在前面的文章中介紹了平均數和資料的尺度,但僅僅通過它們來描述資料是不夠的,還需要通過更多的度量描述資料,
測度中心
上一章已經介紹過測度中心(measure of center),測度中心也被稱為資料平衡點,能夠在某種程度上對資料進行概括,
測度中心雖然是描述資料的一種簡便的方法,但它存在有很多局限性,下表是兩個籃球運動員在上個月比賽的得分:
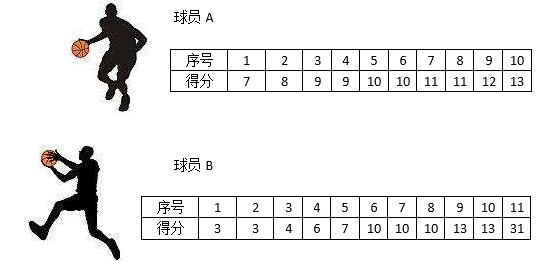
得分表中有意識地將得分從低到高排序,下面的代碼計算了A和B的均值和中位數:
1 import numpy as np 2 3 A = [7, 8, 9, 9, 10, 10, 11, 11, 12, 13] 4 B = [3, 3, 4, 6, 7, 10, 10, 10, 13, 13, 31] 5 mu_A, mu_B = np.mean(A), np.mean(B) # 均值 6 median_A, median_B = np.median(A), np.median(B) # 中位數 7 print('mu_A = {}, mu_B = {}'.format(mu_A, mu_B)) # mu_A = 10.0, mu_B = 10.0 8 print('median_A = {}, median_B = {}'.format(median_A, median_B)) # median_A = 10.0, median_B = 10.0
均值A的描述較為恰當,但是B就不一定了,B的離群資料過多,這些資料將極大地影響均值,雖然中位數受離群資料影響較小,但仍不能完整地描述B的特性,此時我們需要尋求資料的其它指標,
資料的距
資料的全距
測度中心用于量化資料的中心,資料的全距則用于量化資料的離散程度,
全距的計算方式很簡單,使用資料的最大值減去最小值,僅此而已,它只是對資料離散程度極其基本的描述,
1 A = [7, 8, 9, 9, 10, 10, 11, 11, 12, 13] 2 B = [3, 3, 4, 6, 7, 10, 10, 10, 13, 13, 31] 3 range_A, range_B = max(A) - min(A), max(B) - min(B) # 全距 4 print('range_A = {}, range_B = {}'.format(range_A, range_B)) # range_A = 6, range_B = 28
資料的最小值和最大值分別是全距的下界和上界,二者間的距離就是資料的全距:

全距是由資料的極值計算得出的,僅僅度量了資料的寬度,并且不能指出資料是否包含了例外值,因此全距的使用場景十分有限,很多時候使用全距僅僅是因為它很簡單,
全距有一些典型的使用場景:在演算法分析時,雖然我們用大O表示法表達演算法在平均情況下的效率,但是我們對演算法在最好和最差情況的效率依然有很大的興趣;在軟體專案的任務評估時,一個重要的指標是“最壞情況下的完成時間”,畢竟專案進度并不總是那么令人歡欣鼓舞,如此看來,全距并不是那么一無是處,
四分位距
首先要明確的是,四分位和四分衛沒有半點關系,

既然全距很容易受例外值影響,那么忽略例外值不就可以了嗎?對于B球員來說,可以忽略狀態及佳和極差的得分,現在又來了球員C,他的得分情況:
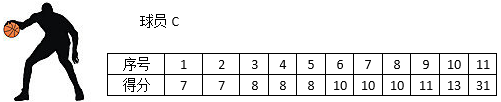
31分遠遠高出了其他場次,因此忽略31分,現在問題產生了,B球員和C球員采用了不同的例外值忽略方式——B忽略了最低分,而C沒有,比較使用不同方式處理的資料,是資料分析的大忌,
忽略例外值的一種較好的方式是使用四分位距,首先將資料排序,然后將資料等分為4份:
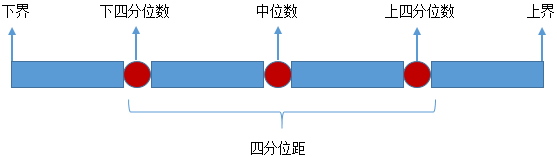
從分布上看,四分位距保留了中間靠近均值的50%的資料:
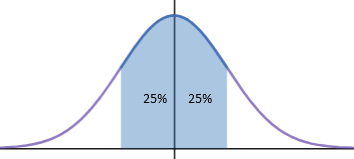
用統一的標準去除了兩組資料的例外值,
下四分位數和上四分位數的計算方法和中位數類似,資料集有n個資料,對于下四分位數來說,如果n/4是整數,則下四分位數是n/4位置和n/4 + 1位置的兩個數的平均值;如果n/4不是整數,向上取整,該位置的數就是下四分位數,對于上四分位數來說,如果3n/4是整數,則下四分位數是3n/4位置和3n/4 + 1位置的兩個數的平均值;如果3n/4不是整數,向上取整,該位置的數就是下四分位數,
球員B共有11個得分,11÷4=2.75,向上取整,下四分位數是資料集中的第3個,下四分位數是4;用11×3÷4=8.25,向上取整,上四分位數是資料集中的第9個,下四分位數是13,該球員的四分距是13 – 4 = 9,

