文章目錄
- 前言
- 1. 爬取百度文章
- 1.1 網頁分析
- 1.2 代碼實作
- 1.3 代碼測驗
- 2. 爬取微信公眾號文章
- 2.1 網頁分析
- 2.2 反爬分析
- 2.3 代碼實作
- 2.4 代碼測驗
- 3. 模型訓練
- 4. 相似度分析
- 5. 剩下的就交給客服吧
- 結束語
前言
??免責宣告:
????本篇博文的初衷是分享自己學習逆向分析時的個人感悟,所涉及的內容僅供學習、交流,請勿將其用于非法用途!!!任何由此引發的法律糾紛均與作者本人無關,請自行負責!!!
??著作權宣告:
????未經作者本人授權,禁止轉載!!!

??沒想到,我的博客竟然被抄襲了(??へ??╬),文章一丟丟都不改,原封不動的照搬,更過分的是,將作者的名字直接改成他自己的名字,然后美名其曰:“原創”;還有個網站在未經授權的情況下,直接連作者名字都抄,也不標注來源,,,這種行為本人極其鄙視,雖然客服及時做了處理,將侵權的文章洗掉了,但這樣的懲罰措施未免也太輕了些,抄襲者沒有付出什么代價,而且抄襲對他們來說百利而無一害,沒有直接封號來的實在,希望這方面的制度繼續完善,
??本篇博文就是在這樣的背景下,分享一個博客查重腳本,通過對全網進行搜索,對相關網頁進行相似度分析,對相似度極高的網頁進一步核實,一旦發現抄襲,就聯系客服進行著作權申訴,
??目標:通過輸入關鍵詞資訊,在百度和微信公眾號分別進行搜索,將相關文章保存到本地,然后再進行相似度分析,輸出相似度高的文章鏈接,以便后面的著作權申訴,
??工具:Google Chrome、Charles、PyCharm

1. 爬取百度文章
??這里以我的這篇文章《Python爬蟲:逆向分析網易云音樂加密引數》為例,進行查重,
1.1 網頁分析
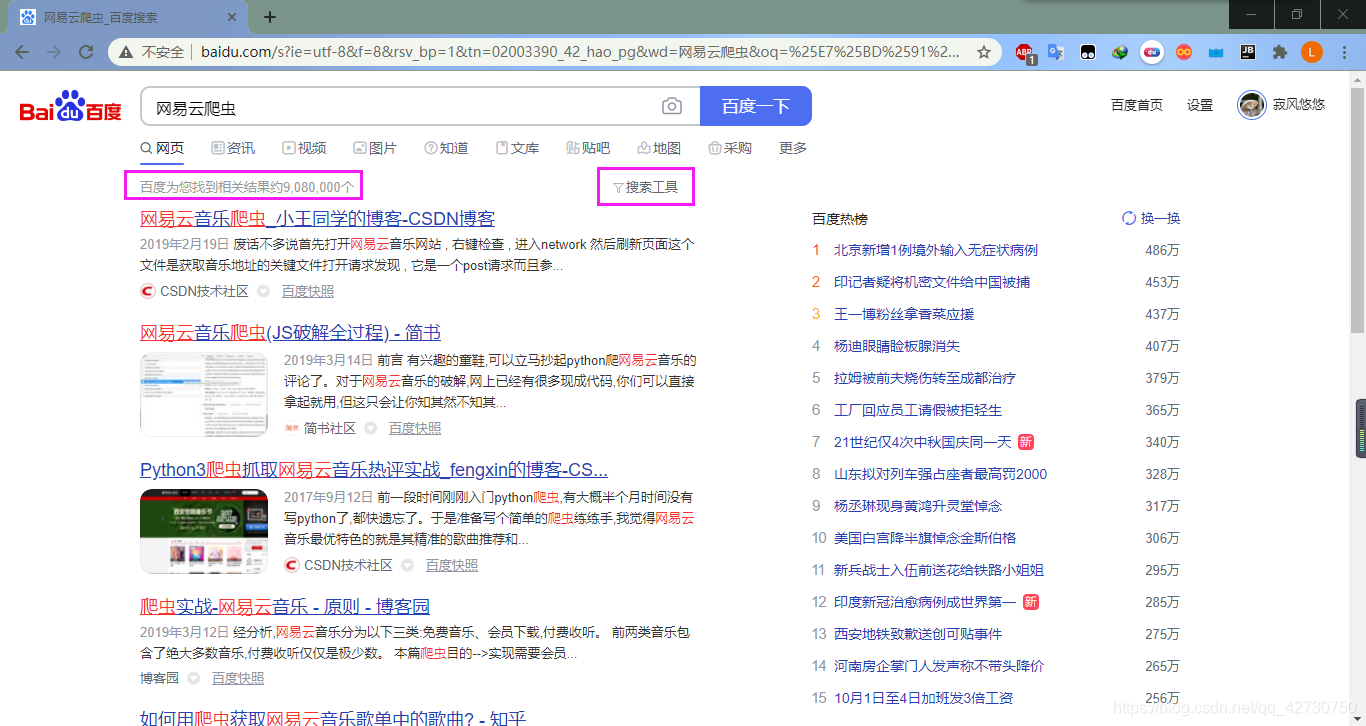
??首先我們在百度上輸入關鍵詞網易云爬蟲進行搜索,搜索結果有九百多萬條,為了方便我們這里選擇近一個月發表過的文章,操作就是點擊右側的搜索工具,時間選擇一個月內,如下圖:
??然后我們打開Chrome的除錯面板,相關資訊是直接放在網頁上的:
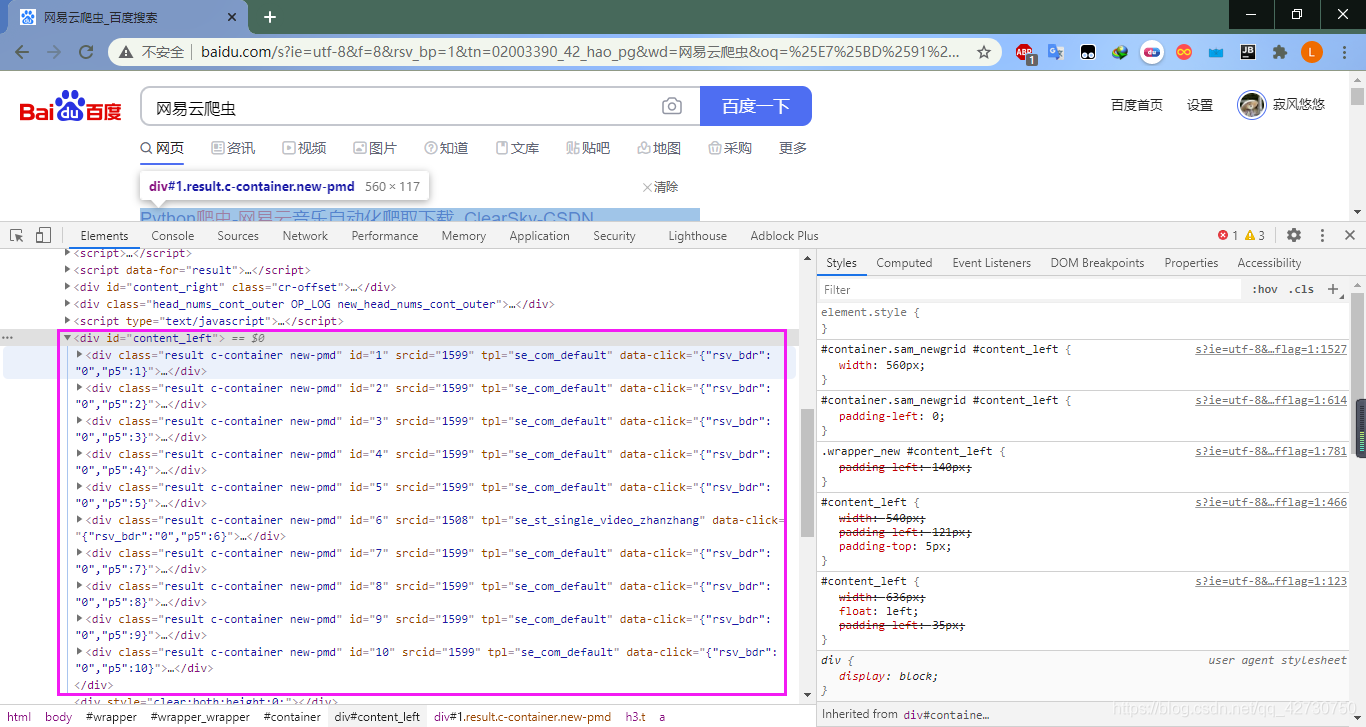
??一頁有十篇文章,它們的資訊都放在一個id="content_left"的div標簽里,每篇文章也對應一個div,它們的區別是id不同,id是文章的序號,這里我們打開第一個,即id=1的div標簽:

??我們點擊箭頭標記的連接就會跳轉到這篇文章,它的真實url為https://blog.csdn.net/weixin_39190897/article/details/108327884
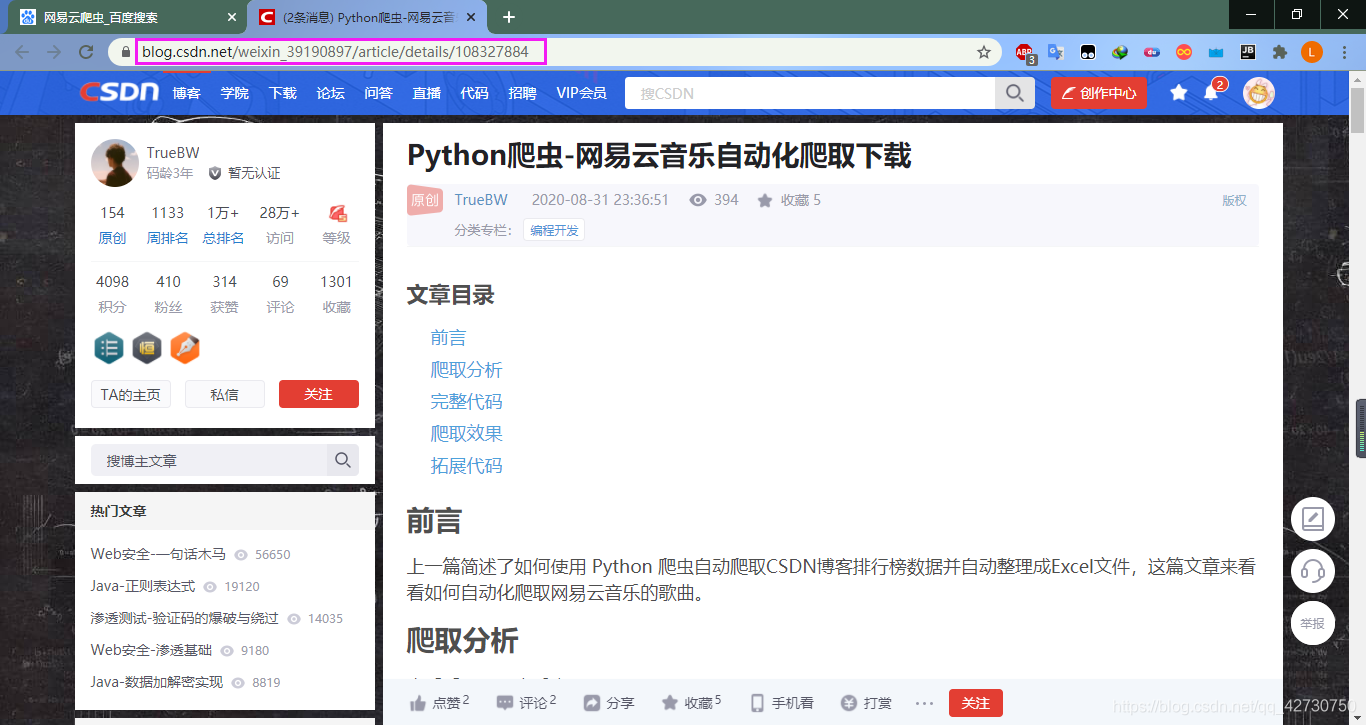
??這篇文章是CSDN網站上的,文章的內容在一個id="article_content"的div標簽里,但是我們的搜索是進行全網搜索,搜索結果里除了有CSDN里的文章外,還有博客園、知乎、簡書、嗶哩嗶哩、GitHub等其他網站的內容,如果我們這樣對內容進行精確提取的話,需要為每個網站進行標簽分析,這樣未免太繁瑣了,我的方法是通過正則運算式去除網頁源代碼,然后對剩余的內容進行保存,其實只要正則運算式寫的好些,基本上就可以將文本提取出來了,
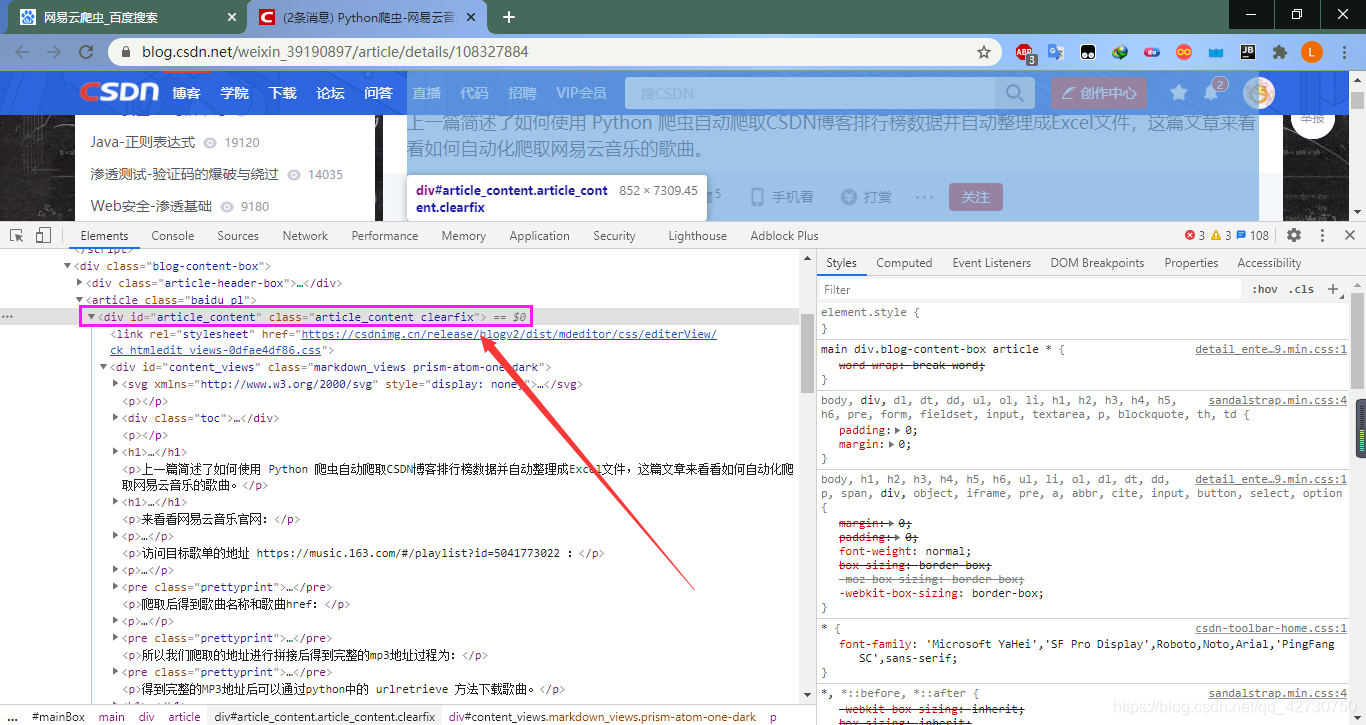
??大致流程就是上面說的,這里說一下具體如何實作:
??(1) 需要對搜索結果進行一次篩選,篩選的條件是一個月內,即先找到搜索工具的按鈕,然后左移一定的距離到時間選項,然后再向下移動一定距離選擇一個月內,這里使用selenium庫中的動作鏈來模擬此動作,代碼如下:
def check(self, browser):
"""
只檢索最近一個月的文章
:param browser:
:return:
"""
# 找到搜索工具按鈕
action1 = browser.find_element_by_css_selector('.search_tool')
actions = ActionChains(browser)
actions.click(action1)
# 左移
actions.move_by_offset(-495, 0).click()
# 下移
actions.move_by_offset(0, 110).click()
actions.perform()
time.sleep(2)
return browser
??(2) 需要實作翻頁的功能,即要找到下一頁按鈕所對應的id或class,因為上一頁和下一頁的按鈕所對應的class是相同的,所以還需要一個判斷,代碼如下:
next_page = browser.find_elements_by_css_selector('.n')[-1]
if next_page.text == '下一頁 >':
next_page.click()
??(3) 需要對網頁內容進行一次粗提取,使用正則運算式,然后將提取的結果進行保存,
??使用
selenium時要注意加一個延時,否則瀏覽器可能反應不過來,會導致下一步操作出現例外錯誤,
1.2 代碼實作
# -*- coding: utf-8 -*-
# @Time : 2020/9/15 15:20
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : CSDN.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
import re
import os
class BauDu(object):
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
self.input_kw = input('請輸入要搜索的關鍵字: ')
def search(self):
"""
搜索
:return:
"""
url = 'http://www.baidu.com'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(2)
