之前搭建好了k8s集群,現在在此基礎上部署ceph集群以用于專案資料的存盤備份,其實并不是說必須在k8s集群上才能部署ceph集群,在Centos上直接部署ceph集群也是可以的,因為我之后要將所有的應用容器化,所以k8s集群上的資料就直接放到了ceph集群中,
參考博客為 初試 Centos7 上 Ceph 存盤集群搭建
一、環境說明
centos的版本資訊:CentOS Linux release 7.6.1810 (Core)
主機資訊:
| 服務器名稱 | 服務器ip | k8s集群角色 |
|---|---|---|
| k8s-master | 111.30.30.30 | master,worker |
| k8s-node1 | 111.30.30.31 | worker |
| k8s-node2 | 111.30.30.32 | worker |
ceph集群中節點的分配安排:
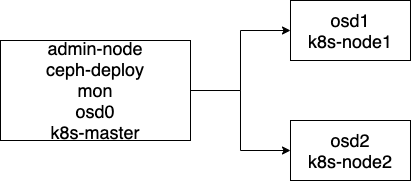
說明:原文章安裝的是jewel版本的ceph,其實這個版本是比較老的,并且這個版本的ceph缺少了很多的功能,比如沒有mgr服務,而該服務可以查看ceph集群的健康狀態,所以我比較推薦大家安裝Luminous或者mimic版本的ceph,但是,我接下來演示的仍然是jewel版本的ceph安裝(因為我最初是安裝的這個jewel版本的ceph),并且Luminous或者mimic版本的ceph集群的安裝程序與jewel版本的ceph安裝程序差別不大,在以下的安裝程序中我會具體說明,

二、安裝部署ceph集群前的準備作業
因為之后會涉及組態檔的同步以及ceph相關資源的部署安裝,所以配置節點間的免密登陸會方便之后的操作,
以下操作在所有服務器節點上執行:
1、關閉防火墻和selinux模式
//關閉防火墻
systemctl stop firewalld
systemctl disable firewalld
//查看防火墻狀態
systemctl status firewalld
//臨時關閉selinux
setenforce 0
//查看selinux狀態,SELinux status引數為enabled即為開啟狀態
/usr/sbin/sestatus -v
其中我們也可以通過sed -i 's/SELINUX=.*/SELINUX=disabled/' /etc/selinux/config命令來永久關閉selinux模式,注意關閉selinux需要reboot重啟服務器才能使之生效,慎用!!慎用!!因為有可能服務器上在跑著其他的服務,所以一般情況下不要重啟服務器,
2、配置各節點間的/etc/hosts檔案
比如在k8s-master節點上設定內容為:
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
111.30.30.30 k8s-master
111.30.30.31 k8s-node1
111.30.30.32 k8s-node2
其余的k8s-node1和k8s-node2按照此檔案中的內容設定即可,主要是配置ip與節點名稱之間的映射,
說明:大家可以通過hostname命令查看一下自己的主機名,注意/etc/hosts檔案中的主機名稱最好與hostname查出來的主機名一致,假如不一致的話后面在進行mon節點初始化的時候可能會出現節點找不到的問題,所以兩者最好一致,
大家也可以通過hostnamectl set-hostname your_hostname設定主機名,其中your_hostname就是你所設定的主機的新名稱,
3、安裝NTP服務
因為無論是k8s集群還是ceph集群,都是要求集群中各服務器節點的時間是要同步的,否則可能會導致時鐘漂移的問題,
# yum 安裝 ntp
sudo yum install ntp ntpdate ntp-doc
# 校對系統時鐘
ntpdate 0.cn.pool.ntp.org
除此之外也可以使用第三方軟體工具chrony實作時鐘同步,
4、安裝部署ssh免密登陸
此步驟主要是為了k8s-master節點即ceph-deploy節點能夠免密登陸到其他的節點上,然后進行ceph集群相關資源的部署安裝,
此程序的安裝程序參考初試 Centos7 上 Ceph 存盤集群搭建,參考該博客的3.3和3.4即可,
最終應該達到的效果是:在k8s-master節點上在使用root用戶或者cephd用戶登陸的情況下,使用ssh k8s-node1或者k8s-node2命令能夠直接登錄到k8s-node1和k8s-node2節點上,使用exit命令即可退出k8s-node1或者k8s-node2節點的登陸,
如下圖驗證的效果一樣:
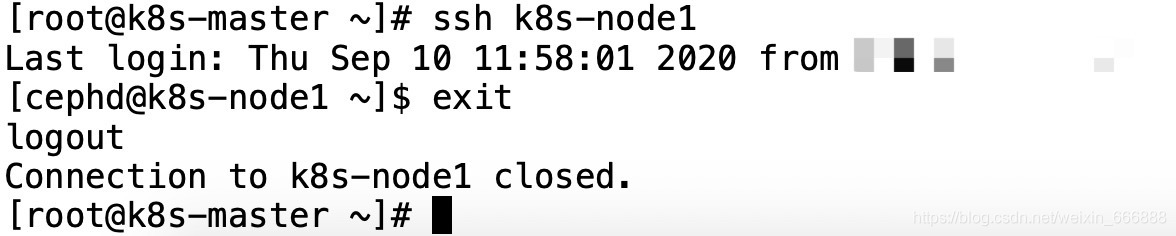
注意:我還是建議大家配置一下這個ssh免密登陸,因為之后ceph集群的組態檔或者密鑰需要同步到ceph集群的所有節點上,所以ssh免密登陸的話對于組態檔或者密鑰檔案的分發來說非常方便,
三、安裝部署ceph集群
(注意!注意!)以下步驟僅在k8s-master節點上執行,即僅在自己所指定的mon節點和ceph-deploy節點上執行以下步驟:
1、安裝ceph集群所需的依萊澩
下載安裝其他配置資源,直接執行此命令即可(此命令非常重要,如若不執行此步驟則之后會出現很多依賴錯誤的報錯)
sudo yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/yum.repos.d/dl.fedoraproject.org*
2、修改ceph源組態檔/etc/yum.repos.d/ceph.repo
(此檔案不存在創建即可),注意檔案編輯修改后使用:wq!命令保存退出,
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-jewel/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1

注意:有關此組態檔,我有一些東西想說一下,
說明一:執行完此步驟后,我所參考的博客 初試 Centos7 上 Ceph 存盤集群搭建中接下來會執行sudo yum update && sudo yum install ceph-deploy這個命令,其實這個命令包含兩個命令:sudo yum update這個命令不是隨意就能執行的,這個命令會升級所有包的同時也升級軟體和系統內核,我之前沒注意,所以我的k8s組件的版本都被升級了,額,也怪自己沒有看清楚,因為有的時候軟體或者服務安裝包升級的話可能會引起服務器上不同組件或服務之間的不適配,所以一般情況下我都是不升級已經安裝的軟體包的版本的,所以不用執行 sudo yum update命令,僅執行sudo yum install ceph-deploy這個命令進行ceph-deploy的安裝即可,
說明二:這個ceph源組態檔即/etc/yum.repos.d/ceph.repo這個檔案的內容會影響所下載的ceph-deploy和ceph的版本,比如上面我所編輯的組態檔內容就是jewel版的ceph的下載源,按照上面的ceph源組態檔下載下來的ceph版本一般是如下圖所示的版本:

一般所下載的jewel版的ceph的版本都是10.2.x,如果說大家已經安裝好了jewel版本的ceph集群,因為在文章的開頭也是說過,這個版本的ceph還是比較老的,有很多新的ceph的特性在這個版本中是沒有的,所以現在應該如何操作呢?如何將其升級到Luminous版本(12.2.12)的ceph集群呢?我建議大家參考一下這篇文章Ceph集群由Jewel版本(10.2.10)升級到Luminous版本(12.2.12),經本人實測,升級步驟準確可行,這一塊就是Ceph集群由Jewel版本(10.2.x)升級到Luminous版本(12.2.12) 的解決方法,那么如何直接安裝Luminous版本的ceph集群呢?實作方法就是修改ceph源組態檔:
將/etc/yum.repos.d/ceph.repo組態檔修改為以下內容,注意使用:wq!退出編輯并保存,
[ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=1
priority=1
type=rpm-md
gpgkey=http://mirrors.163.com/ceph/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch
enabled=1
gpgcheck=1
priority=1
type=rpm-md
gpgkey=http://mirrors.163.com/ceph/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/SRPMS
enabled=0
gpgcheck=1
type=rpm-md
gpgkey=http://mirrors.163.com/ceph/keys/release.asc
priority=1
補充說明:使用此ceph源組態檔安裝部署Luminous版本的ceph集群時,以下的操作步驟與安裝部署jewel版本的ceph集群的流程完全一樣,僅在之后的”激活osd節點“上有所不同(僅有這一個地方不同),所以即使是打算安裝Luminous版本的ceph集群的朋友也可以參考我的這篇文章,
3、安裝ceph-deploy(僅在k8s-master節點上執行)
ceph-deploy服務對應的是deploy部署節點,因為ceph-deploy服務可以很方便地實作在不同節點上安裝ceph,所以先下載ceph-deploy服務,
//安裝部署ceph-deploy節點
sudo yum install ceph-deploy
4、創建一個新的ceph集群
因為之后在這個ceph集群的admin-node節點上(比如,按照我自己的規劃我指定了k8s集群中的k8s-maste節點作為ceph集群的admin-node節點)會放置一些資源,所以大家需要在自己的admin-node的服務器節點上創建一個檔案夾,用于保存ceph集群創建時產生的配置文檔案和密鑰檔案等,
創建檔案夾mkdir toyourpath/ceph-cluster/ceph-cluster,進入到自己所創建的這個檔案夾cd toyourpath/ceph-cluster/ceph-cluster,
//創建新的ceph集群,一定要提前進入自己之前所創建的ceph-cluster檔案夾
ceph-deploy new k8s-master
注意:執行創建新的ceph集群的命令后,會發現自己的ceph-cluster檔案夾下多了幾個檔案,這幾個檔案分別是ceph.conf,ceph-deploy-ceph.log和ceph.mon.keyring檔案,
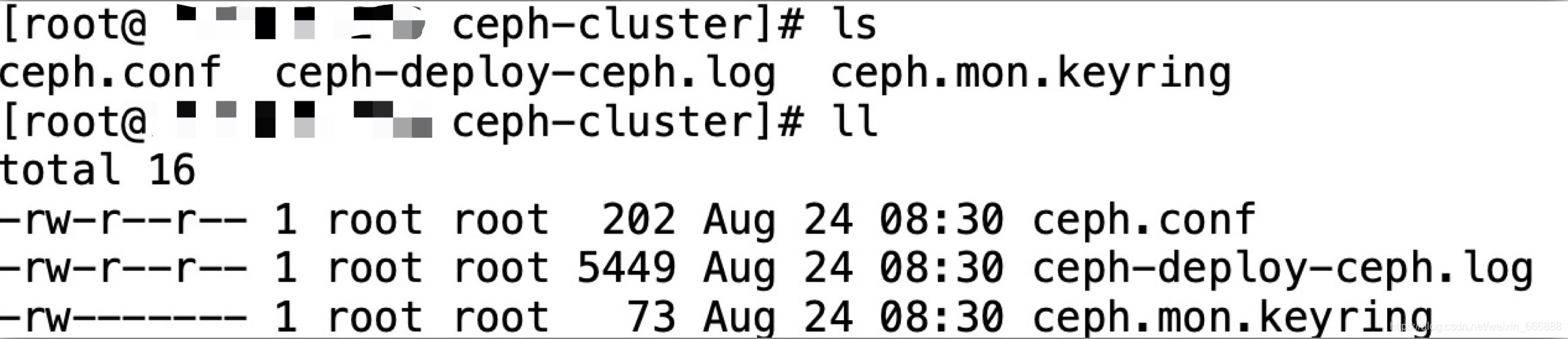
其中,ceph.conf檔案是ceph集群的組態檔,我們只需要修改編輯其中的一些地方就可以了,將mon_host修改為admin_node節點的內網ip地址;將osd pool default size設定為osd節點的個數(osd節點是什么,下文會講到,這里大家先理解成ceph集群的存盤節點就好,比如我設定了3個osd節點,所以此處我填寫的該欄位的值就是3);public network欄位用于設定ceph集群的public網路的公共網段,比如我的mon_host欄位的值(即admin_node節點的內網ip地址為10.10.7.212),把最后的212替換為0,再加上/24即可,即10.10.7.212->10.10.7.0/24,
[global]
fsid = 45c8a6a6-525c-44c5-9009-69dad92eb3af
mon_initial_members = k8s-master
mon_host = 10.10.7.212
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 3
public network = 10.10.7.0/24
將ceph.conf檔案配置好之后我們就可以安裝ceph服務了,由于我們之前僅在k8s-master(即ceph集群的admin_node節點、mon節點、ceph-depoy節點)上編輯了ceph源組態檔/etc/yum.repos.d/ceph.repo,所以我們先通過ceph-deploy來直接安裝各服務器節點上的ceph服務,
5、使用ceph-deploy安裝ceph服務
//安裝ceph服務,注意將ceph-deploy install后添加自己的服務器節點名稱
ceph-deploy install k8s-master k8s-node1 k8s-node2
說明:在安裝ceph服務的時候,可能會遇到如下幾個安裝報錯的問題,
報錯一:[k8s-master][DEBUG ] connection detected need for sudo
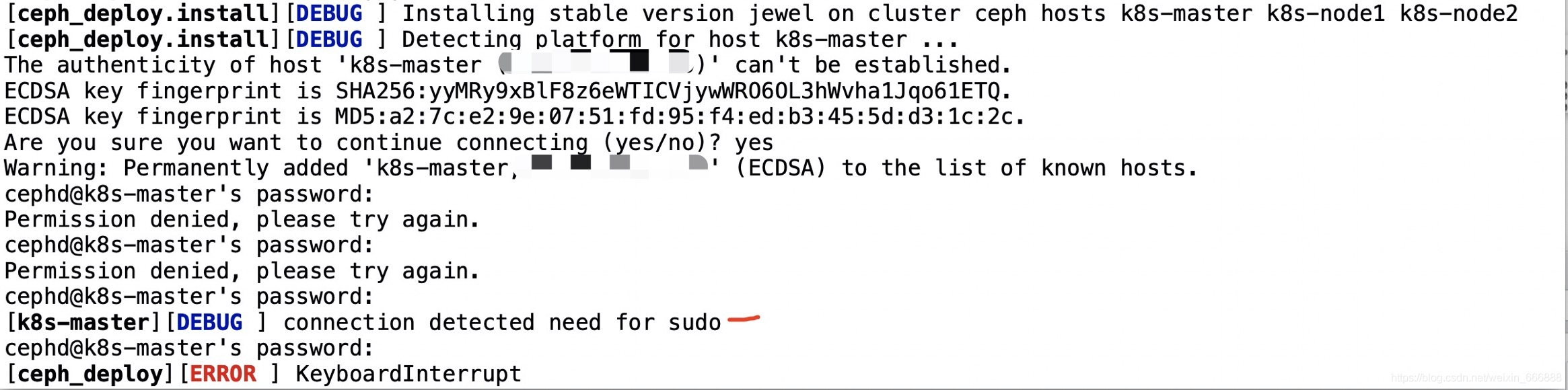
如圖所示在使用ceph-deploy安裝ceph服務的時候雖然我輸入正確了cephd@k8s-master的密碼,但是依舊報錯:[ceph_deploy] [ERROR] KeyboardInterrupt的錯誤,
解決方案:將安裝命令修改為圖中所提示的那樣:sudo ceph-deploy install k8s-master k8s-node1 k8s-node2再次進行ceph服務的安裝,
報錯二:[k8s-master][WARNIN] ensuring that /etc/yum.repos.d/ceph.repo contains a high priority
[ceph_deploy][ERRO R ] RuntimeError: NoSectionError: No section: ‘ceph’

解決方案:使用命令sudo ceph-deploy install k8s-master k8s-node1 k8s-node2安裝失敗的話就在k8s-master節點上單獨使用yum -y install ceph進行安裝(接下來會講如何在每個服務器節點上單獨安裝ceph服務),注意修改 /etc/yum.repos.d/ceph.repo組態檔(查看一下該組態檔的內容是否與上文中所提及的ceph源檔案的內容一致,如果內容一致仍然報錯的話就參考一下"報錯三"中所提及的有關ceph源組態檔的操作方法),
報錯三:使用命令ceph-deploy install k8s-master k8s-node1 k8s-node2安裝ceph時報錯,安裝程序卡在Downloading packages,提示報錯資訊No data was received after 300 seconds, disconnecting...,
經歷過以上的兩個報錯,按理說接下來就能夠下載安裝ceph服務了,這時候你所看到的界面可能是這樣的,

這個時候開始下載相關的軟體包了,可是過了好一會兒可能還是這樣,耐心等待一會可能就出現了以下的界面:

但是我的心里例外的難受啊,這,,安裝步驟,坑有點兒多啊,

大家不要放棄,堅持就是勝利!
原因:出現這個錯誤的原因應該是未能從ceph源下載所需要的ceph資源,是ceph源的問題,
解決方案:修改ceph源為國內鏡像源,執行以下操作即可:
export CEPH_DEPLOY_REPO_URL=http://mirrors.163.com/ceph/rpm-jewel/el7
export CEPH_DEPLOY_GPG_URL=http://mirrors.163.com/ceph/keys/release.asc
報錯四:在報錯三解決之后,接下來再次執行ceph-deploy install k8s-master k8s-node1 k8s-node2可能報錯,
Loaded plugins: fastestmirror, langpacks
Repository cr is listed more than once in the configuration
Repository fasttrack is listed more than once in the configuration
Existing lock /var/run/yum.pid: another copy is running as pid 115367.
Another app is currently holding the yum lock; waiting for it to exit…
原因:這個報錯就是說服務器中已經有一個yum ceph的行程在運行中了,這個就是ceph-deploy之前安裝ceph服務的行程,雖然資源下載失敗了,但是行程還是存在的,這個行程可能阻礙了ceph-deploy安裝ceph,
解決方案:使用命令kill -9 115367把這個行程kill掉即可,
接下來再次使用ceph-deploy install k8s-master k8s-node1 k8s-node2進行ceph的安裝即可,然后我們就應該能看到ceph服務的正常安裝界面了,



這里我想說一下,ceph-deploy安裝ceph集群中所有節點的ceph服務還是有很多的問題的,我比較推薦使用yum -y install ceph命令在每個ceph集群的服務器節點上分別手動安裝ceph服務,注意執行此安裝命令的前提是需要提前在每個服務器節點上配置 /etc/yum.repos.d/ceph.repo組態檔,建議大家在每個服務器節點將此ceph源組態檔的內容修改為如下內容,注意使用:wq!保存編輯并退出,
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-jewel/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-jewel/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
準備好這個ceph源組態檔后就可以進行ceph服務的安裝部署了,
6、初始化ceph集群中的monitor節點
#初始化monitor節點并收集ceph的密鑰環
sudo ceph-deploy mon create-initial
注意:此命令一定要在上文提到的ceph-cluster檔案夾下執行此操作,否則會報"找不到ceph.conf檔案"的錯誤,
其實在這一步也會出現很多問題的,但是大家不要慌,跟緊我,

