1、序言
本文使用Python實作了一些常用的排序方法,文章結構如下:
1.直接插入排序
2.希爾排序
3.冒泡排序
4.快速排序
5.簡單選擇排序
6.堆排序
7.歸并排序
8.基數排序
上述所有的排序均寫在一個Python自定義類中,作為成員函式,
2、排序方法詳細介紹
1.直接插入排序
直接插入排序(Straight Insertion Sort)是一種最簡單的排序方法,它的基本操作是一個值插入到已排好序的有序表中,從而得到一個新的、記錄數增1的有序表,如下圖所示:
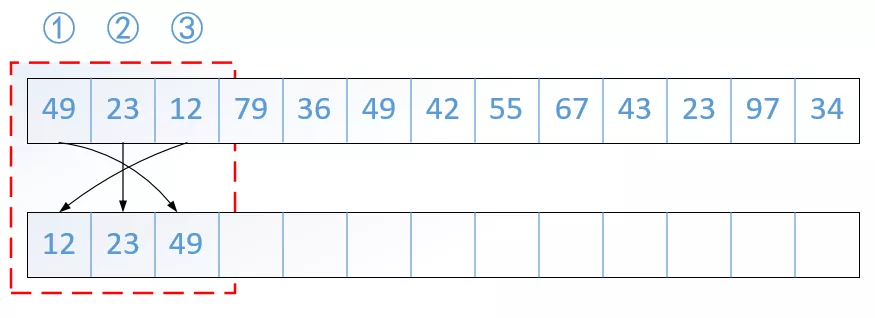
由上圖可知若最初始的有序表即為陣列的第一個元素,用Python實作如下:
def straight_insertion_sort(self, value_list): """ 直接插入排序 :param value_list: 無序串列 :return: """ return self.__straight_insert(value_list) @staticmethod def __straight_insert(value_list): sorted_list = [] sorted_list.append(value_list.pop(0)) for i in range(0, len(value_list)): tail = True # 是否在尾部插入 insert_loc = 0 for j in range(len(sorted_list)): if value_list[i] <= sorted_list[j]: tail = False insert_loc = j break sorted_list.append(value_list[i]) # 先將值插入尾部 if not tail: # 移動值 for j in range(len(sorted_list) - 1, insert_loc, -1): temp = sorted_list[j] sorted_list[j] = sorted_list[j - 1] sorted_list[j - 1] = temp return sorted_list
2.希爾排序
希爾排序(Shell’s Sort)又稱“縮小增量排序”(Diminishing Incerement Sort),它也是一種數插入排序的方法,但在時間效率上較前面的排序方法有較大的改進,它的基本思想是:先將整個待排記錄序列分割成若干個子序列分別進行直接插入排序,待整個序列中的記錄“基本有序”時,再對全體記錄進行一次直接插入排序,如下圖所示:
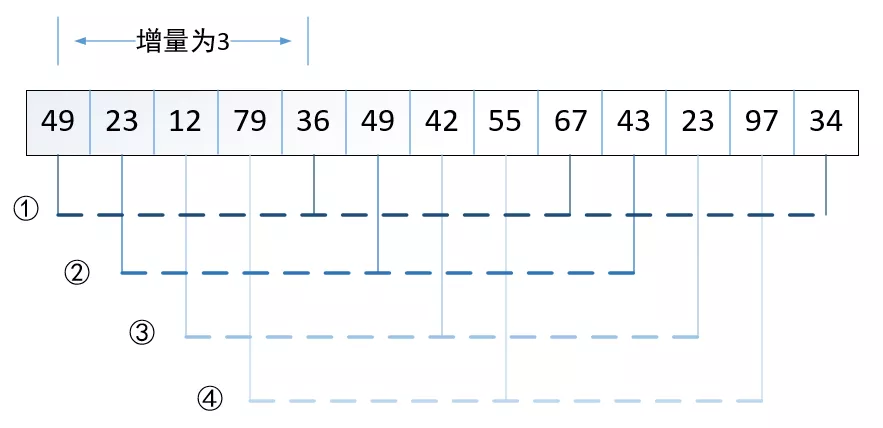
即根據增量將原序列分割成多個子序列進行直接插入排序,增量應不斷減小,且最后一個增量為1,用Python實作如下:
def shells_sort(self, value_list): """ 希爾排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ gap = len(value_list) // 2 while gap >= 1: i = 0 while(i + gap) < len(value_list): start = i gap_list = [] while start < len(value_list): gap_list.append(value_list[start]) start = start + gap gap_list = self.__straight_insert(gap_list) start = i while start < len(value_list): value_list[start] = gap_list.pop(0) start += gap i += 1 gap //= 2 sorted_list = value_list return sorted_list
3.冒泡排序
冒泡排序(Bubble Sort)的程序很簡單,首先將第一個記錄的關鍵字和第二個記錄的關鍵字進行比較,若逆序(與需要的順序相反),則將兩個記錄交換之,然后比較第二個記錄和第三個記錄的關鍵字,以此類推,為第一趟冒泡結束,接著對前n-1個記錄繼續進行上述的程序,這樣重復的程序直至n-1=1結束,排序程序如下所示:
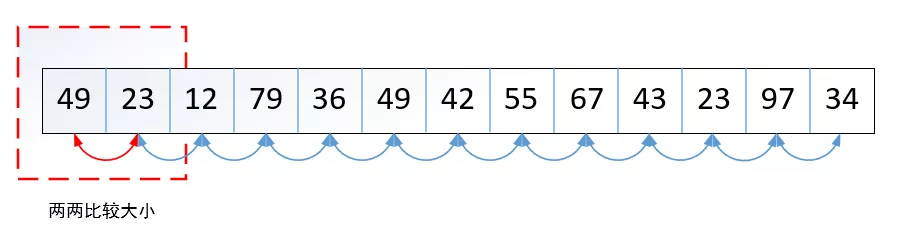
用Python實作如下:
@staticmethod def bubble_sort(value_list): """ 冒泡排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ for i in range(len(value_list) - 1): for j in range(i + 1, len(value_list)): if value_list[i] > value_list[j]: value_list[i], value_list[j] = value_list[j], value_list[i] sorted_list = value_list return sorted_list
4.快速排序
快速排序(Quick Sort)是對冒泡排序的一種改進,它的基本思想是,通過一趟排序將待排記錄分割成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分記錄的關鍵字小,則可分別對這兩部分記錄繼續進行排序,已達到整個序列有序,其排序思想如下:
首先任意選取一個記錄(通常可選第一個記錄)作為樞軸,然后按下述原則重新排列記錄:將所有關鍵字較它小的記錄都安置在它的位置之前,將所有關鍵字較它大的記錄都安置在它的位置之后,一趟快速排序的具體做法是:設兩個指標low和high,他們的初值分別為最低位置的下一個位置和最高位,設最低位置樞軸的關鍵字為pivotkey,則首先從high所指位置起向前搜索找到第一個關鍵字小于pivotkey的記錄的樞軸記錄互相交換,發生了交換后才從low所指向的位置起向后搜索,找到第一個關鍵字大于pivotkey的記錄和樞軸記錄互相交換,重復這兩步直至low=how為止
如下圖所示:

特別要注意換方向的時機是發生了交換后,用Python實作如下:
def quick_sort(self, value_list): """ 快速排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ low = 0 high = len(value_list) - 1 self.__qsort(value_list, low, high) sorted_list = value_list return sorted_list def __qsort(self, val_list, low, high): """ 快速排序輔助函式 :param val_list: 無序串列 :param low: 低位 :param high: 高位 :return: """ if low >= high: return pivot_key = low temp_low = pivot_key temp_high = high while low < high: # 分成一邊比軸(pivot)大,一邊比軸(pivot)小的順序 while low < high: if val_list[high] < val_list[pivot_key]: temp = val_list[high] val_list[high] = val_list[pivot_key] val_list[pivot_key] = temp pivot_key = high break # 發生交換后,就換方向 else: high -= 1 while low < high: if val_list[low] > val_list[pivot_key]: temp = val_list[low] val_list[low] = val_list[pivot_key] val_list[pivot_key] = temp pivot_key = low break # 發生交換后,就換方向 else: low += 1 self.__qsort(val_list, temp_low, pivot_key - 1) self.__qsort(val_list, pivot_key + 1, temp_high)
5.簡單選擇排序
選擇排序(Selection Sort)是一種簡單直觀的排序演算法,它的基本思想是:每一趟在n-i+1(i=1,2,...,n-1)個記錄中選取關鍵字最小的記錄作為有序序列中第i個記錄,簡單選擇排序:通過n-1次關鍵字的比較,從n-i+1個記錄中選出關鍵字最小的記錄,并和第i(1≤i≤n)個記錄交換之,如下圖所示:

用Python實作如下:
@staticmethod def simple_selection_sort(value_list): """ 簡單選擇排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ for i in range(len(value_list)): min_val = 9999999 for j in range(i, len(value_list)): if min_val > value_list[j]: min_val = value_list[j] count = 0 # 如果有多個相同的最小值 for j in range(i, len(value_list)): if min_val == value_list[j]: value_list[j], value_list[i + count] = value_list[i + count], value_list[j] sorted_list = value_list return sorted_list
6.堆排序
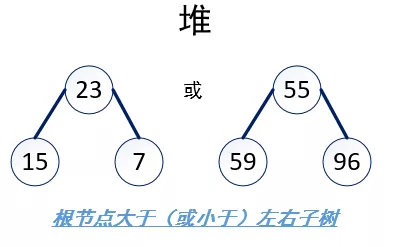
堆排序(Heap Sort)是指利用堆這種資料結構所設計的一種排序演算法,堆的定義如下:
n個元素的序列{k1,k2,...,kn}當且僅當滿足一下關系時,稱之為堆,

若將序列看成是一個完全二叉樹,則堆的含義表明,完全二叉樹中所有非終端節點均不大于(或不小于)其左、右孩子節點的值,由此,若序列是堆,則堆頂元素必為序列中的最小值(或最大值),如下圖所示:
至此,我們可以給出堆排序的程序:若在輸出堆頂的最小值后,使得剩余n-1個元素的序列又建成一個堆,則得到n個元素中的次小值,如此反復執行,便能得到一個有序序列,
故整個堆排序可以大致分為兩個程序:
·將無序序列建成堆,
·輸出堆頂元素后,用類似建堆的方法調整堆,
如下兩個圖所示:

