這一篇將會介紹什么是雙向遞回模型和如何使用雙向遞回模型實作根據背景關系補全句子中的單詞,
雙向遞回模型
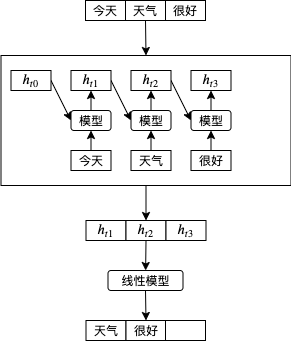
到這里為止我們看到的例子都是按原有順序把輸入傳給遞回模型的,例如傳遞第一天股價會回傳根據第一天股價預測的漲跌,再傳遞第二天股價會回傳根據第一天股價和第二天股價預測的漲跌,以此類推,這樣的模型也稱單向遞回模型,如果我們要根據句子的一部分預測下一個單詞,可以像下圖這樣做,這時 天氣 會根據 今天 計算, 很好 會根據 今天 和 天氣 計算:
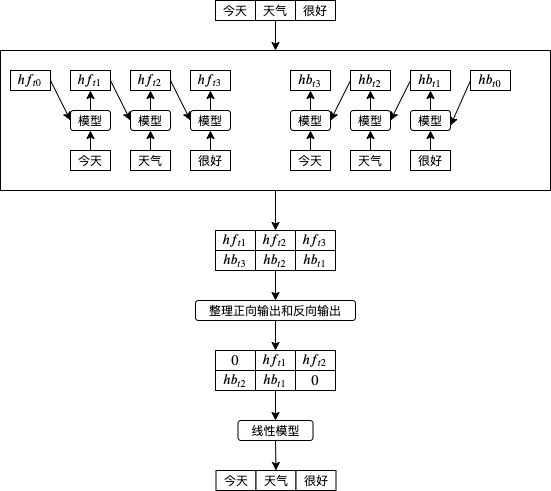
那么如果想要預測在句子中間的單詞呢?例如給出 今天 和 很好 預測 天氣,因為只能根據前面的單詞預測,單向遞回模型的效果會打折,這時候雙向遞回模型就派上用場了,雙向遞回模型 (BRNN, Bidirectional Recurrent Neural Network) 會先按原有順序把輸入傳給遞回模型,然后再按反向順序把輸入傳給遞回模型,然后合并正向輸出和反向輸出,如下圖所示,hf 代表正向輸出,hb 代表反向輸出,把它們合并到一塊就可以實作根據背景關系預測中間的內容,今天 會根據反向的 天氣 和 很好 計算,天氣 會根據正向的 今天 和反向的 很好 計算,很好 會根據正向的 今天 和 天氣 計算,
在 pytorch 中使用雙向遞回模型非常簡單,只要在創建的時候傳入引數 bidirectional = True 即可:
self.rnn = nn.GRU(
input_size = 20,
hidden_size = 50,
num_layers = 1,
batch_first = True,
bidirectional = True
)
單向遞回模型會回傳維度為 批次大小,輸入次數,隱藏值數量 的 tensor,而雙向遞回模型會回傳維度為 批次大小,輸入次數,隱藏值數量*2 的 tensor,
你可能還會有疑問,雙向遞回模型會怎樣處理批次呢?如果批次中每組資料的輸入次數都不一樣,那么反向計算的時候會不會從那些填充的 0 開始計算呢?以下是一個小實驗,我們可以看到反向計算的時候 pytorch 會跳過結尾的填充值,不需要做特殊的處理??,
>>> import torch
>>> from torch import nn
>>> x = torch.zeros((3, 3, 1))
>>> lengths = torch.tensor([1, 2, 3])
>>> rnn = torch.nn.GRU(input_size=1, hidden_size=1, batch_first=True, bidirectional=True)
>>> packed = nn.utils.rnn.pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False)
>>> output, hidden = rnn(packed)
>>> unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
>>> unpacked
tensor([[[0.2916, 0.2377],
[0.0000, 0.0000],
[0.0000, 0.0000]],
[[0.2916, 0.2239],
[0.3949, 0.2377],
[0.0000, 0.0000]],
[[0.2916, 0.2243],
[0.3949, 0.2239],
[0.4263, 0.2377]]], grad_fn=<IndexSelectBackward>)
此外,如果你想使用雙向遞回模型來實作分類(例如文本情感分類),那么可以只抽出 (torch.gather) 每組資料的最后一個正向隱藏值和第一個反向隱藏值,然后把它們組合 (torch.cat) 一起傳遞到多層線性模型,盡管大多數情況下單向遞回模型足以實作分類功能,提取組合的代碼例子如下 (unpacked 來源于上一個例子):
>>> hidden_size = unpacked.shape[2]//2
>>> forward_last = unpacked[:,:,:hidden_size].gather(1, (lengths - 1).reshape(-1, 1, 1).repeat(1, 1, hidden_size))
>>> forward_last
tensor([[[0.2916]],
[[0.3949]],
[[0.4263]]], grad_fn=<GatherBackward>)
>>> backward_first = unpacked[:,:1,hidden_size:]
>>> backward_first
tensor([[[0.2377]],
[[0.2239]],
[[0.2243]]], grad_fn=<SliceBackward>)
>>> combined = torch.cat((forward_last, backward_first), dim=2)
>>> combined
tensor([[[0.2916, 0.2377]],
[[0.3949, 0.2239]],
[[0.4263, 0.2243]]], grad_fn=<CatBackward>)
>>> combined.shape
torch.Size([3, 1, 2])
例子 - 根據背景關系補全單詞
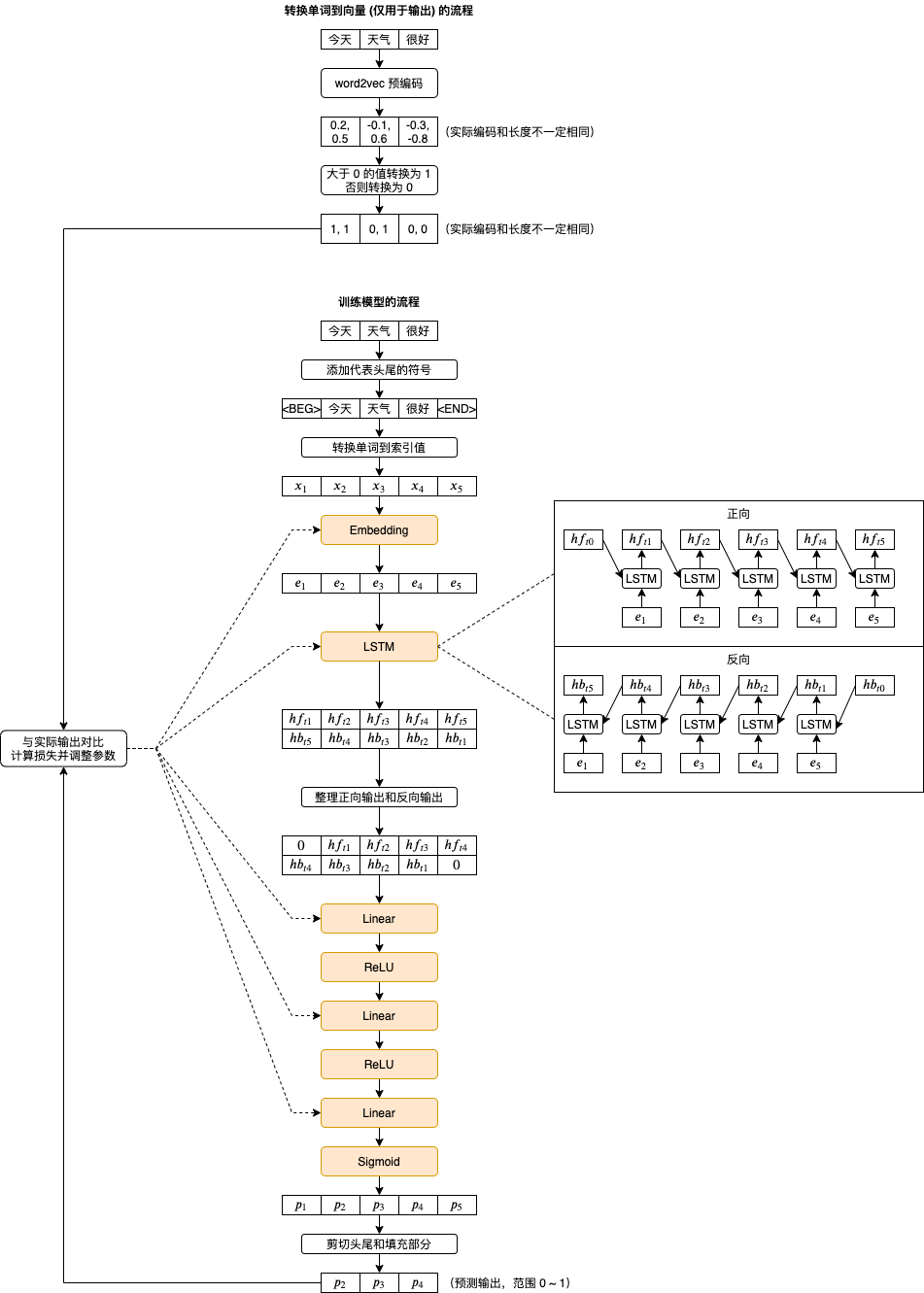
還記得我們小學語文做的填空題嗎,這回我們試試寫一個程式幫我們自動填空吧??,為了這個例子我消耗了一個多月的時間,走了很多冤枉路,下圖是最終使用的訓練流程和模型結構:
以下是踩過的坑一覽??:
- 輸入和輸出的編碼需要分開 (使用不同的向量)
- 輸入的編碼最好不固定 (跟隨訓練調整),輸出的編碼需要固定 (否則模型會作弊讓所有單詞的輸出編碼相同)
- 輸出的編碼只能由 0 和 1 組成,不能直接使用浮點陣列成的向量 (模型無法調整所有輸出到精確的向量,只能調整到方向大致相同的值然后用 Sigmoid 處理)
- 輸出的編碼向量長度大約 50 以上即可避免 13000 個單詞轉換到 0 和 1 以后的編碼沖突,向量長度越大效果越好但需要更多記憶體和訓練時間
- 每個句子需要添加表示開頭和結尾的符號 (
<BEG>與<EOF>),它們會當作預測第一個單詞和最后一個單詞的輸入,比使用 0 效果要好一些 - 輸出中表示開頭和結尾的向量不參與損失的計算 (預測它們沒有意義)
- 根據預測輸出的向量查找對應的單詞可以計算歐幾里得距離,找出距離最接近的單詞
- 引數調整器可以使用 Adam,在這個例子中比 Adadelta 快一些
這個例子最大的特點是輸出的編碼使用了 Embedding 的變種,使得編碼近似于 binary,傳統的做法是使用 onehot + softmax,但隨著單詞數量增多需要的處理時間和記憶體大小會暴增,我目前的機器是訓練不過來的,輸出編碼使用 Embedding 變種的好處還有可以同時找出接近的單詞,但計算歐幾里得距離的效率會比 onehot + softmax 直接得出最可能單詞索引的時間差很多,
首先我們需要使用 word2vec 生成輸出使用的編碼,來源是京東商品評論(下載地址請參考上一篇文章),每個單詞對應一個長度 100 的向量:
import jieba
f = open('chinese.text8', 'w')
for line in open('goods_zh.txt', 'r'):
line = "".join(line.split(',')[:-2])
words = list(jieba.cut(line))
words = [w for w in words if not (w.isascii() or w in (",", ",", "!"))]
words.insert(0, "<BEG>")
words.append("<EOF>")
f.write(" ".join(words))
f.write(" ")
import torch
from gensim.models import word2vec
sentences = word2vec.Text8Corpus('chinese.text8')
model = word2vec.Word2Vec(sentences, size=100)
生成編碼以后我們需要把編碼中的浮點數轉換為 0 或者 1,執行以下代碼后編碼中小于 0 的值會當作 0,大于或等于 0 的值會當作 1:
v = torch.tensor(model.wv.vectors)
v1 = (v > 0).float()
model.wv.vectors = v1.numpy()
然后再來測驗一下編碼是否有沖突(兩個單詞對應完全相同的向量),如果它們輸出相同那就代表沒有問題:
print("wv shape:", v1.shape)
print("wv unique shape:", v1.unique(dim=0).shape)
最后保存編碼模型到硬碟:
model.save("chinese.model")
接下來使用以下代碼訓練和使用模型:
import os
import sys
import torch
import gzip
import itertools
import jieba
import json
import random
from gensim.models import word2vec
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據背景關系預測句子中的單詞"""
def __init__(self, w2v):
super().__init__()
self.hidden_size = 500
self.embedded_in_size = 100
self.embedded_out_size = 100
self.linear_l1_size = 600
self.linear_l2_size = 300
self.embedding_in = nn.Embedding(
num_embeddings=len(w2v.wv.vocab),
embedding_dim=self.embedded_in_size,
padding_idx=0
)
self.rnn = nn.LSTM(
input_size = self.embedded_in_size,
hidden_size = self.hidden_size,
num_layers = 1,
batch_first = True,
bidirectional = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=self.hidden_size*2, out_features=self.linear_l1_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(in_features=self.linear_l1_size, out_features=self.linear_l2_size),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(in_features=self.linear_l2_size, out_features=self.embedded_out_size),