報錯一:假如大家沒有像上面我所提到的那樣修改ceph.conf檔案,會出現這樣一個錯誤,
[ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
monitor: mon.k8s-master, might not be running yet
monitor k8s-master does not exist in monmap
neither public_addr nor public_network keys are defined for monitors
monitors may not be able to form quorum

原因:ceph.conf檔案中沒有配置public_network欄位,
解決方案:修改/data/deployfile/ceph-cluster/ceph.conf檔案,在檔案最后添加內容public network = 10.10.7.0/24(參考上文的第4步,注意根據自己的admin_node的內網ip設定public networ欄位的值),注意:在ceph集群的admin_node節點上設定完/data/deployfile/ceph-cluster/ceph.conf檔案之后一定要把這個檔案推送到其他節點,使用下面的命令ceph-deploy --overwrite-conf config push k8s-node1 k8s-node2將ceph集群的monitor節點(同時也是admin_node節點)上的組態檔同步到其他的ceph集群的節點上(我這里對應的就是k8s-node1節點和k8s-node2節點),注意此推送同步命令一定要在大家的ceph集群的monitor節點上的ceph-cluster目錄下執行,否則會報錯的,
報錯二:執行ceph-deploy mon create-initial命令報錯,RuntimeError: config file /etc/ceph/ceph.conf exists with different content; use --overwrite-conf to overwrite

解決方案:使用 --overwrite-conf引數覆寫原有的組態檔,修改初始化monitor節點的命令為ceph-deploy --overwrite-conf mon create-initial,繼續進行mon節點的初始化操作,
報錯三:使用命令(sudo) ceph-deploy mon create-initial初始化mon節點卡住
[k8s-master][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --admin-daemon=/var/run/ceph/ceph-mon.xlab-node4.asok mon_status
[k8s-masterx][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xlab-node4/keyring auth get client.admin
使用ceph -s看到報錯資訊如下:
auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin: (2) No such file or directory
monclient(hunting): ERROR: missing keyring, cannot use cephx for authentication
librados: client.admin initialization error (2) No such file or directory
Error connecting to cluster: ObjectNotFound

解決方案:暫時沒找到,
其實這個問題卡了我很長時間,我暫時還沒有找到解決方案,如果大家有知道的話歡迎在評論區溝通交流,我對這個問題采取的做法是比較暴力的:把原先安裝的ceph集群卸載,然后重新安裝ceph,重新初始化monitor節點即可,
卸載已經安裝的ceph集群,注意依次執行清理ceph集群的步驟
ceph-deploy forgetkeys
ceph-deploy purge k8s-master k8s-node1 k8s-node2
ceph-deploy purgedata k8s-master k8s-node1 k8s-node2
報錯四:這是在卸載ceph集群的時候遇到的錯誤,如果大家首先執行ceph-deploy purgedata k8s-master k8s-node1 k8s-node2命令的話可能會報錯,
[ceph_deploy.install][ERROR ] Ceph is still installed on: [‘k8s-master’, ‘k8s-node1’, ‘k8s-node2’]
[ceph_deploy][ERROR ] RuntimeError: refusing to purge data while Ceph is still installed

解決方案:注意卸載集群的3條指令的執行順序,修改清理ceph集群的指令執行順序:
ceph-deploy forgetkeys
ceph-deploy purge k8s-master k8s-node1 k8s-node2
ceph-deploy purgedata k8s-master k8s-node1 k8s-node2
沒有以上報錯的話,monitotr節點應該是可以正常初始化了,不出意外的話大家應該是可以看到以下的界面的:


