Manacher(馬拉車演算法)
序言
mannacher 是一種在 O(n)時間內求出最長回文串的演算法
我們用暴力求解最長回文串長度的時間復雜度為O(n3)
很明顯,這個時間復雜度我們接受不了,這時候,manacher也就是俗稱的馬拉車演算法就出世了
演算法描述
先考慮一種在O(n2)的時間復雜度內求解的演算法
我們可以從左到右列舉字串的每一個字符,以當前字符為起點,向左,和向右同事延伸來求解
回文長度,但我們深入分析一下,發現,這個演算法明顯是有漏洞的,它只能解決字串長度為
為奇數的回文長度,偶數的字串無法由它求出回文長度,
比如aba用該演算法求出的值為3是正確的,但abba用該演算法求出的值卻是1,很明顯,是錯誤的,那么我們考慮,
如何去優化該演算法,使得奇數和偶數都能解決,我們考慮在字串的首尾和字符
串間隔中插入一個特殊字符如\(,例如abba,插入后就變為了\)a\(b\)b\(a\)字串的長
度由n變為了2n+1這樣就可以保證字串的長度為奇數了,證明很簡單,2n定為偶數
則2n+1一定為奇數然后便可以通過上述演算法求出目前的回文長度了,
但,n2 的演算法仍然無法滿足我們的需求,我們考慮繼續優化,那么如何優化呢?
我們需要引入幾個定義
下述定義用未插入特殊字符的字串進行解釋
1:回文中心,即一回文串的中心字符比如abcba這個回文串,從左向右數的第3個字符即c
便為其回文中心我們因為我們對字串進行了處理,所以便保證了每一串都有其回文中心
2,回文半徑,即回文串的最右邊界到回文中心的字符個數(包含回文中心)
我們可以發現,每個串的回文半徑的長度*2-1便是所求回文串的長度
所以,我們只要求出那個最大的回文半徑便可得到最長回文串長度
那么,我們如何求解呢?
manacher演算法的本質便是對上面所提的n2的優化
我們看下圖,假設我們目前列舉到i,定義r為到目前為止的回文串的最右邊界,即目前為止的所
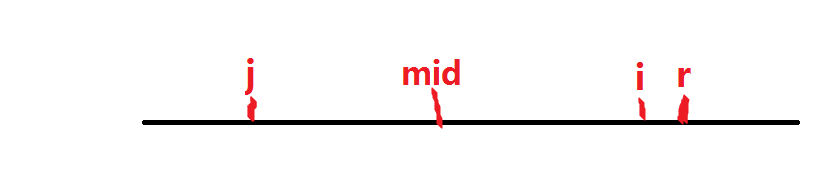
有回文串中,最右的字符下標最大的那個下標;mid則為 r 所在回文串的回文中心
我們對i進行討論
當i<r時因為i位于以mid為回文中心的回文串中,所以以i為回文中心的字串有可能被以mid
為回文中心的字串包含,假設被包含,我們利用回文串的對稱性可知,以i關于mid的對稱點也就是j點
為回文中心的字符半徑等于以i為半徑的回文半徑
我們直接賦值即可
定義p陣列為回文半徑長度
那么我們如何判斷呢?當r-i的長度要大于p [j] 時,p[j]一定沒有超過mid的范圍,那么,我們直接對稱過去更新p[i]即可
反之,當r-i>r-i 表明p[j]有可能包含mid范圍之外的數,我們無法將p[j]賦給p[i]便在范圍內將r-i賦給p[i];
本質融合成一句代碼便是
p[i]=p[mid*2-i]>mir-i?mir-i:p[mid*2-i];
我們求j的下標利用中點坐標公式求解即可
貼一發代碼
#include<iostream>
#include<cstring>
#include<string>
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn =2e7+10;
char s[maxn];
char ns[maxn];
int p[maxn];
int getle(){
int len=strlen(s);
int j=2;
ns[0]='~';//設定列舉邊界,字串右側帶有換行,所以我們右側不必放字符了
ns[1]='$';
for(int i=0;i<len;i++){
ns[j++]=s[i];
ns[j++]='$';
}
return j;
}
int manacher(){
int len=getle();
int mid=1;
int mir=1;
int ans=-1;
for(int i=1;i<len;i++){
if(mir>=i){
p[i]=p[mid*2-i]>mir-i?mir-i:p[mid*2-i];
}
else{
p[i]=1;
}
while(ns[i+p[i]]==ns[i-p[i]]){
p[i]++;
}
if(p[i]+i>mir){
mid=i;
mir=p[i]+i;
}
ans=max(p[i]-1,ans);
}
return ans;
}
int main(){
cin>>s;
cout<<manacher();
return 0;
}
完結撒花
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/106357.html
標籤:其他