# from selenium.webdriver.common.by import By
# input = browser.find_element(By.ID, 'kw')
# input = browser.find_elements_by_id('kw')
input = browser.find_element_by_css_selector('#kw')
input.send_keys(self.input_kw)
button = browser.find_element_by_css_selector('#su')
button.click()
time.sleep(3)
return browser
def check(self, browser):
"""
只檢索最近一個月的文章
:param browser:
:return:
"""
# 找到搜索工具按鈕
action1 = browser.find_element_by_css_selector('.search_tool')
actions = ActionChains(browser)
actions.click(action1)
# 左移
actions.move_by_offset(-495, 0).click()
# 下移
actions.move_by_offset(0, 110).click()
actions.perform()
time.sleep(2)
return browser
def parser(self, browser):
"""
決議出文章的url
:param browser:
:return:
"""
html = browser.page_source
soup = BeautifulSoup(html, 'lxml')
text_list = soup.find_all(class_='result c-container new-pmd')
urls = []
for text in text_list:
tag_a = text.h3.a
title = tag_a.get_text()
url = tag_a['href']
urls.append(url)
# print(title, url)
return urls
def getAllurl(self, browser):
"""
提取所有結果的url
:param browser:
:return:
"""
url_list = []
count = 1
while True:
print('{:*^30}'.format('正在抓取第%d頁' % count))
url = baidu.parser(browser)
url_list.extend(url)
try:
# 下一頁
next_page = browser.find_elements_by_css_selector('.n')[-1]
if next_page.text == '下一頁 >':
next_page.click()
time.sleep(3)
count += 1
else:
break
except Exception as err:
print(err)
break
browser.close()
return url_list
def getText(self, url):
"""
提取文章
:param url:
:return:
"""
try:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
response.encoding = 'utf-8'
return response.url, response.text
except Exception as err:
# print(err)
# print('請求例外')
return '', ''
def saveArticle(self, url_list):
"""
保存文章
:param url_list:
:return:
"""
for index in range(len(url_list)):
# 開始整處理網頁
blog_url, blog_text = baidu.getText(url_list[index])
if blog_text == '找不到頁面' or blog_text == '':
# 內容為空, 該url請求失敗, 內容有可能是被刪了404
continue
# 正則提取
pattern = re.compile('[a-zA-Z0-9</>":.;!!=_#&@\\\?\[\]()(),:+,\'%《》$、,\s\|\{\}\*\-?【】“”‘’~\^]')
blog_text = re.sub(pattern, '', blog_text)
if not os.path.exists('./articleBaidu'):
os.mkdir('./articleBaidu')
with open('./articleBaidu/{}.txt'.format(str(index).zfill(5)), 'w', encoding='gb18030') as f:
f.write(blog_url + '\n' + blog_text)
if (index + 1) % 10 == 0:
print('已保存: %d頁' % (index + 1))
1.3 代碼測驗
??測驗代碼如下:
if __name__ == '__main__':
baidu = BauDu()
browser = baidu.search()
browser = baidu.check(browser)
url_list = baidu.getAllurl(browser)
baidu.saveArticle(url_list)
??運行結果如下,首先是模擬瀏覽器進行點擊跳轉操作:
??然后提取網頁中各個文章的url:
??然后將文章處理后進行保存:

