自上周完成任務后還沒安排新的任務,煩(qie)躁(xi),
今天打算安排兩篇博客,這是第一篇,另一個是由這個再做的索引案例
一:前期準備
1、使用的還是之前的資料庫,采用CopySQLTableData表、HierarchyDepartment表 :
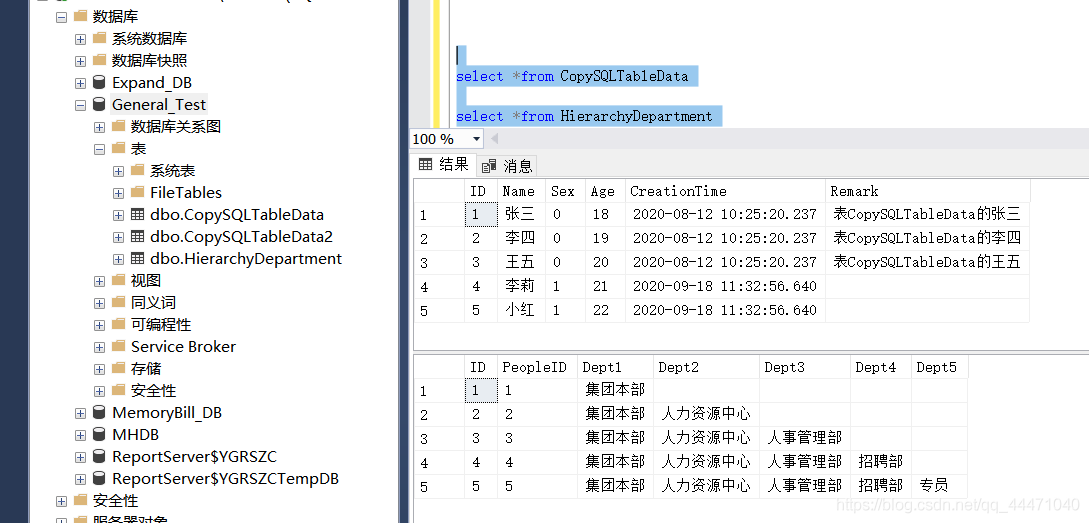
2、我需要對表CopySQLTableData進行批量新增
二:實踐
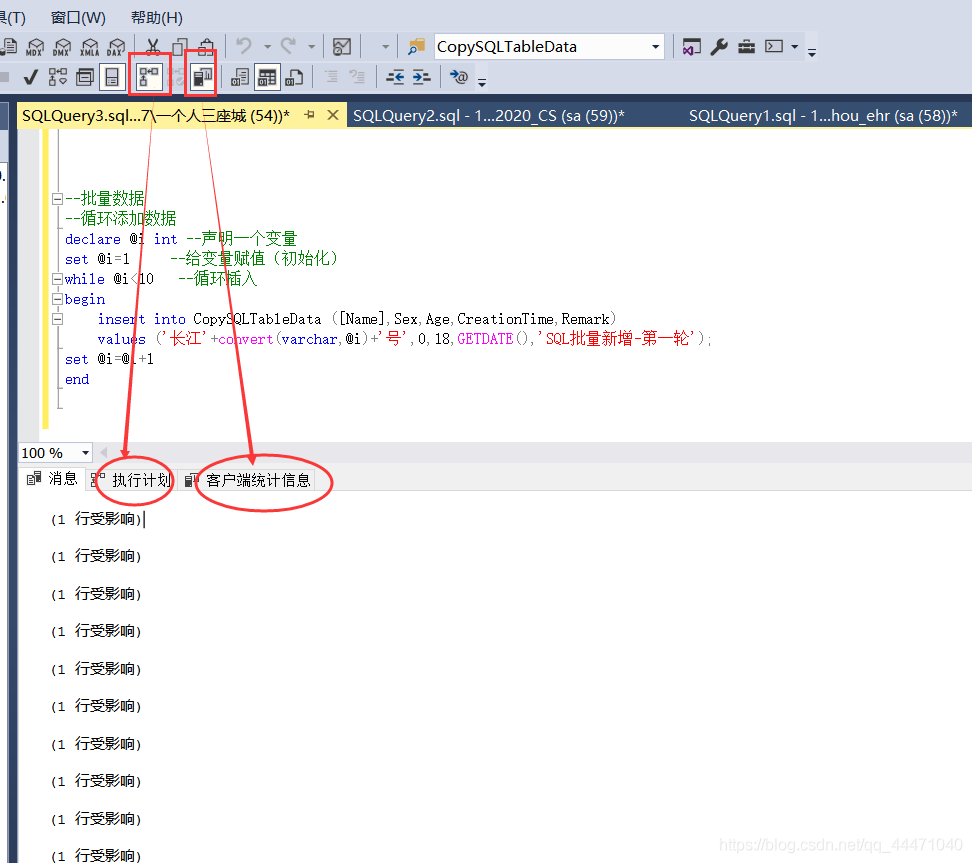
