拓撲排序(Topological Sorting)
- Ⅰ 前言
- Ⅱ 拓撲排序演算法決議
- A. Kahn 演算法
- B. DFS 演算法
- C. 演算法時間復雜度
Ⅰ 前言
我們一般寫程式的時候,一個完整的專案往往會包含很多代碼源檔案,編譯器在編譯整個專案的時候,需要按照依賴關系,依次編譯每個源檔案,比如 a.java 依賴 b.java,那在編譯的時候,編譯器需要先編譯 b.java,才能編譯 a.java,
原來我寫 C 語言的程式的時候,經常要用到聯合編譯,當時我們運行程式都是手動在命令列上編譯和運行,所以如果要聯合編譯而且有依賴關系,比如 a.c 里用到了 b.c 的函式,我們就要先把 b.c 編譯,生成一個 obj 檔案,然后再用 b.obj 和 a.c 一起編譯,大家如果看我最早的文章,一定會經常看到,現在用 Java 就舒服很多,IDE 會自動編譯這個檔案所依賴的其他檔案,不用我再一個一個按照依賴關系手動編譯了,
編譯器通過分析源檔案或者程式員事先寫好的編譯組態檔(比如 Makefile)檔案,來獲取這種區域的依賴關系,那么編譯器又該如何通過源檔案兩兩之間的區域依賴關系,確定一個全域的編譯順序呢?
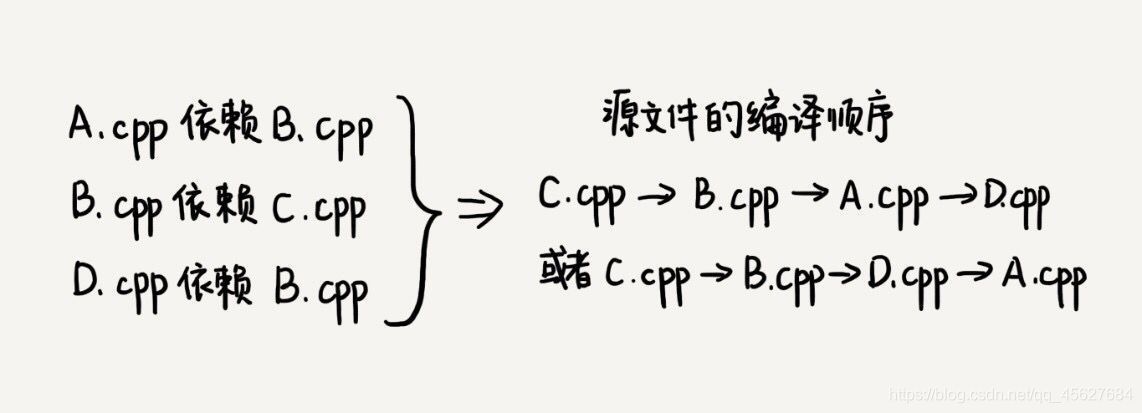
這就要用到我們這篇文章要講的這個演算法了,
Ⅱ 拓撲排序演算法決議
上面提出的問題的解決思路與 “圖” 這種資料結構的一個經典演算法 “拓樸排序演算法” 有關,那什么是拓撲排序呢?這個概念很好理解,我們來看一個生活中的拓撲排序的例子,
我們在穿衣服的時候都有一定的順序,我們可以把這種順序想成,衣服與衣服之間有一定的依賴關系,比如說,你必須先穿內褲,才能穿外褲,不能反過來,不是每個人都能穿出超人的感覺,
假設我們現在有八件衣服要穿,它們之間的兩兩依賴關系我們已經很清楚了,那如何安排一個穿衣序列,能夠滿足所有的兩兩之間的依賴關系?