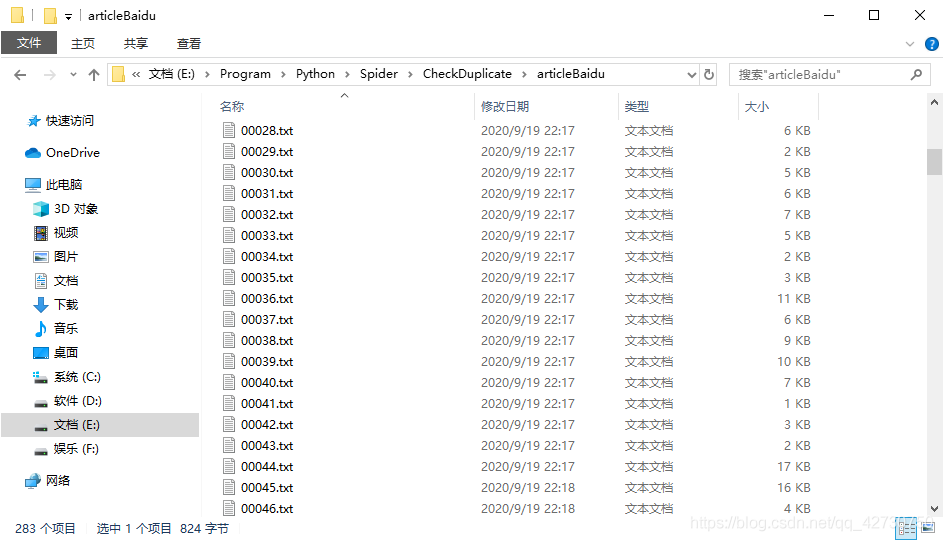

??可以看到,CSDN、簡書、搜狐,還有GitHub等各網站的文章都保存到了本地,每個檔案對應一篇文章,每個文章分為兩個部分:文章的url和文章內容,當然也就極個別網站因為編碼等各種問題,提取到的內容都是亂碼,這個問題可以不用管它,畢竟是很少一部分,
2. 爬取微信公眾號文章
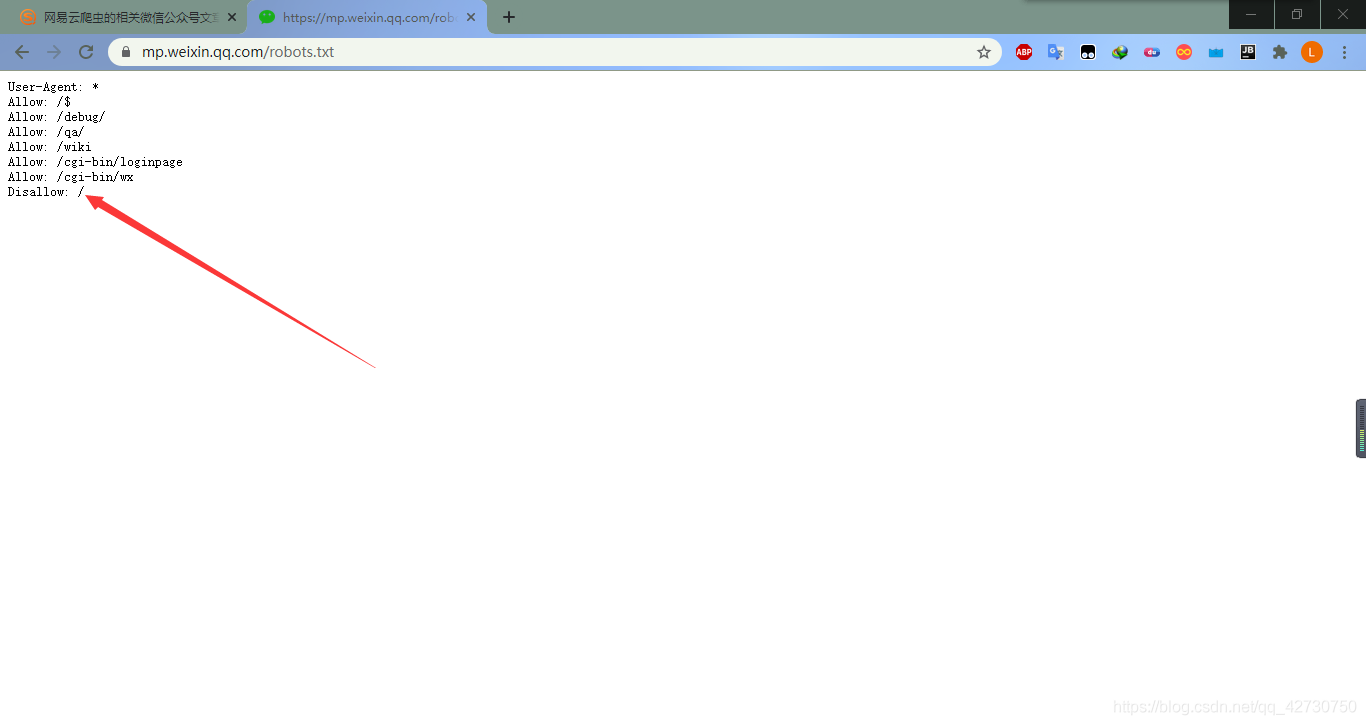
??因為微信公眾號的文章禁止了百度爬蟲,所以百度搜索引擎沒有權限收錄微信公眾號里的文章,我們可以輸入https://mp.weixin.qq.com/robots.txt查看到微信公眾號的Robots協議:
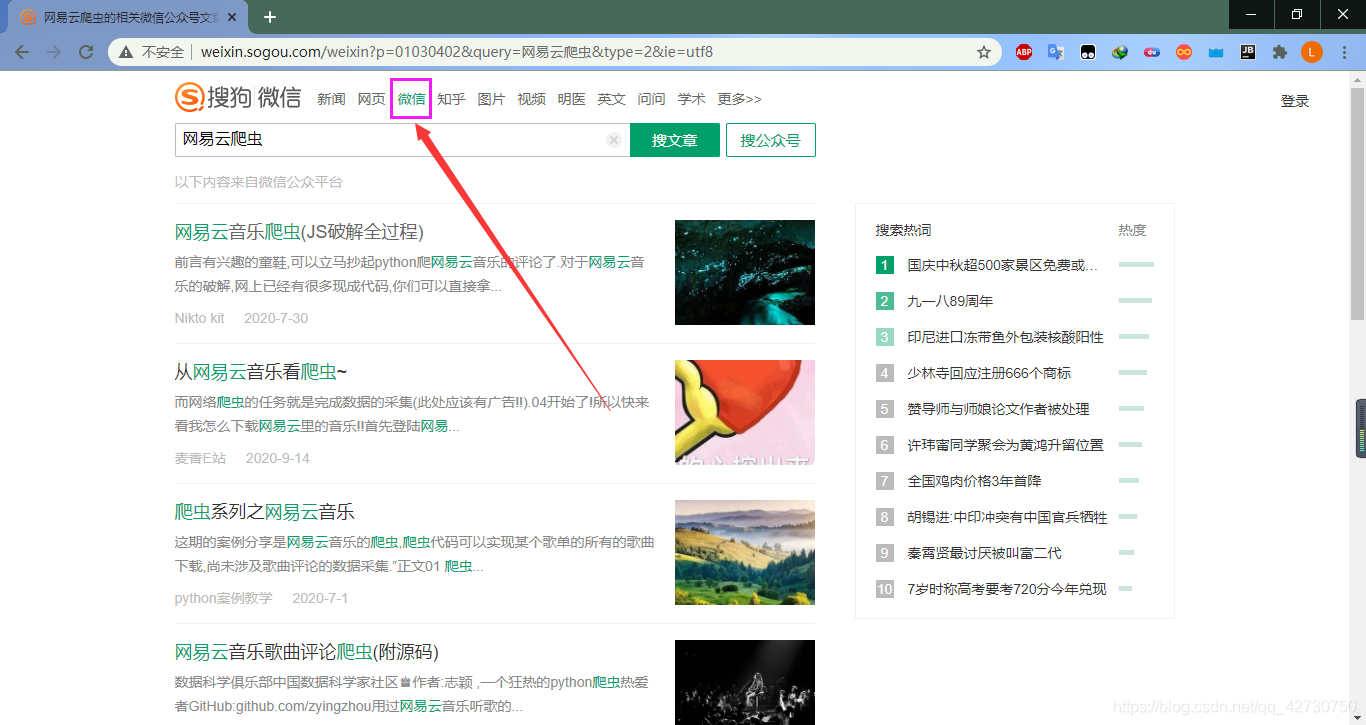
??或許你已經發現了,百度沒有收錄,但是搜狗收錄了,我們可以通過搜狗的搜索引擎來搜索微信公眾號的文章,這里依舊用關鍵詞網易云爬蟲進行搜索:
2.1 網頁分析
??分析流程是可百度一樣的,我們還是打開Chrome的除錯面板,看一下文章的資訊:
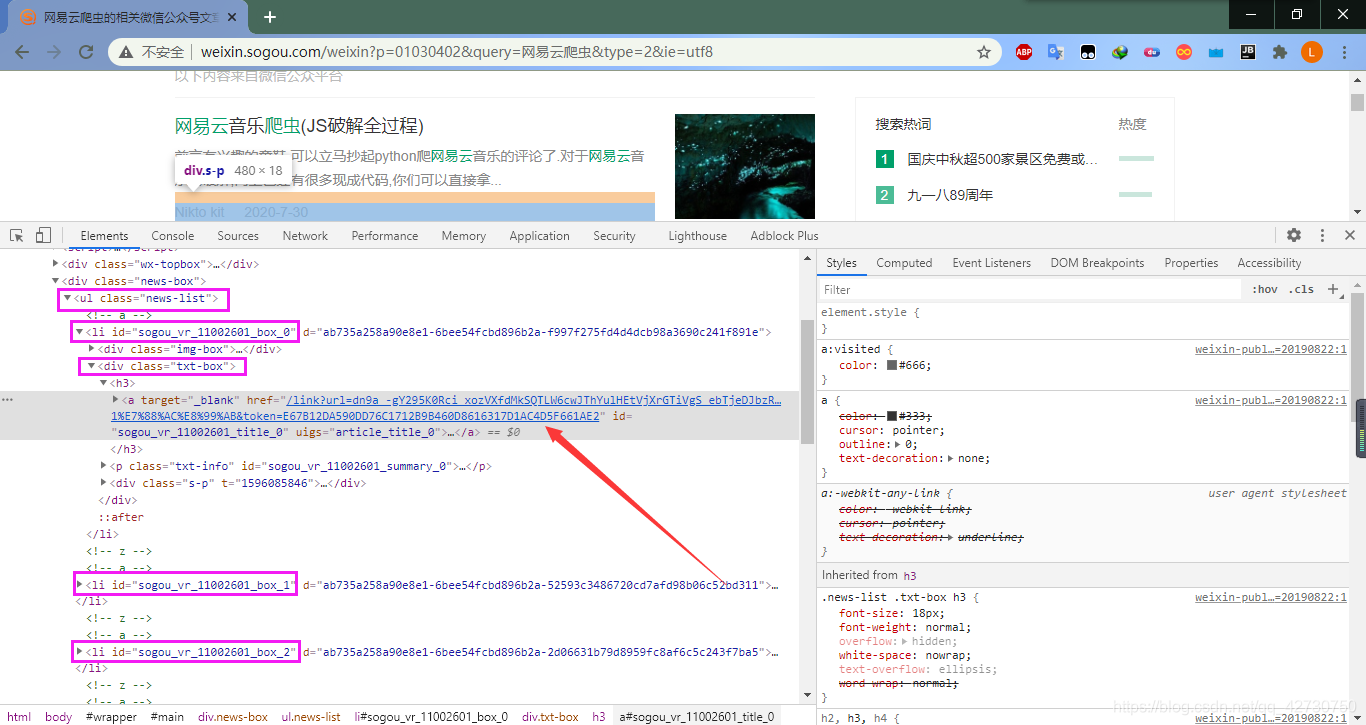
??可以看到,每個網頁也是十篇文章,都放在了一個class="news-list"的ul標簽里,每個文章的url在一個class="txt-box"的div標簽里,點擊圖中箭頭所示的鏈接也會發生跳轉,轉到所在的公眾號:

??然后提取方法就和百度的一樣,直接用正則提取即可,
??相比百度文章的提取來說,這里不需要使用動作鏈模擬時間選擇,只需要找到下一頁的按鈕,然后提取相關資訊并保存即可,這樣看來微信公眾號的提取比百度還簡單,其實并不是,這些都是假象,
2.2 反爬分析
??這里來到第一步,我們找到了文章在搜狗的搜索引擎中url,這里以第一篇為例,它在搜狗的搜索引擎中url為http://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgS_ebTjeDJbzRobk7sV0-esChYTg9WI5RvlqXa8Fplpd9p9wyDv1i5nLnl71X1UfI_CJKUC0n9tWj6xepdWbSVrenOGPPw_VvyqlJvHqDryH-3JVoytoHLXnTdEvnQ15mFVP42dxeIClXiHTBUrOZ2RdaiHLZUWi_E5Yn3k7xqldQhRrZENR-zjShq5GeNOivVW7i63t4nGTYnF0v03wc3RlhWLv6O878UA..&type=2&query=%E7%BD%91%E6%98%93%E4%BA%91%E7%88%AC%E8%99%AB&token=E6921574590DD76C1712B9B460D8616317D1AC4D5F661F52,其中%后面是什么意思應該已經知道了吧,它的意思在上一篇文章里已經介紹了,這里的%E7%BD%91%E6%98%93%E4%BA%91%E7%88%AC%E8%99%AB意思就是我們輸入的關鍵詞網易云爬蟲,
??我通過代碼去訪問該鏈接,理論上應該跳轉到該文章的公眾號上,然而卻出現了錯誤,根據PyCharm控制臺輸出的資訊,我看到了一個鏈接:https://weixin.sogou.com/antispider/,很明顯,被網站的反爬蟲機制給禁止了,打開這個鏈接看一下:
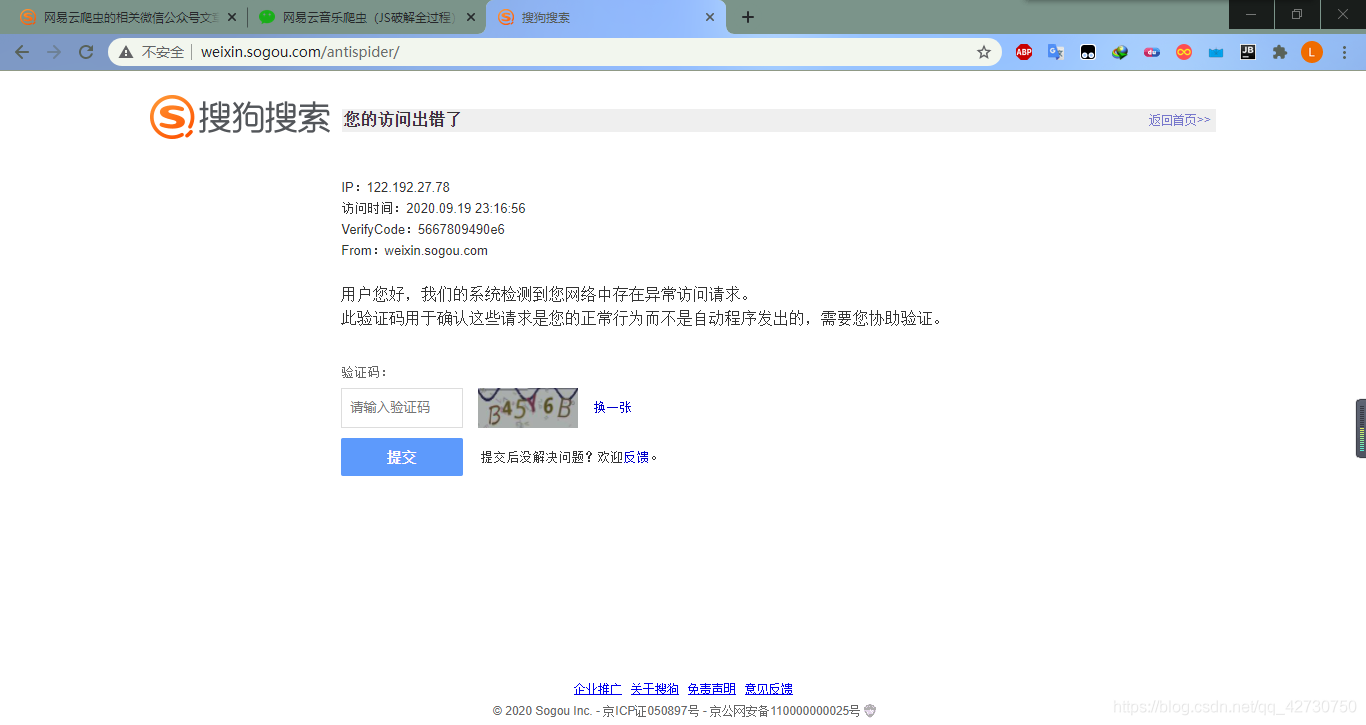
??這里有兩種方法來解決,第一個就是嘗試進一步偽裝來欺騙網站的反爬蟲機制,第二個就是驗證碼識別,這里我嘗試了去識別驗證碼,使用的是Tesseract-OCR以及它的Python API pytesseract,但是效果并不好,它的這個驗證碼不僅有很多小的字母,而且圖片上加了一條類似余弦波的曲線來干擾識別,剛開始我也想嘗試針對這個驗證碼來訓練一個神經網路模型,但是隨之而來的就是資料集問題,而且還得自己標注,太麻煩了,所以還是采用第一種方法,偽裝自己,
??因為發生了跳轉,為了方便看一下這個跳轉的程序中發生了什么,所以這里我用Charles進行了抓包:
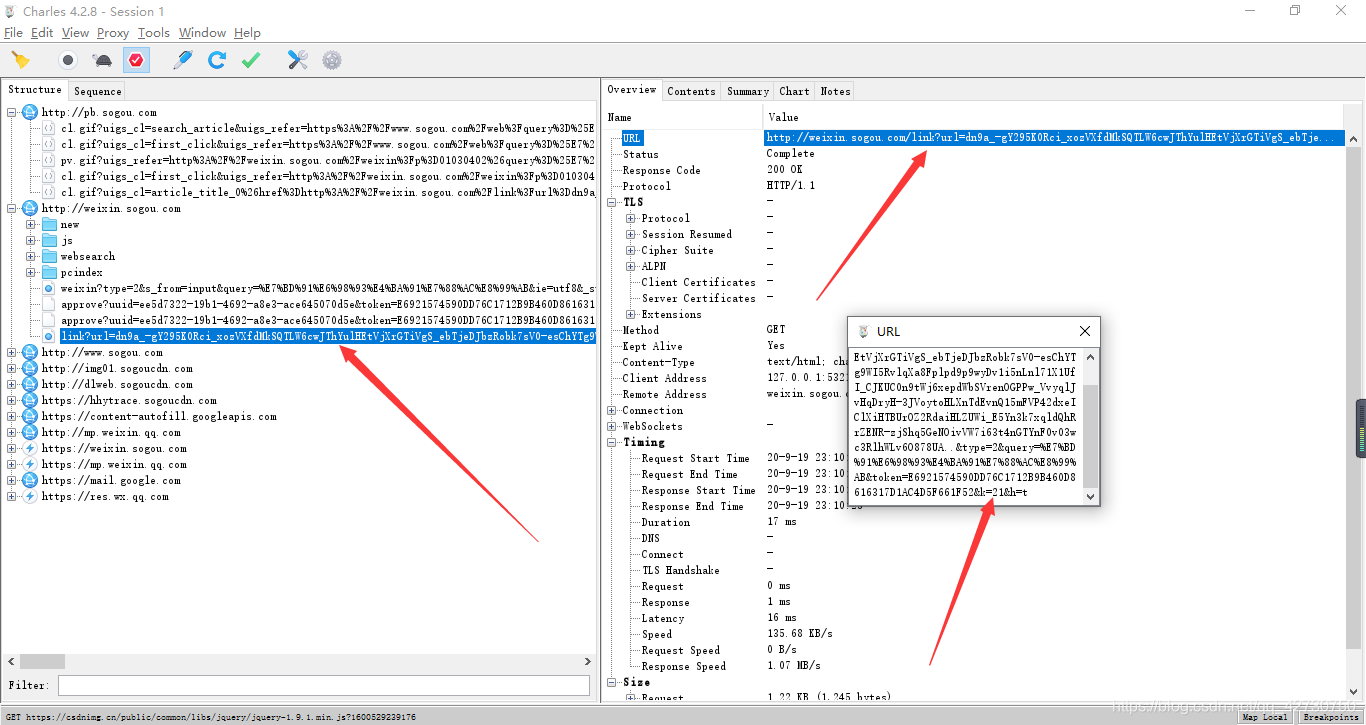
??這里的第一個不同就是這個發生跳轉的url發生了稍微的變化,相比原來的,這里多了兩個引數:&k=21&h=t,經過幾次重繪發現,并沒有什么影響,即這兩個引數不是必須的,

??我們手動點擊的那個鏈接會跳轉到這里,就是上圖框框里面的,它會執行這個這段JavaScript代碼,然后將url進行重定向,框框中的url就是微信公眾號里的文章鏈接,所以干脆直接在這里面提取微信公眾號里文章的url,代碼如下:
reault = response.text.split(';')
real_url = ''
for i in reault[2:-3]:
j = i.strip()
real_url += j[8:-1]
return real_url
??這段代碼的意思就是先將文本以;進行分割,然后去除冗余字符后再進行拼接,拼接出來的url就是我們要找的微信公眾號里文章的url,最后將結果回傳,
??需要注意的是,這個
url后面的字符也是隨機的,每次重繪都不一樣,但是無妨,因為我們直接提取的是變化后的結果,
??經過多次失敗地嘗試,Request請求所需要的User-Agent、Referer、Cookie和Host要和上面抓包抓取的內容一樣,否則就會觸發反爬蟲機制,這里的反爬蟲機制對這些引數還是很敏感的,
Host: weixin.sogou.com
User-Agent: netdisk;2.2.2;pc;pc-mac;10.14.5;macbaiduyunguanjia
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://weixin.sogou.com/weixin?type=2&s_from=input&query=%E7%BD%91%E6%98%93%E4%BA%91%E7%88%AC%E8%99%AB&ie=utf8&_sug_=n&_sug_type_=