在原先的ceph-cluster檔案夾下大家可以看到這個時候是多了幾個檔案的,就像下面這樣,是多了幾個密鑰檔案,

如果大家也得到了這幾個檔案那么說明ceph集群的monitor節點是安裝好了的,ceph存盤集群至少是需要一個Monitor(監視器)才能運行的,為了達到ceph集群的高可用,一般會在ceph集群中運行多個monitor,像我們這個地方只是初始化了一個monitor節點,之后如果要擴展新的monnitor直接使用ceph-deploy mon add k8s-node1 k8s-node2即可完成monitor監視器的新增,
四、osd節點的安裝部署
osd就是ceph集群最終存盤資料的地方,放兩張圖片大家感受以下,
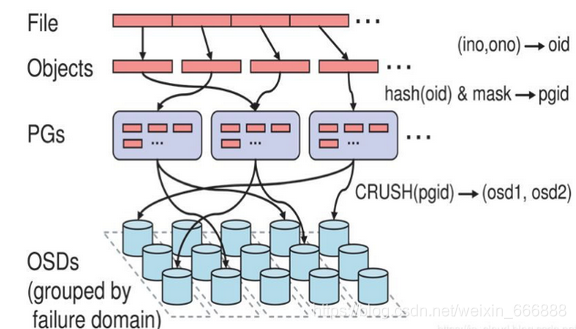
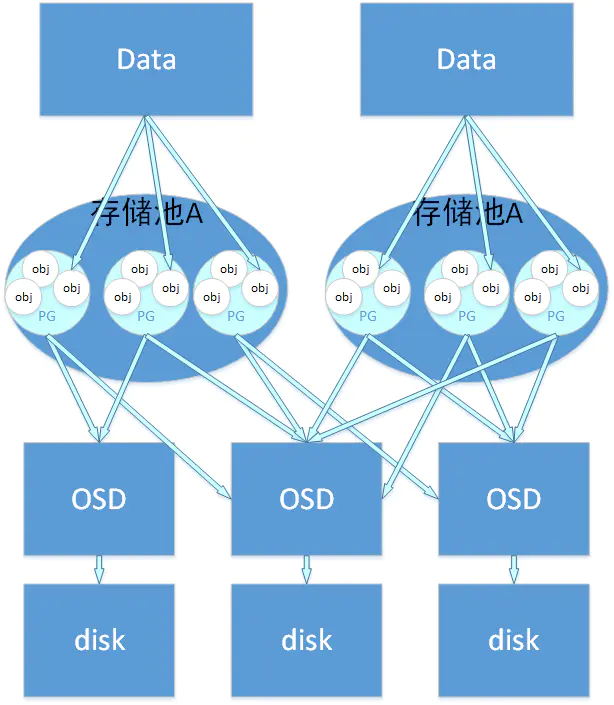
這里就不詳細解釋了,之后我會單獨寫篇博客來介紹ceph集群存盤的這塊兒內容的,現在大家知道這是用于ceph集群存盤的就可以了,
這個osd的目錄可以是一塊兒獨立磁盤上的唯一磁區,也可以是一塊兒磁盤上的某個磁區,不過我還是建議大家單獨準備獨立的磁盤,將其格式化后形成一個磁區,然后將其設定為osd的目錄即可,這樣的話,osd節點使用單獨磁盤有利于保證資料的獨立性,也方便之后osd節點的擴展(直接使用一塊兒新的資料磁盤就能完成osd節點的添加),
注意:以下的操作僅在k8s-master(即僅在ceph集群的admin_node節點上執行即可),一定要在之前的ceph-cluster檔案夾下執行以下命令,
1、通過ceph-deploy執行osd節點激活之前的準備作業
#分別在每個節點上為osd目錄設定用戶組和用戶,這一步驟一定要執行,如果不執行的話在之后的"激活osd"節點時會報權限的錯誤
#k8s-master節點上執行
sudo chown -R ceph:ceph /data1/osd0
#k8s-node1節點上執行
sudo chown -R ceph:ceph /opt/osd1
#k8s-node2節點上執行
sudo chown -R ceph:ceph /opt/osd2
ceph-deploy osd prepare k8s-master:/data1/osd0 k8s-node1:/opt/osd1 k8s-node2:/opt/osd2
//如果還是報組態檔已經存在的錯誤,直接覆寫掉組態檔即可
ceph-deploy --overwrite-conf osd prepare k8s-master:/data1/osd0 k8s-node1:/opt/osd1 k8s-node2:/opt/osd2
說明:上面代碼中的k8s-master:/data1/osd0指定的就是k8s-master節點上的/data1/osd0目錄,也就是說這個osd0節點目錄就是k8s-master節點的/data1/osd0,(如果是使用服務器上已經存在這個檔案目錄比如/data1/osd0的話)在執行osd prepare之前最好把這個/data1/osd0目錄清空一下,或者可以在k8s-master節點上直接使用一塊兒新的磁盤劃分出一個新的磁區掛載到k8s-master節點(即ceph集群的admin_node節點)上的/data1/osd0目錄即可,
一般情況下不會有什么錯誤出現,執行osd prepare操作之后的正常結果如下圖所示:
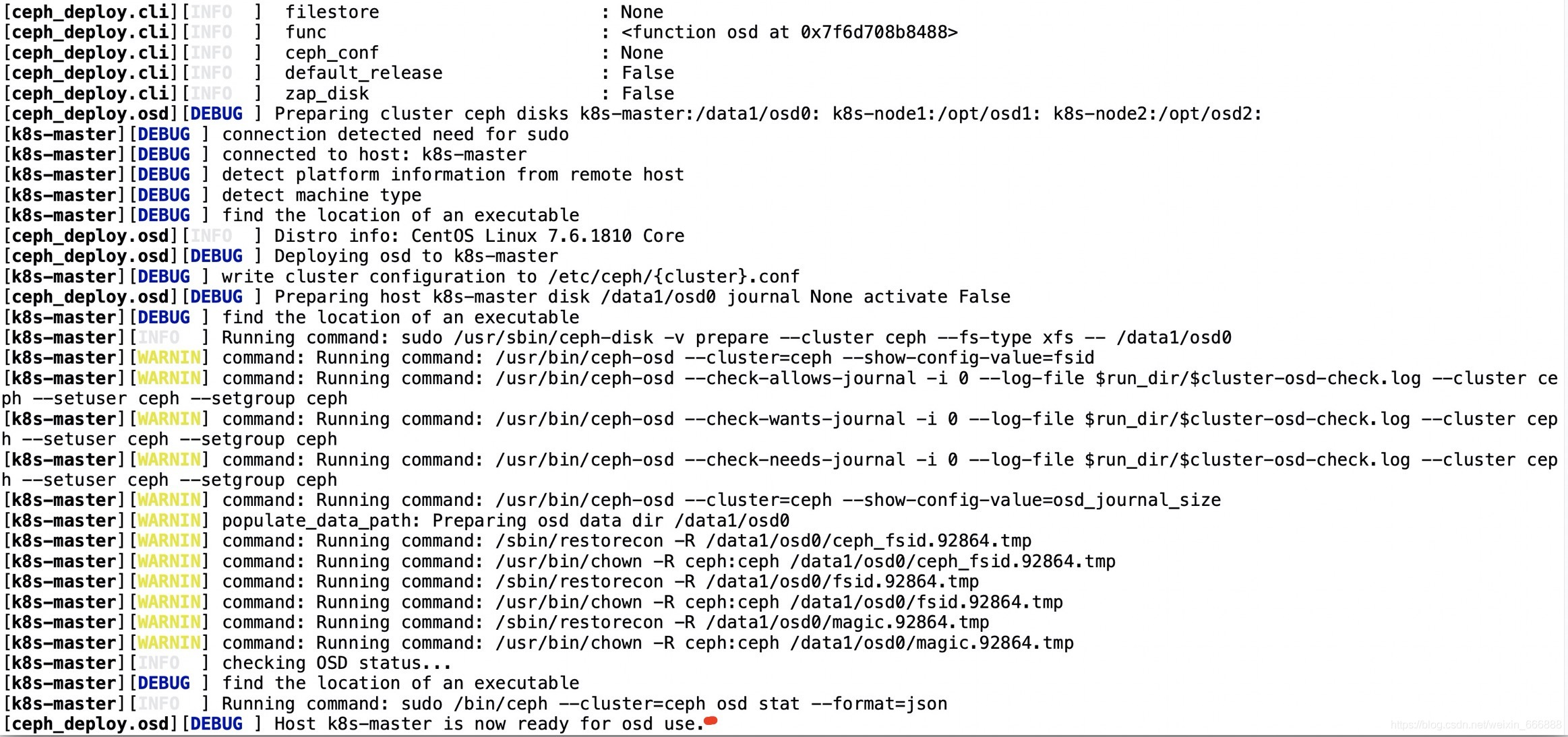
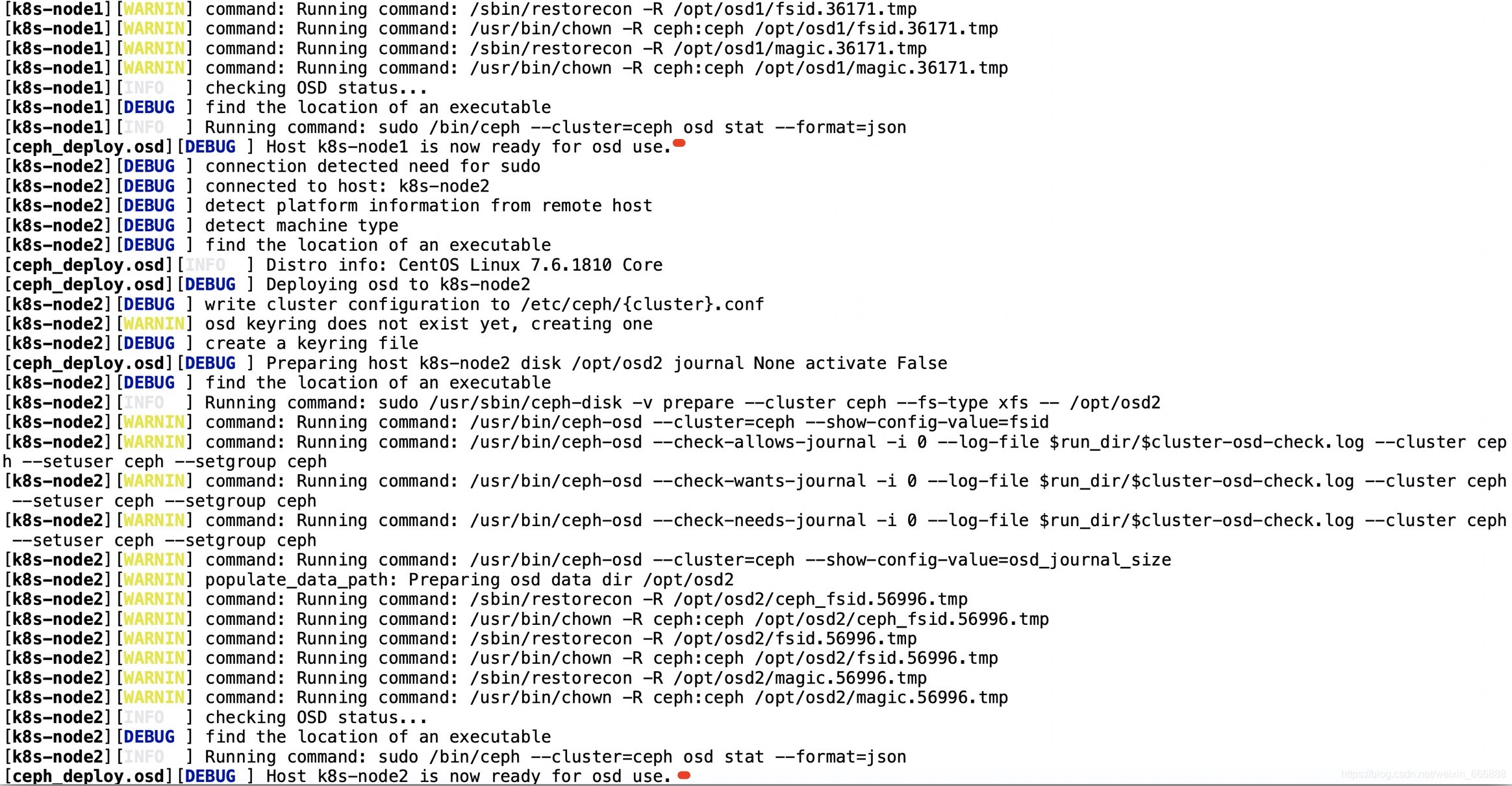
2、激活osd節點
ceph-deploy osd activate k8s-master:/data1/osd0 k8s-node1:/opt/osd1 k8s-node2:/opt/osd2
一般情況下這一步是沒有什么錯誤的,大家可以看到如下界面:
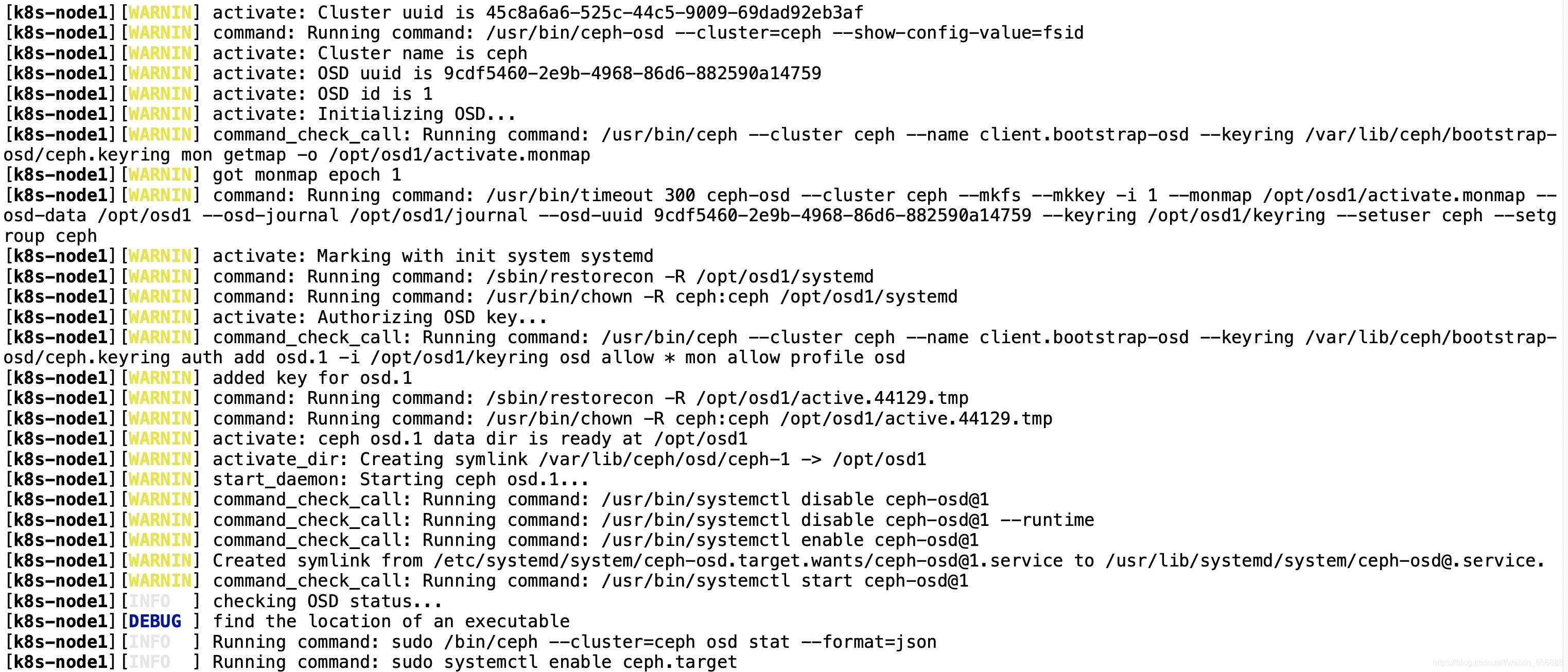
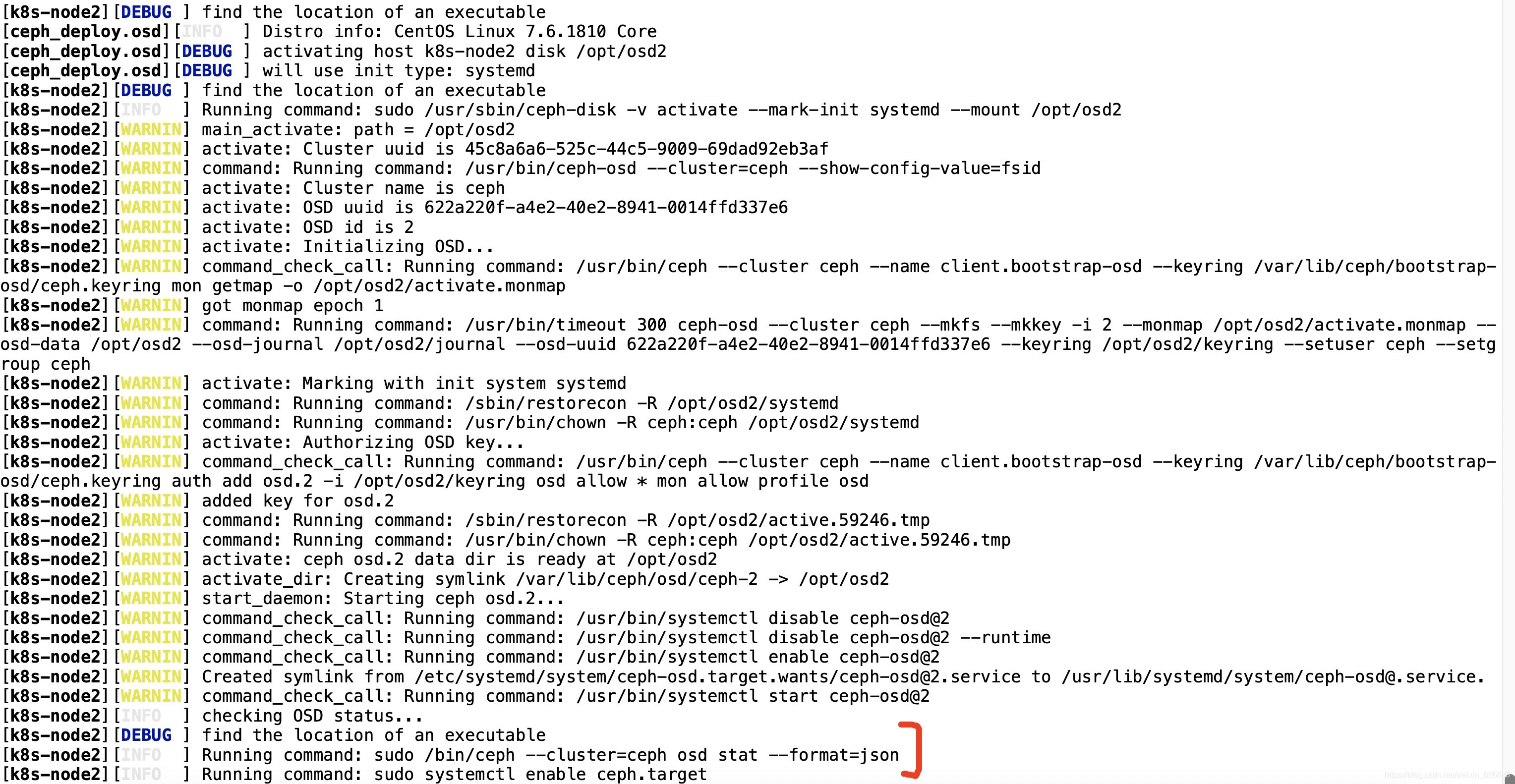
這樣的話,這個osd節點的初始化以及激活的作業就完成了,
說明:現在高版本的ceph集群,比如Luminous和mimic版本的ceph集群使用ceph-deploy osd create {node-name}:{disk}[:{path/to/journal}]命令來創建osd,具體可以參考Ceph Documention——增加/洗掉osd,
3、同步ceph集群的組態檔和admin密鑰
//將ceph集群admin節點上的密鑰和組態檔同步到各節點
ceph-deploy admin k8s-master k8s-node1 k8s-node2
說明:因為之后會在ceph集群的admin_node節點上執行一些ceph的操作,其他的ceph集群節點如果沒有這個admin_node節點上的組態檔和admin密鑰的話可能會出現ceph集群連接不上的問題,所以這個地方最好還是同步一下,同步完成的話應該是下面界面所展示的這樣:
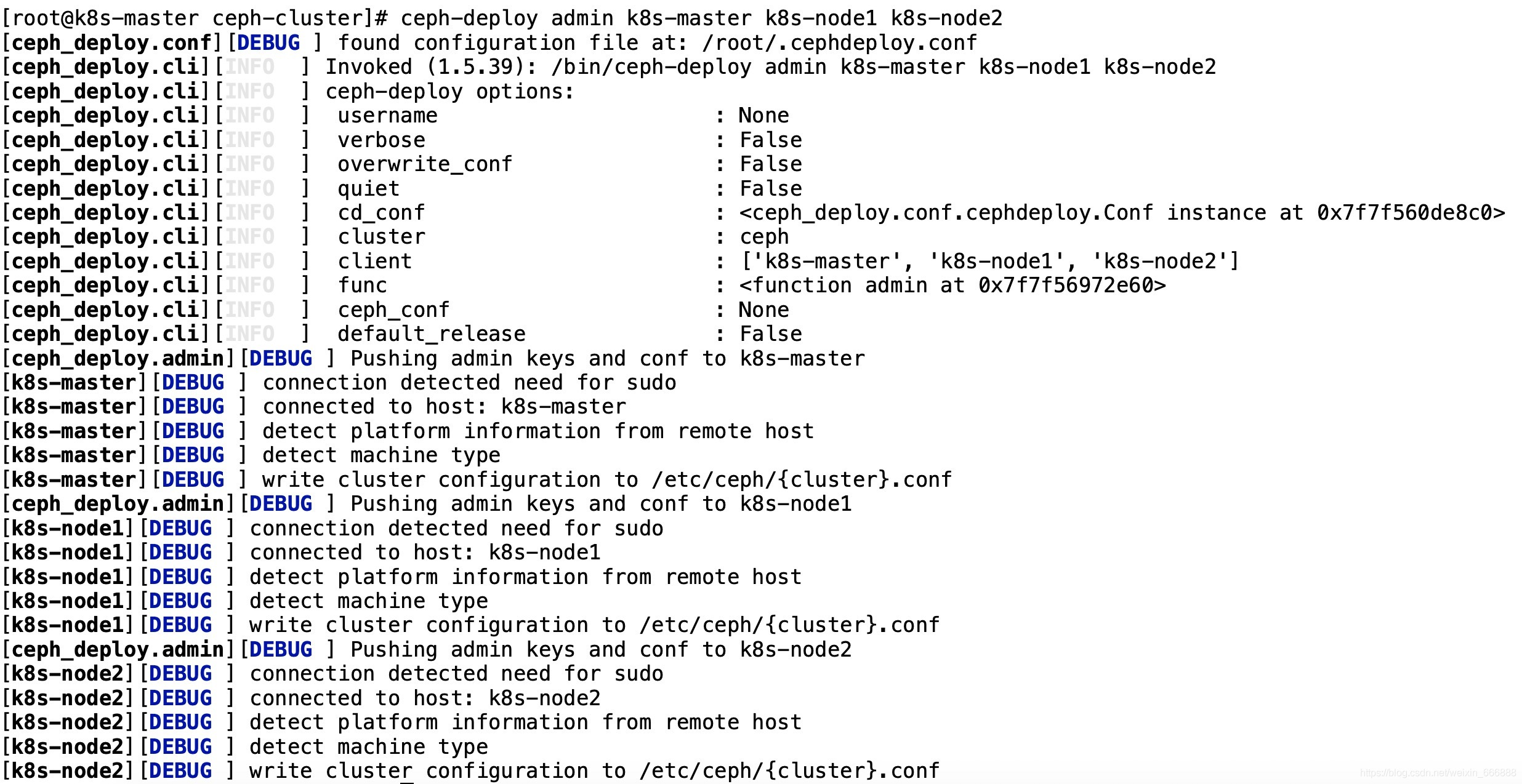
接下來需要在各個ceph集群的節點上設定admin密鑰檔案的讀取權限,在每個ceph集群的節點上執行一下即可(比如此處我的ceph集群有3個節點,分別是k8s-master、k8s-node1、k8s-node2,在這些節點上設定admin密鑰檔案的讀取權限),
#所有服務器節點上執行該檔案的權限授予操作
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
到現在為止,整個ceph集群的安裝部署就已經完成了,但是,