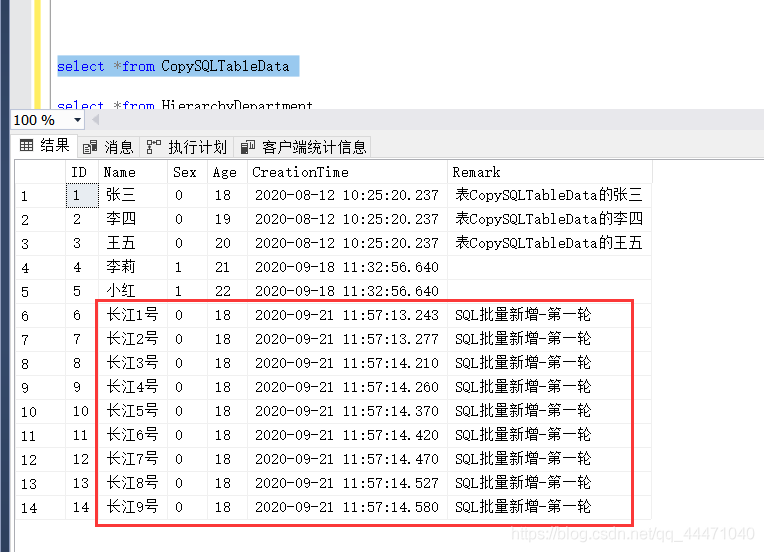
1、先測驗新增9條,就執行速度來說,感覺上過了3s,也就是1秒3條,(這個比例可以去具體理解)這里我們也打開了兩個按鈕,后邊看下具體情況
咱可愛的七仔大軍準備出擊,加上永遠18的我們
--批量資料
--回圈添加資料
declare @i int --宣告一個變數
set @i=1 --給變數賦值(初始化)
while @i<10 --回圈插入
begin
