程式:只是一段代碼,保存在檔案中,
編譯器在編譯程式生成可執行檔案時,會對每一條指令和資料,進行地址排號,
程式運行時,就會將指令和資料放到指定的記憶體當中去,而程式只有在運行的時候才會占據記憶體,因此程式地址空間又被叫做行程地址空間,
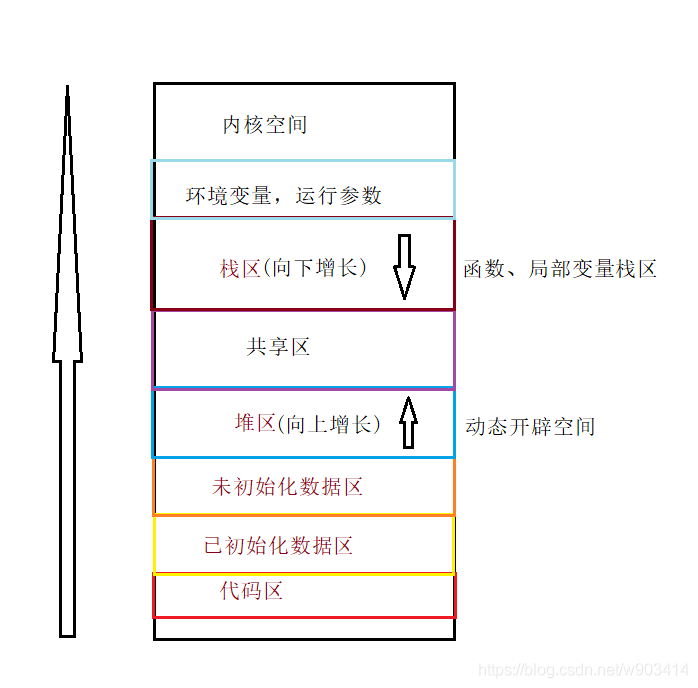
記憶體空間是這樣的,
若運行中的程式直接訪問物理地址,會怎么樣呢?
- 可能導致程式無法運行起來, 程式在編譯時,會給變數資料進行地址排號,但若是某個地址被占用了,就會使程式無法運行起來,(編譯器無法動態的獲取哪一塊記憶體是否被使用)
- 野指標問題, 若行程直接訪問物理地址,野指標可能更改其它行程的資料,
- 記憶體使用率低, 程式運行需要一塊連續的地址空間,會一定程度上造成空間的浪費,
所以OS中設定了虛擬記憶體,通過虛擬地址空間映射到物理記憶體上,而使用C語言/C++時,變數或函式的地址,都是虛擬空間地址,物理記憶體地址用戶一概看不到,由OS統一管理,而OS負責將虛擬地址映射到對應的物理地址,
每運行一段程式,就會開辟連續的地址空間,若是每個程式占據的空間比較大,很多程式共同運行,就會導致有的程式在記憶體中無法運行,而連續開辟的記憶體地址空間的空間使用率是很低的,
而行程使用了虛擬記憶體之后,每個行程都擁有自己的虛擬地址空間,都會有一塊連續的空間使用,
看一下這段代碼:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global_val = 200;
int main()
{
pid_t pid = fork();//創建子行程
if(pid < 0)
{
printf("fork error\n");
return 0;
}
else if(pid == 0)
{
printf("child:%d %p\n",global_val,&global_val);
}
else
{
printf("parent:%d %p\n",global_val,&global_val);
}
return 0;
}
其輸出為:
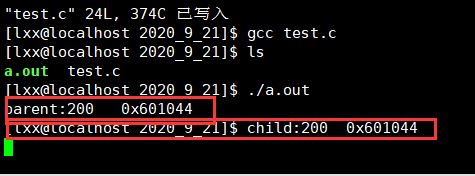
發現子行程中和父行程使用的是同樣的變數和地址,
對代碼進行一點小更改:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global_val = 200;
int main()
{
pid_t pid = fork();//創建子行程
if(pid < 0)
{
printf("fork error\n");
return 0;
}
else if(pid == 0)
{
global_val = 100;
printf("child:%d %p\n",global_val,&global_val);
}
else
{
sleep(3);
printf("parent:%d %p\n",global_val,&global_val);
}
return 0;
}
其輸出為:
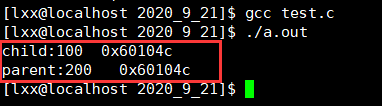
可以看到子行程的變數改變了,而父行程的變數是沒有改變的,
為什么子行程變數改變了,而父行程的變數沒有改變?