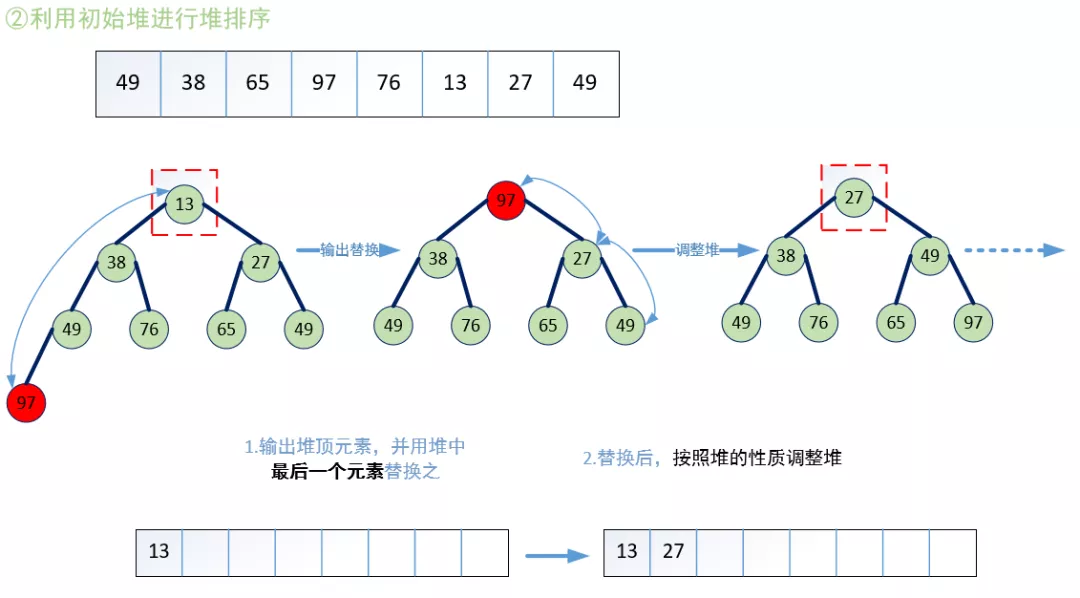
根據堆排序的特點總結出兩點注意事項:
1.利用把堆看成完全二叉樹的特點,用完全二叉樹的性質解決演算法問題,
2.建堆的程序是從樹種的最后一個非終端節點逆序開始調整的,
3.每調整一次需要檢查前后是否依然保持堆的特征,
本文利用了二叉樹的孩子兄弟表示法來生成二叉樹(堆)的,代碼如下:
class CldSibNode(object): """ 私有內部類:孩子兄弟二叉鏈表節點 """ def __init__(self, val): self.value = val self.child = None self.sibling = None def heap_sort(self, value_list): """ 堆排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ sorted_list = [] root_node = self.CldSibNode(None) self.__child_sibling(root_node, value_list, 0) for ct in range(1, len(value_list) // 2 + 1): # 建堆 self.__adjust_heap(root_node, len(value_list) // 2 + 1 - ct, 1) for i in range(1, len(value_list) + 1): # 堆排序 sorted_list.append(root_node.value) # 輸出堆頂元素 head = root_node self.__shrink_heap(root_node, len(value_list) + 1 - i, 1, head) self.__adjust_heap(root_node, 1, 1) # 調整堆 return sorted_list def __child_sibling(self, node, value_list, ind): """ 創建完全二叉樹的左孩子右兄弟二叉鏈表 :param node: 當前節點 :param value_list: 待排序的無序串列 :param ind: :return: """ if ind >= len(value_list): return node.value = value_list[ind] if ind * 2 + 1 < len(value_list): node.child = self.CldSibNode(None) # 孩子 self.__child_sibling(node.child, value_list, ind * 2 + 1) if ind * 2 + 2 < len(value_list): node.child.sibling = self.CldSibNode(None) # 兄弟 self.__child_sibling(node.child.sibling, value_list, ind * 2 + 2) def __adjust_heap(self, root_node, last_ind, now_ind): if not root_node or not root_node.child: # 不為空且有孩子 return if now_ind == last_ind: # 需要調整的非終端節點 temp = root_node cg = False while temp.child: if temp.value > temp.child.value: temp.value, temp.child.value = temp.child.value, temp.value cg = True # 發生交換 if temp.child.sibling: if temp.value > temp.child.sibling.value: if cg: # 如果發生過交換 temp.value, temp.child.value =https://www.cnblogs.com/mayi0312/p/ temp.child.value, temp.value temp.value, temp.child.sibling.value = temp.child.sibling.value, temp.value temp = temp.child.sibling continue else: if cg: # 如果發生過交換 temp = temp.child continue break # 遞回 self.__adjust_heap(root_node.child, last_ind, now_ind * 2) if root_node.child.sibling: self.__adjust_heap(root_node.child.sibling, last_ind, now_ind * 2 + 1) def __shrink_heap(self, root_node, last_ind, now_ind, head): if not root_node or now_ind * 2 > last_ind: # 為空 return if last_ind == now_ind * 2 + 1: head.value = root_node.child.sibling.value root_node.child.sibling = None return True if last_ind == now_ind * 2: head.value = root_node.child.value root_node.child = None return True if root_node.child: self.__shrink_heap(root_node.child, last_ind, now_ind * 2, head) self.__shrink_heap(root_node.child.sibling, last_ind, now_ind * 2 + 1, head)
