作者|ANIRUDDHA BHANDARI
編譯|VK
來源|Analytics Vidhya
概述
-
NumPy是一個Python庫,每個資料科學專業人員都應該熟悉它
-
這個全面的NumPy教程從頭開始介紹NumPy,從基本的數學運算到NumPy如何處理影像資料
-
本文中有大量的Numpy概念和Python代碼
介紹
我非常喜歡Python中的NumPy庫,在我的資料科學之旅中,我無數次依賴它來完成各種任務,從基本的數學運算到使用它進行影像分類!
簡而言之,NumPy是Python中最基本的庫之一,也許是其中最有用的庫,NumPy高效地處理大型資料集, 作為一名資料科學家或一名有抱負的資料科學專業人士,我們需要對NumPy及其在Python中的作業原理有一個扎實的掌握,

在本文中,我將首先描述一下NumPy庫是什么,以及為什么你應該選擇它而不是繁瑣的Python串列,然后,我們將介紹一些最基本的NumPy操作,這些操作將使你喜歡這個很棒的庫!
目錄
-
NumPy庫是什么?
-
Python串列與NumPy陣列有什么區別?
-
創建NumPy陣列
- 基本的ndarray
- 全零陣列
- 全一陣列
- ndarray中的亂數
- 定制的陣列
- NumPy的Imatrix
- 等間距的ndarray
-
NumPy陣列的形狀與重塑
- NumPy陣列的維數
- NumPy陣列的形狀
- NumPy陣列的大小
- 重塑NumPy陣列
- 展開NumPy陣列
- NumPy陣列的轉置
-
擴展和壓縮一個NumPy陣列
- 展開NumPy陣列
- 壓縮NumPy陣列
-
NumPy陣列的索引與切片
- 一維陣列的切片
- 二維陣列切片
- 三維陣列切片
- NumPy陣列的負切片
-
堆疊和級聯Numpy陣列
- 堆疊ndarrays
- 級聯ndarrays
-
Numpy陣列廣播
-
NumPy Ufuncs
-
用NumPy陣列計算
- 平均值、中位數和標準差
- 最小最大值及其索引
-
在NumPy陣列中排序
-
NumPy陣列和影像
NumPy庫是什么?
NumPy是Python數值庫,是Python編程中最有用的科學庫之一,它支持大型多維陣列物件和各種工具,各種其他的庫,如Pandas、Matplotlib和Scikit-learn,都建立在這個令人驚嘆的庫之上,
陣列是元素/值的集合,可以有一個或多個維度,一維陣列稱為向量,二維陣列稱為矩陣,
NumPy陣列稱為ndarray或N維陣列,它們存盤相同型別和大小的元素,它以其高性能而聞名,并在陣列規模不斷擴大時提供高效的存盤和資料操作,
下載Anaconda時,NumPy會預先安裝,但是如果你想在你的機器上單獨安裝NumPy,只需在你的終端上鍵入以下命令:
pip install numpy
現在需要匯入庫:
import numpy as np
np實際上是資料科學界使用的NumPy的縮寫,
Python串列與NumPy陣列有什么區別?
如果你熟悉Python,你可能會想,既然我們已經有了Python串列,為什么還要使用NumPy陣列?畢竟,這些Python串列充當一個陣列,可以存盤各種型別的元素,這是一個完全正確的問題,答案隱藏在Python在記憶體中存盤物件的方式中,
Python物件實際上是一個指向記憶體位置的指標,該記憶體位置存盤有關該物件的所有詳細資訊,如位元組和值,盡管這些額外的資訊使Python成為一種動態型別語言,但它也付出了代價,這在存盤大量物件(如在陣列中)時變得顯而易見,
Python串列本質上是一個指標陣列,每個指標指向一個包含與元素相關資訊的位置,這在記憶體和計算方面增加了很多開銷,當串列中存盤的所有物件都是同一型別時,大多數資訊都是冗余的!
為了解決這個問題,我們使用只包含同構元素的NumPy陣列,即具有相同資料型別的元素,這使得它在存盤和操作陣列方面更加高效,
當陣列包含大量元素(比如數千或數百萬個元素)時,這種差異就變得明顯了,另外,使用NumPy陣列,你可以執行元素操作,這是使用Python串列不可能做到的!
