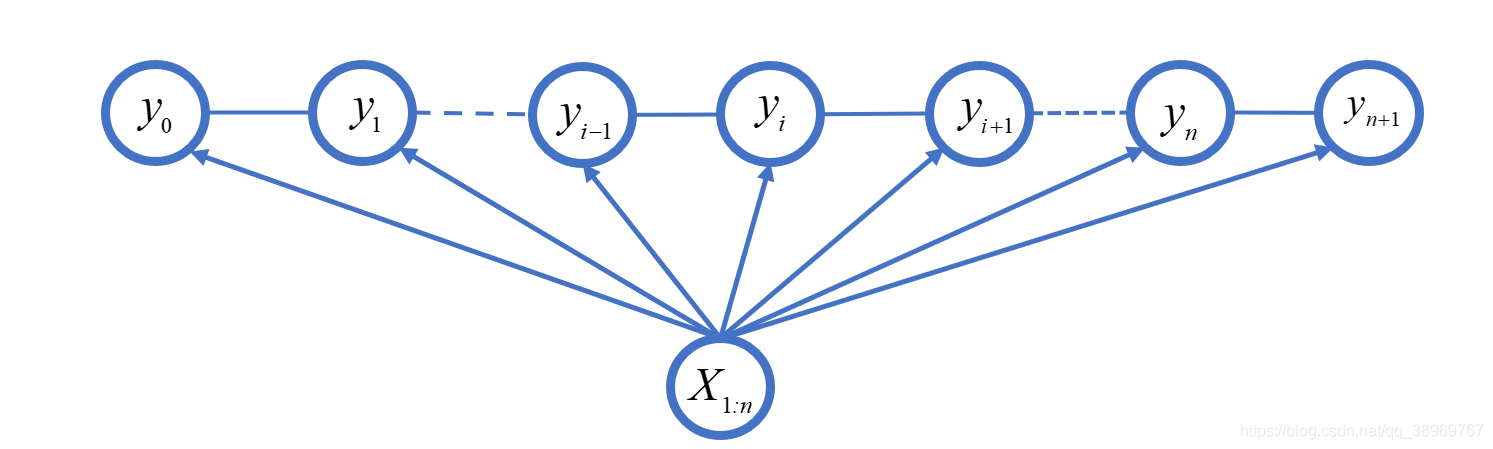
我們引入一個新的變數,令該變數為:
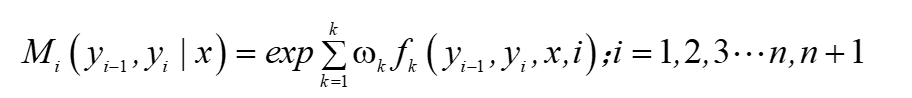
這個矩陣可以看出是針對i于i-1進行的概率計算,假設有m個可能取值,我們就可以得到一個m×m階的矩陣,
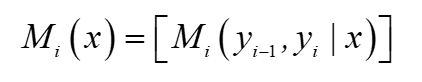
這樣,非規范化概率為: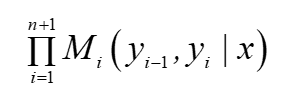
? ?這里為什么可以這么寫呢?其實當時我看到這里的時候也想了好久,后來查閱了一些資料和博客后,恍然大悟,將程序貼出來,減少大家思考的時間,也就是次方的相乘就是指數的相加,
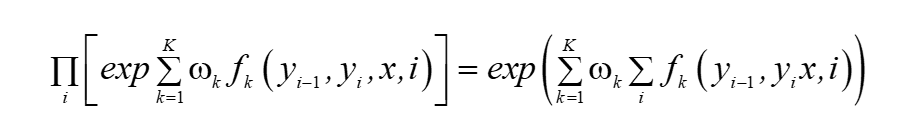
所以,可以得到條件概率為:
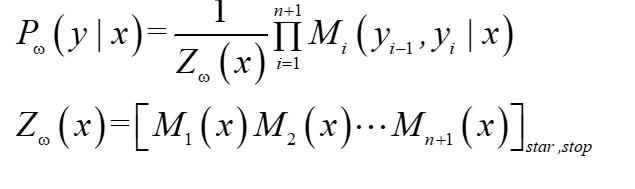
? ?注意,y0 =start , yn+1=stop表示開始狀態與終止狀態,Zw(x)是以start為起點stop為終點通過狀態的所有路徑y1,y2,…,yn的非規范化概率之和,
二、條件隨機場的概率計算問題