insert into CopySQLTableData ([Name],Sex,Age,CreationTime,Remark)
values ('長江'+convert(varchar,@i)+'號',0,18,GETDATE(),'SQL批量新增-第一輪');
set @i=@i+1
end
GO
2、先看下執行計劃,這里9條insert陳述句平攤了開銷,這很容易理解
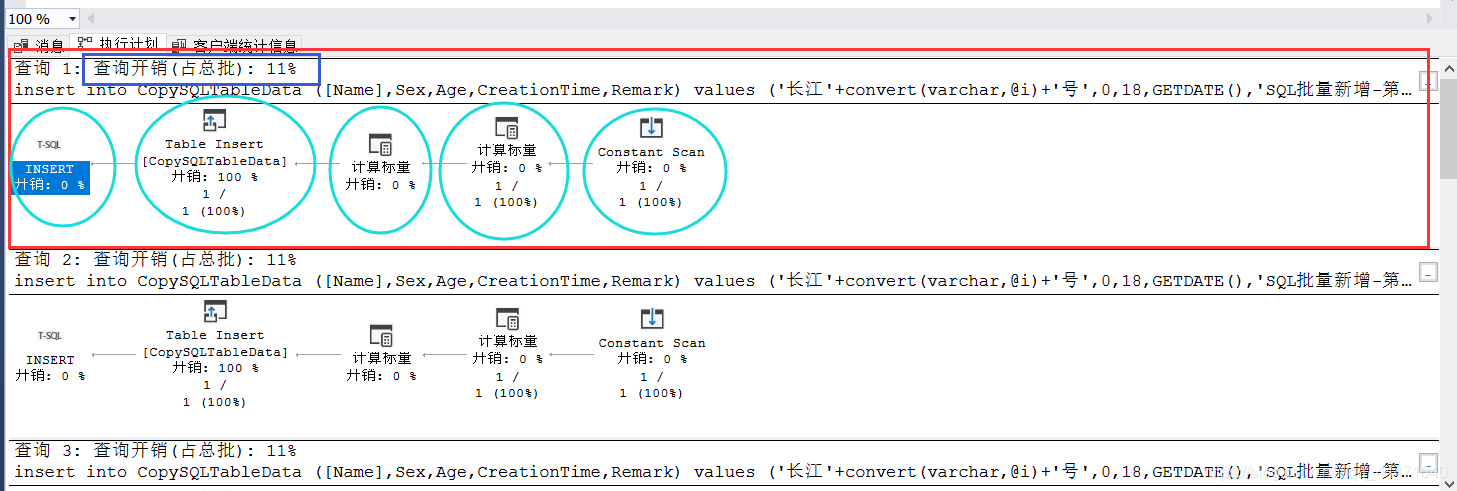