這就是為什么在對大量資料執行數學操作時,NumPy陣列比Python串列更受歡迎的原因,
創建NumPy陣列
基本的ndarray
考慮到NumPy陣列解決的復雜問題,它很容易創建,要創建一個非常基本的ndarray,可以使用np.array()方法,你只需將陣列的值作為串列傳遞:
np.array([1,2,3,4])
輸出:
array([1, 2, 3, 4])
此陣列包含整數值,可以在dtype引數中指定資料型別:
np.array([1,2,3,4],dtype=np.float32)
輸出:
array([1., 2., 3., 4.], dtype=float32)
由于NumPy陣列只能包含同構資料型別,因此如果型別不匹配,則將向上轉換值:
np.array([1,2.0,3,4])
輸出:
array([1., 2., 3., 4.])
在這里,NumPy將整數值上移到浮點值,
NumPy陣列也可以是多維的,
np.array([[1,2,3,4],[5,6,7,8]])
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
在這里,我們創建了一個二維陣列,
注:矩陣只是一個NxM形狀的數字矩形陣列,其中N是行數,M是矩陣中的列數,你剛才看到的是一個2x4矩陣,
全零陣列
NumPy允許你使用 np.zeros()方法,你只需傳遞所需陣列的形狀:
np.zeros(5)
array([0., 0., 0., 0., 0.])
上面一個是一維陣列,下面一個是二維陣列:
np.zeros((2,3))
array([[0., 0., 0.],
[0., 0., 0.]])
全一陣列
你還可以使用 np.ones()方法獲得全一陣列:
np.ones(5,dtype=np.int32)
array([1, 1, 1, 1, 1])
ndarray中的亂數
創建ndarray的另一個非常常用的方法是隨機亂數方法,它創建一個給定形狀的陣列,其隨機值來自[0,1]:
# 隨機的
np.random.rand(2,3)
array([[0.95580785, 0.98378873, 0.65133872],
[0.38330437, 0.16033608, 0.13826526]])
定制的陣列
或者,實際上,可以使用 np.full()方法,只需傳入所需陣列的形狀和所需的值:
np.full((2,2),7)
array([[7, 7],
[7, 7]])
NumPy的Imatrix
另一個偉大的方法是np.eye()回傳一個陣列,其對角線上有1,其他地方都有0,
一個單位矩陣是一個正方形矩陣,它的主對角線上有1,其他地方都有0,下面是形狀為3x 3的單位矩陣,
注:正方形矩陣是N x N的形狀,這意味著它具有相同數量的行和列,
# 單位矩陣
np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
但是,NumPy允許你靈活地更改對角線,值必須為1,你可以將其移到主對角線上方:
# 不是單位矩陣
np.eye(3,k=1)
array([[0., 1., 0.],
[0., 0., 1.],
[0., 0., 0.]])
或將其移到主對角線下方:
np.eye(3,k=-2)
array([[0., 0., 0.],
[0., 0., 0.],
[1., 0., 0.]])
注:只有當1沿主對角線而不是任何其他對角線時,矩陣才稱為單位矩陣!
等間距的ndarray
你可以使用np.arange()方法:
np.arange(5)
array([0, 1, 2, 3, 4])
通過分別傳遞三個數字作為這些值的引數,可以顯式定義值間隔的開始、結束和步長,這里要注意的一點是,間隔定義為[開始,結束),其中最后一個數字將不包含在陣列中:
np.arange(2,10,2)
array([2, 4, 6, 8])
由于步長定義為2,因此下圖展示了輸出的元素,注意,10不會列印出來,因為它是最后一個元素,
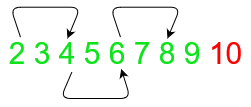
另一個類似的功能是 np.linspace(),但它將從間隔中獲取需要檢索的樣本數,而不是步長,這里要注意的一點是,最后一個數字包含在回傳的值中,這與np.arange()不同
np.linspace(0,1,5)
array([0. , 0.25, 0.5 , 0.75, 1. ])
太好了!現在你知道了如何使用NumPy創建陣列,但了解陣列的形狀也很重要,
NumPy陣列的形狀與重塑
創建了ndarray之后,接下來要做的是檢查ndarray的軸數、形狀和大小,
NumPy陣列的維數
可以使用ndims屬性輕松確定NumPy陣列的維數或軸數:
# 軸數
a = np.array([[5,10,15],[20,25,20]])
print('Array :','\n',a)
print('Dimensions :','\n',a.ndim)
Array :
[[ 5 10 15]
[20 25 20]]
Dimensions :
2
這個陣列有兩個維度:2行3列,
NumPy陣列的形狀
形狀是NumPy陣列的一個屬性,它顯示每個維度上有多少行元素,你可以進一步索引ndarray回傳的形狀,以便沿每個維度獲取值:
a = np.array([[1,2,3],[4,5,6]])
print('Array :','\n',a)
print('Shape :','\n',a.shape)
print('Rows = ',a.shape[0])
print('Columns = ',a.shape[1])
Array :
[[1 2 3]
[4 5 6]]
Shape :
(2, 3)
Rows = 2
Columns = 3
NumPy陣列的大小
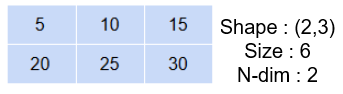
可以使用size屬性確定陣列中有多少值,它只是將行數乘以ndarray中的列數:
# size of array
a = np.array([[5,10,15],[20,25,20]])
print('Size of array :',a.size)
print('Manual determination of size of array :',a.shape[0]*a.shape[1])
Size of array : 6
Manual determination of size of array : 6
重塑NumPy陣列
可以使用np.reshape()方法,它在不更改ndarray中的資料的情況下更改ndarray的形狀:
# 重塑
a = np.array([3,6,9,12])
np.reshape(a,(2,2))
array([[ 3, 6],
[ 9, 12]])
在這里,我將ndarray從一維重塑為二維ndarray,
重塑時,如果你不確定任何軸的形狀,只需輸入-1,當NumPy看到-1時,它會自動計算形狀:
a = np.array([3,6,9,12,18,24])
print('Three rows :','\n',np.reshape(a,(3,-1)))
print('Three columns :','\n',np.reshape(a,(-1,3)))
Three rows :
[[ 3 6]
[ 9 12]
[18 24]]
Three columns :
[[ 3 6 9]
[12 18 24]]
展開NumPy陣列
有時,當你有多維陣列并希望將其折疊為一維陣列時,可以使用 flatten()方法或ravel()方法:
a = np.ones((2,2))
b = a.flatten()
c = a.ravel()
print('Original shape :', a.shape)
print('Array :','\n', a)
print('Shape after flatten :',b.shape)
print('Array :','\n', b)
print('Shape after ravel :',c.shape)
print('Array :','\n', c)
Original shape : (2, 2)
Array :
[[1. 1.]
[1. 1.]]
Shape after flatten : (4,)
Array :
[1. 1. 1. 1.]
Shape after ravel : (4,)
Array :
[1. 1. 1. 1.]
但是flatten() 和ravel()之間的一個重要區別是前者回傳原始陣列的副本,而后者回傳對原始陣列的參考,這意味著對ravel()回傳的陣列所做的任何更改也將反映在原始陣列中,而flatten()則不會這樣,
b[0] = 0
print(a)
[[1. 1.]
[1. 1.]]
所做的更改沒有反映在原始陣列中,
c[0] = 0
print(a)
[[0. 1.]
[1. 1.]]
但在這里,更改后的值也反映在原始ndarray中,
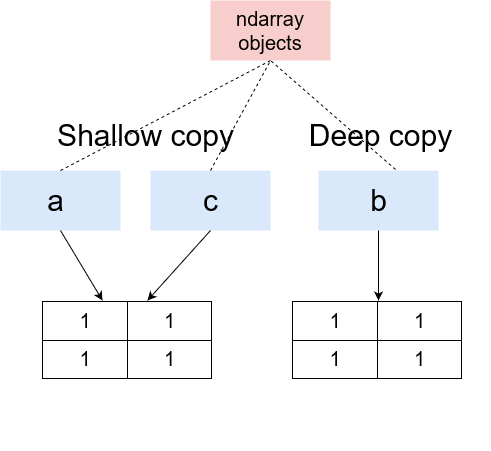
這里發生的事情是flatten()創建了ndarray的深層副本,而ravel()創建了ndarray的淺層副本,
深層副本意味著在記憶體中創建了一個全新的ndarray,flatten()回傳的ndarray物件現在指向這個記憶體位置,因此,此處所做的任何更改都不會反映在原始ndarray中,