1.條件隨機場的概率計算
? ?我們給定P(Y=y|X=x)求P(yt=i|x)我們使用最原始的一個條件隨機場的公式:
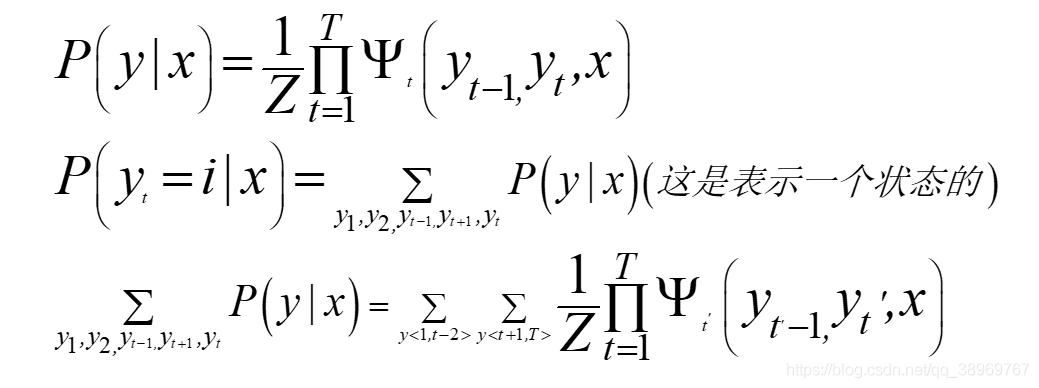
? ?在這里,我們可以看出來如果整個標注的集合為S的話這個式子的復雜度為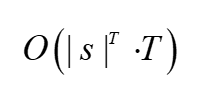
? ?所以我們需要進行變數的消除,具體的做法的話,在周志華的西瓜書的第328頁的14.4中,有一個推導方法,我們這里直接將推導帶入式子中,

得出遞推公式:
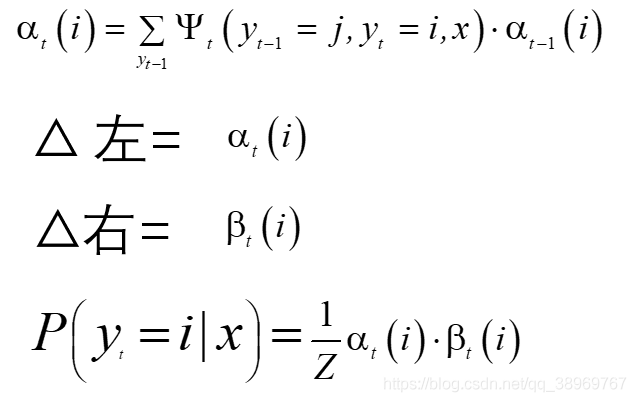
2.條件隨機場的期望值的計算
? ?同理,我們使用前向后向演算法計算特征函式關于聯合分布P(X,Y)和條件分布P(Y|X)的數學期望,
特征函式fk關于條件分布P(Y|X)的數學期望是:
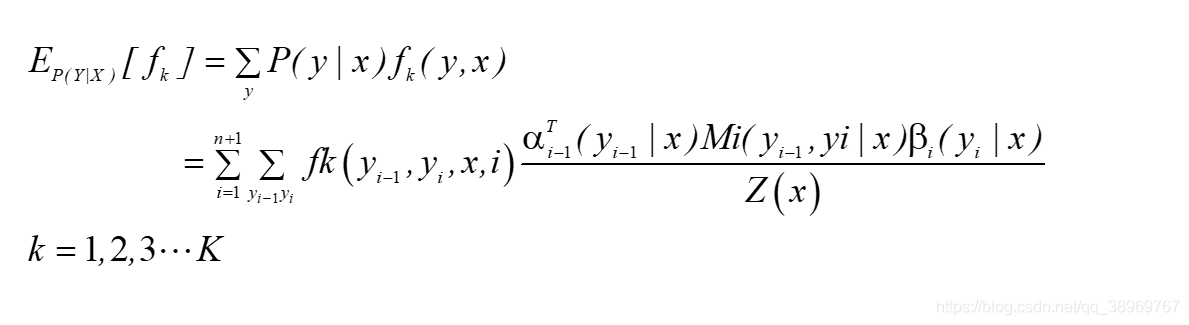 特征函式fk關于聯合分布P(Y,X)的數學期望是:
特征函式fk關于聯合分布P(Y,X)的數學期望是:
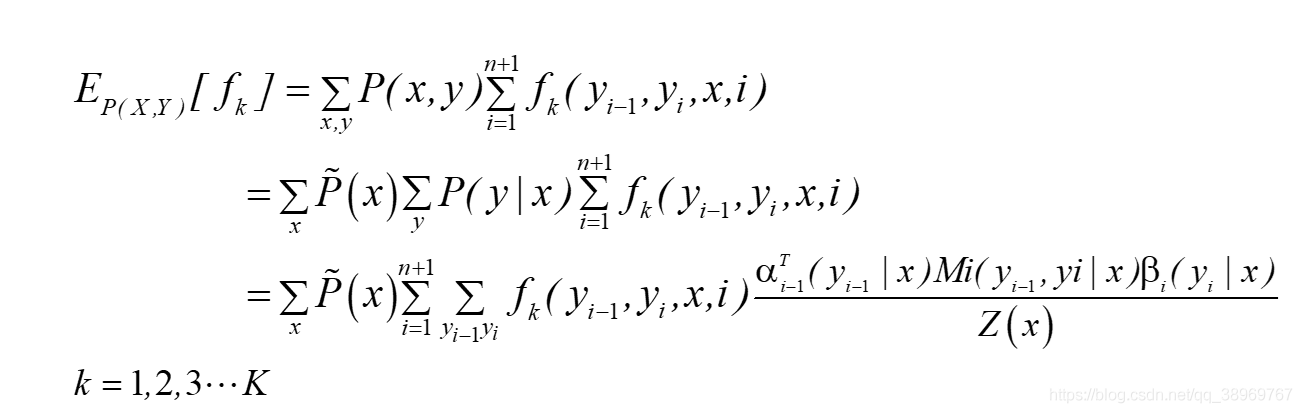