nn.Sigmoid())
def forward(self, x, lengths):
# 轉換單詞對應的數值到輸入使用的向量
embedded_in = self.embedding_in(x)
# 附加長度資訊,避免 RNN 計算填充的資料
packed = nn.utils.rnn.pack_padded_sequence(
embedded_in, lengths, batch_first=True, enforce_sorted=False)
# 使用遞回模型計算,接下來的步驟需要所有輸出,所以忽略最新的隱藏狀態
output, _ = self.rnn(packed)
# output 內部會連接所有隱藏狀態,shape = 實際輸入數量合計, hidden_size
# 為了接下來的處理,需要先整理 shape = batch_size, 每組的最大輸入數量, hidden_size
# 第二個回傳值是各個 tensor 的實際長度,內容和 lengths 相同,所以可以省略掉
unpacked, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
# 整理正向輸出和反向輸出,例如有 8 個單詞,2 個填充
# B 1 2 3 4 5 6 7 8 E 0 0
# 0 B 1 2 3 4 5 6 7 8 E 0 (對應正向)
# 1 2 3 4 5 6 7 8 E 0 0 0 (對應反向)
h = self.hidden_size
hidden_forward = torch.cat((torch.zeros(unpacked.shape[0], 1, h), unpacked[:,:,:h]), dim=1)[:,:-1,:]
hidden_backward = torch.cat((unpacked[:,:,h:], torch.zeros(unpacked.shape[0], 1, h)), dim=1)[:,1:,:]
hidden = torch.cat((hidden_forward, hidden_backward), dim=2)
# 使用多層線性模型推測各個單詞以接近原有句子
y = self.linear(hidden)
return y
def calc_loss(self, loss_function, batch_y, predicted, batch_x_lengths):
# 剪切 batch_y 使得維度與 predicted 相同,因為子批次的最大長度可能與批次的最大長度不一致
batch_y = batch_y[:,:predicted.shape[1],:]
# 根據實際長度清零頭尾和填充的部分
# 不能就地修改否則會導致 gradient computation has been modified by an inplace operation 錯誤
mask = torch.ones(predicted.shape)
for index, length in enumerate(batch_x_lengths):
mask[index,0,:] = 0
mask[index,length-1:,:] = 0
predicted = predicted * mask
batch_y = batch_y * mask
return loss_function(predicted, batch_y)
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def load_word2vec_model():
"""讀取 word2vec 編碼庫"""
return word2vec.Word2Vec.load("chinese.model")
def prepare_save_batch(batch, pending_tensors):
"""準備訓練 - 保存單個批次的資料"""
# 打亂單個批次的資料
random.shuffle(pending_tensors)
# 劃分輸入和輸出 tensor,另外保存各個輸入 tensor 的長度
in_tensor_unpadded = [p[0] for p in pending_tensors]
in_tensor_lengths = torch.tensor([t.shape[0] for t in in_tensor_unpadded])
out_tensor_unpadded = [p[1] for p in pending_tensors]
# 整合長度不等的 tensor 到單個 tensor,不足的長度會填充 0
in_tensor = nn.utils.rnn.pad_sequence(in_tensor_unpadded, batch_first=True)
out_tensor = nn.utils.rnn.pad_sequence(out_tensor_unpadded, batch_first=True)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(in_tensor.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = (in_tensor[training_indices], in_tensor_lengths[training_indices], out_tensor[training_indices])