7.歸并排序
歸并排序(Merging Sort),“歸并”的含義是將兩個或兩個以上的有序表組合成一個新的有序表,假設初始序列有n個記錄,則可看成是n個有序的子序列,每個子序列的長度為1,然后兩兩歸并,得到[n/2]個長度為2或1的有序子序列;再兩兩歸并,……,如此重復,直至得到一個長度為n的有序序列為止,這種排序方法為2-路歸并排序,演算法的基本思想如下圖所示:
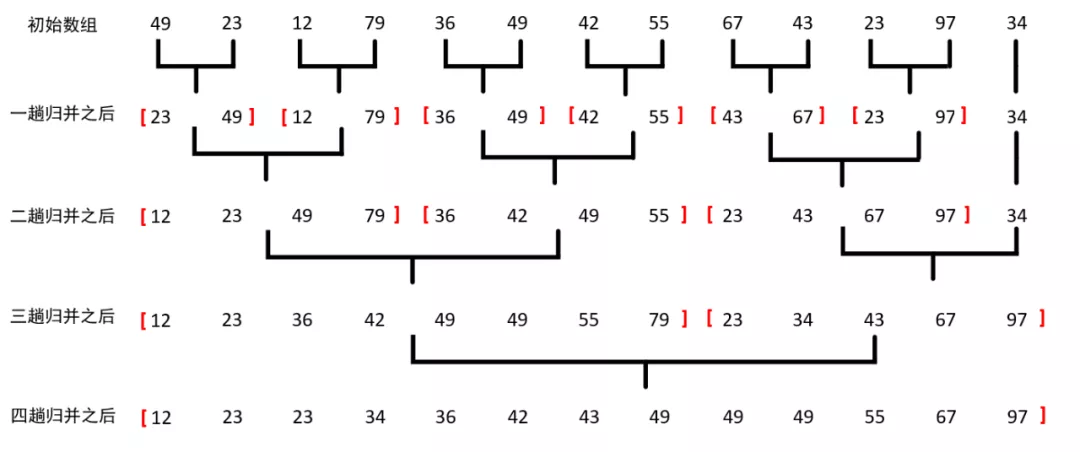
其中兩個子序列的合并大有學問,基本思想就是:分別在兩個序列頭設定指標,比較兩個序列指標所指的值的大小,將滿足要求的值提取出來形成新串列,并將指標右移,當其中一個指標指向結尾之后時,表示其中一個串列已取盡,接著直接在新串列尾部連接另一個串列,如下圖所示:
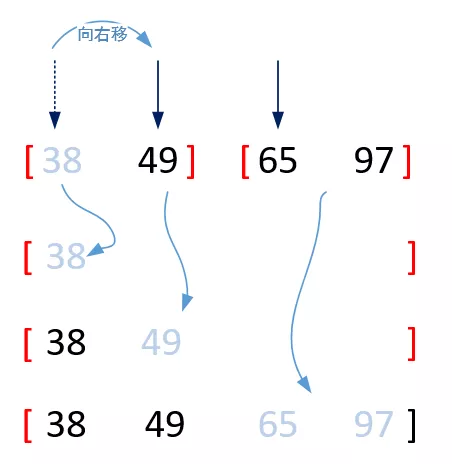
用Python實作如下:
@staticmethod def merging_sort(self, value_list): """ 歸并排序 :param value_list: 待排序的無序串列 :return: 排序后的新串列 """ i = 0 while np.power(2, i) < len(value_list): count = np.power(2, i) start = 0 outer_temp = [] while start < len(value_list): # 定位另一邊 other = start + count temp = [] if other >= len(value_list): # 另一邊不存在:直接合并 outer_temp.extend(value_list[start: start + count]) break left, right = 0, 0 while left < count or right < count: if other + right >= len(value_list): # 右邊提前結束 temp.extend(value_list[start + left: start + count]) break elif value_list[start + left] < value_list[other + right]: # 左邊更小 temp.append(value_list[start + left]) left += 1 if left == count: # 左邊遍歷結束 temp.extend(value_list[other + right: other + count]) break else: # 右邊更小 temp.append(value_list[other + right]) right += 1 if right == count: # 右邊遍歷結束 temp.extend(value_list[start + left: start + count]) break outer_temp.extend(temp) start += count * 2 value_list = outer_temp i += 1 sorted_list = value_list return sorted_list
8.基數排序
基數排序(Radix Sort)是一種非比較整數排序演算法,其原理是將整數按位數切割成不同的數字,然后按每個位數分別比較,由于整數也可以表達字串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用于整數,

排序時有兩點需要注意:
1.每完成一趟排序,要清空佇列,
2.佇列的連接要找到第一個不為空的佇列作為頭,和繞開所有空佇列,
用Python實作如下:
@staticmethod def radix_sort(value_list): """ 基數排序 :param value_list: 待排序的無序串列 :return: 排序后的新串列 """ i = 0 max_num = max(value_list) n = len(str(max_num)) while i < n: # 初始化桶陣列 bucket_list = [[] for _ in range(10)] for x in value_list: # 找到位置放入桶陣列 bucket_list[int(x / (10 ** i)) % 10].append(x) value_list.clear() for x in bucket_list: # 放回原序列 for y in x: value_list.append(y) i += 1 sorted_list = value_list return sorted_list