3、我們主要看的是這I/O、CPU的開銷
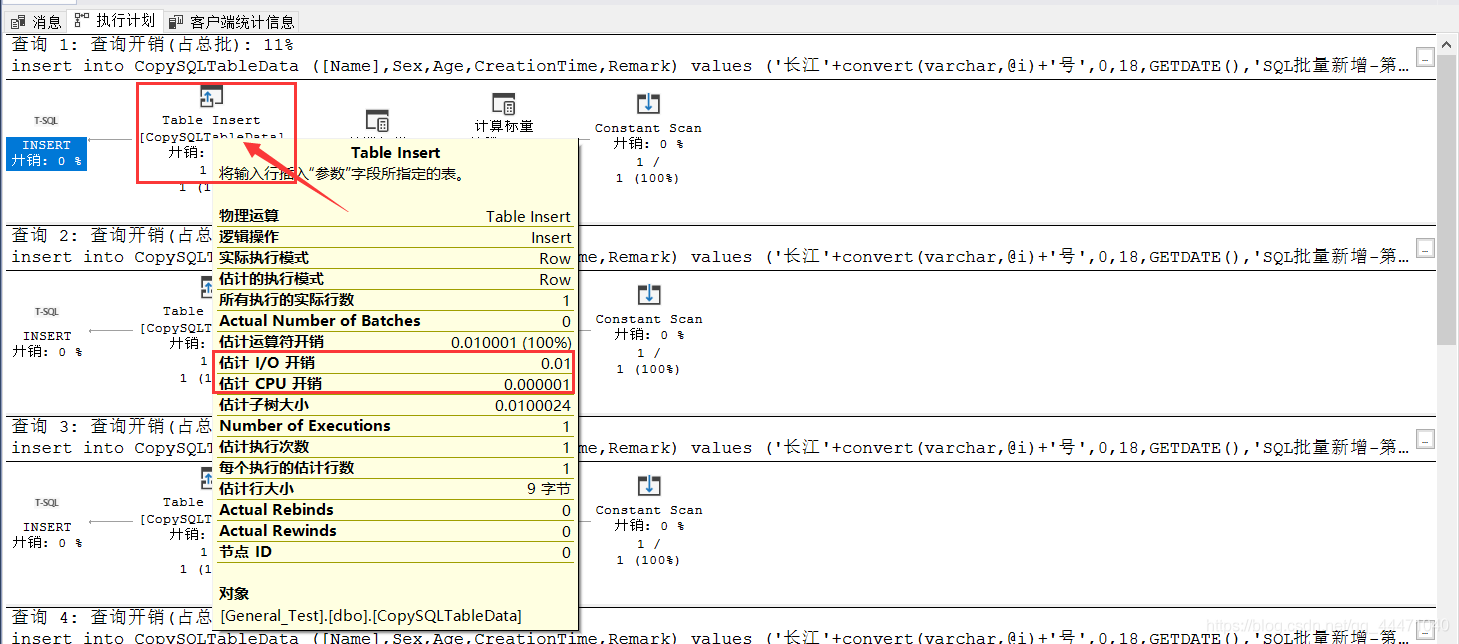
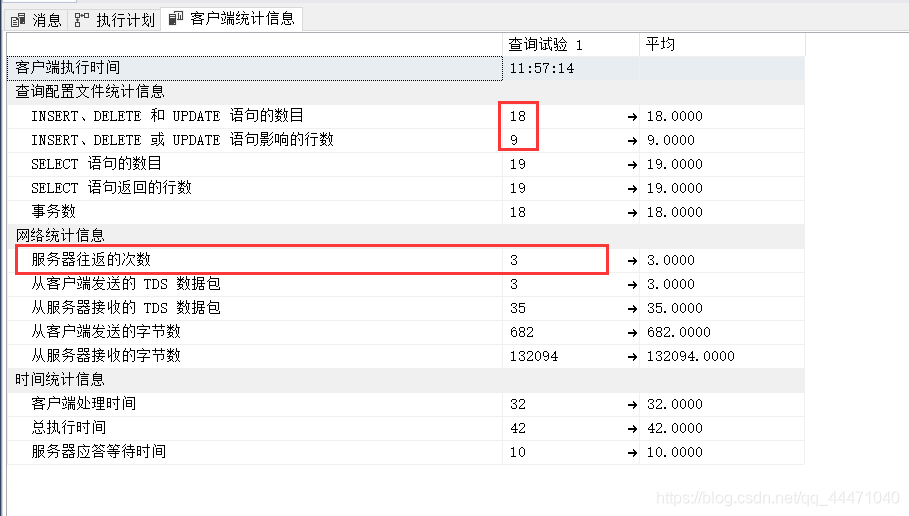
4、再看下另一個 客戶端統計資訊,這我們需要知道并容易理解的是這三個,其他無意義,也有不懂的…,18呢是insert的9條加@i的賦值;9呢就是insert的影響;再下邊的19我估計是18+9+@i初始化;最后的3,應是三次握手(有誤請指正![一本正經.jpg])