另一方面,淺拷貝回傳對原始記憶體位置的參考,這意味著ravel()回傳的物件指向與原始ndarray物件相同的記憶體位置,因此,毫無疑問,對該ndarray所做的任何更改也將反映在原始ndarray中,
NumPy陣列的轉置
NumPy的另一個非常有趣的重塑方法是transpose()方法,它接受輸入陣列并用列值交換行,用行值交換列值:
a = np.array([[1,2,3],
[4,5,6]])
b = np.transpose(a)
print('Original','\n','Shape',a.shape,'\n',a)
print('Expand along columns:','\n','Shape',b.shape,'\n',b)
Original
Shape (2, 3)
[[1 2 3]
[4 5 6]]
Expand along columns:
Shape (3, 2)
[[1 4]
[2 5]
[3 6]]
在轉置一個2x 3陣列時,我們得到了一個3x2陣列,轉置在線性代數中有著重要的意義,
擴展和壓縮一個NumPy陣列
展開NumPy陣列
通過提供要展開的陣列和軸,可以使用expand_dims()方法將新軸添加到陣列中:
# 展開維度
a = np.array([1,2,3])
b = np.expand_dims(a,axis=0)
c = np.expand_dims(a,axis=1)
print('Original:','\n','Shape',a.shape,'\n',a)
print('Expand along columns:','\n','Shape',b.shape,'\n',b)
print('Expand along rows:','\n','Shape',c.shape,'\n',c)
Original:
Shape (3,)
[1 2 3]
Expand along columns:
Shape (1, 3)
[[1 2 3]]
Expand along rows:
Shape (3, 1)
[[1]
[2]
[3]]
壓縮NumPy陣列
另一方面,如果希望減小陣列的軸,請使用squeeze()方法,它將洗掉具有單個條目的軸,這意味著,如果創建了一個2 x 2 x 1矩陣,則squeze()將從矩陣中洗掉第三個維度:
# squeeze
a = np.array([[[1,2,3],
[4,5,6]]])
b = np.squeeze(a, axis=0)
print('Original','\n','Shape',a.shape,'\n',a)
print('Squeeze array:','\n','Shape',b.shape,'\n',b)
Original
Shape (1, 2, 3)
[[[1 2 3]
[4 5 6]]]
Squeeze array:
Shape (2, 3)
[[1 2 3]
[4 5 6]]
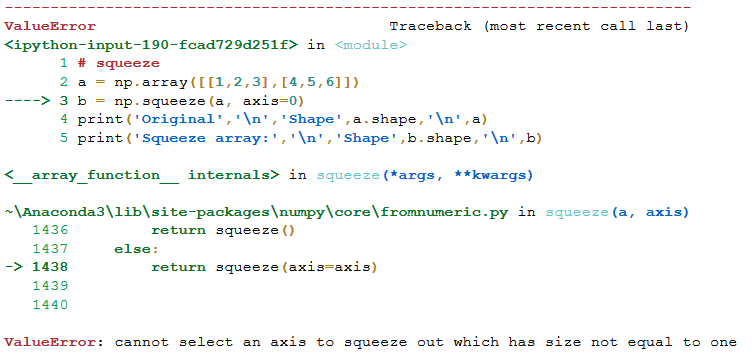
但是,如果你已經有一個2×2的矩陣,在這種情況下使用squeeze()會給你一個錯誤:
# squeeze
a = np.array([[1,2,3],
[4,5,6]])
b = np.squeeze(a, axis=0)
print('Original','\n','Shape',a.shape,'\n',a)
print('Squeeze array:','\n','Shape',b.shape,'\n',b)
NumPy陣列的索引與切片
到目前為止,我們已經看到了如何創建一個NumPy陣列以及如何處理它的形狀,在本節中,我們將看到如何使用索引和切片從陣列中提取特定值,
一維陣列的切片
切片意味著從一個索引檢索元素到另一個索引,我們要做的就是像這樣[start: end]
然而,你也可以定義步長,例如你可以將步長定義為2,這意味著讓元素遠離當前索引2個位置進行取值,
將所有這些內容合并到一個索引中看起來像這樣: [start?:end:step-size],
a = np.array([1,2,3,4,5,6])
print(a[1:5:2])
[2 4]
注意,沒有考慮最后一個元素,這是因為切片包括開始索引,但不包括結束索引,
解決方法是將下一個更高的索引寫入要檢索的最終索引值:
a = np.array([1,2,3,4,5,6])
print(a[1:6:2])
[2 4 6]
如果不指定起始索引或結束索引,則默認值分別為0或陣列大小,默認情況下步長為1,
a = np.array([1,2,3,4,5,6])
print(a[:6:2])
print(a[1::2])
print(a[1:6:])
[1 3 5]
[2 4 6]
[2 3 4 5 6]
二維陣列切片
現在,二維陣列有行和列,所以對二維陣列進行切片會有點困難,但是一旦你理解了它,你就可以分割任何維度陣列!