測驗代碼:
撰寫測驗代碼運行結果如下:
if __name__ == '__main__': li = list(np.random.randint(1, 1000, 30)) my_sort = MySort() print("original sequence:", li) print("*" * 100) print("1.straight_insertion_sort:", my_sort.straight_insertion_sort(li.copy())) print("2.shells_sort:", my_sort.shells_sort(li.copy())) print("3.bubble_sort:", my_sort.bubble_sort(li.copy())) print("4.quick_sort:", my_sort.quick_sort(li.copy())) print("5.simple_selection_sort:", my_sort.simple_selection_sort(li.copy())) print("6.heap_sort:", my_sort.heap_sort(li.copy())) print("7.merging_sort:", my_sort.merging_sort(li.copy())) print("8.radix_sort:", my_sort.radix_sort(li.copy()))
測驗運行結果:
original sequence: [424, 381, 234, 405, 554, 742, 527, 876, 27, 904, 169, 566, 854, 448, 65, 508, 226, 477, 12, 670, 408, 520, 774, 99, 159, 565, 393, 288, 149, 711] **************************************************************************************************** 1.straight_insertion_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 2.shells_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 3.bubble_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 4.quick_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 5.simple_selection_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 6.heap_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 7.merging_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904] 8.radix_sort: [12, 27, 65, 99, 149, 159, 169, 226, 234, 288, 381, 393, 405, 408, 424, 448, 477, 508, 520, 527, 554, 565, 566, 670, 711, 742, 774, 854, 876, 904]
總結
各個排序效率見下圖:

可以得出以下幾個結論:
1.從平均時間性能而言,快速排序最佳,
2.堆排序適用于n較大的資料,
3.基數排序是穩定的,時間復雜度較大的簡單排序方法也是穩定的,
4.穩定性是由方法本身決定的,
5.沒有最好的排序方法,視情況而定,


#! /usr/bin/env python3 # -*- coding:utf-8 -*- # Author : MaYi # Blog : http://www.cnblogs.com/mayi0312/ # Date : 2020-01-06 # Name : mySort # Software : PyCharm # Note : 八大排序演算法 import numpy as np class MySort(object): """ 自定義一個排序的類 """ def straight_insertion_sort(self, value_list): """ 直接插入排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ return self.