貝葉斯公式
貝葉斯公式由英國數學家貝葉斯 ( Thomas Bayes 1702-1761 ) 發展,用來描述兩個條件概率之間的關系,比如 P(A|B) 和 P(B|A),按照乘法法則,可以立刻匯出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B),如上公式也可變形為:P(A|B)=P(B|A)*P(A)/P(B),由于其有著堅實的數學基礎,貝葉斯分類演算法的誤判率是很低的,貝葉斯方法的特點是結合先驗概率和后驗概率,即避免了只使用先驗概率的主觀偏見,也避免了單獨使用樣本資訊的過擬合現象,貝葉斯分類演算法在資料集較大的情況下表現出較高的準確率,同時演算法本身也比較簡單,
貝葉斯

貝葉斯(Thomas Bayes,1702—1761),英國牧師、業余數學家,生活在18世紀的貝葉斯生前是位受人尊敬的英格蘭長老會牧師,為了證明上帝的存在,他發明了概率統計學原理,遺憾的是,他的這一美好愿望至死也未能實作,貝葉斯在數學方面主要研究概率論,他首先將歸納推理法用于概率論基礎理論,并創立了貝葉斯統計理論,對于統計決策函式、統計推斷、統計的估算等做出了貢獻,1763年發表了這方面的論著,對于現代概率論和數理統計都有很重要的作用,1758年發表了另一著作《機會的學說概論》,貝葉斯所采用的許多術語都被沿用至今,貝葉斯思想和方法對概率統計的發展產生了深遠的影響,今天,貝葉斯思想和方法在許多領域都獲得了廣泛的應用,從二十世紀20~30年代開始,概率統計學出現了“頻率學派”和“貝葉斯學派”的爭論,至今,兩派的恩恩怨怨仍在繼續,
樸素貝葉斯
樸素貝葉斯分類是基于貝葉斯概率的思想,假設屬性之間相互獨立,求得各特征的概率,最后取較大的一個作為預測結果,雖然這個簡化方式在一定程度上降低了貝葉斯分類演算法的分類效果,但是在實際的應用場景中,極大地簡化了貝葉斯方法的復雜性,簡而言之,樸素貝葉斯是較為簡單的一種分類器,
屬性獨立性:事件B的發生不對事件A的發生造成影響,這樣的兩個事件叫做相互獨立事件,然而其屬性獨立性假設在現實世界中大多不能成立,例如: “spring”的后面更有可能跟著“MVC”,
A和B中至少有一件事情發生:A∪B; A與B同時發生:A∩B(或AB);如果P(AB) =P(A)P(B),稱A,B 相互獨立,即:從數學上說,若N (N≥2) 個事件相互獨立,則必須滿足這樣的條件:其中任意k (N ≥ k ≥2)個事件同時發生的概率等于該k個事件單獨發生時的概率的乘積,
例:假設事件相互獨立,P(spring) = 0.2,P(MVC) = 0.8, 則 P(spring MVC) = 0.2 * 0.8=0.16
1.樸素貝葉斯演算法思想
邏輯回歸通過擬合曲線(或者學習超平面)實作分類,決策樹通過尋找最佳劃分特征進而學習樣本路徑實作分類,支持向量機通過尋找分類超平面進而最大化類別間隔實作分類,相比之下,樸素貝葉斯另辟蹊徑,通過考慮特征概率來預測分類,
舉個例子:現在有100個人,魚龍混雜,好人和壞人的個數都差不多,現在要利用他們來訓練一個“壞蛋識別器”,這時應該怎么辦呢?我們不管他們之前干過什么事,只單看他們的長相,也就是說,我們在區別好人壞人時,只考慮他們的樣貌特征,比如說“笑”這個特征,它可以是“甜美的笑”、“隨和的笑”、“憨厚的笑”、“沒心沒肺的笑”、“微笑”等等,這些更可能是“好人的笑”;也可以是“陰險的笑”、“不懷好意的笑”、“色瞇瞇的笑”、“冷笑”、“皮笑肉不笑”等等,這些更可能是“壞人的笑”,單單就“笑”這個特征來說,一個好人發出“好人的笑”的概率更大,頻率更高;而壞人則是發出“壞人的笑”的概率更大,頻率更高,當然,好人也有發出壞笑的時候,壞人也有發出好人的笑的時候,這些就都是噪聲了,
除了笑之外,這里可以用的特征還有紋身,性別等,樸素貝葉斯把類似“笑”這樣的特征概率化,構成一個“人的樣貌向量”以及對應的“好人/壞人標簽”,訓練出一個標準的“好人模型”和“壞人模型”,這些模型都是各個樣貌特征概率構成的,這樣,當一個品行未知的人來了以后,我們可以迅速獲取他(她)的樣貌特征向量,分別輸入“好人模型”和“壞人模型”,輸出兩個概率值,如果“壞人模型”輸出的概率值大一些,那這個人很有可能就是個壞人了,
決策樹又是怎么做的呢?決策樹可能先看性別,因為它發現給定的帶標簽人群里面壞人中男性更多,這個特征眼下最能區分壞人和好人,然后按性別先把一撥人分成兩撥;接著看“笑”這個特征,因為它是接下來最有區分度的特征,根據不同的“笑”再把兩撥人分成四撥;接下來看紋身......最后發現好人要么在學堂讀書,要么在田里種地,要么在山上砍柴,而壞人呢,要么在大街上溜達,要么在地下買賣白粉,要么在海里當海盜,這些有次序的特征就像路上的一個個墊腳石(樹的節點)一樣,構成通往不同地方的路徑(樹的枝丫),這些不同路徑的目的地(葉子)就是一個類別容器,包含了一類人,一個品行未知的人來了,按照其樣貌特征順序及其對應的特征值,不斷走啊走,最后走到了學堂或農田,那就是好人;走到了地下或大海,那就是壞人,可以看出來,兩種分類模型的原理是很不相同的,
2.樸素貝葉斯例子
【例】給定如下資料:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
現在我們的問題是,假設有一對男女朋友,男生向女生求婚,此男生的四個特點分別是不帥,性格不好,窮,不上進,請你來判斷一下該女生是嫁還是不嫁?
這是一個經典的分類問題,轉換為數學問題就是比較p(嫁|(不帥、性格不好、窮、不上進))和p(不嫁|(不帥、性格不好、窮、不上進))的概率,就能給出嫁或者不嫁的答案!
這里我們運用到樸素貝葉斯公式:
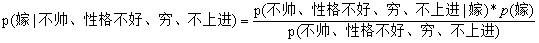
我們需要求p(嫁|(不帥、性格不好、窮、不上進)),這是我們現在不知道的,但是通過樸素貝葉斯公式可以轉化為三個較為簡單的量:
p(不帥、性格不好、窮、不上進|嫁)、p(不帥、性格不好、窮、不上進)、p(嫁),
p(不帥、性格不好、窮、不上進|嫁) = p(不帥|嫁)*p(性格不好|嫁)*p(窮|嫁)*p(不上進|嫁),那么我們就要從給定的資料中分別統計出右邊這幾個概率,就可以求出左邊的概率!
我們將上面的公式整理一下,得到:

接下來我們一個一個地進行統計計算,
p(嫁)=?
首先我們整理的訓練資料中,嫁的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
中 |
上進 |
嫁 |
|
帥 |
好 |
中 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
則 p(嫁) = 6/12(總樣本數) = 1/2
接下來求p(不帥|嫁)=?
嫁的情況下不帥的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
好 |
中 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
則p(不帥|嫁) = 3/6 = 1/2
再求p(性格不好|嫁)= ?
嫁的情況下性格不好的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
則p(性格不好|嫁)= 1/6
求p(窮|嫁) = ?
嫁的情況下窮的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
好 |
窮 |
上進 |
嫁 |
則p(窮|嫁) = 1/6
再求p(不上進|嫁) = ?
嫁的情況下不上進的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
好 |
富 |
不上進 |
嫁 |
則p(不上進|嫁) = 1/6
下面開始求分母,p(不帥),p(性格不好),p(矮),p(不上進)
統計樣本如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
不帥統計如上標黃所示,占5個,那么p(不帥) = 5/12
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
性格不好統計如上標黃所示,占4個,那么p(性格不好) = 4/12 = 1/3
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
窮統計如上標黃所示,占7個,那么p(窮) = 7/12
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
好 |
窮 |
上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
富 |
不上進 |
嫁 |
|
不帥 |
好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
富 |
上進 |
嫁 |
|
不帥 |
不好 |
富 |
上進 |
嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
不上進統計如上標黃所示,占5個,那么p(不上進) = 5/12
到這里,要求p(不帥、性格不好、窮、不上進|嫁),所需要的所有項全部求出來了,下面我們帶入資料進去即可算出:

=(1/2*1/6*1/6*1/6*1/2)/(5/12*1/3*7/12*5/12)
下面我們根據同樣的方法來求p(不嫁|不帥,性格不好,窮,不上進),完全一樣的做法,為了加深理解,我們再來過一遍,首先公式如下:

下面我們也一個一個地來進行統計計算,這個公式里面,分母和上一個公式是一樣的,所以我們不需要再算一次分母了,只需算分子部分,
p(不嫁)=?
首先我們整理的訓練資料中,不嫁的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
則p(不嫁)= 6/12(總樣本數) = 1/2
p(不帥|不嫁) = ?
不嫁的情況下不帥的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
則p(不帥|不嫁) = 2/6 = 1/3
p(性格不好|不嫁) = ?
不嫁的情況下性格不好的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
則p(性格不好|不嫁) = 3/6 = 1/2
p(窮|不嫁) = ?
不嫁的情況下窮的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
好 |
窮 |
上進 |
不嫁 |
|
帥 |
不好 |
窮 |
上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
則p(矮|不嫁) = 6/6 = 1
p(不上進|不嫁) = ?
不嫁的情況下不上進的樣本數如下:
|
帥? |
性格? |
財富? |
上進? |
嫁不嫁? |
|
帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
不帥 |
不好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
|
帥 |
好 |
窮 |
不上進 |
不嫁 |
則p(不上進|不嫁) = 4/6 = 2/3
那么根據公式:

=(1/3*1/2*1*2/3*1/2)/(5/12*1/3*7/12*5/12)
很顯然(1/3*1/2*1*2/3*1/2) > (1/2*1/6*1/6*1/6*1/2)
于是有p(不嫁|不帥、性格不好、窮、不上進) > p(嫁|不帥、性格不好、窮、不上進)
所以我們根據樸素貝葉斯演算法可以給這個女生答案,是不嫁!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/112974.html
標籤:其他
上一篇:CloudFoundry部署教程