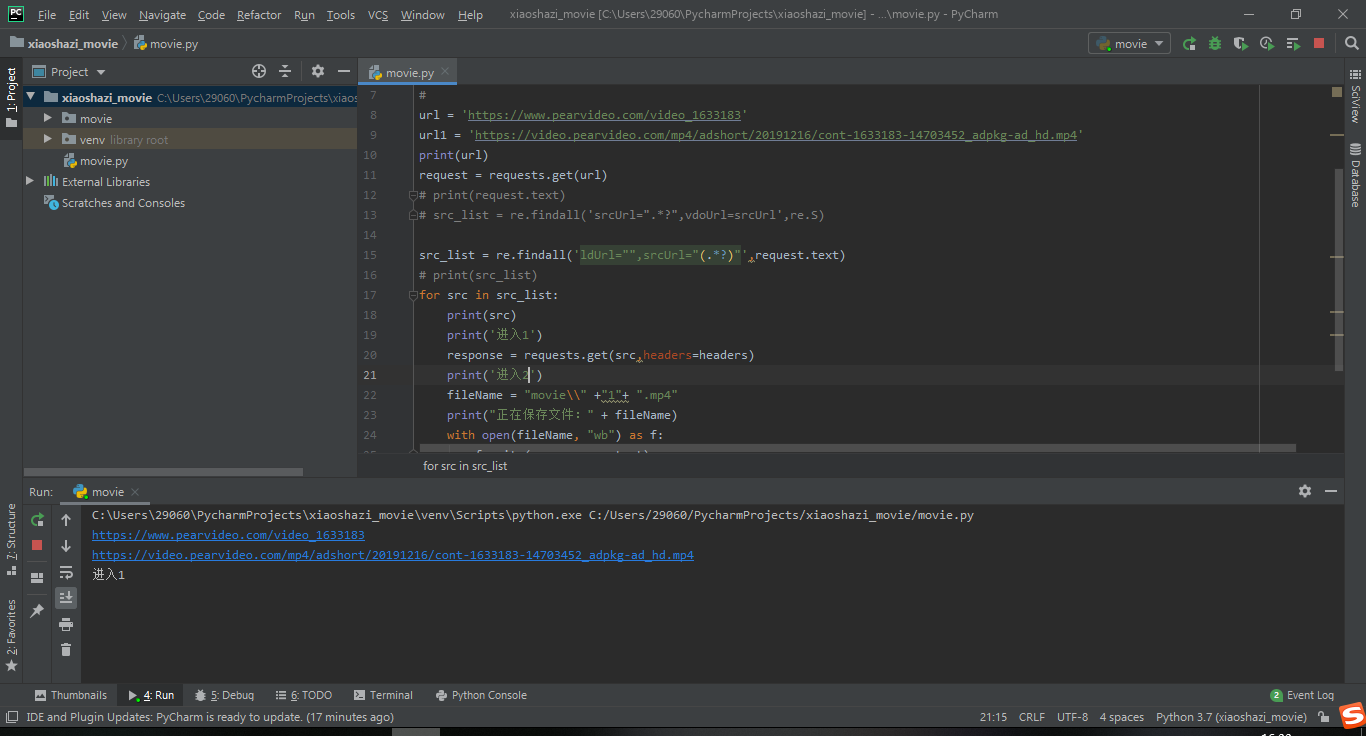
import requests
import re
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"referer": "https://video.pearvideo.com"
}
#
url = 'https://www.pearvideo.com/video_1633183'
url1 = 'https://video.pearvideo.com/mp4/adshort/20191216/cont-1633183-14703452_adpkg-ad_hd.mp4'
print(url)
request = requests.get(url)
# print(request.text)
# src_list = re.findall('srcUrl=".*?",vdoUrl=srcUrl',re.S)
src_list = re.findall('ldUrl="",srcUrl="(.*?)"',request.text)
# print(src_list)
for src in src_list:
print(src)
print('進入1')