我們還需要驗證一下ceph集群的健康狀態,
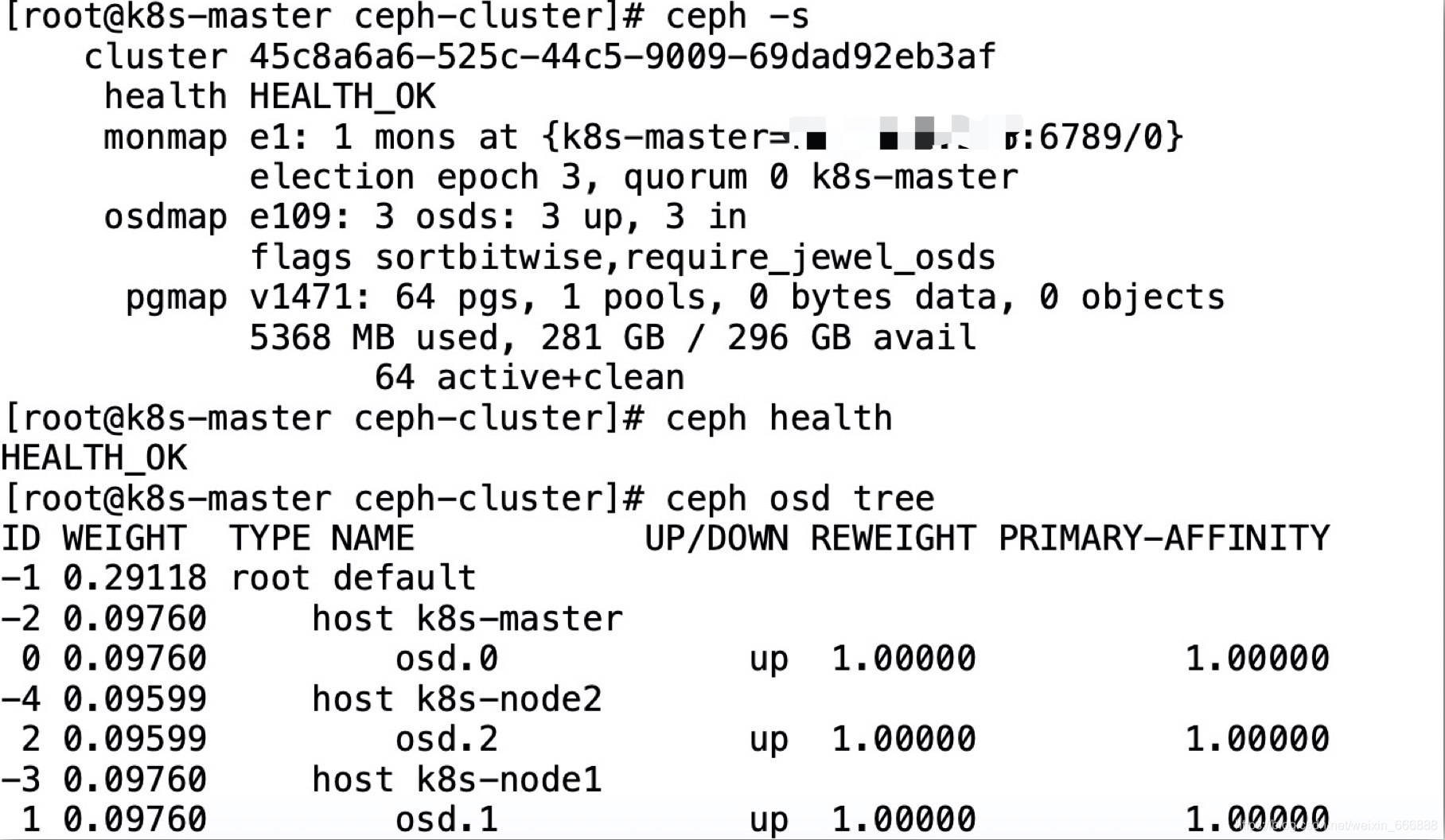
4、驗證ceph集群的健康狀態
//查看整個ceph集群的健康狀態,包含詳細的集群資訊
ceph -s
//查看ceph集群中osd節點的狀態
ceph osd tree
//僅查看集群的狀態是否健康,不含詳細的集群資訊
ceph health
我當時查看ceph集群的狀態是這樣的,
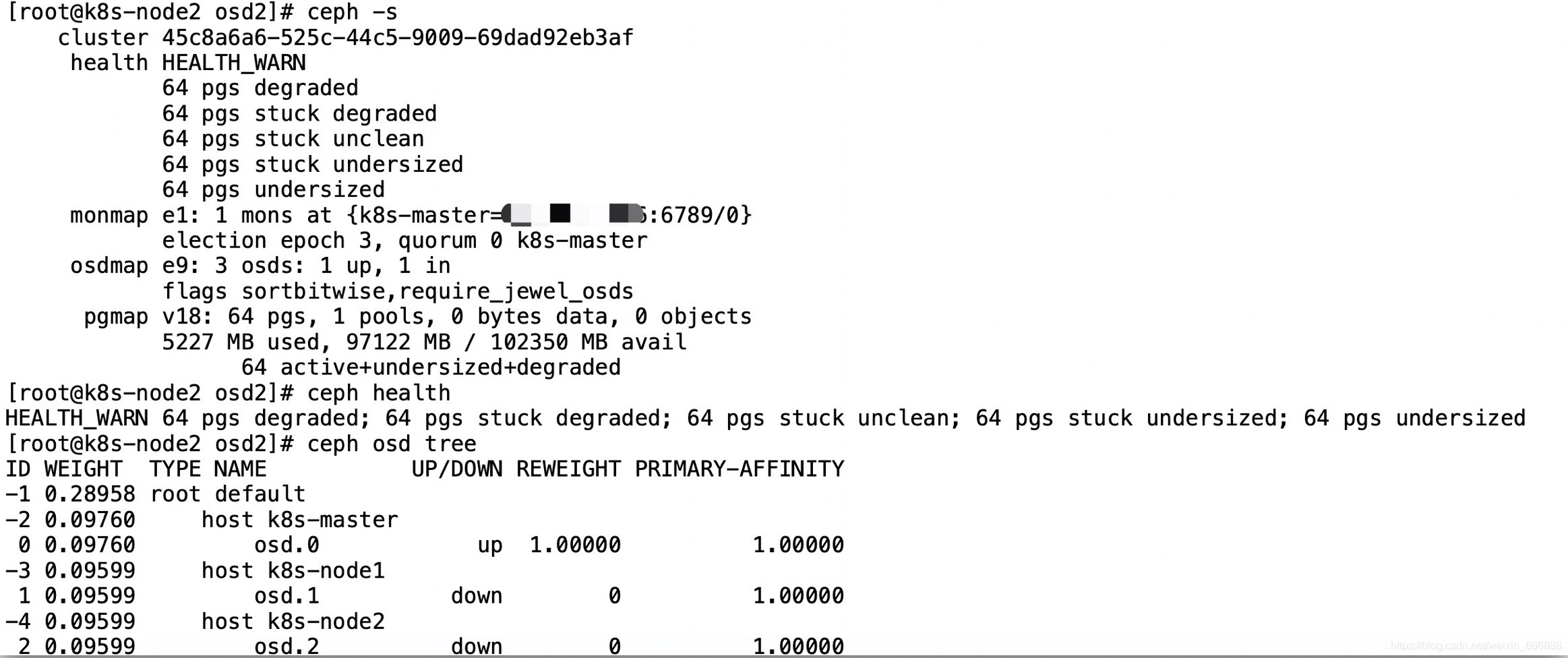


