文章目錄
- 0.寫在前面
- 1. 機器學習是什么?
- 2. 從機器學習到深度學習
- 2.1 機器學習的發展歷史
- 2.2 到底機器學習和深度學習的關系是什么?
- 3. 傳統的機器學習演算法沒落了么?還有必要學么?
- 4. 總結
0.寫在前面
在機器學習與深度學習領域學習了一年之后,想寫一篇關于自己對ML和DL的理解,因為學了這么多演算法,需要跳出來看看到底在學啥?
1. 機器學習是什么?
Think the following Conversation:
朋友:你的專業方向是什么啊,小伙子?
我:機器學習!
朋友:哦,那是干啥的?
我:簡單來說就是用資料去解決實際問題的
wait wait,如果行內人問你:你怎么理解機器學習
我:上圖(其實就是圍繞“用資料解決問題稍微展開一下”)

接著上面的對話
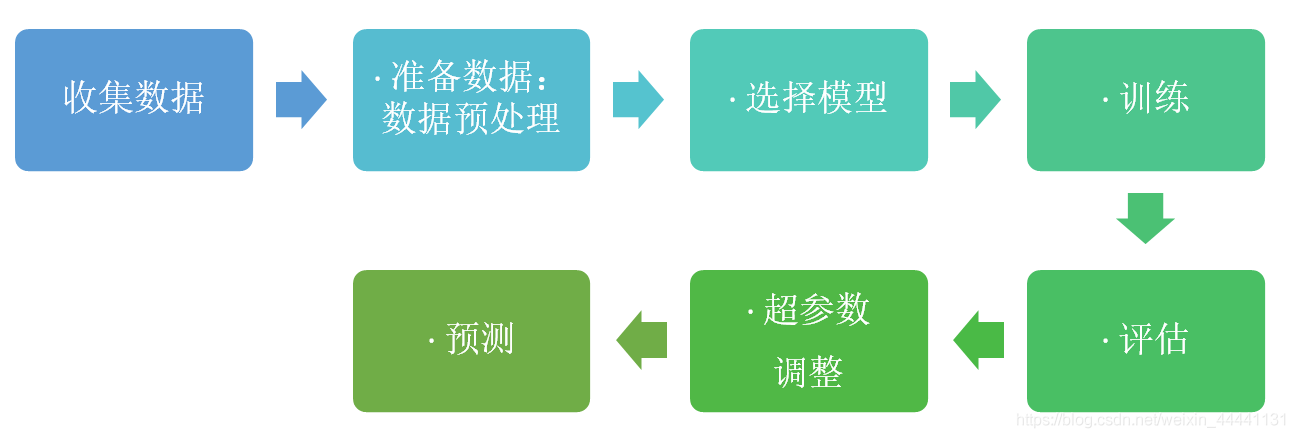
業內人員:你覺得機器學習應該包含哪些程序?
我:上圖,對每一個步驟都可以展開聊一聊
2. 從機器學習到深度學習
2.1 機器學習的發展歷史
機器學習并不是人工智能一開始就采用的方法,人工智能的發展經歷了邏輯推理,知識工程,機器學習三個階段,
1)第一階段的重點是邏輯推理(1950s),例如數學定理的證明,這類方法采用符號邏輯來模擬人的智能
2)第二階段的代表是專家系統(1970s),這類方法為各個領域的問題建立專家知識庫,利用這些知識來完成推理和決策,如果要讓人工智能做疾病診斷,那就要把醫生的診斷知識建成一個庫,然后用這些知識對病人進行判斷,很顯然,它的成本很高,
3)第三階段就是機器學習階段,“授人以魚不如授人以漁“,專家系統需要人工制訂一些規則,資料在根據這些規則去做出預測,有點類似if....then決策樹的意思,與其請那些專家,不如讓模型自己去學習這些規則,這就是機器學習:資料-->模型-->訓練(學習這些資料中的規則或者規律)-->評估-->預測
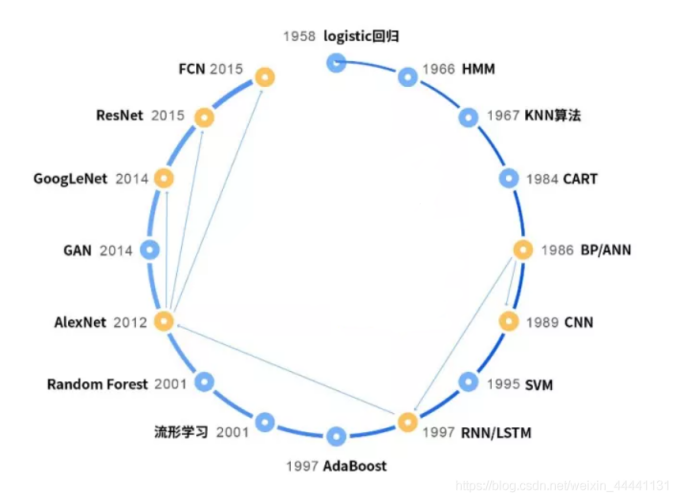
在機器學習時代(上面的第三階段),它的發展又可以分為三個階段,
1)1980年代正式登上歷史舞臺,不具備影響力,不溫不火,主要原因是受限與當時的環境,典型的代表是:
1984:分類與回歸樹(CART)
1986:反向傳播演算法
1989:卷積神經網路
2)1990~2012年,走向成熟和應用,隨著計算機技術的快速發展,機器學習迎來了它的春天,在此期間誕生了眾多的理論和演算法,并真正走向了應用工業界,實作了演算法落地,典型代表演算法有:
1995:支持向量機(SVM)
1997:AdaBoost演算法
1997:回圈神經網路(RNN)和LSTM