在學習如何分割二維陣列之前,讓我們先看看如何從二維陣列中檢索元素:
a = np.array([[1,2,3],
[4,5,6]])
print(a[0,0])
print(a[1,2])
print(a[1,0])
1
6
4
在這里,我們提供了行值和列值來標識要提取的元素,在一維陣列中,我們只提供列值,因為只有一行,
因此,要對二維陣列進行切片,需要同時提到行和列的切片:
a = np.array([[1,2,3],[4,5,6]])
# 列印第一行值
print('First row values :','\n',a[0:1,:])
# 具有列的步長
print('Alternate values from first row:','\n',a[0:1,::2])
#
print('Second column values :','\n',a[:,1::2])
print('Arbitrary values :','\n',a[0:1,1:3])
First row values :
[[1 2 3]]
Alternate values from first row:
[[1 3]]
Second column values :
[[2]
[5]]
Arbitrary values :
[[2 3]]
三維陣列切片
到目前為止我們還沒有看到三維陣列,首先讓我們想象一下三維陣列的樣子:
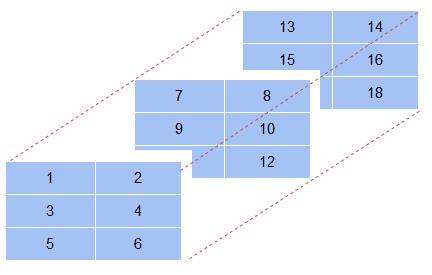
a = np.array([[[1,2],[3,4],[5,6]],# 第一個軸陣列
[[7,8],[9,10],[11,12]],# 第二個軸陣列
[[13,14],[15,16],[17,18]]])# 第三個軸陣列
# 3-D array
print(a)
[[[ 1 2]
[ 3 4]
[ 5 6]]
[[ 7 8]
[ 9 10]
[11 12]]
[[13 14]
[15 16]
[17 18]]]
除了行和列之外,在二維陣列中,三維陣列還有一個深度軸,在這個深度軸上,它將一個二維陣列放在另一個陣列后面,所以,當你在切片一個三維陣列時,你還需要提到你要切片哪個二維陣列,這通常作為索引中的第一個值出現:
# value
print('First array, first row, first column value :','\n',a[0,0,0])
print('First array last column :','\n',a[0,:,1])
print('First two rows for second and third arrays :','\n',a[1:,0:2,0:2])
First array, first row, first column value :
1
First array last column :
[2 4 6]
First two rows for second and third arrays :
[[[ 7 8]
[ 9 10]]
[[13 14]
[15 16]]]
如果希望將值作為一維陣列,則可以始終使用flatten()方法來完成此項作業!
print('Printing as a single array :','\n',a[1:,0:2,0:2].flatten())
Printing as a single array :
[ 7 8 9 10 13 14 15 16]
NumPy陣列的負切片
對陣列進行切片的一個有趣的方法是使用負切片,負切片從末尾而不是開頭列印元素,請看下面:
a = np.array([[1,2,3,4,5],
[6,7,8,9,10]])
print(a[:,-1])
[ 5 10]
這里,列印了每行的最后一個值,但是,如果我們想從末尾提取,我們必須顯式地提供負步長,否則結果將是空串列,
print(a[:,-1:-3:-1])
[[ 5 4]
[10 9]]
盡管如此,切片的基本邏輯保持不變,即輸出中從不包含結束索引,
負切片的一個有趣的用途是反轉原始陣列,
a = np.array([[1,2,3,4,5],
[6,7,8,9,10]])
print('Original array :','\n',a)
print('Reversed array :','\n',a[::-1,::-1])
Original array :
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
Reversed array :
[[10 9 8 7 6]
[ 5 4 3 2 1]]
也可以使用flip()方法來反轉ndarray,
a = np.array([[1,2,3,4,5],
[6,7,8,9,10]])
print('Original array :','\n',a)
print('Reversed array vertically :','\n',np.flip(a,axis=1))