這就是個拓樸排序的問題,從這個例子里,你應該能想到,在很多時候,拓撲排序的序列并不是唯一的,你可以看一下下面這張圖,這兩種排序都滿足這些區域先后關系的穿衣序列,

弄懂了生活中的這個例子,你應該對開篇講的編譯依賴關系有思路了,它和這個問題一樣,都可以抽象成一個拓撲排序問題,
拓撲排序的原理非常簡單,我們的重點放在拓撲排序的實作上面,
我們知道,演算法是構建在具體的資料結構上的,針對這個問題,我們先來看看,如何將問題背景抽象成具體的資料結構,
如果 a 先于 b 執行,也就是說 b 依賴于 a,那么就在頂點 a 和頂點 b 之間,構建一條從 a 指向 b 的邊,而且,這個圖不僅要是有向圖,還要是一個有向無環圖,也就是不能存在像 a->b->c->d->a 這樣的回圈依賴關系,因為圖中一旦出現環,拓撲排序就無法作業了,實際上,拓撲排序本身就是基于有向無環圖的一個演算法,
package com.tyz.about_topo.core;
import java.util.LinkedList;
/**
* 構造有向無環圖
* @author Tong
*/
public class Graph {
private int vertex; //頂點數
private LinkedList<Integer> adj[]; //鄰接表
public Graph() {
}
@SuppressWarnings("unchecked")
public Graph(int vertex) {
this.vertex = vertex;
this.adj = new LinkedList[this.vertex];
for (int i = 0; i < vertex; i++) {
this.adj[i] = new LinkedList<Integer>();
}
}
public void addEdge(int start, int end) { //加有向邊
this.adj[start].add(end);
}
public LinkedList<Integer>[] getAdj() {
return adj;
}
public int getVertex() {
return vertex;
}
public void setVertex(int vertex) {
this.vertex = vertex;
}
}
資料結構定義好了,現在我們來看,如何在這個有向無環圖上,實作拓撲排序,
拓撲排序有兩種實作方法,都不難理解,它們分別是 Kahn 演算法 和 DFS 深度優先搜索演算法,我們依次來看看,
A. Kahn 演算法
Kahn 演算法實際上用的是貪心演算法的思想,思路也比較清晰,
定義資料結構的時候,如果 s 需要先于 t 執行,那就添加一條 s 指向 t 的邊,所以,如果某個頂點的入度為 0,也就表示,沒有任何頂點必須先于這個頂點執行,那么這點頂點就可以執行了,
我們先從圖中,找出一個入度為 0 的頂點,將其輸出到拓撲排序的結果序列中(對應代碼中就是把它列印出來),并且把這個頂點從圖中洗掉(也就是把這個頂點可達的頂點的入度都減 1),我們回圈執行上面的程序,直到所有的頂點都被輸出,最后輸出的序列,就是滿足區域依賴關系的拓撲排序,
package com.tyz.about_topo.core;
import java.util.LinkedList;
/**
* 拓撲排序
* @author Tong
*/
public class TopoSort {
private Graph graph; //有向無環圖
private int vertex; //圖的頂點數
public TopoSort(int vertex) {
this.vertex = vertex;
this.graph = new Graph(vertex);
}
/**
* 用 Kahn演算法 實作拓撲排序
*/
public void topoSortByKahn() {
int[] inDegree = new int[this.vertex]; //統計每個頂點的入度
for (int i = 0; i < this.vertex; ++i) {
for (int j = 0; j < this.graph.getAdj()[i].size(); ++j) {
int w = this.graph.getAdj()[i].get(j);
inDegree[w]++;
}
}
LinkedList<Integer> queue = new LinkedList<Integer>();
for (int i = 0; i < this.vertex; ++i) {
if (inDegree[i] == 0) {
queue.add(i);
}
}
while (!queue.isEmpty()) {
int i = queue.remove();
System.out.println("->" + i);
for (int j = 0; j < this.graph.getAdj()[i].size(); ++j) {
int k = this.graph.getAdj()[i].get(j);