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: SUID=4E1BC07A2C18960A000000005F562407; SUV=1599480842999554; pgv_pvi=4547401728; ABTEST=0|1600214894|v1; weixinIndexVisited=1; IPLOC=CN3203; SNUID=590DD76C1712B9B460D8616317D1AC4D; ld=Dkllllllll2KqAy4lllllVduVhDlllllW7lbFkllllylllll9Zlll5@@@@@@@@@@; LSTMV=182%2C70; LCLKINT=1731; JSESSIONID=aaaTMPxeCI4CUf2aC0Zox
Connection:keep-alive
??再說一下這幾個引數都是干什么的:
????Host用于指定請求資源的主機
????User-Agent瀏覽器的UA標識,服務器根據此內容可以識別到用戶使用的瀏覽器資訊及作業系統地資訊
????Referer標識請求是從哪個頁面發過來的
????Cookie網站為了辨別用戶進行會話跟蹤而存盤在本地的資料

??同理,也要對抓取文章的Request請求引數進行相應的改變:
Host: mp.weixin.qq.com
Referer: 這個就是搜狗搜索引擎中文章的url
Cookie: pgv_pvi=3376051200; RK=zRKkVVUClt; ptcz=bea38e8122d337415e409f1122e019246b9cd2d50352aba7155d95384bfc9cc0; tvfe_boss_uuid=57ca5a85851f958c; pgv_pvid=3704594732; euin=owozNK-zNKosNn**; psrf_access_token_expiresAt=1607758183; tmeLoginType=2; psrf_qqrefresh_token=A8028B993A1A7526C49F5F7CEA2F8D8F; psrf_qqunionid=; psrf_qqaccess_token=48A2231BD3DAFAB5395160B26CCA59C1; psrf_qqopenid=975A7CB39D73DB46B588429325C16AE5; o_cookie=2309209368; pgv_info=ssid=s4047750795; rewardsn=; wxtokenkey=777
??這里還要注意一下,用requests.get()發起請求時最好關閉一下證書認證,即verify=False,否則會引發錯誤或者得不到資訊,對我們輸入的關鍵詞也要重新做一下編碼,處理后的結果為以%開頭后面是兩個十六進制的字符,否則會出現編碼錯誤:UnicodeEncodeError: 'latin-1' codec can't encode characters in position,
2.3 代碼實作
# -*- coding: utf-8 -*-
# @Time : 2020/9/16 8:13
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : WeChat.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
import time
import re
import os
class SouGou(object):
def __init__(self):
# 對輸入的內容做一下編碼, 否則也會出錯
self.input_kw = input('請輸入要搜索的關鍵字: ')
self.headers = {'User-Agent': 'netdisk;2.2.2;pc;pc-mac;10.14.5;macbaiduyunguanjia',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,'
'image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': 'SUID=4E1BC07A2C18960A000000005F562407; SUV=1599480842999554; '
'pgv_pvi=4547401728; ABTEST=0|1600214894|v1; weixinIndexVisited=1; '
'IPLOC=CN3203; ld=olllllllll2KqAy4lllllVd6hNGlllllW7lbFkllllGlllll'
'9klll5@@@@@@@@@@; LCLKINT=1528; LSTMV=180%2C76; SNUID=590DD76C1712B'
'9B460D8616317D1AC4D; JSESSIONID=aaagW2SHM9h2C4PRboZox',
'Connection': 'keep-alive',
'Referer': 'http://weixin.sogou.com/weixin?type=2&s_from=input&query={}&ie=utf8'
'&_sug_=n&_sug_type_='.format(str(self.input_kw.encode())[1:].replace('\\x', '%')),
'Host': 'weixin.sogou.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'}
self.headers_ = {'User-Agent': 'netdisk;2.2.2;pc;pc-mac;10.14.5;macbaiduyunguanjia',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,'