print('Reversed array horizontally :','\n',np.flip(a,axis=0))
Original array :
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
Reversed array vertically :
[[ 5 4 3 2 1]
[10 9 8 7 6]]
Reversed array horizontally :
[[ 6 7 8 9 10]
[ 1 2 3 4 5]]
堆疊和級聯Numpy陣列
堆疊ndarrays
可以通過組合現有陣列來創建新陣列,你可以通過兩種方式來完成:
-
使用vstack()方法垂直組合陣列(即沿行),從而增加結果陣列中的行數
-
或者使用hstack()以水平方式(即沿列)組合陣列,從而增加結果陣列中的列數
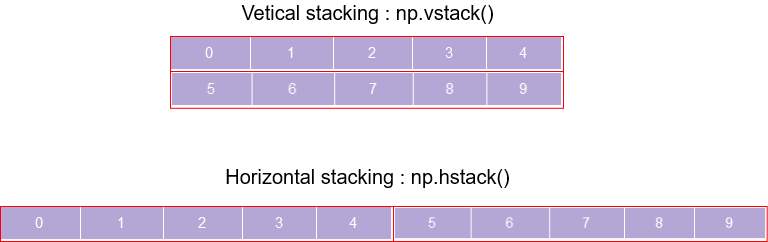
a = np.arange(0,5)
b = np.arange(5,10)
print('Array 1 :','\n',a)
print('Array 2 :','\n',b)
print('Vertical stacking :','\n',np.vstack((a,b)))
print('Horizontal stacking :','\n',np.hstack((a,b)))
Array 1 :
[0 1 2 3 4]
Array 2 :
[5 6 7 8 9]
Vertical stacking :
[[0 1 2 3 4]
[5 6 7 8 9]]
Horizontal stacking :
[0 1 2 3 4 5 6 7 8 9]
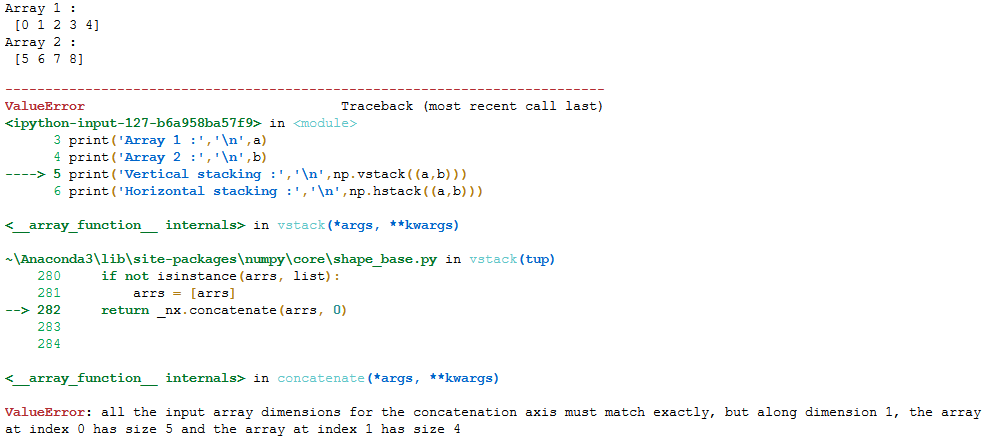
這里要注意的一點是,組合陣列的軸應該具有相同的大小,否則一定會出錯!
a = np.arange(0,5)
b = np.arange(5,9)
print('Array 1 :','\n',a)
print('Array 2 :','\n',b)
print('Vertical stacking :','\n',np.vstack((a,b)))
print('Horizontal stacking :','\n',np.hstack((a,b)))
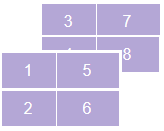
組合陣列的另一個有趣的方法是使用dstack()方法,它按索引組合陣列元素,并沿深度軸堆疊它們:
a = [[1,2],[3,4]]
b = [[5,6],[7,8]]
c = np.dstack((a,b))
print('Array 1 :','\n',a)
print('Array 2 :','\n',b)
print('Dstack :','\n',c)
print(c.shape)
Array 1 :
[[1, 2], [3, 4]]
Array 2 :
[[5, 6], [7, 8]]
Dstack :
[[[1 5]
[2 6]]
[[3 7]
[4 8]]]
(2, 2, 2)
級聯ndarrays
雖然堆疊陣列是組合舊陣列以獲得新陣列的一種方法,但也可以使用concatenate()方法,其中傳遞的陣列沿現有軸連接:
a = np.arange(0,5).reshape(1,5)
b = np.arange(5,10).reshape(1,5)
print('Array 1 :','\n',a)
print('Array 2 :','\n',b)
print('Concatenate along rows :','\n',np.concatenate((a,b),axis=0))
print('Concatenate along columns :','\n',np.concatenate((a,b),axis=1))
Array 1 :
[[0 1 2 3 4]]
Array 2 :
[[5 6 7 8 9]]
Concatenate along rows :
[[0 1 2 3 4]
[5 6 7 8 9]]
Concatenate along columns :
[[0 1 2 3 4 5 6 7 8 9]]
此方法的缺點是原始陣列必須具有要合并的軸,否則,準備好迎接錯誤,
另一個非常有用的函式是append方法,它將新元素添加到ndarray的末尾,當你已經有了一個現有的ndarray,但希望向其添加新值時,這顯然很有用,
# 將值附加到ndarray
a = np.array([[1,2],
[3,4]])
np.append(a,[[5,6]], axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
Numpy陣列廣播
廣播是ndarrays最好的功能之一,它允許你在不同大小的ndarray之間或ndarray與簡單數字之間執行算術運算!
