第四個專案比較簡單和有趣,因為它的資料集全部都是分型別特征,在這種情況下,我們又應該怎么做呢,在這里給大家分享一個比較好用的模型catboost和對分型別特征處理的編碼方式TargetEncoder,在這個專案中可以方便快捷的對資料進行處理和建模,
Part1.資料匯入
import numpy as np
import pandas as pd
import os
from sklearn.exceptions import ConvergenceWarning
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=ConvergenceWarning)
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# separate target, remove id and target
test_ids = test['id']
target = train['target']
train.drop(columns=['id', 'target'], inplace=True)
test.drop(columns=['id'], inplace=True)
train.head()
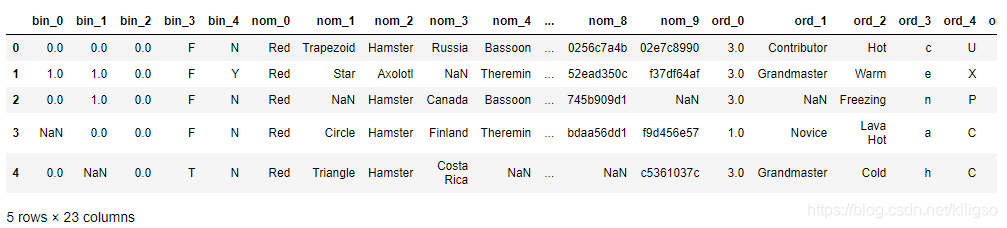
可以看到這次的23個特征全部都是分型別特征,分型別特征是無法直接建模的,一個一個地去處理又比較麻煩,這里我們可以直接使用一個高效的編碼方式TargetEncoder
Part2.資料處理
import category_encoders as ce
te = ce.TargetEncoder(cols=train.columns.values, smoothing=0.3).fit(train, target)
train = te.transform(train)
train.head()
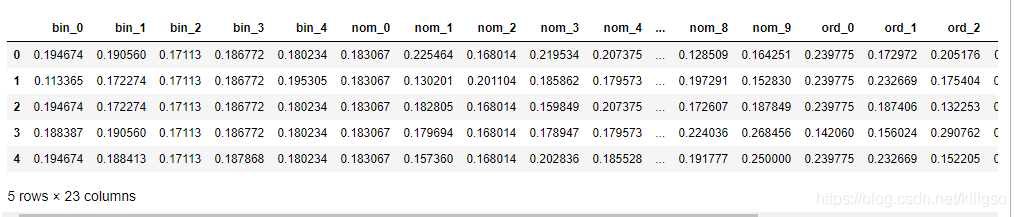
TargetEncoder將所有的分型別特征全部變成了可以直接建模的數字
sklearn中多種編碼方式——category_encoders
TargetEncoder
目標編碼是一種不僅基于特征值本身,還基于相應因變數的類別變數編碼方法,對于分類問題:將類別特征替換為給定某一特定類別值的因變數后驗概率與所有訓練資料上因變數的先驗概率的組合,對于連續目標:將類別特征替換為給定某一特定類別值的因變數目標期望值與所有訓練資料上因變數的目標期望值的組合,該方法嚴重依賴于因變數的分布,但這大大減少了生成編碼后特征的數量,
公式:
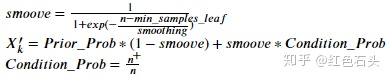
此方法同樣容易引起過擬合,以下方法用于防止過擬合:
①增加正則項a的大小
②在訓練集該列中添加噪聲
③使用交叉驗證
如果想了解其他的編碼方式,可以點擊上面的鏈接去了解更詳細的知識
Part3.資料建模
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
x_train, x_test, y_train, y_test = train_test_split(
train, target,
test_size=0.2,
random_state=100
)
#分訓練集和測驗集
from catboost import CatBoostClassifier
best_params_cat = {
'max_depth': 2,
'n_estimators': 600,
'random_state': 289,
'verbose': 0
}
#預測
def predict(estimator, features):
return estimator.predict_proba(features)[:, 1]
#計算auc分數
def auc(estimator):
y_pred = predict(estimator, x_test)
return roc_auc_score(y_test, y_pred)
SEARCH_NOW = False
# 搜索最佳引數
if SEARCH_NOW:
params = {
'max_depth': [2, 3, 4, 5],
'n_estimators': [50, 100, 200, 400, 600],
'random_state': [289],
'verbose': [0]
}
best_params_cat = make_search(CatBoostClassifier(), params)
# 建模
cat = CatBoostClassifier()
cat.set_params(**best_params_cat)
cat.fit(x_train, y_train)
print('roc auc = %.4f' % auc(cat))
這里用到的模型catboost,如果想要詳細了解的話可以點擊下面的鏈接,
CatBoost原理及實踐
簡單的說catboost是一種能夠很好地處理類別型特征的梯度提升演算法庫,
可以用來防止我們使用了TargetEncoder后的過擬合,能夠降低它帶給我們的影響,
為了將所有樣本用于訓練,CatBoost給出了一種解決方案,即首先對所有樣本進行隨機排序,然后針對類別型特征中的某個取值,每個樣本的該特征轉為數值型時都是基于排在該樣本之前的類別標簽取均值,同時加入了優先級和優先級的權重系數,公式示例如下
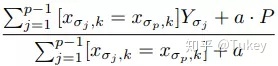
這種做法可以降低類別特征中低頻次特征帶來的噪聲,
#資料預測
test = te.transform(test)
pre =cat.predict_proba(test)[:,1]
#資料保存
res = pd.DataFrame()
res['id'] = test_ids
res['target'] = pre
res.to_csv('submission.csv', index=False)
Part4.總結
這個專案并不是很難,主要是想和大家分享兩個小幫手,來處理這種只有分型別特征的資料集,希望能對大家有幫助,文中有轉載的部分都有貼上原文的鏈接,希望大家也可以看看詳細的內容,謝謝大家的閱讀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/108474.html
標籤:其他
上一篇:百度飛槳目標檢測7日打卡營