? ?其中k是特征函式,K表示有K個特征函式,該式為通用式,可以將fk轉化為tk,
三、條件隨機場的學習演算法
? ?條件隨機場的模型實際上是定義在時序序列的對數線性模型,其學習方法有很多,很多學者都給出了梯度下降、梯度上升等演算法,可以參考linear-CRF模型引數學習之梯度下降法求解和bilibili的機器學習【白板推導系列】分別介紹了梯度下降法和梯度上升法的解法,但存在著迭代次數高,效率慢的缺點,這里我們使用之前在最大熵模型中使用過的改進的迭代尺度法IIS和擬牛頓法,也是主流的CRF軟體之CRF++使用的演算法,
? ?已知訓練資料集,由此可知經驗概率分布可以通過極大化訓練資料的對數似然函式來求模型引數,
訓練資料的經驗分布為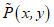 得到似然函式:
得到似然函式:
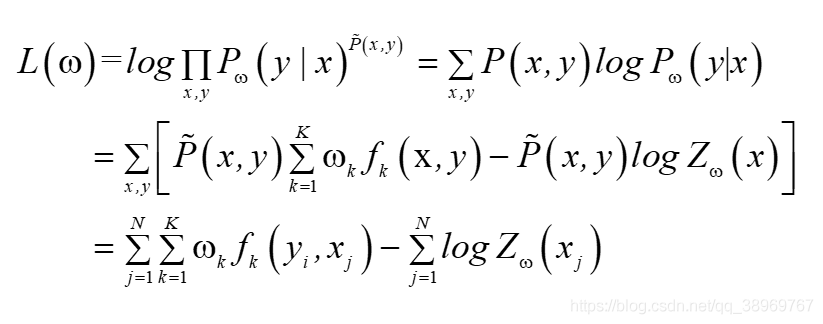
? ?這里其實有一個我很不明白的一個點,最后一步的經驗分布是如何約去的,因為在求解更新方程時,并未用到,所以我沒法驗證最后一步的正確性,如果有大神知道,麻煩可以解釋下,對照邏輯斯蒂回歸一章中極大似然估計中的演算法,其中經驗分布并未舍棄,這里為何就計算消去了呢?