validating_set = (in_tensor[validating_indices], in_tensor_lengths[validating_indices], out_tensor[validating_indices])
testing_set = (in_tensor[testing_indices], in_tensor_lengths[testing_indices], out_tensor[testing_indices])
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 準備詞語到數值的索引
w2v = load_word2vec_model()
beg_index = w2v.wv.vocab["<BEG>"].index
eof_index = w2v.wv.vocab["<EOF>"].index
# 提前轉換輸出的編碼
embedding_out = nn.Embedding.from_pretrained(torch.FloatTensor(w2v.wv.vectors))
# 從 txt 讀取原始資料集,分批每次處理 2000 行
# 這里使用原始方法讀取,最后一個標注為 1 代表好評,為 0 代表差評
batch = 0
pending_tensors = []
for line in open("goods_zh.txt", "r"):
parts = line.split(',')
phase = ",".join(parts[:-2])
positive = int(parts[-1])
# 使用 jieba 分詞,然后轉換單詞到索引
words = jieba.cut(phase)
word_indices = [beg_index] # 代表陳述句開始
for word in words:
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
word_indices.append(eof_index) # 代表陳述句結束
if len(word_indices) <= 2:
continue # 沒有單詞在編碼庫中
# 輸入是各個句子對應的索引值串列,輸出是各個各個句子對應的向量串列
tensor_in = torch.tensor(word_indices)
tensor_out = embedding_out(tensor_in)
pending_tensors.append((tensor_in, tensor_out))
if len(pending_tensors) >= 2000:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
if pending_tensors:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
def train():
"""開始訓練"""
# 創建模型實體
w2v = load_word2vec_model()
model = MyModel(w2v)
# 創建損失計算器
loss_function = torch.nn.BCELoss()
# 創建引數調整器
optimizer = torch.optim.Adam(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = -1
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式,除去頭尾和填充值
def calc_accuracy(actual, predicted, lengths):
acc = 0
for x in range(len(lengths)):
l = lengths[x]
predicted_record = (predicted[x][1:l-1] > 0.5).int()
actual_record = actual[x][1:l-1].int()
acc += (predicted_record == actual_record).sum().item() / predicted_record.numel()
acc /= len(lengths)
return acc
# 劃分輸入和長度的工具函式
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, input_size
batch_x = batch[0][begin:end]
# shape = batch_size, 1
batch_x_lengths = batch[1][begin:end]
# shape = batch_size. input_size, embedded_size
batch_y = batch[2][begin:end]
return batch_x, batch_x_lengths, batch_y
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_accuracy_list = []
for batch_index, batch in enumerate(read_batches("data/training_set")):
# 切分小批次,有助于泛化模型
training_batch_accuracy_list = []
for index in range(0, batch[0].shape[0], 100):
# 劃分輸入和長度
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch, index, index+100)
