前言:
正值金九銀十的黃金招聘期,大家都準備好了嗎?HashMap是程式員面試必問的一個知識點,其內部的基本實作原理是每一位面試者都應該掌握的,只有真正地掌握了 HashMap的內部實作原理,面對面試官的拷問,才不會手忙腳亂,只有經歷面試官的狂轟濫炸才能夠凝練自己的知識,本篇文章結合豐富的圖文形式,將幫助大家理解JDK7 版本的 HashMap基礎及其實作原理,

另外本人整理收藏了20年多家公司面試知識點整理 ,以及各種Java核心知識點免費分享給大家,想要資料的話請點1065653031暗號CSDN,
一、 HashMap介紹

HashMap簡介:
HashMap 是一個散串列,它存盤的內容是鍵值對(key-value)映射,
HashMap 繼承于AbstractMap,實作了Map、Cloneable、java.io.Serializable介面,
HashMap 的實作不是同步的,這意味著它不是執行緒安全的,它的key、value都可以為null,此外,HashMap中的映射不是有序的,
HashMap 的實體有兩個引數影響其性能:“初始容量” 和 “加載因子”,容量 是哈希表中桶的數量,初始容量 只是哈希表在創建時的容量,加載因子 是哈希表在其容量自動增加之前可以達到多滿的一種尺度,當哈希表中的條目數超出了加載因子與當前容量的乘積時,則要對該哈希表進行rehash 操作(即重建內部資料結構),從而哈希表將具有大約兩倍的桶數,
通常,默認加載因子是 0.75, 這是在時間和空間成本上尋求一種折衷,加載因子過高雖然減少了空間開銷,但同時也增加了查詢成本(在大多數 HashMap 類的操作中,包括 get 和 put 操作,都反映了這一點),在設定初始容量時應該考慮到映射中所需的條目數及其加載因子,以便最大限度地減少 rehash 操作次數,如果初始容量大于最大條目數除以加載因子,則不會發生 rehash 操作,
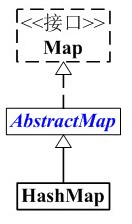
HashMap的繼承關系:

HashMap與Map關系如下圖:
HashMap的建構式
HashMap共有4個建構式,如下:
// 默認建構式,
HashMap()
// 指定“容量大小”的建構式
HashMap(int capacity)
// 指定“容量大小”和“加載因子”的建構式
HashMap(int capacity, float loadFactor)
// 包含“子Map”的建構式
HashMap(Map<? extends K, ? extends V> map)
二、JDK7 中 HashMap 底層原理
HashMap 在 JDK7 或者 JDK8 中采用的基本存盤結構都是陣列+鏈表形式,本節主要是研究 HashMap 在 JDK7 中的底層實作,其基本結構圖如下所示:
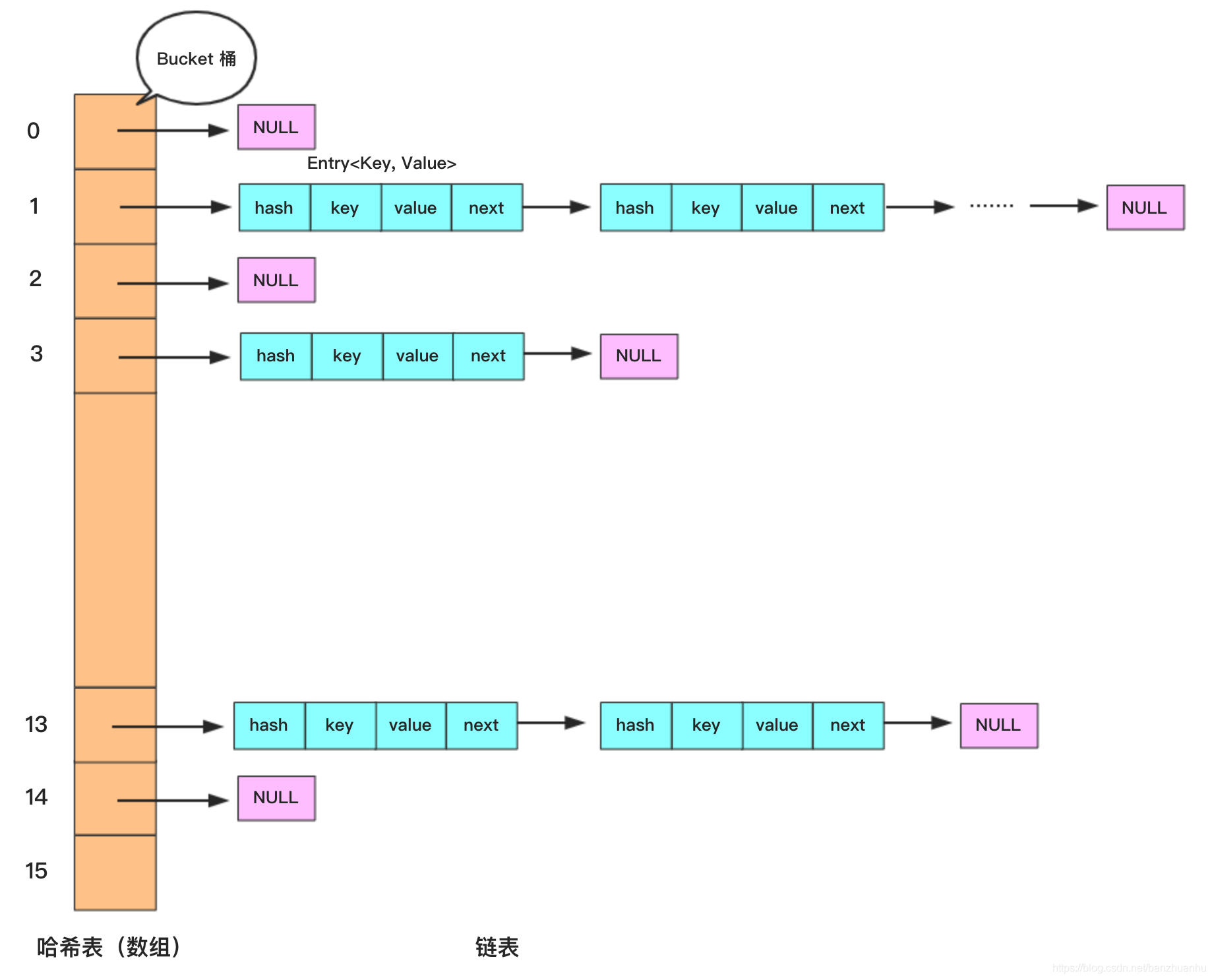
上圖中左邊橙色區域是哈希表,右邊藍色區域為鏈表,鏈表中的元素型別為 Entry,它包含四個屬性分別是:
- K key
- V value
- int hash
- Entry next
那么為什么會出現陣列+鏈表形式的存盤結構呢?這里簡單地闡述一下,我們在使用 HashMap.put(“Key”, “Value”)方法存盤資料的時候,底層實際是將 key 和 value 以 Entry的形式存盤到哈希表中,哈希表是一個陣列,那么它是如何將一個 Entry 物件存盤到陣列中呢?是如何確定當前 key 和 value 組成的 Entry 該存到陣列的哪個位置上,換句話說是如何確定 Entry 物件在陣列中的索引的呢?通常情況下,我們在確定陣列的時候,都是在陣列中挨個存盤資料,直到陣列全滿,然后考慮陣列的擴容,而 HashMap 并不是這么操作的,在 Java 及大多數面向物件的編程語言中,每個物件都有一個整型變數 hashcode,這個 hashcode 是一個很重要的標識,它標識著不同的物件,有了這個 hashcode,那么就很容易確定 Entry 物件的下標索引了,在 Java 語言中,可以理解 hashcode 轉化為陣列下標是按照陣列長度取模運算的,基本公式如下所示:
int index = HashCode(key) % Array.length