子行程是父行程的一份拷貝,子行程拷貝了父行程所有的資訊,在子行程中資料未發生改變的時候,子行程使用父行程的所有資訊,
在第一份代碼中,子行程中變數沒有改變,父行程中變數沒有改變,所以第一份代碼中,地址相等,變數也相等,
第二份代碼中,子行程中變數發生了改變,父行程中變數沒有發生改變,相同的虛擬地址映射到了不同的物理地址,所以第二份代碼,地址相同,變數不同,
這里的相同是指:子行程拷貝了父行程所有的資訊,行程地址空間、PCB…
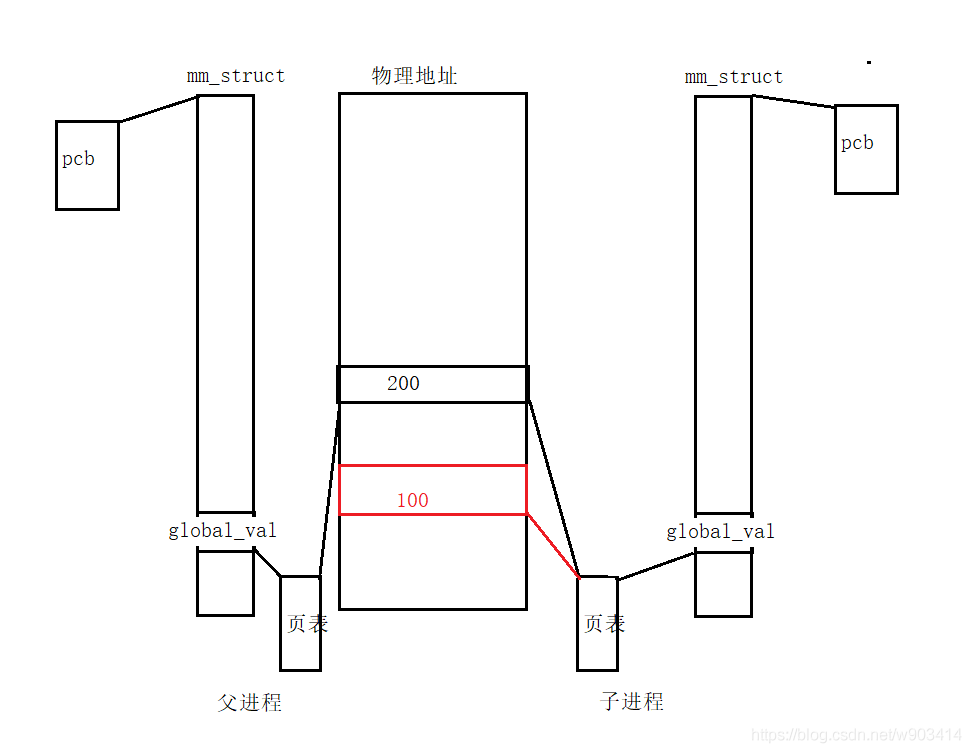
子行程資料發生更改,進行了拷貝了,
第二份代碼中,這里涉及到了寫時拷貝技術:Linux中fork()使用寫時拷貝實作,寫時拷貝是一種推遲或者免除拷貝的技術,OS并不復制整個行程地址空間,而是子行程父行程共享一個地址,當有資料寫入,發生改變時,資料才會被復制,使每個行程都有了自己的拷貝,資源的復制只有在寫入的時候才進行, 而在此之前,子行程只是可讀共享的,這樣就保證了父子行程的代碼共享,資料獨立,
寫時拷貝技術帶來的好處:
- 提高子行程創建效率,
- 節省資源,
那么為什么OS要使用虛擬地址空間?或者說虛擬地址空間帶了什么好處?