# 計算預測值
predicted = model(batch_x, batch_x_lengths)
# 計算損失
loss = model.calc_loss(loss_function, batch_y, predicted, batch_x_lengths)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_batch_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
# 輸出批次正確率
training_batch_accuracy = sum(training_batch_accuracy_list) / len(training_batch_accuracy_list)
training_accuracy_list.append(training_batch_accuracy)
print(f"epoch: {epoch}, batch: {batch_index}: batch accuracy: {training_batch_accuracy}")
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
# 讀取 word2vec 編碼庫
w2v = load_word2vec_model()
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel(w2v)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 獲取單詞索引到向量的 tensor
embedding_tensor = torch.tensor(w2v.wv.vectors)
# 查找最接近單詞數量的函式,根據歐幾里得距離比較
# 也可以使用 w2v.wv.similar_by_vector
def find_similar_words(target_tensor):
top_words = 10
similar_words = []
for word, vocab in w2v.wv.vocab.items():
index = vocab.index
distance = torch.dist(embedding_tensor[index], target_tensor, 2).item()
if len(similar_words) < top_words or distance < similar_words[-1][1]:
similar_words.append((word, distance))
similar_words.sort(key=lambda v: v[1])
if len(similar_words) > top_words:
similar_words.pop()
return similar_words
# 詢問輸入并預測輸出
# __ 為預測目標,例如下次還來__購買 表示預測 __ 處的單詞,只支持一個預測目標
while True:
try:
phase = input("Sentence: ")
phase = phase.replace("\t", "").replace("__", "\t")
if "\t" not in phase:
raise ValueError("Please use __ to represent predict target")
if phase.count("\t") > 1:
raise ValueError("Please only use one predict target")
# 分詞
words = list(jieba.cut(phase))
# 轉換到數值串列
word_indices = [1] # 代表陳述句開始
for word in words:
if word == '\t':
word_indices.append(0) # 預測目標
continue
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
word_indices.append(2) # 代表陳述句結束
if len(word_indices) <= 2:
raise ValueError("No known words")
# 構建輸入
x = torch.tensor(word_indices).reshape(1, -1)
lengths = torch.tensor([len(word_indices)])
# 預測輸出
predicted = model(x, lengths)
# 找出最接近的單詞一覽
target_index = word_indices.index(0)
target_tensor = (predicted[0, target_index] > 0.5).float()
similar_words = find_similar_words(target_tensor)
for word, distance in similar_words:
print(word, distance)
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
執行以下命令準備訓練需要的資料和開始訓練:
python3 example.py prepare
python3 example.py train
訓練結果如下(使用 CPU 訓練需要大約兩天時間??),這里的正確率代表預測輸出和實際輸出向量中有多少個值是相等的:
training accuracy: 0.8106725109454498