__straight_insert(value_list) @staticmethod def __straight_insert(value_list): sorted_list = [] sorted_list.append(value_list.pop(0)) for i in range(0, len(value_list)): tail = True # 是否在尾部插入 insert_loc = 0 for j in range(len(sorted_list)): if value_list[i] <= sorted_list[j]: tail = False insert_loc = j break sorted_list.append(value_list[i]) # 先將值插入尾部 if not tail: # 移動值 for j in range(len(sorted_list) - 1, insert_loc, -1): sorted_list[j], sorted_list[j - 1] = sorted_list[j - 1], sorted_list[j] return sorted_list def shells_sort(self, value_list): """ 希爾排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ gap = len(value_list) // 2 while gap >= 1: i = 0 while(i + gap) < len(value_list): start = i gap_list = [] while start < len(value_list): gap_list.append(value_list[start]) start = start + gap gap_list = self.__straight_insert(gap_list) start = i while start < len(value_list): value_list[start] = gap_list.pop(0) start += gap i += 1 gap //= 2 sorted_list = value_list return sorted_list @staticmethod def bubble_sort(value_list): """ 冒泡排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ for i in range(len(value_list) - 1): for j in range(i + 1, len(value_list)): if value_list[i] > value_list[j]: value_list[i], value_list[j] = value_list[j], value_list[i] sorted_list = value_list return sorted_list def quick_sort(self, value_list): """ 快速排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ low = 0 high = len(value_list) - 1 self.__qsort(value_list, low, high) sorted_list = value_list return sorted_list def __qsort(self, val_list, low, high): """ 快速排序輔助函式 :param val_list: 無序串列 :param low: 低位 :param high: 高位 :return: """ if low >= high: return pivot_key = low temp_low = pivot_key temp_high = high while low < high: # 分成一邊比軸(pivot)大,一邊比軸(pivot)小的順序 while low < high: if val_list[high] < val_list[pivot_key]: temp = val_list[high] val_list[high] = val_list[pivot_key] val_list[pivot_key] = temp pivot_key = high break # 發生交換后,就換方向 else: high -= 1 while low < high: if val_list[low] > val_list[pivot_key]: temp = val_list[low] val_list[low] = val_list[pivot_key] val_list[pivot_key] = temp pivot_key = low break # 發生交換后,就換方向 else: low += 1 self.__qsort(val_list, temp_low, pivot_key - 1) self.__qsort(val_list, pivot_key + 1, temp_high) @staticmethod def simple_selection_sort(value_list): """ 簡單選擇排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ for i in range(len(value_list)): min_val = 9999999 for j in range(i, len(value_list)): if min_val > value_list[j]: min_val = value_list[j] count = 0 # 如果有多個相同的最小值 for j in range(i, len(value_list)): if min_val == value_list[j]: value_list[j], value_list[i + count] = value_list[i + count], value_list[j] sorted_list = value_list return sorted_list class CldSibNode(object): """ 私有內部類:孩子兄弟二叉鏈表節點 """ def __init__(self, val): self.value = val self.child = None self.sibling = None def heap_sort(self, value_list): """ 堆排序 :param value_list: 待排序的無序串列 :return: 排序后的串列 """ sorted_list = [] root_node = self.CldSibNode(None) self.__child_sibling(root_node, value_list, 0) for ct in range(1, len(value_list) // 2 + 1): # 建堆 self.__adjust_heap(root_node, len(value_list) // 2 + 1 - ct, 1) for i in range(1, len(value_list) + 1): # 堆排序 sorted_list.append(root_node.value) # 輸出堆頂元素 head = root_node self.__shrink_heap(root_node, len(value_list) + 1 - i, 1, head) self.__adjust_heap(root_node, 1, 1) # 調整堆 return sorted_list def __child_sibling(self, node, value_list, ind): """ 創建完全二叉樹的左孩子右兄弟二叉鏈表 :param node: 當前節點 :param value_list: 待排序的無序串列 :param ind: :return: """ if ind >= len(value_list): return node.value = value_list[ind] if ind * 2 + 1 < len(value_list): node.child = self.CldSibNode(None) # 孩子 self.__child_sibling(node.child, value_list, ind * 2 + 1) if ind * 2 + 2 < len(value_list): node.child.sibling = self.CldSibNode(None) # 兄弟 self.__child_sibling(node.child.sibling, value_list, ind * 2 + 2) def __adjust_heap(self, root_node, last_ind, now_ind): if not root_node or not root_node.child: # 不為空且有孩子 return if now_ind == last_ind: # 需要調整的非終端節點 temp = root_node cg = False while temp.child: if temp.value > temp.child.value: temp.value, temp.child.value = temp.child.value, temp.value cg = True # 發生交換 if temp.child.sibling: if temp.value > temp.child.sibling.value: if cg: # 如果發生過交換 temp.value, temp.child.value =https://www.cnblogs.com/mayi0312/p/ temp.child.value, temp.value temp.value, temp.child.sibling.value = temp.child.sibling.value, temp.value temp = temp.child.sibling continue else: if cg: # 如果發生過交換 temp = temp.child continue break # 遞回 self.__adjust_heap(root_node.child, last_ind, now_ind * 2) if root_node.child.sibling: self.__adjust_heap(root_node.child.sibling, last_ind, now_ind * 2 + 1) def __shrink_heap(self, root_node, last_ind, now_ind, head): if not root_node or now_ind * 2 > last_ind: # 為空 return if last_ind == now_ind * 2 + 1: head.value = root_node.child.sibling.value root_node.child.sibling = None return True if last_ind == now_ind * 2: head.value = root_node.child.value root_node.child = None return True if root_node.child: self.