response = requests.get(src,headers=headers)
print('進入2')
fileName = "movie\\" +"1"+ ".mp4"
print("正在保存檔案:" + fileName)
with open(fileName, "wb") as f:
f.write(response.content)
uj5u.com熱心網友回復:
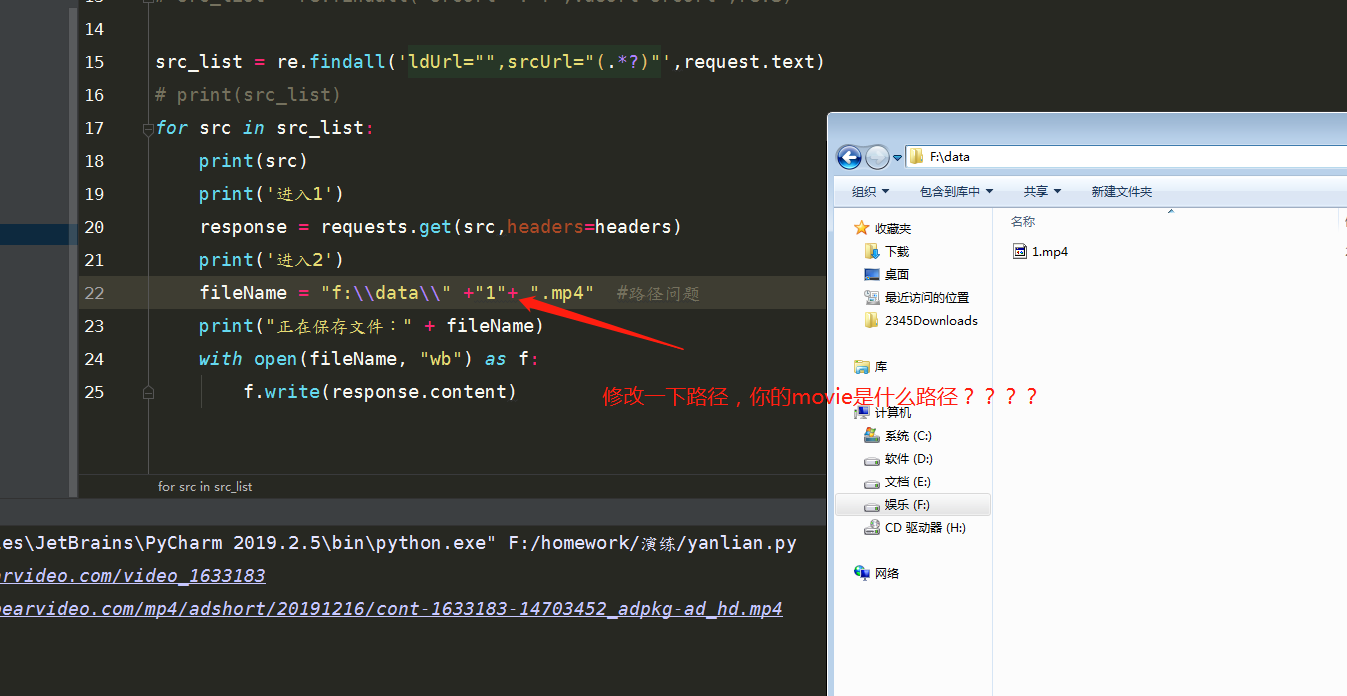
指定檔案存盤路徑,建議放在當前路徑可以使用./
uj5u.com熱心網友回復:
你實在要存放在你指定的路徑可以使用os模塊的chdir方法,了解一下,非常強大uj5u.com熱心網友回復:
謝謝大佬,我以為放在專案檔案里就可以了
uj5u.com熱心網友回復:
放在專案里面也是可以的,路徑前面加一個../表示上一層路徑
uj5u.com熱心網友回復:
搞錯了,當前路徑直接with open就可以了,其他路徑的話在with open里面寫新路徑,別給帶歪了uj5u.com熱心網友回復:
。。。直接進入1 跑完進去不到2了這是為啥?根本獲取不到uj5u.com熱心網友回復:
貼下圖啊
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/113812.html