另外,這個查詢試驗1的表頭,表示第一次執行的資料,假如我把之前的代碼再執行一次,會有查詢試驗2,資料上也有對比,下邊再看吧
5、閑話也聊完了,看下結果吧
三:測驗完,進行正式的大批量回圈insert,這次我們添加百萬
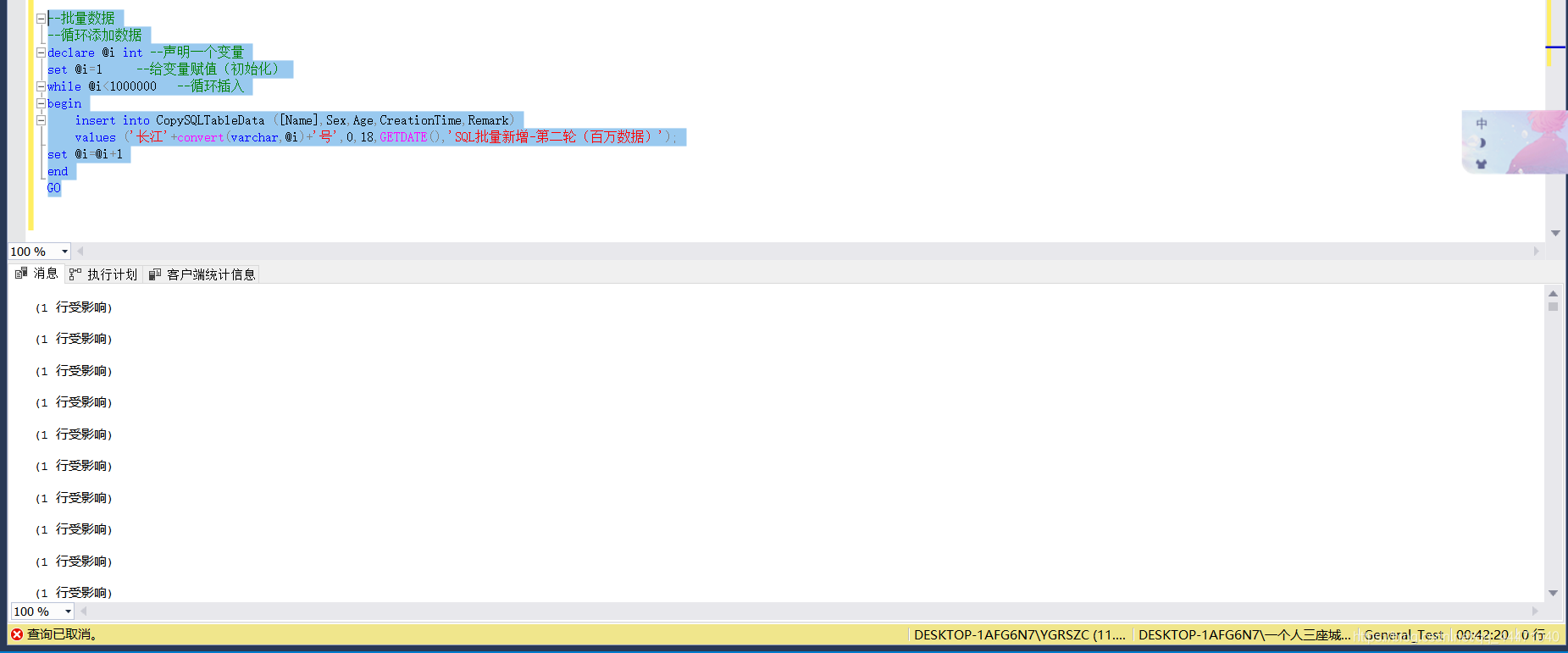
1、執行了42分鐘,我還是等不下了…我都要困了

這執行的,CPU占比都到16-17了(I7-9750H,6核心12執行緒),停止后只有0.1-