
上篇文章給大家講解了Flink中常用的到算子 ?(Flink中的17種TransFormAction算子)那您寫的代碼如何進行優化那,提高效率?那接下來我們使用分布式快取、廣播變數來提高代碼的效率,
一、Flink 的廣播變數(重點 )
介紹Flink廣播變數及試用場景
Flink 支持廣播變數,就是將資料廣播到具體的 taskmanager 上,資料存盤在記憶體中, 這樣可以級訓大量的 shuffle 操作; 比如在資料 join 階段,不可避免的就是大量的 shuffle 操作,我們可以把其中一個 dataSet 廣播出去,一直加載到 taskManager 的記憶體 中,可以直接在記憶體中拿資料,避免了大量的 shuffle, 導致集群性能下降; 廣播變數創 建后,它可以運行在集群中的任何 function 上,而不需要多次傳遞給集群節點,另外需要 記住,不應該修改廣播變數,這樣才能確保每個節點獲取到的值都是一致的,
一句話解釋,可以理解為是一個公共的共享變數,我們可以把一個 dataset 資料集廣 播出去, 然后不同的 task 在節點上都能夠獲取到,這個資料在每個節點上只會存在一份, 如果不使用 broadcast,則在每個節點中的每個 task 中都需要拷貝一份 dataset 資料集, 比較浪費記憶體(也 就是一個節點中可能會存在多份 dataset 資料),
注意事項: 因為廣播變數是要把 dataset 廣播到記憶體中,所以廣播的資料量不能太大,否則會 出 現 OOM 這樣的問題,
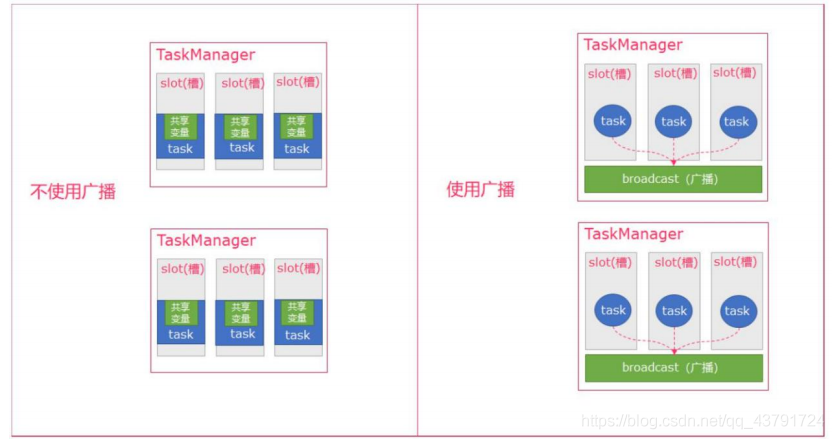
- 可以理解廣播變數就是一個公共的變數
- 將一個資料集廣播后,不同的Task都可以在節點上獲取到
- 每個節點 只保留一份
- 如果不使用廣播,每一個Task都會拷貝一份資料集,造成記憶體資源浪法,
用法:
在需要使用廣播的操作后,使用 withBroadcastSet 創建廣播
在操作中,使用 getRuntimeContext.getBroadcastVariable [廣播資料型別] ( 廣播名 )獲取廣播變數
示例:
創建一個 學生 資料集,包含以下資料
|學生 ID | 姓名 |
List((1, “張三”), (2, “李四”), (3, “王五”))
將該資料,發布到廣播,
再創建一個 成績 資料集
|學生 ID | 學科 | 成績 |
List( (1, “語文”, 50),(2, “數學”, 70), (3, “英文”, 86))
通過獲取廣播變數中的資訊將資料轉為
List( (“張三”, “語文”, 50),(“李四”, “數學”, 70), (“王五”, “英文”, 86))
實作步驟
- 獲取批處理運行環境
- 分別創建兩個資料集(學生資訊、成績資訊)
- 使用RichMapFuncation 對成績資料進行map轉換
- 在資料集呼叫map方法后,呼叫 withBroadcastSet將學生資訊創建廣播
- 實作RichMapFunction
a. 將成績資料(學生 ID,學科,成績)-> (學生姓名,學科,成績)
b.重寫 open 方法中的,獲取廣播資料
c.匯入 import scala.collection.JavaConverters._ 隱式轉換
d.將廣播變數使用asScala 轉換為Scala集合,在只用toList轉為scala toMap集合
e.在map方式用使用廣播變數進行轉換 - 列印輸出
代碼參考
import java.util
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/**