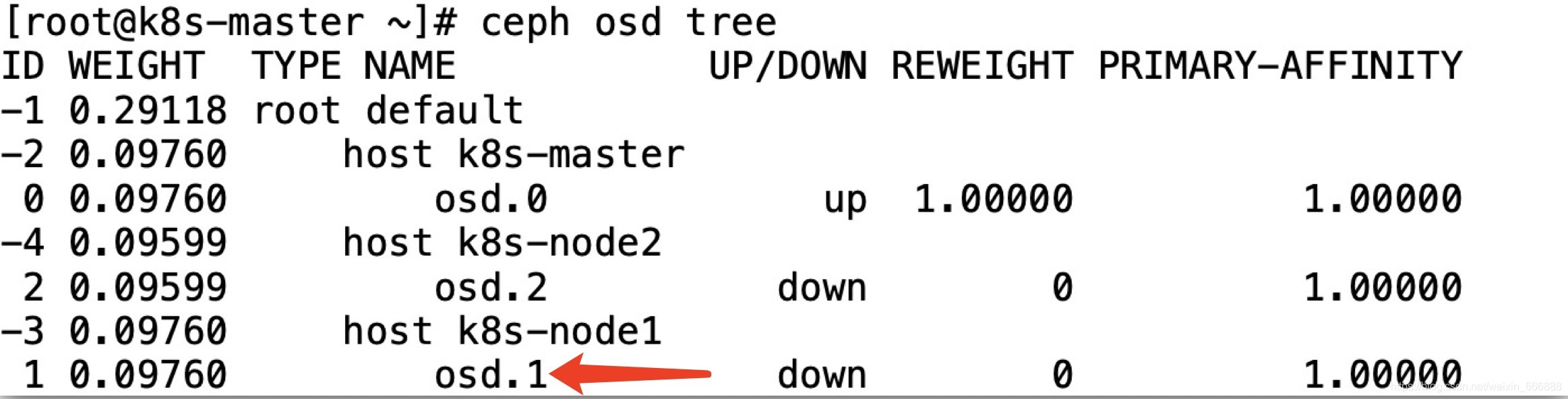
從上圖可以看出是osd節點沒有啟動成功,我使用了命令systemctl restart ceph-osd@1(由于osd.1服務部署在了k8s-node1節點上,所以這里需要在k8s-node1節點上執行這個命令)重啟了一下服務.
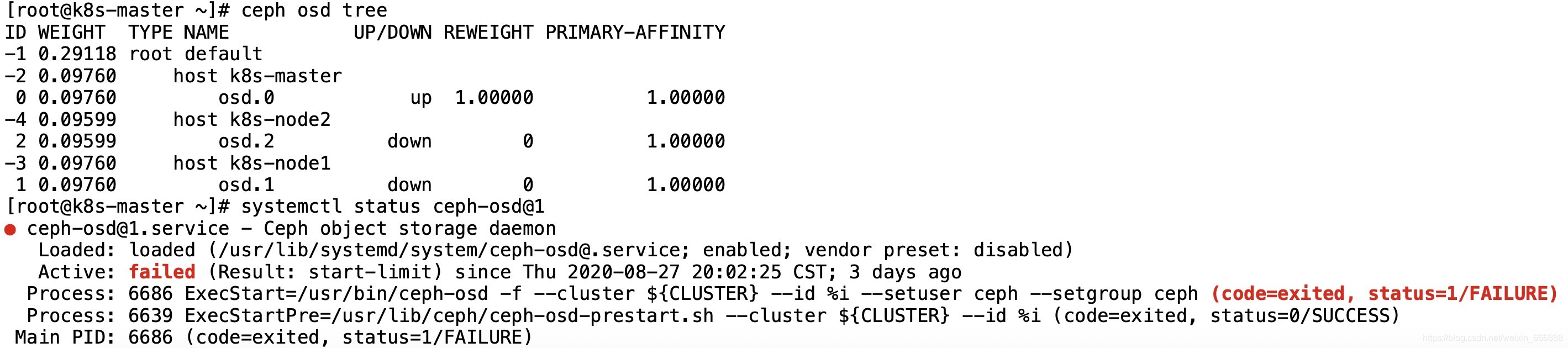
額,我重啟osd服務后好像并沒有什么作用,這個報錯資訊也不夠明顯,我還是不能找到具體的報錯原因,去看一下ceph集群的日志,執行命令cd /var/log/ceph進入ceph集群的日志目錄并查看相應的osd服務的日志,
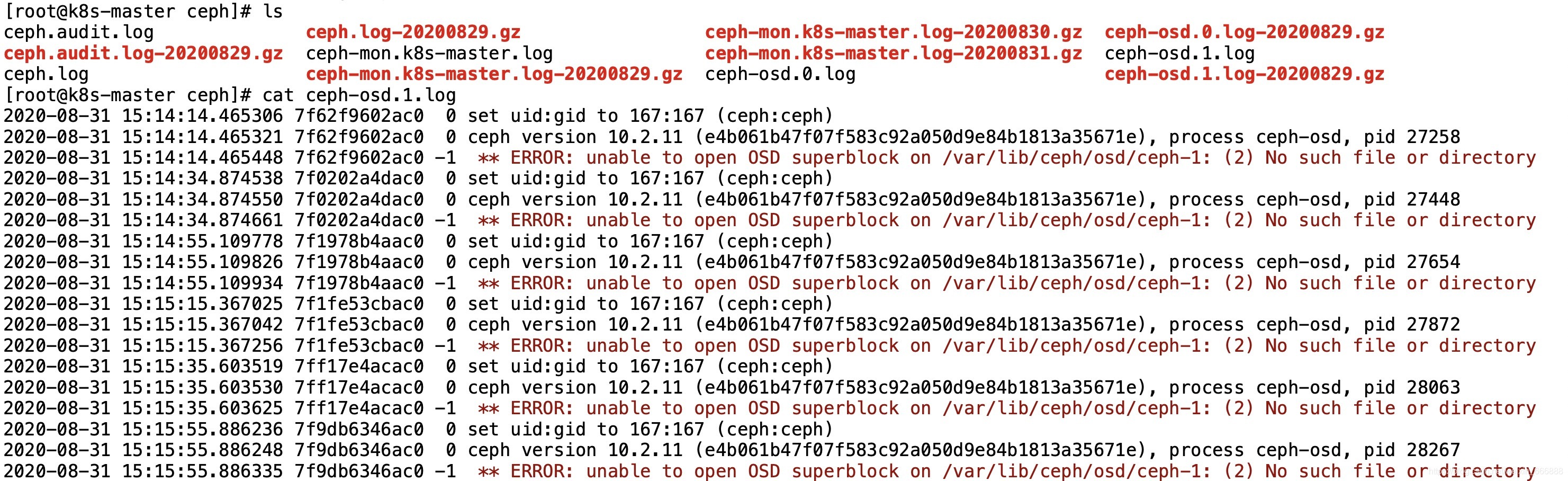
報錯一:這里的報錯資訊是,** ERROR: unable to open OSD superblock on /var/lib/ceph/osd/ceph-1: (2) No such file or directory,即ceph-osd守護程式無法讀取基礎檔案系統
原因:我看了一下 k8s-master節點上/var/lib/ceph/osd/目錄下的檔案,確實是缺少內容,缺少ceph-1檔案(夾)
解決方案:從k8s-node1和k8s-node2節點上將相應檔案檔案拷貝到k8s-master節點的該目錄下(建議通過通過ssh的scp檔案拷貝命令實作)