廣播基本上延伸較小的ndarray,使其與較大ndarray的形狀相匹配:
a = np.arange(10,20,2)
b = np.array([[2],[2]])
print('Adding two different size arrays :','\n',a+b)
print('Multiplying an ndarray and a number :',a*2)
Adding two different size arrays :
[[12 14 16 18 20]
[12 14 16 18 20]]
Multiplying an ndarray and a number : [20 24 28 32 36]
它的作業可以看作是拉伸或復制標量,即數字,[2,2,2]以匹配ndarray的形狀,然后按元素執行操作,但是實際上并沒有生成該陣列,這只是一種思考廣播如何運作的方式,
這非常有用,因為用標量值乘一個陣列比用另一個陣列更有效!需要注意的是,只有當兩個ndarray兼容時,它們才能一起廣播,
Ndarrays在以下情況下兼容:
-
兩者都有相同的尺寸
-
其中一個ndarrays的維數是1,尺寸為1的廣播會滿足尺寸更大的ndarray的大小要求
如果陣列不兼容,你將得到一個ValueError,
a = np.ones((3,3))
b = np.array([2])
a+b
array([[3., 3., 3.],
[3., 3., 3.],
[3., 3., 3.]])
在這里,假設第二個ndarray被拉伸成3x 3形狀,然后計算結果,
NumPy Ufuncs
Python是一種動態型別語言,這意味著在賦值時不需要知道變數的資料型別,Python將在運行時自動確定它,雖然這意味著撰寫更干凈、更容易的代碼,但也會使Python變得遲緩,
當Python必須重復執行許多操作(比如添加兩個陣列)時,這個問題就會顯現出來,這是因為每次需要執行操作時,Python都必須檢查元素的資料型別,使用ufuncs函式的NumPy可以解決這個問題,
NumPy使這個作業更快的方法是使用向量化,向量化在編譯的代碼中以逐元素的方式對ndarray執行相同的操作,因此,不需要每次都確定元素的資料型別,從而執行更快的操作,
ufuncs 是NumPy中的通用函式,只是數學函式,它們執行快速的元素功能,當對NumPy陣列執行簡單的算術操作時,它們會自動呼叫,因為它們充當NumPy ufuncs的包裝器,
例如,當使用“+”添加兩個NumPy陣列時,NumPy ufunc add()會在場景后面自動呼叫,并悄悄地發揮其魔力:
a = [1,2,3,4,5]
b = [6,7,8,9,10]
%timeit a+b
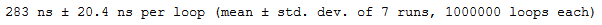
a = np.arange(1,6)
b = np.arange(6,11)
%timeit a+b
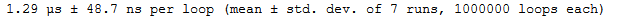
你可以看到,在NumPy ufuncs的幫助下,兩個陣列的相同添加是如何在更短的時間內完成的!
用NumPy陣列計算
下面是一些最重要和最有用的操作,你將需要在你的NumPy陣列上執行這些操作,
NumPy陣列的基本運算
基本的算術運算可以很容易地在NumPy陣列上執行,要記住的重要一點是,這些簡單的算術運算子號只是作為NumPy ufuncs的包裝器,
print('Subtract :',a-5)
print('Multiply :',a*5)
print('Divide :',a/5)
print('Power :',a**2)
print('Remainder :',a%5)
Subtract : [-4 -3 -2 -1 0]
Multiply : [ 5 10 15 20 25]
Divide : [0.2 0.4 0.6 0.8 1. ]
Power : [ 1 4 9 16 25]
Remainder : [1 2 3 4 0]
平均值、中位數和標準差
要查找NumPy陣列的平均值和標準偏差,請使用mean()、std()和median()方法:
a = np.arange(5,15,2)
print('Mean :',np.mean(a))
print('Standard deviation :',np.std(a))
print('Median :',np.median(a))
Mean : 9.0
Standard deviation : 2.8284271247461903
Median : 9.0
最小最大值及其索引
使用Min()和Max()方法可以輕松找到ndarray中的Min和Max值:
a = np.array([[1,6],
[4,3]])
# 最小值
print('Min :',np.min(a,axis=0))
# 最大值
print('Max :',np.max(a,axis=1))
Min : [1 3]
Max : [6 4]
還可以使用argmin()和argmax()方法輕松確定ndarray中沿特定軸的最小值或最大值的索引:
a = np.array([[1,6,5],
[4,3,7]])
# 最小值
print('Min :',np.argmin(a,axis=0))
# 最大值
print('Max :',np.argmax(a,axis=1))
Min : [0 1 0]
Max : [1 2]
讓我給你把輸出分解一下,第一列的最小值是該列的第一個元素,對于第二列,它是第二個元素,對于第三列,它是第一個元素,
類似地,你可以確定最大值的輸出指示什么,
在NumPy陣列中排序
對于任何程式員來說,任何演算法的時間復雜性都是最重要的,排序是一項重要且非常基本的操作,作為一名資料科學家,你可能每天都會用到它,因此,采用一種時間復雜度最小的排序演算法是非常重要的,
當談到排序陣列元素時,NumPy庫有一系列排序函式,可用于對陣列元素進行排序,當你使用sort()方法時,它已經為你實作了快速排序、堆排序、合并排序和時間排序:
a = np.array([1,4,2,5,3,6,8,7,9])
np.sort(a, kind='quicksort')
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
你甚至可以沿著你想要的任何軸對陣列進行排序:
a = np.array([[5,6,7,4],
[9,2,3,7]])# 沿列排序
print('Sort along column :','\n',np.sort(a, kind='mergresort',axis=1))
# 沿行排序
print('Sort along row :','\n',np.sort(a, kind='mergresort',axis=0))
Sort along column :
[[4 5 6 7]
[2 3 7 9]]
Sort along row :
[[5 2 3 4]
[9 6 7 7]]
NumPy陣列和影像
NumPy陣列在存盤和操作影像資料方面有著廣泛的用途,但影像資料到底是什么呢?