* 需求: 創建一個 學生資料集,包含以下資料
* List((1, "張三"), (2, "李四"), (3, "王五"))
* 再創建一個 成績資料集,
* |學生ID | 學科| 成績|
* List( (1, "語文", 50),(2, "數學", 70), (3, "英文", 86))
* 請通過廣播獲取到學生姓名,將資料轉換為
* List( ("張三", "語文", 50),("李四", "數學", 70), ("王五", "英文", 86))
*
* @author
* @date 2020/9/18 23:15
* @version 1.0
*/
object BatchBroadcast {
def main(args: Array[String]): Unit = {
//1.構建運行環境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.構建資料集
val student = env.fromCollection(List((1, "張三"), (2, "李四"), (3, "王五")))
val score = env.fromCollection(List((1, "語文", 50), (2, "數學", 70), (3, "英文", 86)))
//3.使用RichMapFunction 對成績資料集進行map轉換
val result = score.map(new RichMapFunction[(Int, String, Int), (String, String, Int)] {
// 定義一個map用來存放廣播變數中的資訊
var studentMap: Map[Int, String] = null
override def open(parameters: Configuration): Unit = {
// 匯入工具類將java代碼轉為scala
import scala.collection.JavaConversions._
// 獲取廣播變數中的資訊
val studentList: util.List[(Int, String)] = getRuntimeContext.getBroadcastVariable[(Int, String)]("student")
studentMap = studentList.toMap
}
// 重寫map方法回傳指定資料
override def map(value: (Int, String, Int)): (String, String, Int) = {
val stuName = studentMap.getOrElse(value._1, "")
(stuName, value._2, value._3)
}
}).withBroadcastSet(student, "student")
// 結果輸出
result.print()
/*(張三,語文,50)
(李四,數學,70)
(王五,英文,86)
*/
}
}
二、Flink 的分布式快取(重點 )
介紹分布式快取:
Flink 提供了一個類似于 Hadoop 的分布式快取,讓并行運行實體的函式可以在本地訪 問,這 個功能可以被使用來分享外部靜態的資料,例如:機器學習的邏輯回歸模型等! 快取的使用流程: 使用 ExecutionEnvironment 實體對本地的或者遠程的檔案(例如:HDFS 上的檔案),為緩 存 檔案指定一個名字注冊該快取檔案!當程式執行時候,Flink 會自動將復制檔案或者目 錄到所有 worker 節點的本地檔案系統中,函式可以根據名字去該節點的本地檔案系統中檢 索該檔案!