__shrink_heap(root_node.child, last_ind, now_ind * 2, head) self.__shrink_heap(root_node.child.sibling, last_ind, now_ind * 2 + 1, head) @staticmethod def merging_sort(value_list): """ 歸并排序 :param value_list: 待排序的無序串列 :return: 排序后的新串列 """ i = 0 while np.power(2, i) < len(value_list): count = np.power(2, i) start = 0 outer_temp = [] while start < len(value_list): # 定位另一邊 other = start + count temp = [] if other >= len(value_list): # 另一邊不存在:直接合并 outer_temp.extend(value_list[start: start + count]) break left, right = 0, 0 while left < count or right < count: if other + right >= len(value_list): # 右邊提前結束 temp.extend(value_list[start + left: start + count]) break elif value_list[start + left] < value_list[other + right]: # 左邊更小 temp.append(value_list[start + left]) left += 1 if left == count: # 左邊遍歷結束 temp.extend(value_list[other + right: other + count]) break else: # 右邊更小 temp.append(value_list[other + right]) right += 1 if right == count: # 右邊遍歷結束 temp.extend(value_list[start + left: start + count]) break outer_temp.extend(temp) start += count * 2 value_list = outer_temp i += 1 sorted_list = value_list return sorted_list @staticmethod def radix_sort(value_list): """ 基數排序 :param value_list: 待排序的無序串列 :return: 排序后的新串列 """ i = 0 max_num = max(value_list) n = len(str(max_num)) while i < n: # 初始化桶陣列 bucket_list = [[] for _ in range(10)] for x in value_list: # 找到位置放入桶陣列 bucket_list[int(x / (10 ** i)) % 10].append(x) value_list.clear() for x in bucket_list: # 放回原序列 for y in x: value_list.append(y) i += 1 sorted_list = value_list return sorted_list if __name__ == '__main__': li = list(np.random.randint(1, 1000, 30)) my_sort = MySort() print("original sequence:", li) print("*" * 100) print("1.straight_insertion_sort:", my_sort.straight_insertion_sort(li.copy())) print("2.shells_sort:", my_sort.shells_sort(li.copy())) print("3.bubble_sort:", my_sort.bubble_sort(li.copy())) print("4.quick_sort:", my_sort.quick_sort(li.copy())) print("5.simple_selection_sort:", my_sort.simple_selection_sort(li.copy())) print("6.heap_sort:", my_sort.heap_sort(li.copy())) print("7.merging_sort:", my_sort.merging_sort(li.copy())) print("8.radix_sort:", my_sort.radix_sort(li.copy()))完整代碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/113031.html
標籤:其他