可以看到在k8s-node1節點上是有這個檔案夾的,額,我也不怎么清楚作為ceph集群admin_node節點的k8s-master節點上為什么沒有這個檔案夾?先把這個k8s-node1節點上的檔案拷貝到k8s-master節點上,這里大家可以用很多方法比如ssh下的scp來拷貝或者通過winscp、Royal TSX等工具來傳輸檔案,這樣,就不會再報上面的"檔案缺失"的錯誤了,然后我通過命令systemctl start ceph-osd@1 再次手動啟動osd.1的osd服務,結果又遇到了錯誤,
報錯二:通過systemctl start ceph-osd@1命令啟動osd.1失敗,報錯為filestore(/var/lib/ceph/osd/ceph-1) FileStore::mount: error opening ‘/var/lib/ceph/osd/ceph-1/fsid’: (13) Permission denied
osd.2 0 OSD:init: unable to mount object store
** ERROR: osd init failed: (13) Permission denied
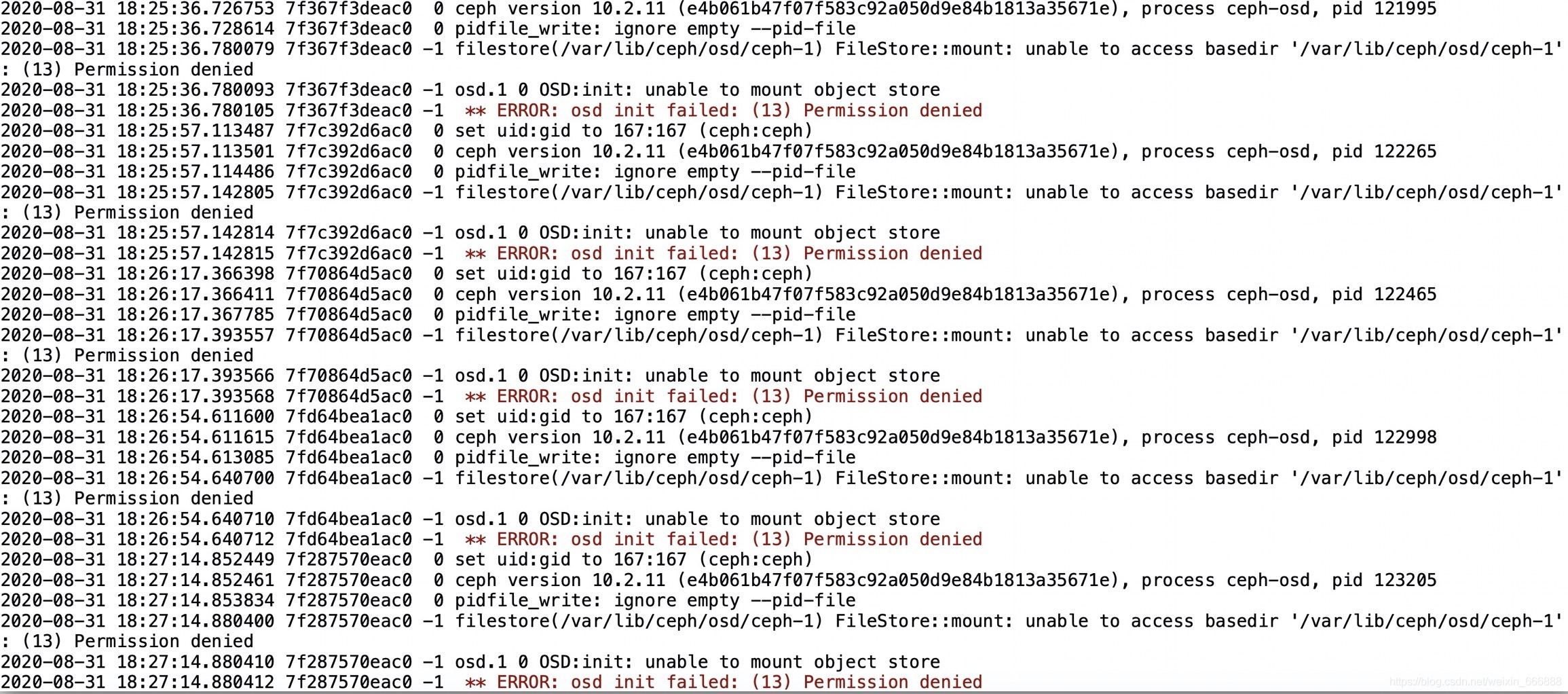
原因:這里是檔案夾的訪問權限的問題
解決方案:通過chown -R ceph:ceph /var/lib/ceph/osd/ceph-1/*命令開放該檔案的權限,注意對于osd.2的osd服務也需要這樣開放檔案的權限,
chown -R ceph:ceph /var/lib/ceph/osd/ceph-1/*
chown -R ceph:ceph /var/lib/ceph/osd/ceph-2/*
可以通過ll -ls命令查看關于檔案權限的分配是否到位,

之后在啟動osd服務的時候可能害會遇到一個啟動osd服務的錯誤,
報錯三:啟動ceph集群中的osd節點報錯,
Job for ceph-osd@1.service failed because start of the service was attempted too often. See “systemctl status ceph-osd@1.service” and “journalctl -xe” for details.
To force a start use “systemctl reset-failed ceph-osd@1.service” followed by “systemctl start ceph-osd@1.service” again.