'image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': 'pgv_pvi=3376051200; RK=zRKkVVUClt; ptcz=bea38e8122d337415e409f1122e0192'
'46b9cd2d50352aba7155d95384bfc9cc0; tvfe_boss_uuid=57ca5a85851f958c; pgv_'
'pvid=3704594732; euin=owozNK-zNKosNn**; psrf_access_token_expiresAt=16077'
'58183; tmeLoginType=2; psrf_qqrefresh_token=A8028B993A1A7526C49F5F7CEA2F8'
'D8F; psrf_qqunionid=; psrf_qqaccess_token=48A2231BD3DAFAB5395160B26CCA59C1;'
' psrf_qqopenid=975A7CB39D73DB46B588429325C16AE5; o_cookie=2309209368; rewar'
'dsn=; wxtokenkey=777',
'Connection': 'keep-alive',
'Referer': '',
'Host': 'mp.weixin.qq.com',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'}
def search(self):
"""
搜索
:return:
"""
url = 'http://weixin.sogou.com'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(2)
input = browser.find_element_by_css_selector('#query')
input.send_keys(self.input_kw)
button = browser.find_element_by_css_selector('.swz')
button.click()
time.sleep(3)
return browser
def parser(self, browser):
"""
決議出文章的url
:param browser:
:return:
"""
html = browser.page_source
soup = BeautifulSoup(html, 'lxml')
text_list = soup.find_all(class_='txt-box')
urls = []
for text in text_list:
tag_a = text.h3.a
title = tag_a.get_text()
url = 'http://weixin.sogou.com' + tag_a['href']
urls.append(url)
# print(title, url)
return urls
def getAllurl(self, browser):
"""
提取所有結果的url
:param browser:
:return:
"""
url_list = []
count = 1
while True:
print('{:*^30}'.format('正在抓取第%d頁' % count))
url = sougou.parser(browser)
url_list.extend(url)
try:
# 下一頁
next_page = browser.find_elements_by_css_selector('.np')[-1]
if next_page.text == '下一頁':
next_page.click()
time.sleep(3)
count += 1
else:
break
except Exception as err:
print(err)
break
browser.close()
return url_list
def getRealURL(self, url):
"""
提取真正的url
:param url:
:return:
"""
try:
# 忽略證書認證
response = requests.get(url, headers=self.headers, verify=False)
response.raise_for_status()
response.encoding = 'utf-8'
reault = response.text.split(';')
real_url = ''
for i in reault[2:-3]:
j = i.strip()
real_url += j[8:-1]
return real_url
except Exception as err:
print(err)
print('請求例外')
return ''
def getText(self, url):
"""
提取文章
:param url:
:return:
"""
real_url = self.getRealURL(url)
try:
self.headers_['Referer'] = url
response = requests.get(real_url, headers=self.headers_, verify=False)
response.raise_for_status()
response.encoding = 'utf-8'
return response.url, response.text
except Exception as err:
# print(err)
# print('請求例外')
return '', ''
def saveArticle(self, url_list):
"""
保存文章
:param url_list:
:return:
"""
for index in range(len(url_list)):