0.3的占比…這等資料量的做法平常還是不要隨便弄了,(期間我切換到資料庫都有十幾秒的卡頓)
讓我們看下這次執行insert了多少資料吧
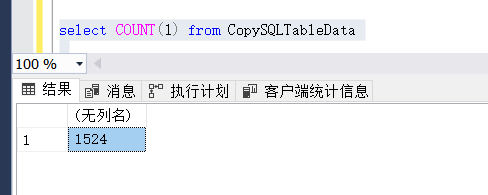
…有點小奔潰,才1.5k???有沒有搞錯(平均一秒2條的速度了…[淚奔.gif])
2、尋找問題
看下執行的客戶端
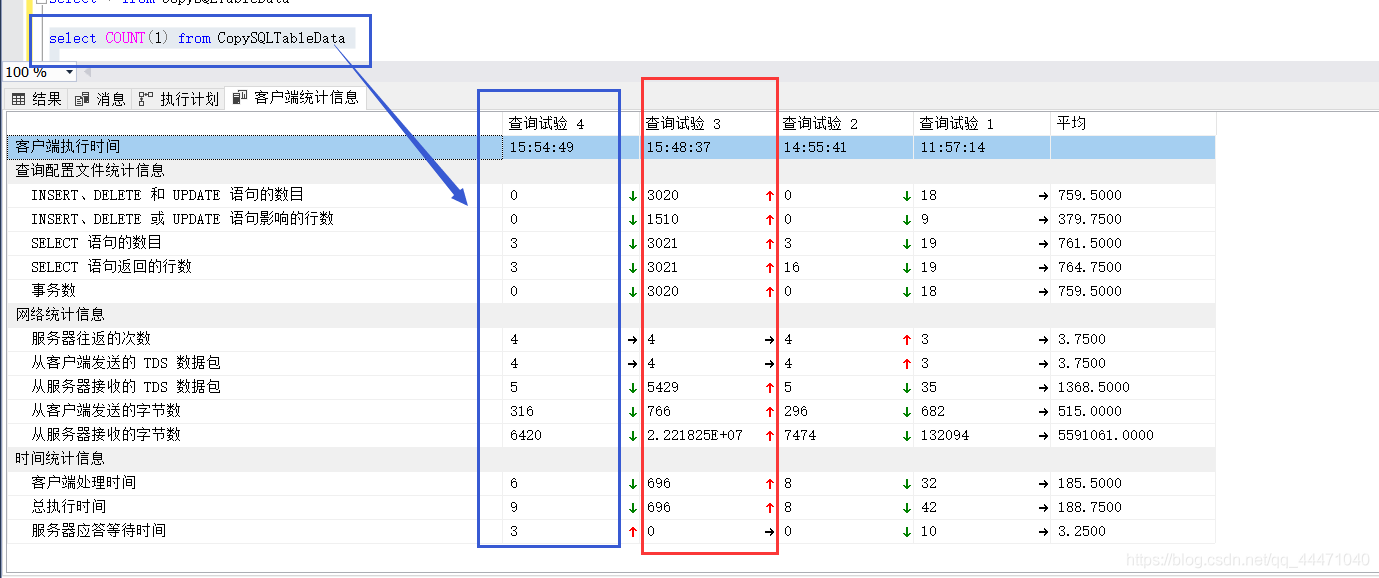