1 A = [7, 8, 9, 9, 10, 10, 11, 11, 12, 13] 2 B = [3, 3, 4, 6, 7, 10, 10, 10, 13, 13, 31] 3 lower_A = np.quantile(A, 1/4, interpolation='lower') # 下四分位數 4 higher_A = np.quantile(A, 3/4, interpolation='higher') # 上四分位數 5 lower_B = np.quantile(B, 1/4, interpolation='lower') 6 higher_B = np.quantile(B, 3/4, interpolation='higher') 7 print('lower_A = {}, higher_A = {}'.format(lower_A, higher_A)) # lower_A = 9, higher_A = 11 8 print('lower_B = {}, higher_B = {}'.format(lower_B, higher_B)) # lower_B = 4, higher_B = 13
當然,你也可以把資料分成任意塊,比如分成100塊,這對于劃分名次很有用,假設某個學生的高考成績是600分,單從成績無法知道好壞,但如果說這一年高考的第90個百分數是590分,則可以知道這個考生的分數超過了90%以上的學生,
箱形圖
我們經常看到箱形圖:
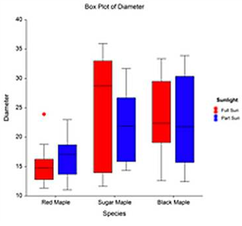
知道了四分位數和四分位距,就不難理解箱形圖:
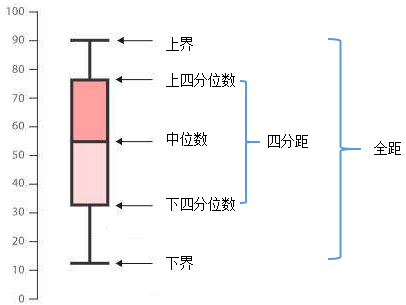
箱形圖同時顯示了資料的全距、四分距和中位數,通過箱形圖可以了解資料的偏斜程度,
1 import matplotlib.pyplot as plt 2 plt.boxplot([A, B], labels = ['player A', 'playerB']) # 箱形圖 3 plt.show()
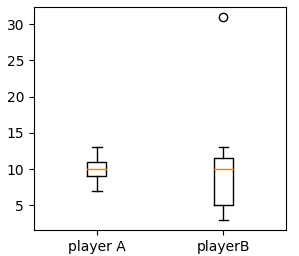
playerB上面還有一個小圓圈,它表示例外值,B球員得31分那場比賽被判定為異常值,箱形圖自動將它剔除了,
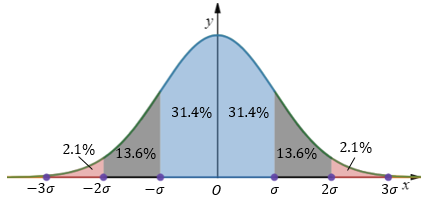
在正態分布的假設下,μ-3σ<=x<=μ+3σ的區域包含了絕大部分資料,該區域之外的資料被認為是例外的(更多資訊可參考:https://mp.weixin.qq.com/s/DgiLzv5sOAS7JeUDk-6fLA):
對于箱形圖來說,設lower是下四分位數,heigher是上四分位數,range是四分位距,x是某個資料樣本,則下面的的不等式判斷x是否是例外值:
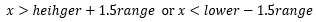
對于B球員來說:
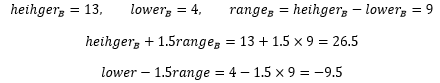
處于-9.5或26.5之外的數值是31,因此31被判定為例外資料,
再談標準差
方差、均方差和協方差(概率8)中已經討論過標準差,它衡量了資料的波動程度,即量化資料點偏離均值的程度,通過下面的代碼計算兩個球員的標準差:
1 A = [7, 8, 9, 9, 10, 10, 11, 11, 12, 13] 2 B = [3, 3, 4, 6, 7, 10, 10, 10, 13, 13, 31] 3 sigma_A, sigma_B = np.std(A), np.std(B) # 標準差 4 print('σ_A = {}, σ_B = {}'.format(sigma_A, sigma_B)) # σ_A = 1.7320508075688772, σ_B = 7.49545316720865
球員A的標準差表示A樣本資料的離散程度,可以認為σA近似于A中所有資料點與均值間距離的平均值,樣本越分散,遠離均值的樣本越多,標準差越大,標準差是有單位的,其單位和計算標準差的資料單位一致,A的標準差是球員的得分數,
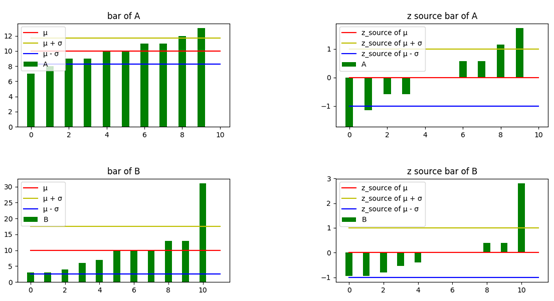
可以通過柱狀圖觀察資料和標準差的關系:
1 def add_bar(data, mu, sigma, name): 2 ''' 3 添加柱狀圖 4 :param data: 資料集 5 :param mu: 均值 6 :param sigma: 標準差 7 :param name: 資料集名稱 8 ''' 9 length = len(data) 10 plt.bar(left=range(length), height=data, width=0.4, color='green', label=name) 11 plt.plot((0, length), (mu, mu), 'r-', label='均值') # 均值線 12 plt.plot((0, length), (mu + sigma, mu + sigma), 'y-', label='均值+標準差') # 均值線 13 plt.plot((0, length), (mu - sigma, mu - sigma), 'b-', label='均值-標準差') # 均值線 14 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽 15 plt.legend(loc='upper left') 16 plt.title('bar of ' + name) 17 18 fig = plt.figure() 19 fig.add_subplot(1, 2, 1) 20 add_bar(A, mu_A, sigma_A, 'A') 21 fig.add_subplot(1, 2, 2) 22 add_bar(B, mu_B, sigma_B, 'B') 23 plt.show()
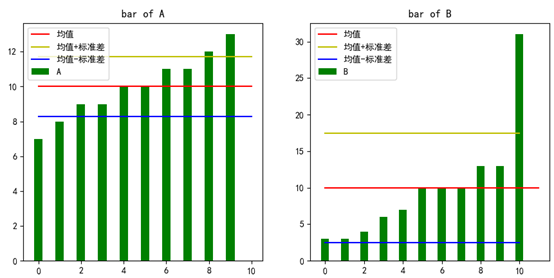
中間紅線是均值,黃線和藍線分別表示均值加減標準差,標準差越大,黃線和藍線之間的距離也越大,說明資料的離散程度越大,在兩條線之外的資料被認為是離群資料,
變異測度
測度中心和標準差都可以描述資料集的特征,二者都是有單位的,如果想要比較兩個不同的資料集,特別對不同尺度的資料集進行橫向比較,就需要有一種方式去掉單位,
變異系數(coefficient of variation)是標準差和均值的比率,二者相除去掉了單位,并對標準差進行了標準化處理,這種測度也稱為變異測度,
假設下表是NBA中鋒和控球后衛的身高資料:

可以看到,中鋒的平均身高較高,但變異系數只有2.4%,說明作為球隊中最高大的隊員,各中鋒之間的身高差距不大,控球后衛雖然平均身高更接近普通人,但變異系數是8.0%,說明各球隊控球后衛的身高差異也較為明顯,該位置對身高的要求相對較弱,
z分數(z-scorce)
z分數也稱相對分數,用于描述單個資料點和均值之間的距離,資料點和z分數的計算方法是:
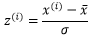
x(i)表示第i個資料點,σ是樣本的標準差,帶上帽子的x是均值,
標準差近似于所有資料點與均值間距離的平均值,z分數是單個資料點和均值間的距離,更確切地說,是標準化后單個資料點和均值間的距離,
1 z_source_A = (np.array(A) - mu_A) / sigma_A 2 z_source_B = (np.array(B) - mu_B) / sigma_B 3 print('z_source_A =', z_source_A) 4 print('z_source_B =', z_source_B)
z_source_A = [-1.73205081 -1.15470054 -0.57735027 -0.57735027 0. 0. 0.57735027 0.57735027 1.15470054 1.73205081]
z_source_B = [-0.9338995 -0.9338995 -0.80048529 -0.53365686 -0.40024264 0. 0. 0. 0.40024264 0.40024264 2.80169851]
對于的z分數來說,均值的z分數是0,均值加標準差的z分數是1,均值減標準差的z分數是-1:
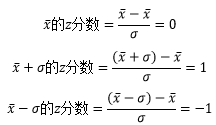
1 def add_z_bar(z_source, name): 2 ''' 添加z_source柱狀圖 ''' 3 length = len(z_source) 4 plt.bar(left=range(length), height=z_source, width=0.4, color='green', label=name) 5 plt.plot((0, length), (0, 0), 'r-', label='z_source of μ') 6 plt.plot((0, length), (1, 1), 'b-', label='z_source of μ') 7 plt.plot((0, length), (-1, -1), 'y-', label='z_source of μ') 8 9 plt.title('bar of ' + name) 10 fig = plt.figure() 11 # plt.subplots_adjust(wspace=0.5, hspace=0.5) 12 fig.add_subplot(2, 1, 1) 13 add_z_bar(z_source_A, 'z source of A') 14 fig.add_subplot(2, 1, 2) 15 add_z_bar(z_source_B, 'z source of B') 16 plt.show()