實際上,在 JDK 中哈希函式并沒有直接采取取模運算,而是利用了位運算的方式來提高性能,在這里我們理解為簡單的取模運算, 我們知道了對 Key 進行哈希運算然后對陣列長度進行取模就可以得到當前 Entry 物件在陣列中的下標,那么我們可以一直呼叫 HashMap 的 put 方法持續存盤資料到陣列中,但是存在一種現象,那就是根據不同的 Key 計算出來的結果有可能會完全相同,這種現象叫作“哈希沖突”,既然出現了哈希沖突,那么發生沖突的這個資料該如何存盤呢?哈希沖突其實是無法避免的一個事實,既然無法避免,那么就應該想辦法來解決這個問題,目前常用的方法主要是兩種,一種是開放尋址法,另外一種是鏈表法, 開放尋址法是原理比較簡單,就是在陣列里面“另謀高就”,嘗試尋找下一個空檔位置,而鏈表法則不是尋找下一個空檔位置,而是繼續在當前沖突的地方存盤,與現有的資料組成鏈表,以鏈表的形式進行存盤,HashMap 的存盤形式是陣列+鏈表就是采用的鏈表法來解決哈希沖突問題的,具體的詳細說明請繼續往下看, 在日常開發中,開發者對于 HashMap 使用的最多的就是它的構造方法、put 方法以及 get 方法了,下面就開始詳細地從這三個方法出發,深入理解 HashMap 的實作原理,
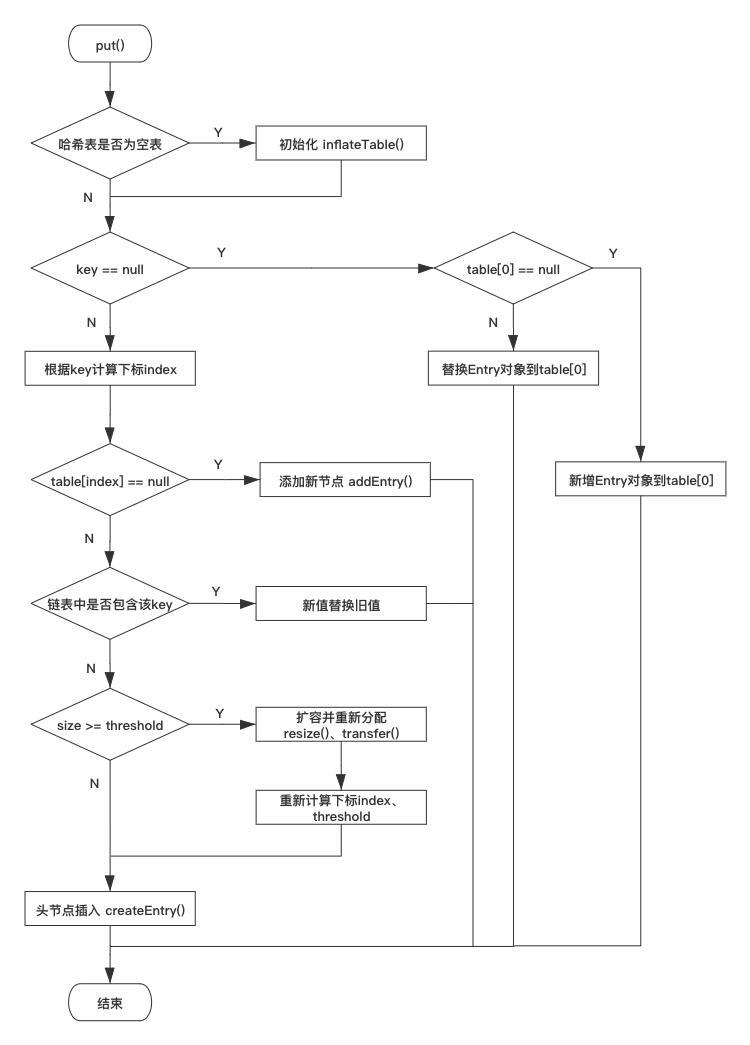
三、HashMap put、get 方法流程圖
這里提供一個 HashMap 的 put 方法存盤資料的流程圖供讀者參考:
這里提供一個 HashMap 的 get 方法獲取資料的流程圖供讀者參考:
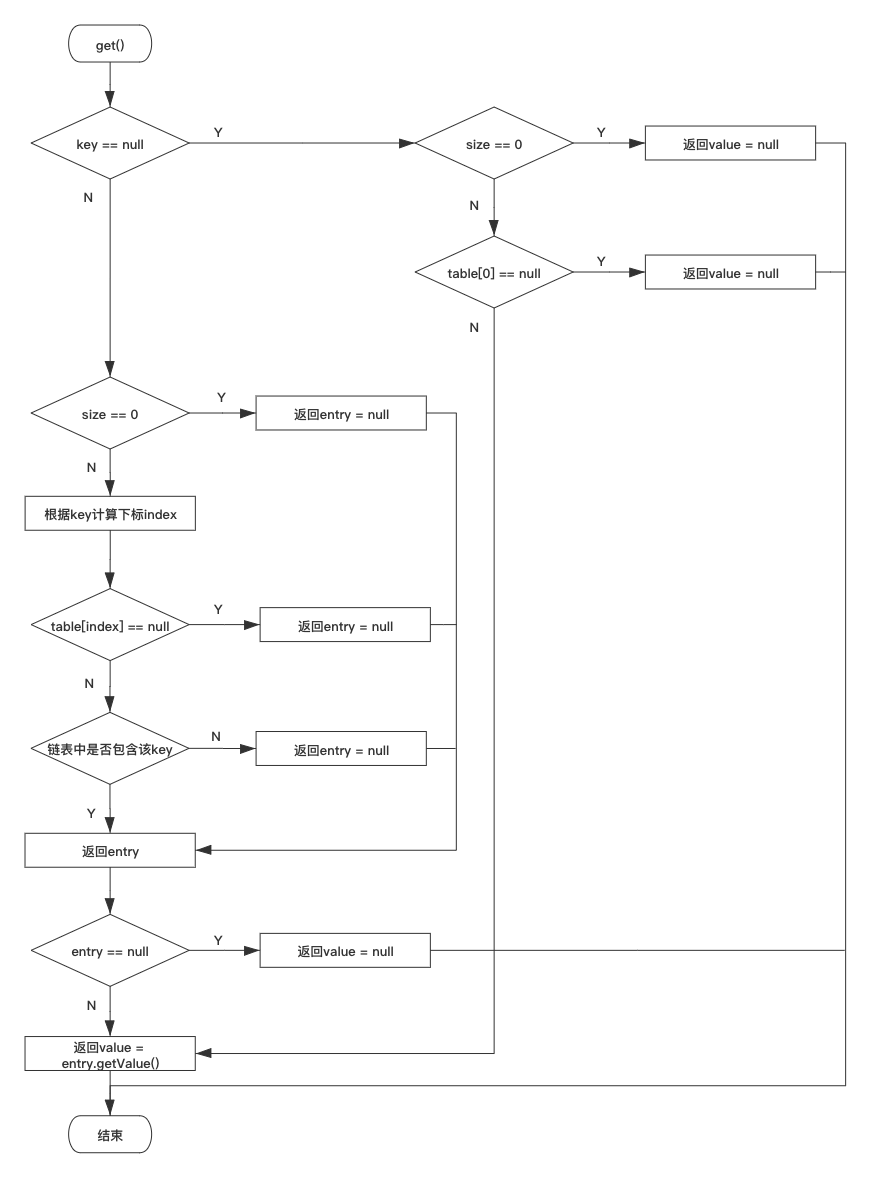
上面中 get 流程圖畫得稍微比正常的要復雜一些,只是為了描述流程更加清晰,
四、常見的 HashMap 的迭代方式
在實際開發程序中,我們對于 HashMap 的迭代遍歷也是常見的操作,HashMap 的迭代遍歷常用方式有如下幾種:
- 方式一:迭代器模式
Map<String, String> map = new HashMap<>(16);
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