注意: 廣播是將變數分發到各個 worker 節點的記憶體上,分布式快取是將檔案快取到各個 worker 節點上;
用法:
使用 Flink 運行時環境的 registerCachedFile 注冊一個分布式快取 在操作中
使用 getRuntimeContext.getDistributedCache.getFile ( 檔案名 )獲取分布 式快取
示例:
List( (1, “語文”, 50),(2, “數學”, 70), (3, “英文”, 86))
使用分布式快取獲取資料將數資料轉為
List( (“張三”, “語文”, 50),(“李四”, “數學”, 70), (“王五”, “英文”, 86))
注意:student.txt測驗檔案保存了學生 ID 以及學生姓名
實作步驟:
- 將創建student.txt 檔案
- 獲取批處理運行環境
- 創建成績資料集
- 對 成績 資料集進行 map 轉換,將(學生 ID, 學科, 分數)轉換為(學生姓名,學科, 分數)
a. RichMapFunction 的 open 方法中,獲取分布式快取資料
b. 在 map 方法中進行轉換 - 實作 open 方法
a. 使用 getRuntimeContext.getDistributedCache.getFile 獲取分布式快取檔案
b. 使用 Scala.fromFile 讀取檔案,并獲取行 c. 將文本轉換為元組(學生 ID,學生姓名),再轉換為 List - 實作 map 方法
a. 從分布式快取中根據學生 ID 過濾出來學生
b. 獲取學生姓名
c. 構建最終結果元組 - 列印測驗
代碼參考
import java.io.File
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import scala.io.Source
/** * 需求:
* 創建一個 成績 資料集
* List( (1, "語文", 50),(2, "數學", 70), (3, "英文", 86))
* 請通過分布式快取獲取到學生姓名,將資料轉換為
* List( ("張三", "語文", 50),("李四", "數學", 70), ("王五", "英文", 86))
* 注: distribute_cache_student 測驗檔案保存了學生 ID 以及學生姓名
*
* @author
* @date 2020/9/18 23:51
* @version 1.0
*/
object BatchDisCachedFile {
def main(args: Array[String]): Unit = {
//1.構建運行環境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.構建資料集
val scoreDataSet = env.fromCollection(List((1, "語文", 50), (2, "數學", 70), (3, "英文", 86)))
//3.注冊分布式快取
env.registerCachedFile("./data/student.txt", "student")
val result = scoreDataSet.map(new RichMapFunction[(Int, String, Int), (String, String, Int)] {
//定義一個map用來存盤分布式快取中的資料
var studentMap: Map[Int, String] = null
// 初始化操作
override def open(parameters: Configuration): Unit = {
// 獲取快取中的資訊
val student: File = getRuntimeContext.getDistributedCache.getFile("student")
// 讀取據按照每行資料回傳
val liens = Source.fromFile(student).getLines()
//遍歷資料進行回傳
studentMap = liens.map(s => {
val arr = s.split(",")
(arr(0).toInt, arr(1))
}).toMap
}
override def map(value: (Int, String, Int)): (String, String, Int) = {
val studentName = studentMap.getOrElse(value._1, "")
(studentName, value._2, value._3)
}
})
result.print()
}
}
三、Flink累加器(Accumulators 了解)
介紹:
Accumulator 即累加器,與 Mapreduce counter 的應用場景差不多,都能很好地觀察 task 在運行期間的資料變化 可以在 Flink job 任務中的算子函式中操作累加器,但是只 能在任務執行結束之后才能獲得累加器的最終結果, Counter 是 一 個 具 體 的 累 加 器 (Accumulator) 實 現 IntCounter, LongCounter 和 DoubleCounter
示例
需求: 給定一個資料源 “a”,“b”,“c”,“d” 通過累加器列印出多少個元素
實作步驟:
- 創建累加器
- 注冊累加器
- 使用累加器
- 獲取累加器的結果
代碼參考
import org.apache.flink.api.common.accumulators.IntCounter
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/** 需求:
* 給定一個資料源
* "a","b","c","d"
* 通過累加器列印出多少個元素
*
* @author
* @date 2020/9/19 0:17
* @version 1.0
*/
object BatchCounter {
def main(args: Array[String]): Unit = {
//1.構建運行環境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.構建資料源
val dataSet = env.fromElements("a", "b", "c", "d")
val resultDataSet = dataSet.map(new RichMapFunction[String, String] {
//定義一個累加器
val counter: IntCounter = new IntCounter()
override def open(parameters: Configuration): Unit = {
getRuntimeContext.addAccumulator("MyAccumulator", counter)
}
override def map(value: String): String = {
counter.add(1)
value
}
})
resultDataSet.writeAsText("./data/BatchCounter")
val result = env.execute("BatchCounter")
// 獲取累加資料
val value = result.getAccumulatorResult[Int]("MyAccumulator")
println("累加器的最終結果是:" + value)
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/102794.html
標籤:其他
上一篇:hadoop-day02