inDegree[k]--;
if (inDegree[k] == 0) {
queue.add(k);
}
}
}
}
}
代碼就是根據我們上面說的思路實作的,比較簡單,大家可以做一個參考,
B. DFS 演算法
圖的深度優先搜索演算法在我之前的文章里寫過,有興趣或者有疑惑的同學可以跳轉過去看,
【資料結構與演算法】->演算法->深度優先搜索&廣度優先搜索
實際上,拓撲排序也可以用深度優先搜索演算法來實作,不過這里更準確的說法不是深度優先搜索,而是深度優先遍歷,遍歷圖中的所有頂點,而非只是搜索一個頂點到另一個頂點的路徑,
package com.tyz.about_topo.core;
import java.util.LinkedList;
/**
* 拓撲排序
* @author Tong
*/
public class TopoSort {
private Graph graph; //有向無環圖
private int vertex; //圖的頂點數
public TopoSort(int vertex) {
this.vertex = vertex;
this.graph = new Graph(vertex);
}
/**
* 用 DFS演算法 實作拓撲排序
*/
public void topoSortByDFS() {
@SuppressWarnings("unchecked")
LinkedList<Integer> inverseAdj[] = new LinkedList[this.vertex]; //創建逆鄰接表
for (int i = 0; i < this.vertex; ++i) {
for (int j = 0; j < this.graph.getAdj()[i].size(); ++i) {
int w = this.graph.getAdj()[i].get(j);
inverseAdj[w].add(i);
}
}
boolean[] visited = new boolean[this.vertex];
for (int i = 0; i < this.vertex; ++i) { //深度優先遍歷圖
if (visited[i] == false) {
visited[i] = true;
dfs(i, inverseAdj, visited);
}
}
}
/**
* 遞回實作深度優先遍歷
* @param vertex 當前頂點
* @param inverseAdj 逆鄰接表
* @param visited 頂點狀態
*/
private void dfs(int vertex, LinkedList<Integer> inverseAdj[], boolean[] visited) {
for (int i = 0; i < inverseAdj[this.vertex].size(); ++i) {
int w = inverseAdj[this.vertex].get(i);
if (visited[w] == true) {
continue;
}
visited[i] = true;
dfs(w, inverseAdj, visited);
}
System.out.println("->" + vertex); //輸出完逆鄰接表中這個頂點所達到的所有頂點后輸出自己
}
這個演算法包含兩個關鍵部分,
第一部分是通過鄰接表構造逆鄰接表,鄰接表中,邊 s->t 表示 s 先于 t 執行,也就是 t 要依賴 s,在逆鄰接表中,邊 s->t 表示 s 依賴于 t ,s 后于 t 執行,
第二部分是這個演算法的核心,也就是遞回處理每個頂點,對于頂點 vertex 來說,我們先輸出它可達的所有頂點,也就是說,先把它依賴的所有的頂點輸出了,然后再輸出自己,
大家可以想一下這個邏輯,深度優先遍歷是先找到這個頂點,然后輸出它指向的所有頂點,如果遇到死路再回溯回去,但是如果這樣的話,我們是沒辦法把一個頂點依賴的所有頂點都先輸出來的,但如果我們把鄰接表反過來,我們將一個頂點設定為最后執行的,這樣我們可以通過遞回遍歷找到它所有的子頂點,也就是它依賴的所有頂點,都先輸出完,最后再輸出自己,這樣就可以保證拓撲排序不會出錯,
C. 演算法時間復雜度
現在我們已經了解了 Kahn 演算法和 DFS 演算法求拓撲排序的原理,我們再來看看它們的時間復雜度,
從 Kahn 演算法代碼中可以看出來,每個頂點被訪問了一次,每個邊也都被訪問了一次,所以,Kahn 演算法的時間復雜度就說 O(V+E),V 表示頂點的個數,E 表示邊的個數,
DFS 演算法的時間復雜度在圖的搜索演算法中我詳細分析過,每個頂點被訪問了兩次,每條邊被訪問了一次,所以時間復雜度也是 O(V+E),
需要注意的是,這里的圖可能不是連通的,有可能是好幾個不連通的子圖構成,所以 E 并不一定大于 V,兩者的大小關系不確定,所以,在時間復雜度的表示里,V、E 都要考慮在內,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/102837.html
標籤:其他