- 方式二:遍歷 Set>方式
Map<String, String> map = new HashMap<>(16);
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
- 方式三:forEach 方式(JDK8 特性,lambda)
Map<String, String> map = new HashMap<>(16);
map.forEach((key, value) -> System.out.println(key + ":" + value));
- 方式四:keySet 方式
Map<String, String> map = new HashMap<>(16);
Iterator<String> keyIterator = map.keySet().iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
System.out.println(key + ":" + map.get(key));
}
把這四種方式進行比較,前三種其實屬于同一種,都是迭代器遍歷方式,如果要同時使用到 key 和 value,推薦使用前三種方式,如果僅僅使用到 key,那么推薦使用第四種,
五、總結
本文著重講解了 JDK7 中 HashMap 的具體實作原理,相信讀者仔細品讀以后,對 JDK7 中的 HashMap 的實作會有一個清晰地認識,JDK7 中的 HashMap 的實作原理屬于經典實作,不管 JDK7 是否已經再被使用,但是其基本原理還是值得學習!后續將繼續講解 JDK8 中的 HashMap實作原理,屆時將對比 JDK7,幫助讀者掌握兩者之間的共性和差異!
另外本人整理收藏了20年多家公司面試知識點整理 ,以及各種Java核心知識點免費分享給大家,想要資料的話請點1065653031暗號CSDN,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/104218.html
標籤:其他
上一篇:關于寫51單片機庫的問題