validating accuracy: 0.7361285656628191
stop training because highest validating accuracy not updated in 20 epoches
highest validating accuracy: 0.7382469316157465 from epoch 18
testing accuracy: 0.7378169895469142
執行以下命令可以使用訓練好的模型:
python3 example.py eval
以下是一些使用例子,__ (兩個下劃線)代表預測目標的單詞,會輸出最接近的 10 個單詞:
Sentence: 衣服質量__哦
不錯 0.0
很棒 3.872983455657959
挺不錯 4.0
物有所值 4.582575798034668
物超所值 4.795831680297852
很贊 4.795831680297852
超好 4.795831680297852
太好了 4.795831680297852
好 5.0
太棒了 5.0
Sentence: 鞋子輕便__,好穿,值得推薦,
修身 3.316624879837036
身材 3.464101552963257
顯 3.464101552963257
貼身 3.464101552963257
休閑 3.605551242828369
軟和 3.605551242828369
保暖 3.7416574954986572
涼快 3.7416574954986572
柔軟 3.7416574954986572
輕快 3.7416574954986572
Sentence: 鞋子輕便舒服,好穿,值得__,
擁有 3.316624879837036
夠買 3.605551242828369
信賴 3.7416574954986572
購買 4.242640495300293
信耐 4.582575798034668
推薦 4.795831680297852
入手 4.795831680297852
表揚 4.795831680297852
點贊 5.0
下手 5.0
Sentence: 鞋子輕便舒服,好穿,__推薦,
值得 1.4142135381698608
放心 4.690415859222412
值 4.795831680297852
物美價廉 5.099019527435303
價廉物美 5.099019527435303
價格便宜 5.196152210235596
加油 5.196152210235596
一百分 5.196152210235596
很贊 5.196152210235596
贊贊贊 5.196152210235596
Sentence: 發貨__很贊,東西也挺好
速度 2.4494898319244385
迅速 4.898979663848877
給力 5.0
力 5.0
價格便宜 5.0
沒得說 5.196152210235596
超值 5.196152210235596
很贊 5.196152210235596
小哥 5.291502475738525
小巧 5.291502475738525
Sentence: 半個月就出現這問題 ,__直接說找附近站點售后 ,浪費時間,還得自己修,差評一個
客服 0.0
商家 4.690415859222412
賣家 4.898979663848877
售后 5.099019527435303
沒人 5.099019527435303
店家 5.196152210235596
補發 5.291502475738525
人工 5.291502475738525
客戶 5.385164737701416
機器人 5.385164737701416
Sentence: 不錯給老公買了好幾個了,穿著特別__
舒服 0.0
舒適 3.316624879837036
挺舒服 4.242640495300293
帥氣 4.690415859222412
腳疼 4.690415859222412
很帥 4.795831680297852
涼快 4.898979663848877
合身 5.0
暖和 5.099019527435303
老公 5.291502475738525
Sentence: 不錯給__買了好幾個了,穿著特別舒服
老爸 2.8284270763397217
爸爸 3.0
弟弟 3.0
妹妹 3.0
女朋友 3.0
男朋友 3.1622776985168457
老媽 3.1622776985168457
女兒 3.316624879837036
表弟 3.316624879837036
家人 3.316624879837036
可以看到預測出來的效果還不錯??,盡管部分陳述句沒有完全準確的預測出原有的單詞但是語意很接近,如果你想得到更好的效果,可以增加輸出向量長度 (word2vec 生成時的 size 引數,對應 embedded_out_size),輸入向量長度(embedded_in_size),和模型的隱藏值數量(hidden_size, linear_l1_size, linear_l2_size),但會需要更多的訓練時間和記憶體??,
寫在最后
關于遞回模型就介紹到這里了,下一篇開始將會介紹適合處理影像的卷積神經網路 (CNN) 模型,敬請期待,
本來想買臺帶顯卡 (支持 CUDA) 的機器減少訓練所需的時間,但是黃臉婆不允許??,估計一段時間內只能繼續用 CPU 訓練了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/10870.html
標籤:其他
上一篇:linux下usb轉網口的問題
下一篇:Python影像處理