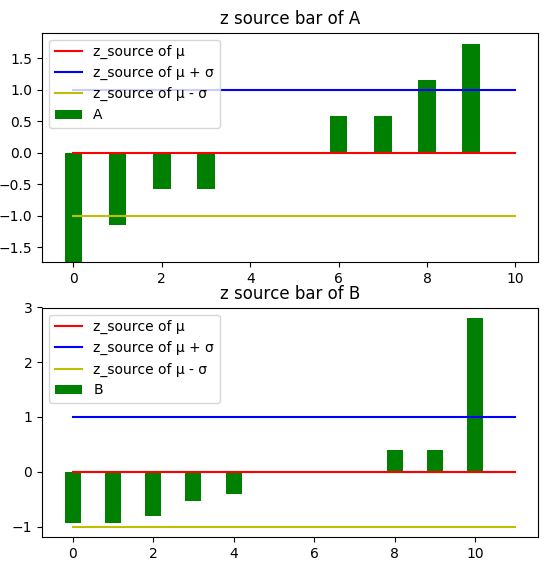
低于均值的資料,z分數是負值;高于均值的資料,z分數是正值;等于z分數的資料,均值為0,下圖可以看出z分數和均值的關系:
相關系數
相關系數是描述兩個變數間關聯性強弱的量化指標,資料的各個特征之間存在關聯關系是機器學習模型的重要假設,預測能夠成立的原因正是由于特征間存在某種相關性,
相關系數的值介于-1到1之間,兩個特征間的關系越強,相關系數越接近±1;關系越若,越接近0,接近+1,表示一個指標增加了,另一個也隨之增加;接近-1,表示一個指標增加了,另一個指標將降低,
成年男性的腳長約等與身高的1/7,下面的代碼生成了200個身高和腳長的正態分布資料:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 import pandas as pd 4 5 def create_data(count=200): 6 ''' 7 構造2維訓練集 8 :param model: train:訓練集, test:測驗集 9 :param count: 樣本數量 10 :return: X1:身高維度的列, X2:腳長維度的串列 11 ''' 12 np.random.seed(21) # 設定seed使每次生成的亂數都相等 13 X1 = np.random.normal(1.7, 0.036, count) # 生成200個符合正態分布的身高資料 14 low, high = -0.01, 0.01 15 # 設定身高對應的腳長,正常腳長=身高/7±0.01 16 X2 = X1 / 7 + np.random.uniform(low=low, high=high, size=len(X1)) 17 return X1, X2 18 19 X1, X2 = create_data() 20 df = pd.DataFrame({'height':X1, 'foot':X2}) 21 print(df.head()) # 顯示前5個資料
height foot
0 1.698129 0.250340
1 1.695997 0.233121
2 1.737505 0.247780
3 1.654757 0.238051
4 1.726834 0.241137
身高和腳長的維度不同,1厘米對于身高來說相差不大,但對于腳長來說就很大了,為了尋找關聯關系,需要對兩個維度進行標準化處理,將二者壓縮到統一尺度,
1 from sklearn import preprocessing 2 3 # 使用z分數標準化 4 df_scaled = pd.DataFrame(preprocessing.scale(df), columns=['height_scaled', 'foot_scaled']) 5 print(df_scaled.head())
sklearn的preprocessing使用了z分數標準化,結果如下:
height_scaled foot_scaled
0 -0.051839 0.959658
1 -0.110551 -1.389462
2 1.032336 0.610501
3 -1.246054 -0.716968
4 0.738525 -0.295843
現在可以看看兩個維度的相關系數:
corr = df_scaled.corr() # 兩個維度的相關系數 print(corr)
height_scaled foot_scaled
height_scaled 1.000000 0.614949
foot_scaled 0.614949 1.000000
這個結果告訴我們,身高和腳長關聯關系,由于corr()分析的是線性相關,因此即使相關系數為0,也不能明兩個特征間沒有關系,只能說不存在線性關系,
作者:我是8位的
出處:https://mp.weixin.qq.com/s/ysMdUdcAk9BuXNH9bvqOBg
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/107582.html
標籤:其他
上一篇:心率傳感器 SC7R30資料尋求