- 提高物理記憶體的使用率,
- 保證行程之間的獨立性
虛擬地址是如何映射到物理地址的?
作業系統中記憶體管理方式:
- 分段式:段號+段內偏移
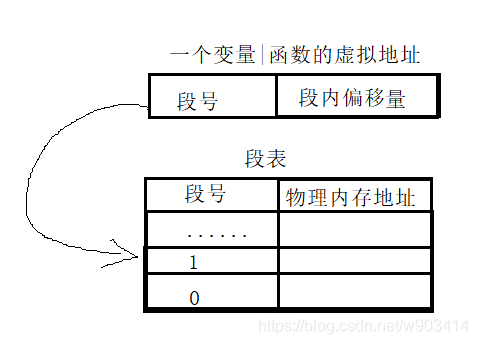
段表:作業系統記錄記憶體分了多少塊,
通過段號尋找對應的物理記憶體起始地址,再加上段內偏移量,就找到了物理地址,
- 分頁式:頁號+頁內偏移,這里畫的比較簡單
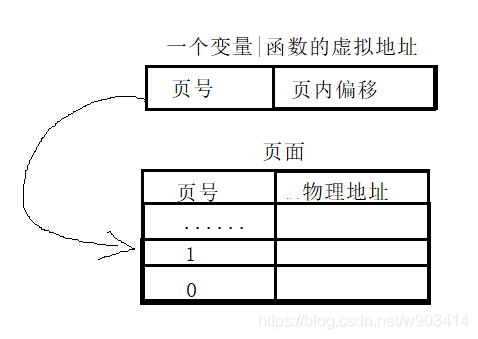
在這里有所不同的時候,我們需要知道一個頁面的大小,一般一個頁面的大小為4K,
則在32位OS中,記憶體為4G,則占有4* 1024* 1024* 1024/4* 1024個頁號,即頁表項,
共計有2^20個頁表項/頁號,將記憶體分為很多個細小的塊,
通過找到對應的頁號,其物理地址和頁內偏移就可找到變數的物理地址,
- 段頁式:記憶體通過分段式進行管理,而每個段內使用分頁式,
首先取得段號,在段表中進行查找;在段表中,存放著對應段號的頁表起始地址,再通過段內頁表起始地址找到頁表,
當前計算機使用的段頁式管理,
虛擬頁會快取在物理記憶體中,如圖:
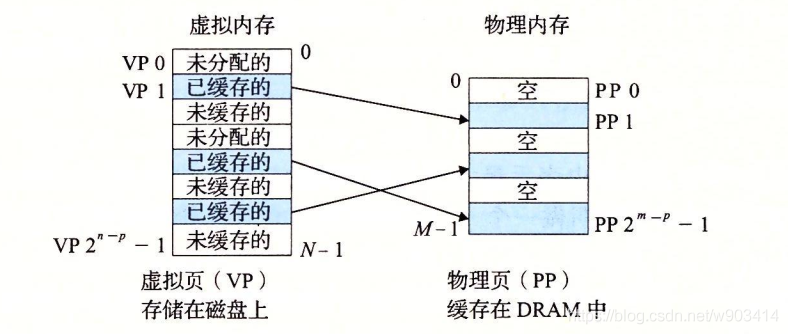
虛擬記憶體可快取到頁表中:頁命中,VP2就會快取在記憶體中,
快取不命中:缺頁 ,VP3不會命中,發生缺頁中斷,那么OS就會從磁盤復制VP3到記憶體中PP3,再更新PTE3,隨后回傳,
VP3:虛擬記憶體3.