影像由以陣列形式存盤的像素組成,每個像素的值介于0到255之間–0表示黑色像素,255表示白色像素,
彩色影像由三個二維陣列組成,每個彩色通道一個:紅色、綠色和藍色,背靠背放置,從而形成三維陣列,陣列中的每個值構成一個像素值,因此,陣列的大小取決于每個維度上的像素數,
請看下圖:

Python可以使用scipy.misc.imread()方法(SciPy庫中的方法),當我們輸出它時,它只是一個包含像素值的三維陣列:
import numpy as np
import matplotlib.pyplot as plt
from scipy import misc
# 讀取影像
im = misc.imread('./original.jpg')
# 影像
im
array([[[115, 106, 67],
[113, 104, 65],
[112, 103, 64],
...,
[160, 138, 37],
[160, 138, 37],
[160, 138, 37]],
[[117, 108, 69],
[115, 106, 67],
[114, 105, 66],
...,
[157, 135, 36],
[157, 135, 34],
[158, 136, 37]],
[[120, 110, 74],
[118, 108, 72],
[117, 107, 71],
...,
我們可以檢查這個NumPy陣列的形狀和型別:
print(im.shape)
print(type(type))
(561, 997, 3)
numpy.ndarray
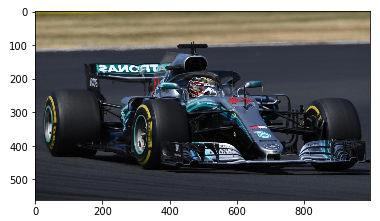
現在,由于影像只是一個陣列,我們可以使用本文中介紹的陣列函式輕松地對其進行操作,比如,我們可以使用np.flip()方法:
# 翻轉
plt.imshow(np.flip(im, axis=1))
或者你可以規范化或更改像素值的范圍,這有時對更快的計算很有用,
im/255
array([[[0.45098039, 0.41568627, 0.2627451 ],
[0.44313725, 0.40784314, 0.25490196],
[0.43921569, 0.40392157, 0.25098039],
...,
[0.62745098, 0.54117647, 0.14509804],
[0.62745098, 0.54117647, 0.14509804],
[0.62745098, 0.54117647, 0.14509804]],
[[0.45882353, 0.42352941, 0.27058824],
[0.45098039, 0.41568627, 0.2627451 ],
[0.44705882, 0.41176471, 0.25882353],
...,
[0.61568627, 0.52941176, 0.14117647],
[0.61568627, 0.52941176, 0.13333333],
[0.61960784, 0.53333333, 0.14509804]],
[[0.47058824, 0.43137255, 0.29019608],
[0.4627451 , 0.42352941, 0.28235294],
[0.45882353, 0.41960784, 0.27843137],
...,
[0.6 , 0.52156863, 0.14117647],
[0.6 , 0.52156863, 0.13333333],
[0.6 , 0.52156863, 0.14117647]],
...,
請記住,這是使用我們在文章中看到的ufuncs和廣播的相同概念!
當你使用神經網路對影像進行分類時,你可以做更多的事情來操作你的影像,
結尾
我們在這篇文章中涉及了很多方面,希望你對NumPy陣列的使用非常熟悉,并且非常熱衷于將其融入到日常的分析任務中,
要了解更多關于任何NumPy函式的資訊,請查看他們的官方檔案,在那里你可以找到每個函式的詳細描述,
檔案鏈接:https://numpy.org/doc/
原文鏈接:https://www.analyticsvidhya.com/blog/2020/04/the-ultimate-numpy-tutorial-for-data-science-beginners/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/10867.html
標籤:其他