# 開始整處理網頁
blog_url, blog_text = sougou.getText(url_list[index])
# 微信公眾號的主題內容在一個id為js_content的div標簽內
# 所以這里再進行一下冗余處理
soup = BeautifulSoup(blog_text, 'lxml')
text_tag = soup.find(id='js_content')
if text_tag is None:
# 內容為空, 應該是內容被刪了
continue
blog_text = text_tag.text
pattern = re.compile('[a-zA-Z0-9</>":.;!!=_#&@\\\?\[\]()(),:+,\'%《》$、,\s\|\{\}\*\-?【】“”‘’~\^]')
blog_text = re.sub(pattern, '', blog_text)
if not os.path.exists('./articleWechat'):
os.mkdir('./articleWechat')
with open('./articleWechat/{}.txt'.format(str(index).zfill(5)), 'w', encoding='gb18030') as f:
f.write(blog_url + '\n' + blog_text)
if (index + 1) % 10 == 0:
print('已保存: %d頁' % (index + 1))
2.4 代碼測驗
??測驗代碼如下:
if __name__ == '__main__':
sougou = SouGou()
browser = sougou.search()
url_list = sougou.getAllurl(browser)
sougou.saveArticle(url_list)
??運行結果如下,警告資訊不需要管它,哈哈哈哈:
3. 模型訓練
??我是用doc2vec來將文本向量化,它是在word2vec的基礎上進行拓展的,由于考慮了文本的背景關系資訊,所以效果會比單純地word2vec更好,這里使用的是doc2vec中的DM模型,語料庫用的是維基百科上的(2020年7月),訓練代碼如下:
# -*- coding: utf-8 -*-
# @Time : 2020/9/17 13:03
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : WiKi.py
# @Software: PyCharm
from gensim.models import doc2vec
import logging
# 列印日志的時間 列印日志級別名稱 列印日志資訊
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s', level=logging.INFO)
if __name__ == '__main__':
wikidata = 'E:/Program/Python/NLP/AutomanticSummarization/data/wiki_202007_s.txt'
# 遍歷包含檔案的檔案: 一行 = TaggedDocument物件
# 單詞應該已經過預處理, 并用空格分隔
# 檔案標簽是根據檔案行號自動構建的(每個檔案都有一個唯一的整數標簽)
document = doc2vec.TaggedLineDocument(source=wikidata)
# dm=1, 使用分布式記憶模型(PV-DM), 否則, 將使用分布式詞袋模型(PV-DBOW)
# dbow_words=0, 只訓練doc2vec
# vector_size: 特征向量的維數
# window: 視窗大小, 即句子中當前單詞和預測單詞之間的最大距離
# min_count: 忽略總頻率低于此頻率的所有單詞
# epochs: 語料庫中的迭代次數
# workers: 使用多執行緒來訓練模型
model = doc2vec.Doc2Vec(documents=document, dm=1, dbow_words=0, vector_size=128, window=10, min_count=5, epochs=10, seed=128, workers=8)
model.save('./model/doc2vec_size128_202007.model')
??有關gensim的詳細操作,請參考官方檔案,
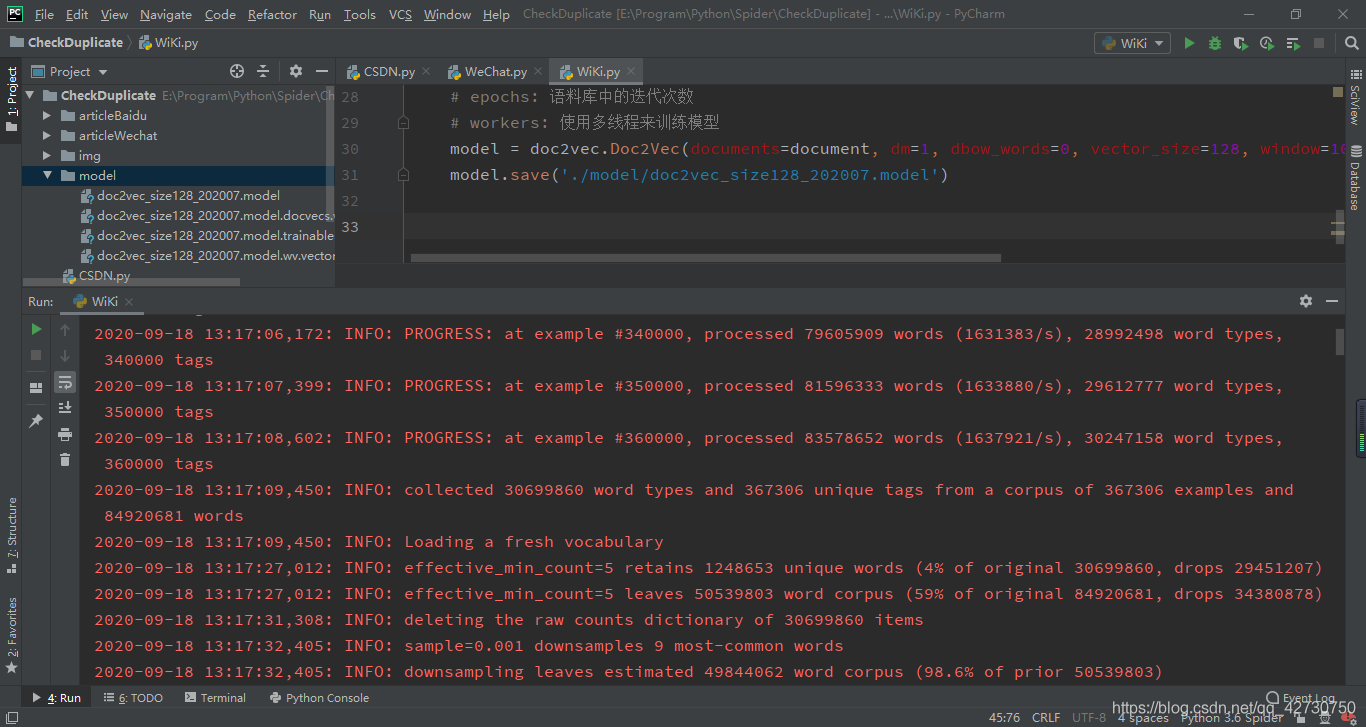
??我這里設定的向量維度為128,訓練了10次,大概用了四十多分鐘,如果想進一步提高準確率,可以將這兩個值再改大一些,模型的訓練資訊如下:
4. 相似度分析
??我是用余弦相似度來做文本的相似度分析,余弦相似度計算的是兩個向量間的夾角的余弦值,夾角越小,其余弦值就越大,說明這兩個向量越相關,計算公式如下:
s
i
m
i
l
a
r
i
t
y
=
cos
?
θ
=
A
?
B
?
∣
∣
A
?
∣
∣
∣
∣
B
?
∣
∣
=
∑
i
=
1
n
A
?
i
B
?
i
∑
i
=
1
n
A
?
i
∑
i
=
1
n
B
?
i
similarity=\cos \theta=\frac {\vec A \vec B} {\big|\big|\vec A\big|\big| \big|\big|\vec B\big|\big|}=\frac {\sum_{i=1}^n\vec A_i \vec B_i} {\sqrt {\sum_{i=1}^n\vec A_i}\sqrt {\sum_{i=1}^n\vec B_i}}
similarity=cosθ=∣∣?∣∣?A
∣∣?∣∣?∣∣?∣∣?B
∣∣?∣∣?A
B
?=∑i=1n?A
i?
?∑i=1n?B
i?
?∑i=1n?A
i?B
i????如果是向量是二維的,這個公式就是我們常說的向量的夾角公式:
cos
?