原因:默認情況下,一個服務在10秒內最多允許啟動5次,啟動次數超過5次后,就會報該錯誤資訊
解決方案:使用命令systemctl reset-failed ceph-osd@1重置osd.1 單元的啟動頻率計數器,清除該單元的啟動限制,然后就可以繼續通過systemctl restart ceph-osd@1命令重啟osd服務了,
報錯四:處理完以上可能出現的錯誤,還有可能遇到ERROR: osd init failed: (36) File name too long的報錯問題,
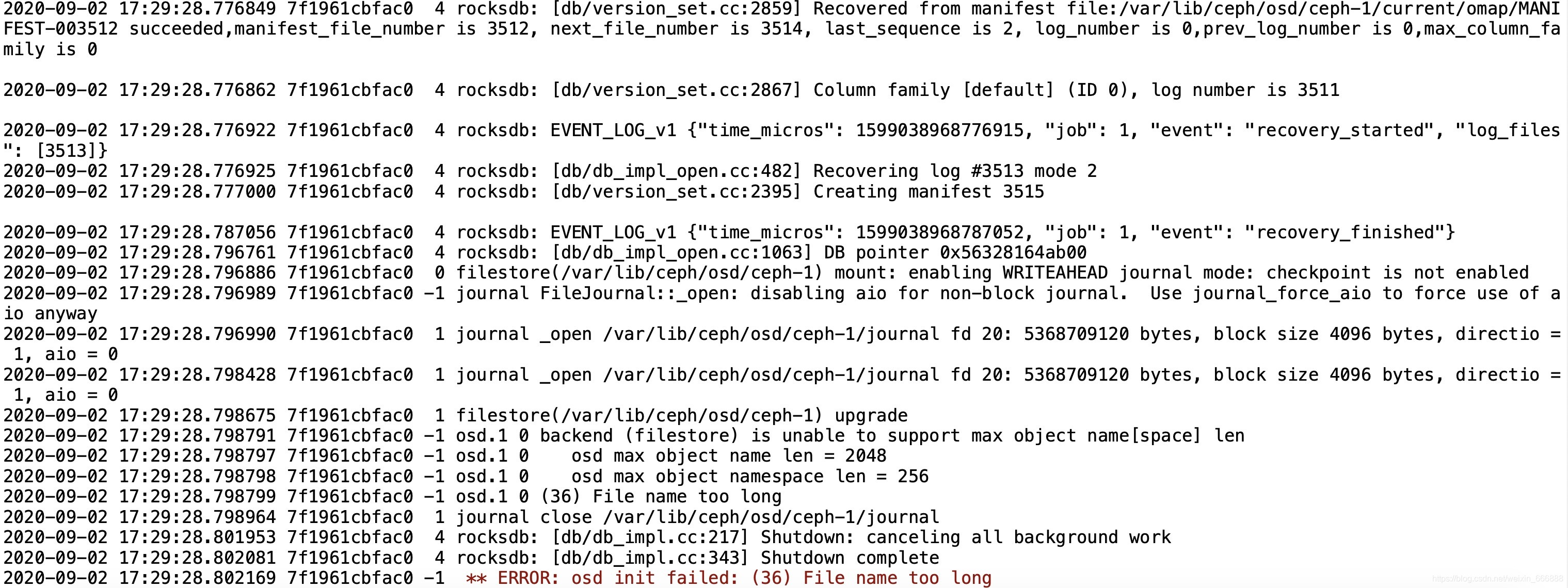
解決方案:修改ceph-cluster集群下的ceph.conf檔案,在檔案末尾添加內容:
osd max object name len = 256
osd max object namespace len = 64
最后使用:wq!保存編輯并退出,有關這個問題的詳細解釋,大家可以參考一下這篇文章Ceph osd啟動報錯osd init failed (36) File name too long,此處我就不再贅述了,
在k8s-node1節點上使用`systemctl start ceph-osd@1`命令啟動osd.1服務,在k8s-node2節點上使用`systemctl start ceph-osd@2`命令啟動osd.2服務,
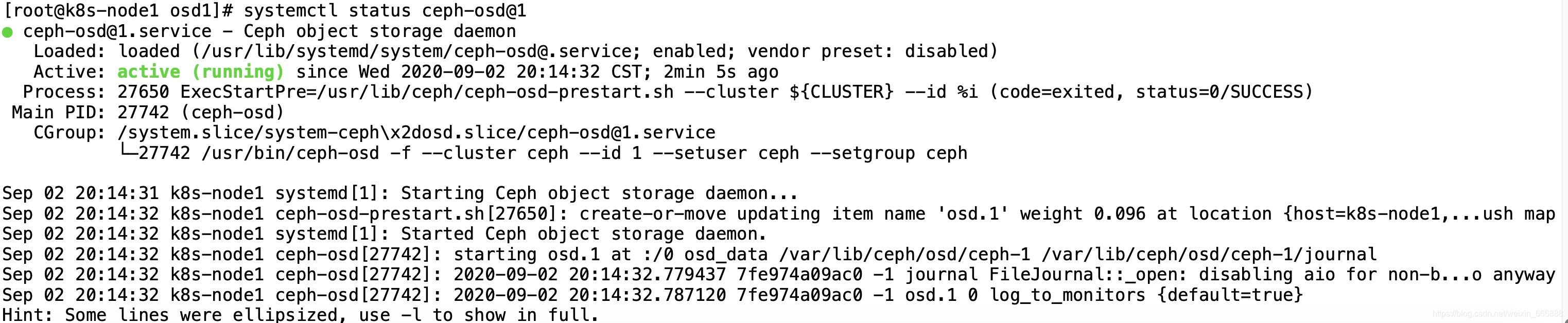
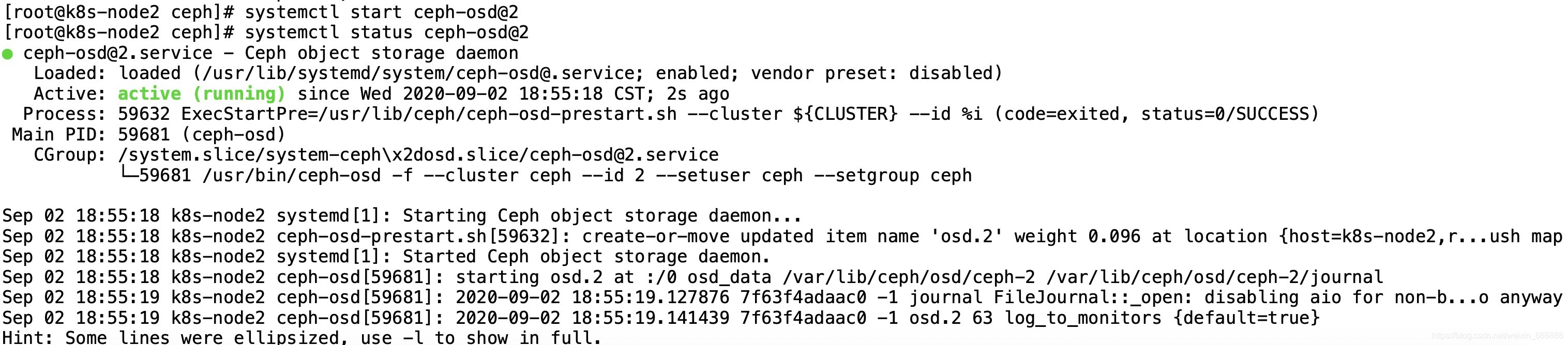
這一次啟動起來了,

至此,我們的ceph集群就已經安裝部署成功了,并且ceph集群也是處于健康狀態的,osd節點也是已經都處于up狀態了,下一步的話我們主要是討論ceph存盤集群的使用了,歡迎有需要的朋友移步到我的其他博客,
說明:這里介紹幾個與osd服務相關的命令
手動啟動osd節點服務:systemctl start ceph-osd@1 (這個后面的數字1就是osd的編號)
重新啟動osd節點服務:systemctl restart ceph-osd@1
查看osd節點服務的狀態:systemctl status ceph-osd@1
在文章的最后,我想說明一下為什么在文章中我一直在強調要在ceph-cluster檔案夾的目錄下執行ceph-deploy命令,因為不在這個檔案夾下執行命令的話就會報一個錯誤,[ceph_deploy][ERROR ] ConfigError: Cannot load config: [Errno 2] No such file or directory: ‘ceph.conf’; has ceph-deploy new been run in this directory?,所以執行與ceph-deploy有關的命令一點要在包含ceph.conf檔案的ceph-cluster檔案夾目錄下執行,
最后,如果大家在安裝ceph集群程序中遇到了問題,那么歡迎大家在評論區留言,大家一起討論交流!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/102610.html
標籤:其他
下一篇:速求多線路選路優化邏輯