PP3:物理記憶體3
PTE3:頁表條目3,0:發生中斷,1:可以快取,
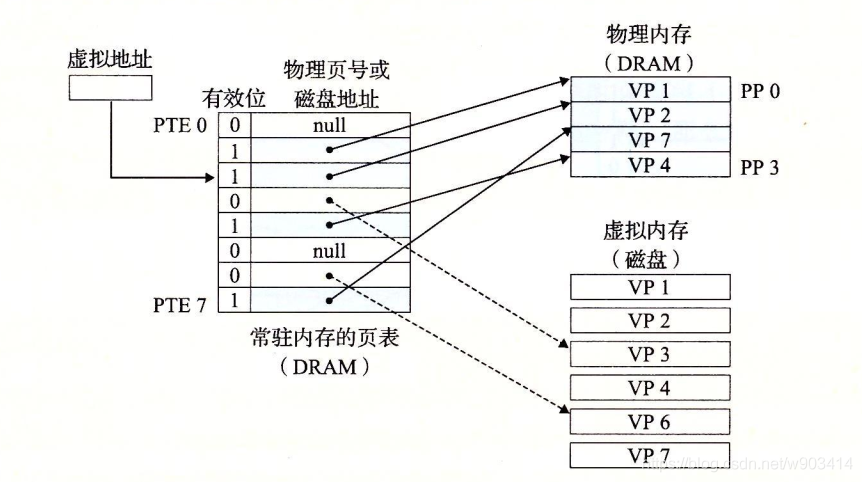
經過缺頁中斷之后:缺頁處理程式會選擇一個作為犧牲頁,并從磁盤上VP3的副本取代它,
MMU利用頁表來實作虛擬地址空間到物理地址空空間的映射:
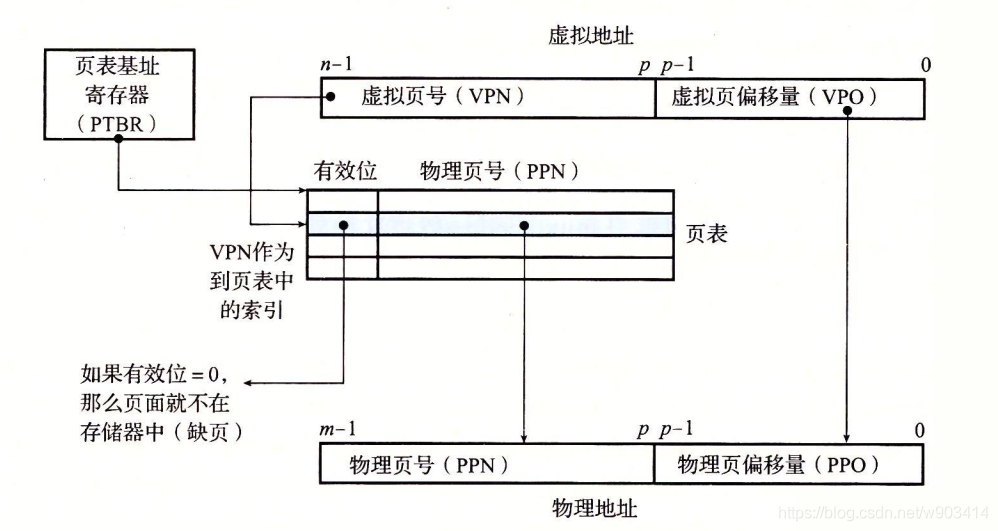
那么該選擇犧牲頁呢?
采用記憶體置換演算法:
- OPT:最佳置換演算法,所被置換出的頁面是以后永遠不會再使用的或者是最長時間內不會再使用,這個演算法只是理論上的演算法,
- FIFO:先進先出演算法,會導致缺頁率升高,
- LRU:最久未使用演算法,將最久未使用的頁面置換出來, (一般使用這個演算法)
- LFU:最不常用演算法,一段時間內使用的次數最少,在將來使用的可能性也很低,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/110552.html
標籤:其他
下一篇:天津大學仁愛學院ACM作業室簡介