2000:流形學習
2001:隨機森林
3)2012年~至今為深度學習時期,神經網路卷土重來,在與SVM的競爭中,神經網路長時間內處于下風,直到2012年局面才被改變,原因是計算機處理資料的能力越來越好,SVM、AdaBoost等所謂的淺層模型并不能很好的解決影像識別,語音識別等復雜的問題,在這些問題上存在嚴重的過擬合(過擬合的表現是在訓練樣本集上表現很好,在真正使用時表現很差,就像一個很機械的學生,考試時遇到自己學過的題目都會做,但對新的題目無法舉一反三),為此我們需要更強大的演算法,歷史又一次選擇了神經網路,深度學習技術誕生并急速發展,較好的解決了現階段AI的一些重點問題,并帶來了產業界的快速發展,
深度學習的起源可以追溯到2006年的一篇文章《 Reducing the Dimensionality of Data with Neural Networks》,Hinton等人提出了一種訓練深層神經網路的方法,用受限玻爾茲曼機訓練多層神經網路的每一層,得到初始權重,然后繼續訓練整個神經網路,2012年Hinton小組發明的深度卷積神經網路AlexNet(《ImageNet Classification with Deep Convolutional Neural Networks》)首先在影像分類問題上取代成功,隨后被用于機器視覺的各種問題上,包括通用目標檢測,人臉檢測,行人檢測,人臉識別,影像分割,影像邊緣檢測等,在這些問題上,卷積神經網路取得了當前最好的性能,
在另一類稱為時間序列分析的問題上,回圈神經網路取得了成功,典型的代表是語音識別,自然語言處理,使用深度回圈神經網路之后,語音識別的準確率顯著提升,直至達到實際應用的要求,

歷史選擇了深度神經網路作為解決影像、聲音識別、圍棋等復雜AI問題的方法并非偶然,神經網路在理論上有萬能逼近定理(universal approximation),文章來自《Multilayer feedforward networks are universal approximators》):
只要神經元的數量足夠,激活函式滿足某些數學性質,至少包含一個隱含層的前饋型神經網路可以逼近閉區間上任意連續函式到任意指定精度,即用神經網路可以模擬出任意復雜的函式,我們要識別的影像、語音資料可以看做是一個向量或者矩陣,識別演算法則是這些資料到類別值的一個映射函式,
2016年3月份,震驚世界的AlphaGo以4:1的成績戰勝李世石,將深度學習技術(具體來講是強化學習)推向高潮,讓越來越多的人了解到深度學習的魅力,也讓更多的人加入深度學習的研究,
下圖展示了這些年的經典演算法:
2.2 到底機器學習和深度學習的關系是什么?