藍色的是執行COUNT函式的,紅色的就是我們新增的資料了,還是是在不敢相信才這么點,I/O效率太低了,得安排個高效率的做法
3、看下資料添加進入的時間
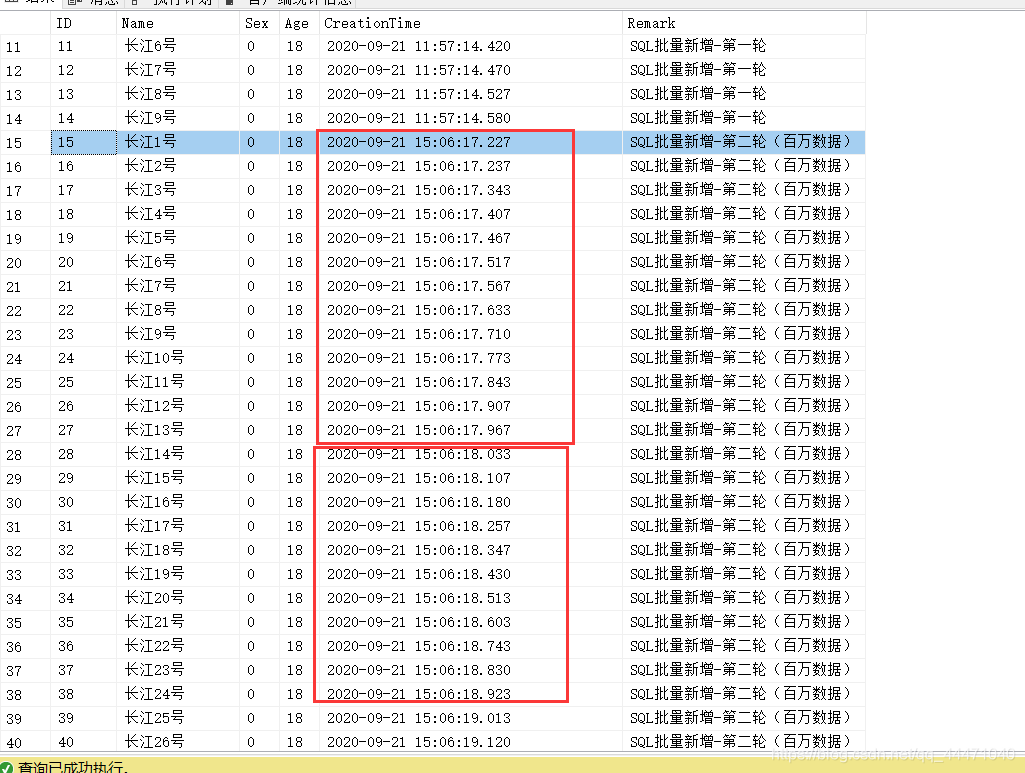
可以看到,剛開始的速度還是可以的,一秒insert了10來條資料,但是18秒又少了
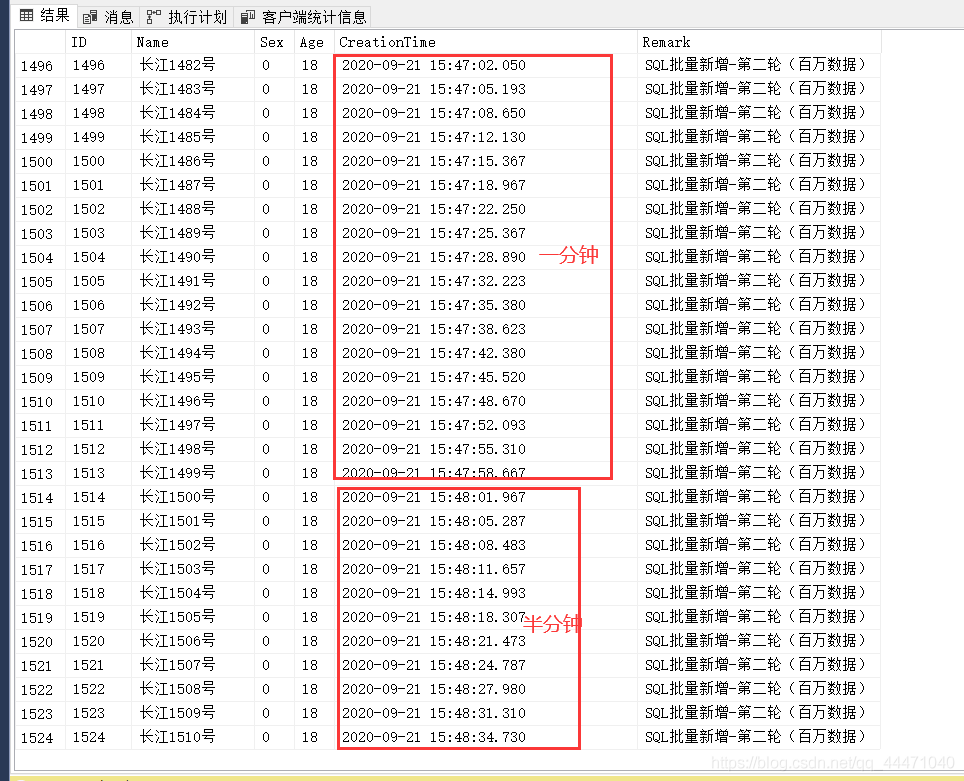
以至于到后期的一分鐘不如前2秒insert的條數,理論不應該這樣啊,
4、是資料庫限制了什么東西了么??
