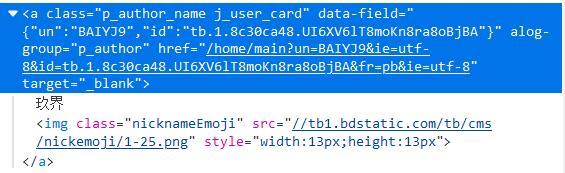
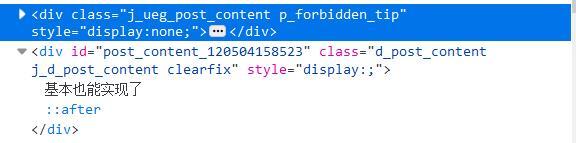
新手,打算練習爬貼吧,書是17年的,遇見下面這兩段網頁代碼,不會用正則運算式,怎么才能把里面的漢字提取出來?
uj5u.com熱心網友回復:
def test_re():
import re
test_html = '''
<span class="title text_overflow">怎么用正則運算式提取以下兩段代碼里的文字</span>
<span>
問題點數:20分</span>
'''
pattern = re.compile(r'<[^>]+>', re.S)
result = pattern.sub('', test_html)
print(result)
test_re()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/113801.html
上一篇:銳捷AP版本RG10.4配置模板