θ
=
x
1
x
2
+
y
1
y
2
x
1
2
+
y
1
2
x
2
2
+
y
2
2
\cos \theta=\frac {x_1x_2+y_1y_2} {\sqrt {x_1^2+y_1^2}\sqrt {x_2^2+y_2^2}}
cosθ=x12?+y12?
?x22?+y22?
?x1?x2?+y1?y2????代碼實作就是:
def cosine(self, vec1, vec2):
# 兩個分母
vec1mod = np.sqrt(vec1.dot(vec1))
vec2mod = np.sqrt(vec2.dot(vec2))
if vec1mod != 0 and vec2mod != 0:
sim = vec1.dot(vec2) / (vec1mod * vec2mod)
else:
sim = 0
return "{:.4}".format(sim)
??當然,也可以使用sklearn庫中的cosine_similarity函式來計算:
from sklearn.metrics.pairwise import cosine_similarity
??這里又對文本進行了處理,使用了jieba來進行分詞,方便進行向量化,還用到了以前整理的一個停用詞檔案,當然也可以使用其他的,其目的就是將一些非必要字符在進行去除,
??代碼實作如下:
# -*- coding: utf-8 -*-
# @Time : 2020/9/19 19:26
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : Check.py
# @Software: PyCharm
from gensim.models import doc2vec
import logging
import jieba
import os
import numpy as np
import requests
import re
# 列印日志的時間 列印日志級別名稱 列印日志資訊
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s', level=logging.INFO)
class Check(object):
def __init__(self):
self.sw_list = self.get_stopword(stopword_file='./stopword/stopword.txt')
self.model = doc2vec.Doc2Vec.load('./model/doc2vec_size128_202007.model')
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def get_stopword(self, stopword_file):
"""
加載停用詞
:param stopword_file:
:return:
"""
stopword_list = []
with open(stopword_file, 'r', encoding='gb18030', errors='ignore') as f:
line_list = f.readlines()
for line in line_list:
stopword_list.append(line.replace('\n', ''))
return stopword_list
def article2vec(self, article_file):
"""
文本向量化
:param article_file:
:return:
"""
article = []
with open(article_file, 'r', encoding='gb18030') as f:
line_list = f.readlines()
article_url = line_list[0]
for line in line_list[1:]:
short_sentence = line.strip('\r\n')
word_list = list(jieba.cut(short_sentence))
for word in word_list:
if len(word) > 1 and word not in self.sw_list:
article.append(word)
article_vec = self.model.infer_vector(doc_words=article, alpha=0.01, epochs=1000)
return article_url, article_vec
def cosine(self, vec1, vec2):
"""
余弦相似度
:param vec1:
:param vec2:
:return:
"""
# 兩個分母
vec1mod = np.sqrt(vec1.dot(vec1))
vec2mod = np.sqrt(vec2.dot(vec2))
if vec1mod != 0 and vec2mod != 0:
sim = vec1.dot(vec2) / (vec1mod * vec2mod)
else:
sim = 0
return "{:.4}".format(abs(sim))
def simlarity(self, article_path, article_file, article_list):
"""
計算文章的相似度
:param article_path:
:param article_file:
:param article_list:
:return:
"""
_, real_vec = self.article2vec(article_file=article_file)
count = 0
result = []
for article in article_list:
article = article_path + article
article_url, article_vec = self.article2vec(article)
