在“百度架構師手把手帶你零基礎實踐深度學習”課程中,第一周課程的實踐作業中,要求寫一個cifar-10資料集的資料讀取器。這是這門課程第一個作業,也是我現在到課程結束,感覺最能0距離體驗paddle程式架構的一個作業。
何出此言呢?后面的作業,雖然程式越來越復雜,但以筆者機器學習0基礎上手的前提,在短短的三周學習時間內,其實只能大致把握其思路與流程,并沒有深入鉆研每個演算法的實作和設計思路的機會。
但這個資料讀取器大大滿足了我“鉆研演算法實作”的愿望,要是沒有群里助教的指點險些沒做出來。下面分享一下我的學習程序:
首先,作業要求寫一個讀寫器,實作讀入和亂序。
讀入一般有兩種思路,第一種是采用本地資料集,呼叫方法是:
for counter in range(本地資料個數),(其中counter代表回圈計數器,下同),
由于本地資料個數已知,不管是做亂序還是讀入,都可以采用這種最簡單可靠的全部遍歷方法。
另一種方法是在飛槳里看到的,構造一個讀取器,型別reader_creator(),函式回傳一個reader()函式。這個函式的特點有點類似于鏈表,只能順序讀取,不能直接全域定位到特定的第N個元素。
缺點是不能任意定位讀取
優點是可以節約空間,你可以用多少資料讀多少資料,不用一口氣全部讀完才開始后續作業。
cifa-10資料集在paddle網路上有配置,如果采用該種方法就可以不下載資料的情況下完成讀取任務。
reader()函式的基本用法是
for counter in enumerate(reader()),每執行一次for回圈相當于對reader()函式使用一次next(reader()),讓讀取器reader()去呼叫獲得一個新的值以后,再進行回圈內的操作。
但前提是reader()函式必須是一個帶有yield的函式,型別為generator(生成器)。
這樣的迭代回圈方式顛覆了我對“for”函式的理解,在使用yield結構后,函式居然可以用“for”進行迭代呼叫,而且可以用于enumerate()(列舉函式),即函式為“可數的”,“列舉變數”。
正當我驚訝于這個神奇的結構時,我對新想法的實驗程式報錯了:
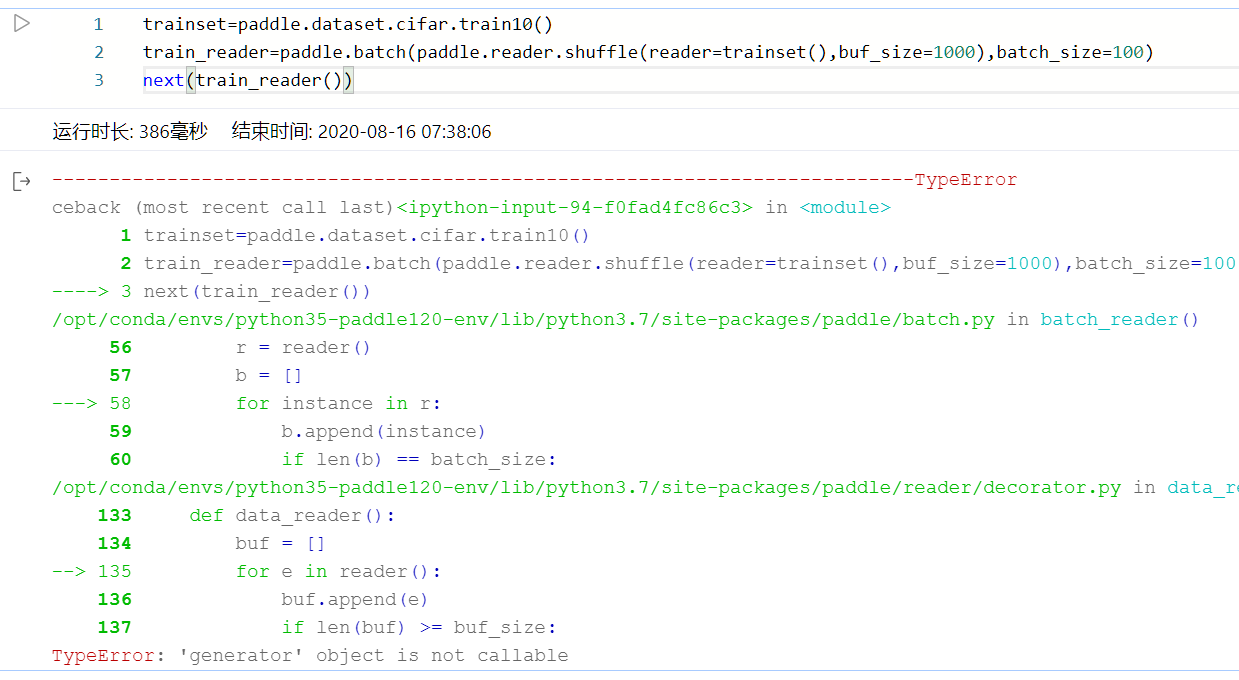
我的完美計劃是:
trainset是paddle提供的資料讀取器,型別是reader_creator()
任務是打包成patch、把資料亂序,生成新的讀取器。
那么很自然的想到先打亂,再分批次,是比較合理的設計。
1, paddle.reader.shuffle(reader=trainset(),buf_size=1000),shuffle是一個修飾reader_creator的函式,回傳一個讀取器reader(),作用是讀取buf_size數量資料元素后打亂。
2, train_creator=paddle.batch(paddle.reader.shuffle(),batch_size),把打亂以后的資料再分批次就好了
但這樣做是不行的。
以batch函式為例,讀取器修飾函式(源代碼:https://github.com/PaddlePaddle/Paddle/blob/release/1.8/python/paddle/reader/decorator.py#L102),之所以可以對reader_creator()進行處理后回傳reader()函式,是因為其源代碼定義如下:
def batch(reader, batch_size, drop_last=False):
def batch_reader():
……
return batch_reader
按照官網的api說明:“該介面是一個reader的裝飾器。回傳的reader將輸入reader的資料打包成指定的batch_size大小的批處理資料(batched data)。”
回傳:batched reader
回傳型別:generator
而batch函式呼叫的是reader_creator型別。paddle的api中并沒有明確給出reader_creator的定義.
但《【深度學習系列】關于PaddlePaddle的一些避“坑”技巧》一文中,給出了一段樣例程式:
def reader_creator(data,label):
def reader():
for i in xrange(len(data)):
yield data[i,:],int(label[i])
return reader
對比可知,batch函式,shuffle函式,也屬于reader_creator型別。其能夠處理并回傳一個reader()型別函式的理由就在于,它在函式定義時,嵌套定義了一個函式"def reader():"
因此我的代碼:
train_creator=paddle.batch( paddle.reader.shuffle() ,batch_size)
不能運行的原理就在于,shuffle輸出的函式是reader()型別,沒有進行嵌套定義成reader_creator型別,因此不能被batch函式呼叫。
當時作業采取的方案是繞過了這個問題,現在看看對這個答案并不十分滿意。將輸出的shuffle用reader_creator()格式包裝一下,就可以被batch進行呼叫,這樣才是當時本來設計的思路的滿意答案。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/10192.html