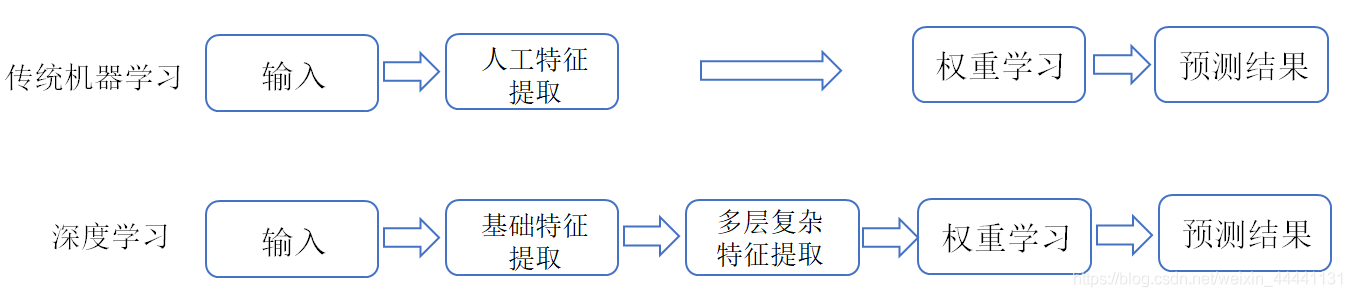
其實可以從特征提取的角度考慮問題,機器學習對資料的特征需要一定的洞察能力,到底什么是好的特征,這是ML要思考的問題,而深度學習相當于把資料放在了黑盒子中,然后”搖一搖“,就能自動學習到有用的特征,剋說DL是一種端到端的學習(end-to-end).
3. 傳統的機器學習演算法沒落了么?還有必要學么?
有時候學習深度學習學的陷進去了,慢慢地,覺得既然有了深度學習,那我們還學習機器學習干什么,除了作業實習面試需要,不知道你們是否有這樣的疑惑?
后來跳出來想一想,學習機器學習非常必要,相當必要!
首先,考慮深度學習與機器學習的關系,深度學習是機器學習的一部分,所以說機器學習是深度學習的基石,
其次,深度學習占據統治地位的多數是在計算機視覺領域、自然語言處理領域,而且深度學習是 data driven 的,需要大量的資料,資料是其燃料,沒了燃料,深度學習也巧婦難為無米之炊,如影像分類任務中,就需要大量的標注資料,因為有了 ImageNet 這樣 百萬量級,并帶有標注 的資料,CNN 才能大顯神威,
事實上,在實際的問題中,我們可能并不會有海量級別的、帶有標注的資料,如你在做醫學方面的一些模型,能拿到病人的資訊資料少之又少,所以說在小資料集上,深度學習還取代不了諸如 非線性和線性核 SVM,貝葉斯分類器 方法,實際操作來看,SVM 只需要很小的資料就能找到資料之間分類的 超平面,得到很不錯的分類結果,
所以,根據奧卡姆剃刀原理,能用 Linear regression、Logistic regression 能解決的問題,還干嘛一定要用深度學習演算法呢?
所以,雖然深度學習發展如火如荼,但是其他機器學習演算法并不會因此而沒落,
4. 總結
-
深度學習是 data driven 的,需要大量的資料,而傳統的機器學習演算法通暢不需要;
-
深度學習本質上可以看作一個特征學習器,在無需另構特征情況下,傳統的機器學習演算法已經能夠勝任日常的任務;
-
如無必要,勿增物體,能夠簡單的模型解決的,不必要上深度學習演算法,殺雞焉用牛刀?
參考文章:
https://blog.csdn.net/yezi_1026/article/details/52760709
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/4743.html
標籤:其他
上一篇:小白學習:李航《統計學習方法》第二版第11章 條件隨機場(二)----條件隨機場
下一篇:小小白學C成長記(第四期)