? ?迭代尺度法的思想是找到一個新的引數向量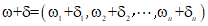
? ? 使得似然函式值增大, 故有:
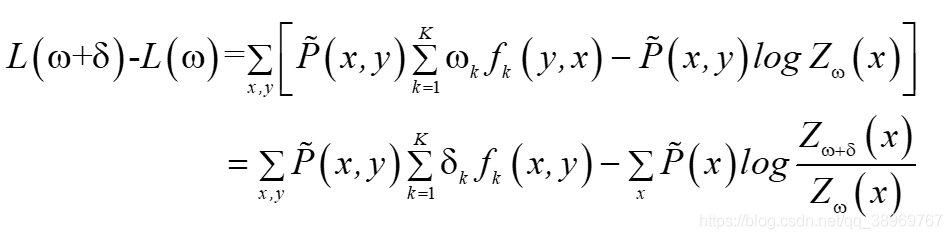
-logα≥1-α,α>0,則有:
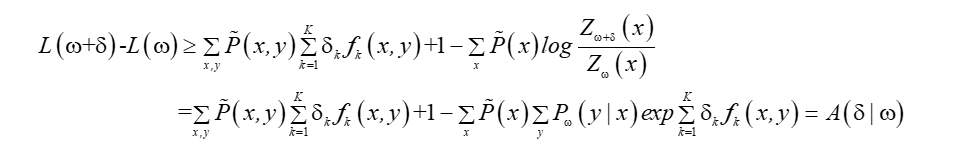
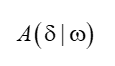
A(δ|ω)是對數似然的下界,當下界提高,對數似然也會提高, 由于fk是二值函式,故f#(x,y)表示的是全部特征(x, y)出現的次數,令:
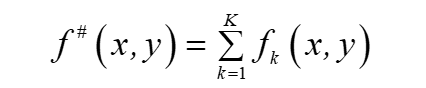
則:
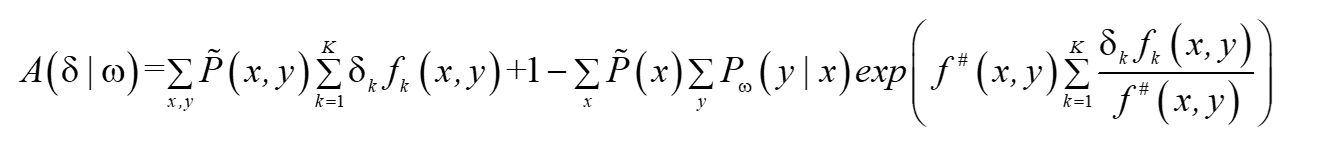
根據Jensen不等式,得到
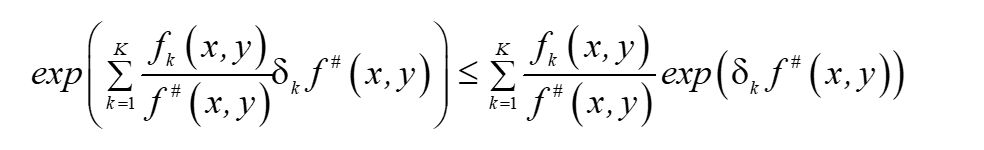
故:
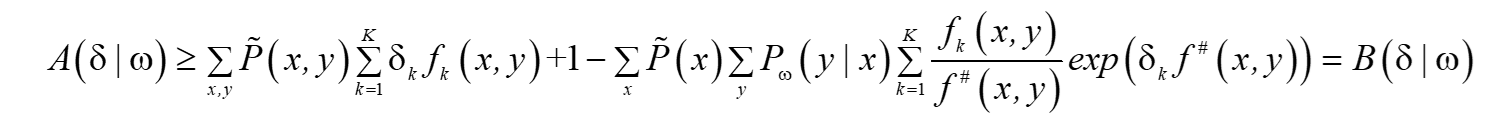 于是得到:
于是得到:
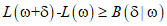
? ?這里B(δ|ω)對數似然函式改變數的一個新的下界,求B(δ|ω)對δi的偏導:這里得到
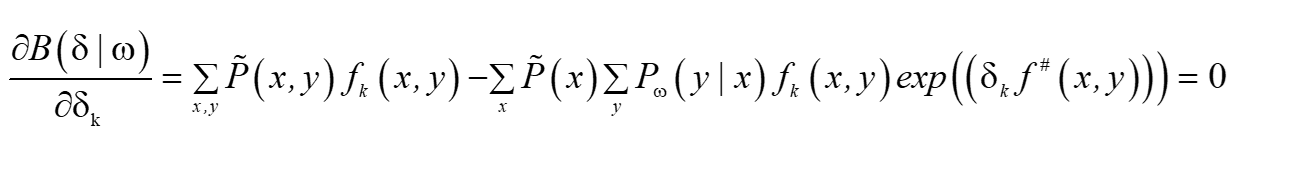
得到:
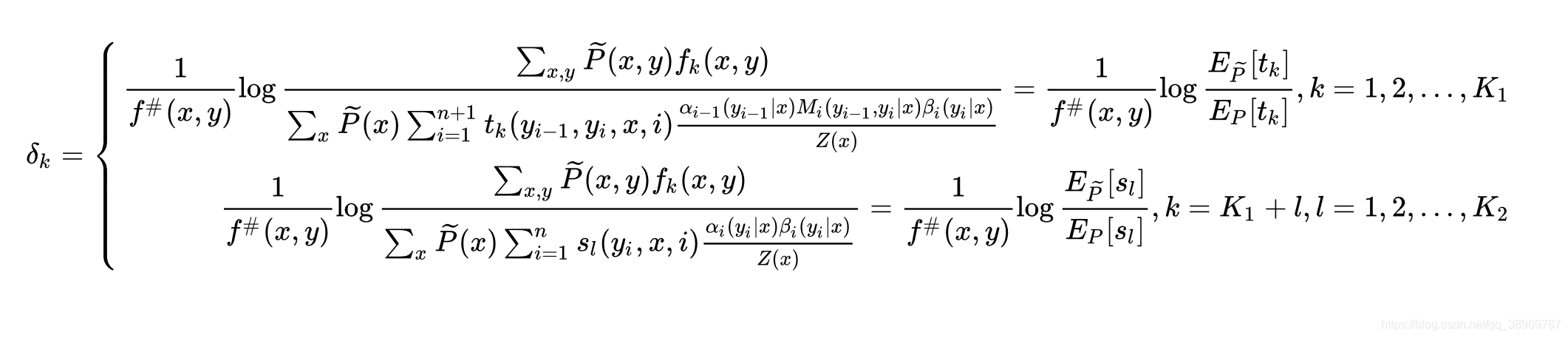
條件隨機場模型學習的改進的迭代尺度演算法

? ?條件隨機場的改進的迭代尺度演算法和最大熵模型的迭代尺度演算法思路一致,但是轉移狀態和特征狀態進行更新時,特征數的綜合f#表示資料(x,y)中的特征總數,對不同的資料取值不同,定義一個常數當選擇足夠大的S使得對訓練資料集的所有資料(x,y),s(x,y)≥0成立,這時:
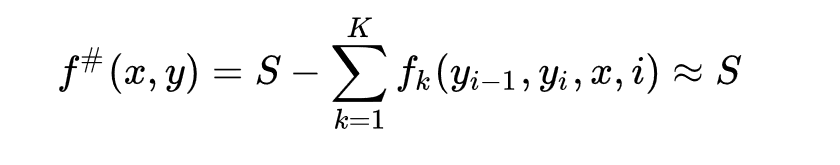
條件隨機場模型學習的預測的維特比演算法