sim = self.cosine(real_vec, article_vec)
result.append([article_url, sim])
count += 1
if count % 25 == 0:
print('[{0}]Processed {1} articles'.format(article_path[9:-1], count))
print('[{}]Processed over!'.format(article_path[9:-1]))
return result
def saveResult(self, result_list):
"""
將分析結果保存
:param result_list:
:return:
"""
result_list = sorted(result_list, key=lambda list1: float(list1[1]), reverse=True)
with open('./result.txt', 'w', encoding='utf-8') as f:
count = 0
for result in result_list:
line = result[1] + '\t' + result[0] + '\n'
f.write(line)
count += 1
if count % 50 == 0:
print('Writed %d articles' % count)
print('Writed over!')
def getText(self, url, my_article_file):
"""
提取我的文章
:param url:
:param my_article_file:
:return:
"""
try:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
response.encoding = 'utf-8'
pattern = re.compile('[a-zA-Z0-9</>":.;!!=_#&@\\\?\[\]()(),:+,\'%《》$、,\s\|\{\}\*\-?【】“”‘’~\^]')
my_article = re.sub(pattern, '', response.text)
with open(my_article_file, 'w', encoding='gb18030') as f:
f.write(response.url + '\n' + my_article)
except Exception as err:
print(err)
print('請求例外')
??測驗代碼如下:
if __name__ == '__main__':
my_article_url = 'https://blog.csdn.net/qq_42730750/article/details/108415551'
my_article_file = './my_article.txt'
baidu_article = './articleBaidu/'
wechat_article = './articleWechat/'
check = Check()
check.getText(my_article_url, my_article_file)
print('Processing...')
baidu_result_list = check.simlarity(article_path=baidu_article, article_file=my_article_file,
article_list=os.listdir(baidu_article))
wechat_result_list = check.simlarity(article_path=wechat_article, article_file=my_article_file,
article_list=os.listdir(wechat_article))
print('Writting...')
check.saveResult(baidu_result_list + wechat_result_list)
??運行結果如下:
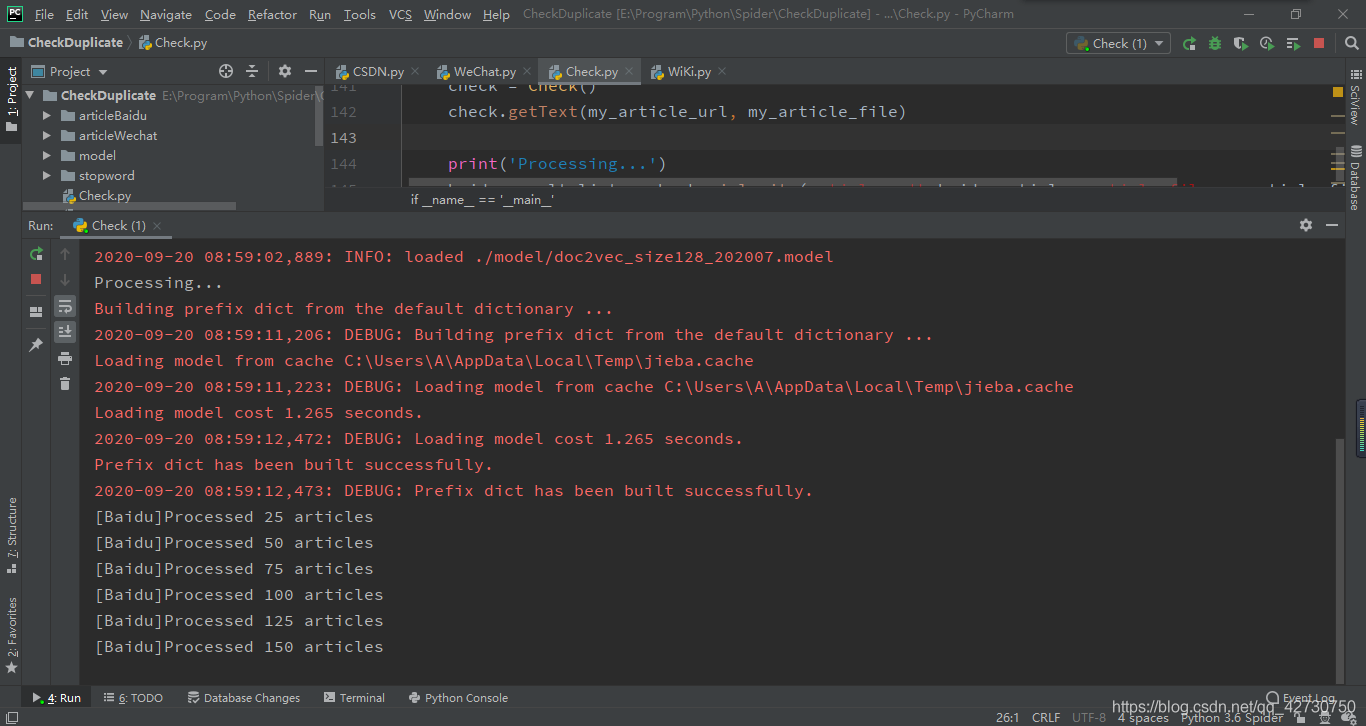
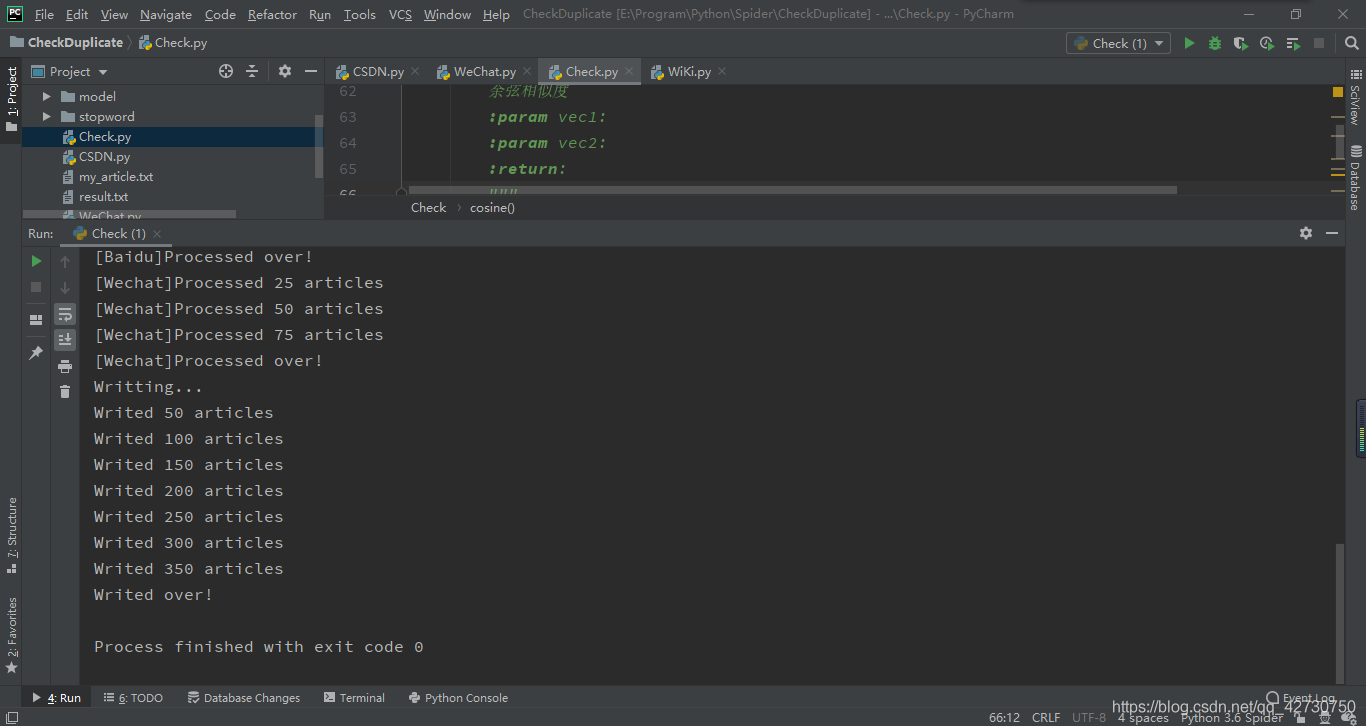
??我對結果按照相似度從高到低進行了一個排序,結果檔案中最上面的就是疑似侵權的,就比如第一個,相似度超過了98%,十分可疑,我們復制后面的鏈接到瀏覽器進一步核實:


??enmmm,是我自己的,哈哈哈哈(〃‘▽’〃),想必你會有個疑問,既然是同一篇文章,為什么相似度不是100%???這是因為演算法引入了隨機性,即隨機初始化和隨機采樣,而且訓練是多執行緒進行的,輸出的結果因為排序也會引起微小的差異,會導致各個向量的訓練位置漂移到任意不同的位置,詳細資訊請看官方給出的答復,
5. 剩下的就交給客服吧
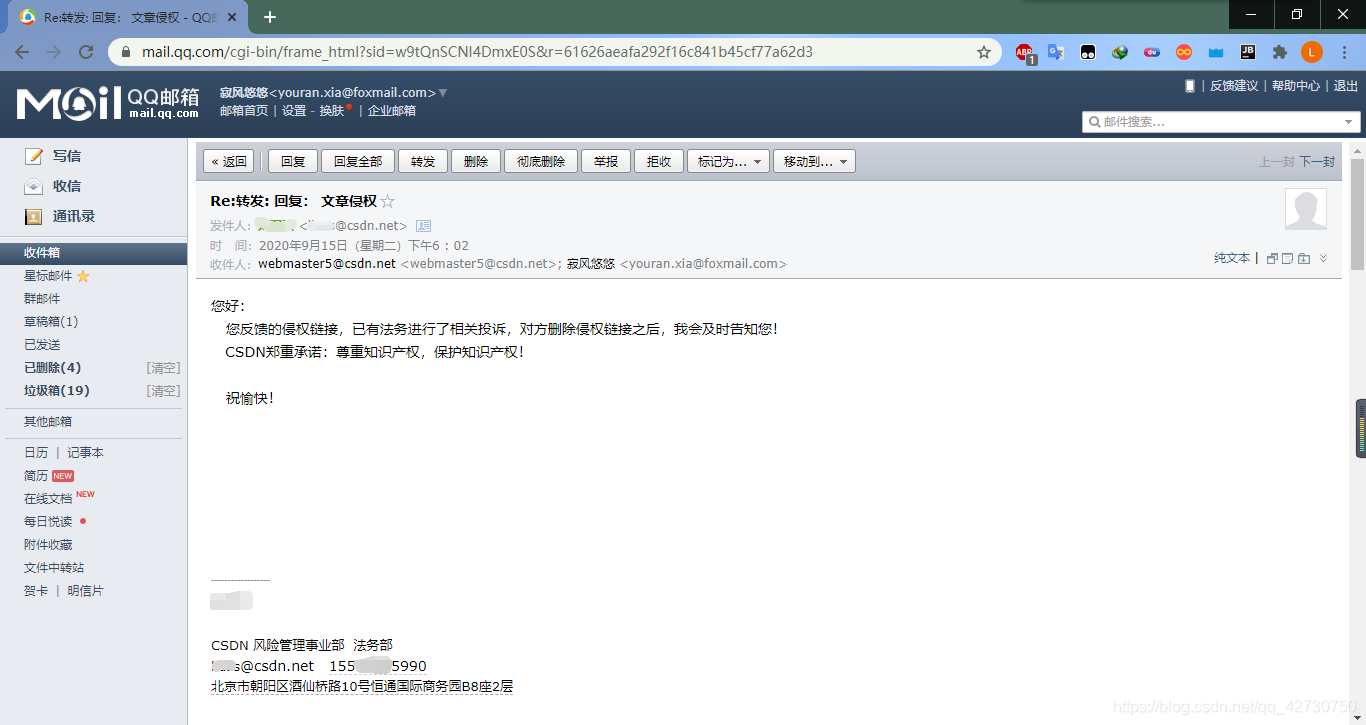
??如果發現了抄襲的文章,可以將咱們提取的侵權鏈接和自己文章的原鏈接一起發給CSDN的客服,具體操作流程可以參考這篇文章:

??剩下的法律交涉就交給后臺的法務部吧,哈哈哈哈o(′^`)o
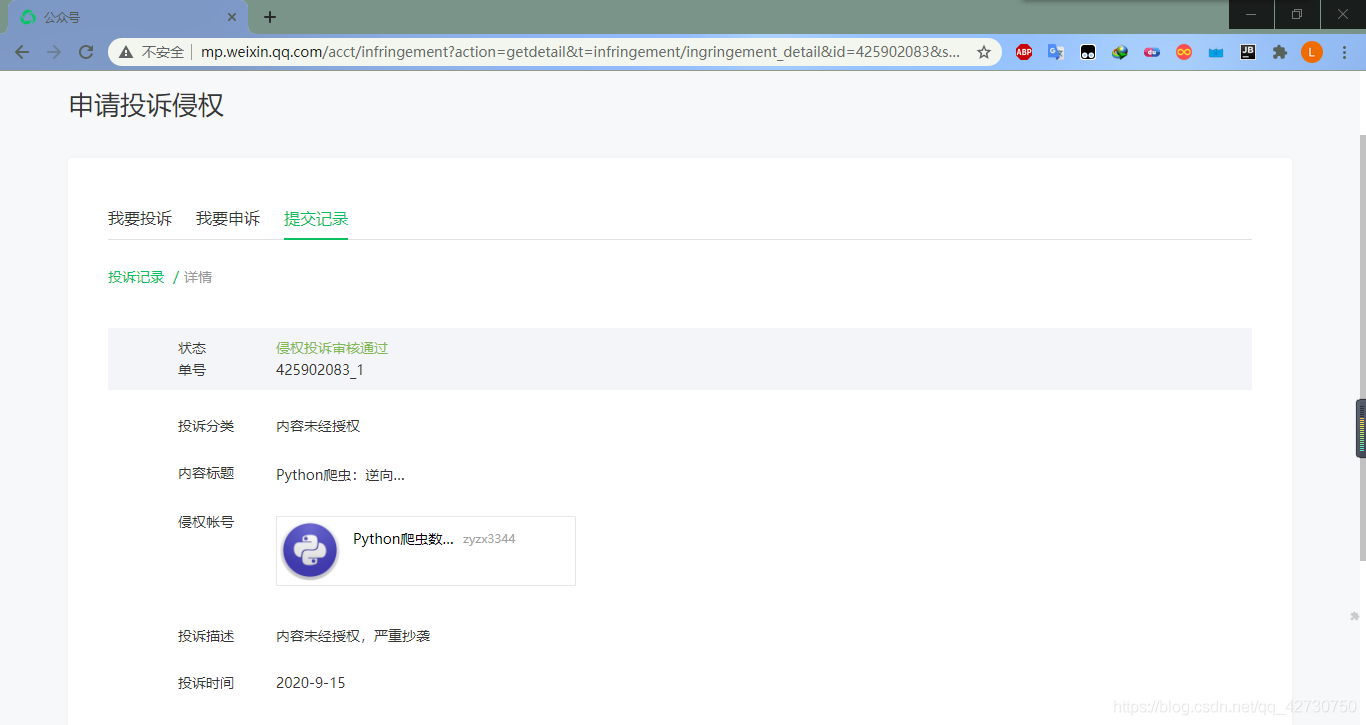
??當然了,除此之外你還可以自己申訴,像博客園、微信公眾號這些直接投訴即可,不過有些網站根本不搭理你,建議通過官方進行著作權申訴,
結束語
??整體的想法就是這些,需要優化的部分還有很多,在進行文本相似度分析那一模塊,由于文本很多,處理起來較慢,所以后期想加入多執行緒來提高并發性,有時間還可以再做一個GUI,加入郵件發送的功能,哈哈哈哈,侵權必究(??へ??╬),加油(? ??_??)?,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/99760.html
標籤:其他