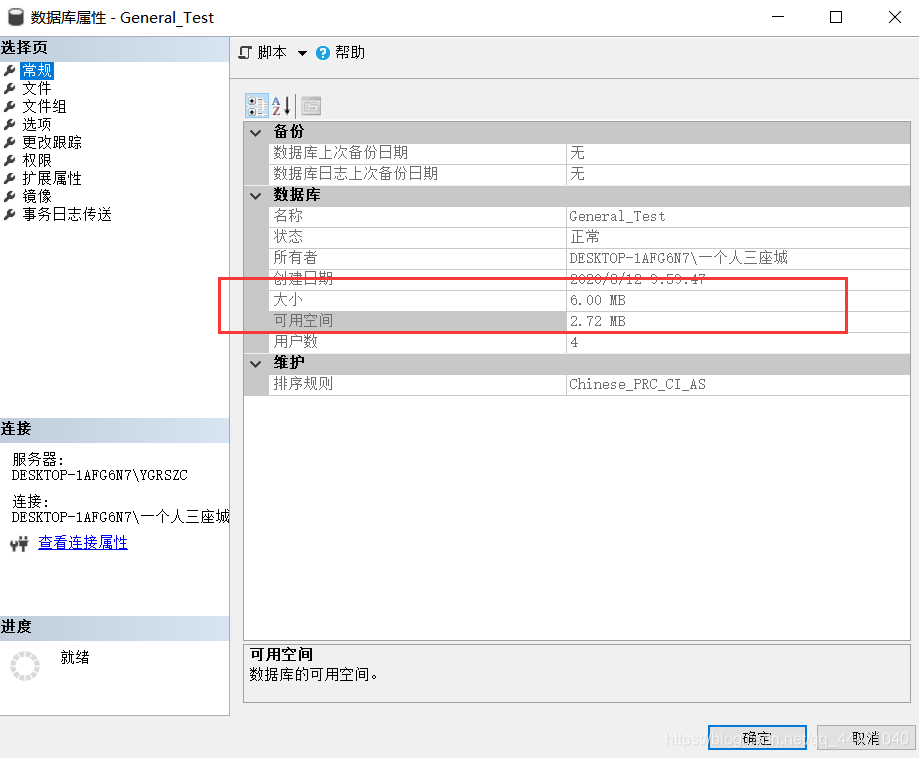
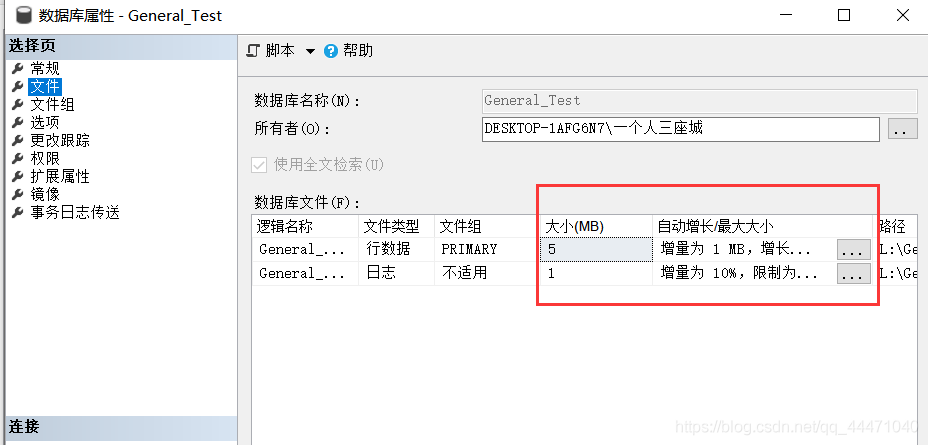
也不知道是不是這一塊的問題,,有大佬路過的幫忙看看[拜托拜托][拜托拜托]
四、尋找新方法
待續…意外的問題,我得去解決下,再補充了[狗頭保命]
索引的博客也延遲到百萬資料正式新增進去后再寫了
加油ヾ(?°?°?)ノ゙

這是一個失敗的方法,但是一篇成功的博客,讓我認識到了理論與實踐的差距
實踐是檢驗真理的唯一標準 !!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/107825.html
標籤:其他
下一篇:【面試題】MySQL的鎖機制