? ?我們的第一個區域狀態定義δi(l),表示在位置i標記l各個可能取值(1,2…m)對應的非規范化概率的最大值,之所以用非規范化概率是,規范化因子Z(x)不影響最大值的比較,利用前向演算法,遞推出位置i+1標記l的運算式和區域狀態Ψi+1(l)來記錄使δi+1(l)達到最大的位置i的標記取值,用這個值用來最侄訓溯最優解,
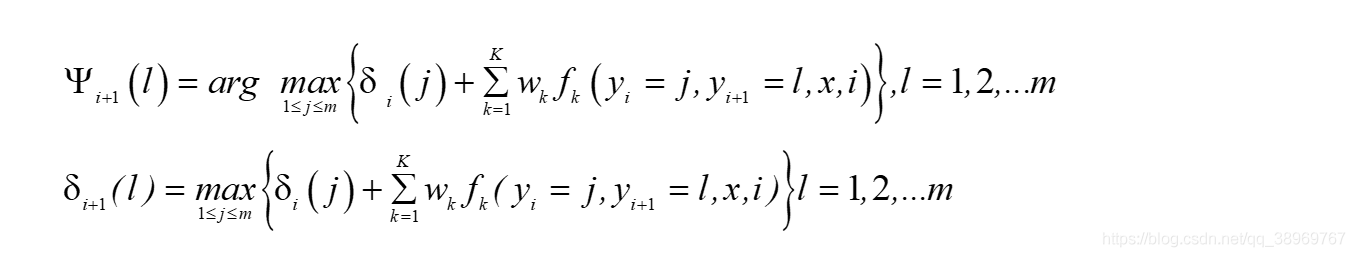

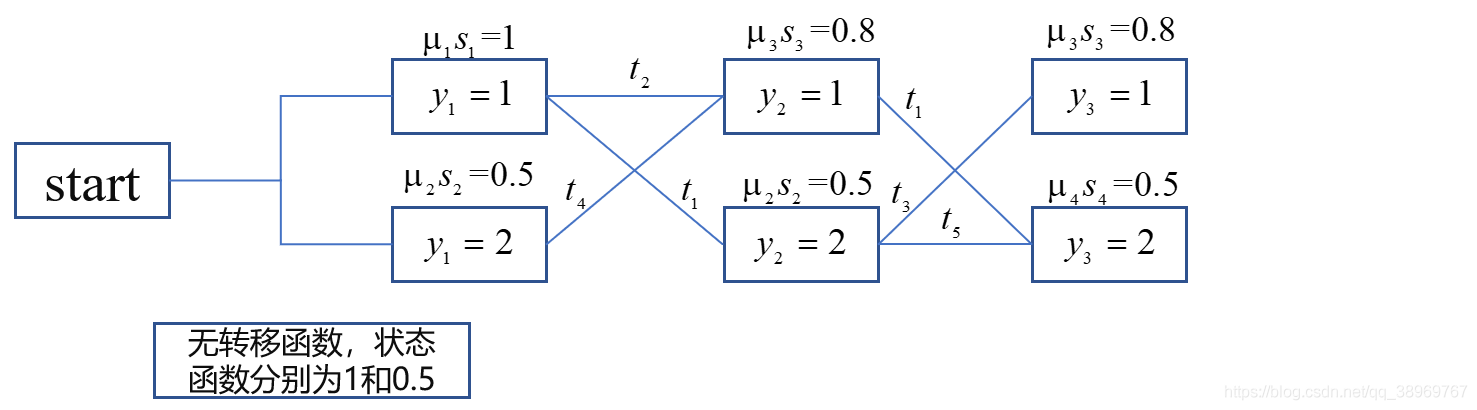
舉個栗子
? ?在例題11.1也就是引數化形式的條件隨機場中的例題,現在我們求他給定輸入序列x對應的最優輸出序列,

首先進行
(1)初始化:
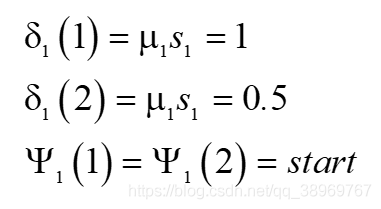
(2)遞推
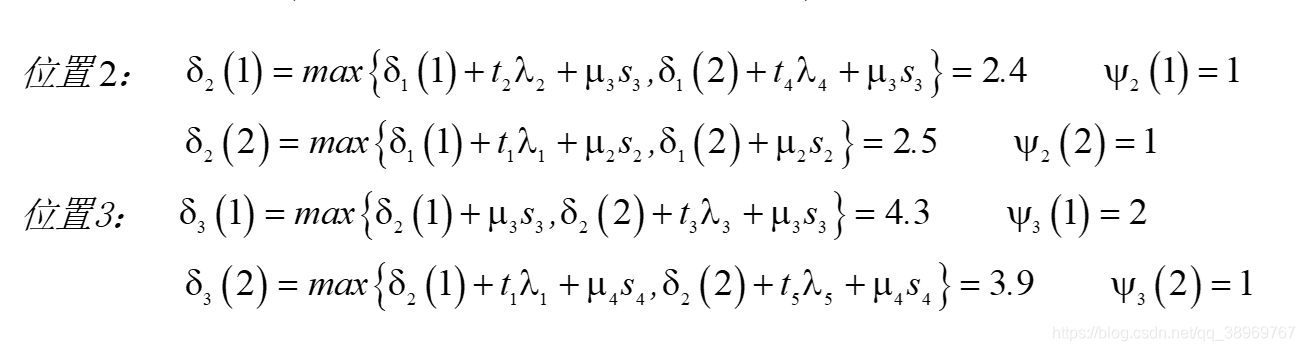
(3)終止
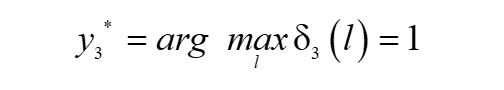
(4)回傳
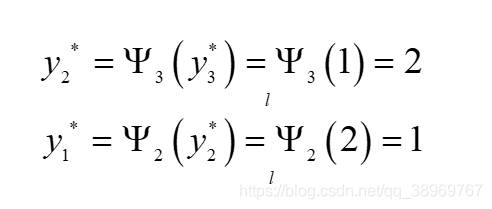
最優標記序列
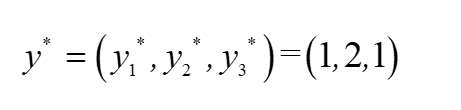
? ?這個題目其實就如上圖所示,計算每一個可能的路徑,然后進行概率比較,取最大路徑,書上將遞推程序寫成了向量形式,其實我覺得向量形式簡化過多,所以還是使用的原始形式,方便計算,s是轉移函式,t是狀態函式,在初始時,沒有進行上級的轉移,所以也就沒有轉移函式只有狀態函式,
總結
? ?linear-CRF相較于HMM來說,最大的不同點是linear-CRF模型是判別模型,而HMM是生成模型,在整個學習、推斷、預測問題的程序中,linear-CRF是利用最大熵模型的思路去建立條件概率模型,對于觀測序列并沒有做馬爾科夫假設,而HMM是在對觀測序列做了馬爾科夫假設的前提下建立聯合分布的模型,在這兩個過渡中其實還有一個模型-MEMM,最大熵馬爾科夫模型,三者之間的關系,我會再寫一篇博客進行探討,其中會與邏輯斯蒂回歸進行關聯,先占坑,等學會了CRF++的使用和看懂條件隨機場與網路和影像的結合,會一起碼上來的!小尚可以的!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/4742.html
標籤:其他