本文是用機器學習打造聊天機器人系列的第六篇,主要介紹代碼中用到的相關演算法的原理,了解演算法原理,可以讓我們知道程式背后都做了些什么,為什么有時候會出現錯誤以及什么場景下選擇哪種演算法會更合適,
- word2vec 我們使用的詞向量模型就是基于word2vec訓練的,word2vec 是 Google 在 2013 年推出的一個 NLP 工具,它的特點 是將所有的詞向量化,這樣詞與詞之間就可以定量的去度量他們之間 的關系,挖掘詞之間的聯系,
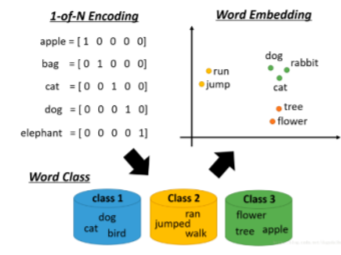
word2vec 基于分布式表征(Dristributed Representation)的 思想,相比于 One hot 可以用更低維數的向量表示詞匯, 有一個有趣的研究表明,用詞向量表示我們的詞時,我們可以發 現:King - Man + Woman = Queen, word2vec 實作了 CBOW 和 Skip-Gram 兩個神經網路 模型,SkyAAE 在訓練詞向量的時候就是使用的 CBOW 模型,
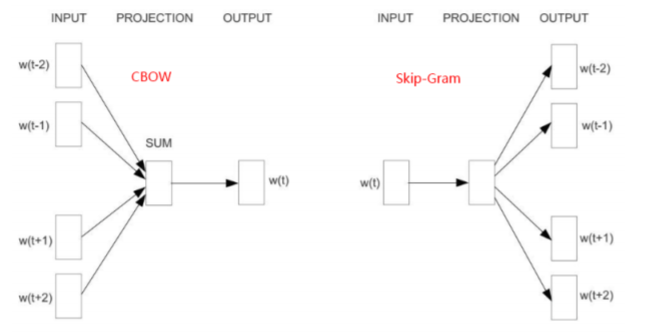
CBOW(Continuous Bag-of-Words,連續詞袋)的核心思想是可 以用一個詞的周圍的詞來預測這個詞,該模型的訓練輸入是某一個特 征詞的背景關系相關的詞對應的詞向量,而輸出就是這特定的一個詞的 詞向量, 比如這段話:“...an efficient method for 【learning】 high quality distributed vector...”,我們要預測 learning,則 可以選取背景關系大小為 4,也就是我們需要輸出的詞向量,背景關系對 應的詞有 8 個,前后各 4 個,這 8 個詞是我們模型的輸入,由于 CBOW 使用的是詞袋模型,因此這 8 個詞都是平等的,也就是不考慮他們和 我們關注的詞之間的距離大小,只要在我們背景關系之內即可,與 CBOW 相對應的是 Skip-Gram 模型,核心思想是可以用當前詞去預測該詞的 周圍的詞, 可以看出,當word2vec模型訓練好了之后,詞的向量表征也就確定了,以后再次使用的時候,輸入一個詞,模型就給你那個確定的向量,所以我們表示一個句子的時候,需要先分詞,然后分別取出詞的向量,然后通過一些方式將這些向量融合在一起來表示整個句子,比如累加后除以分詞串列的長度,
- 余弦相似度 我們在語意匹配階段使用的演算法就是余弦相似度,余弦相似度是指通過測量兩個向量的夾角的余弦值來度量它們 之間的相似性,我們知道,0 度角的余弦值是 1,而其他任何角度的 余弦值都不大于 1;并且其最小值是-1,但是余弦相似度通常用于 正空間,因此給出的值為 0 到 1 之間,兩個向量有相同的指向時, 余弦相似度的值為 1;兩個向量夾角為 90°時,余弦相似度的值為 0,所以兩個向量之間的角度的余弦值可以確定兩個向量是否大致指 向相同的方向,具體公式如下:
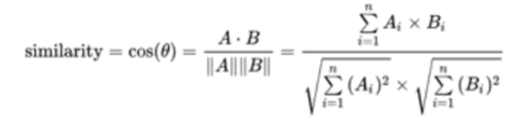
- 樸素貝葉斯 我們在意圖分類階段使用了多項式樸素貝葉斯演算法來將輸入的問題分到對應的意圖類別下,讓我們先來看看什么式樸素貝葉斯,樸素貝葉斯演算法是基于貝葉斯定理與特征條件獨立假設的分類 方法, 貝葉斯公式推導程序:
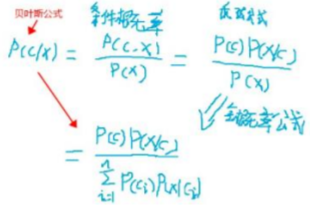
c 隨機事件的其中一種情況,比如電影領域問答中的意圖分類可能包括:閑聊,評分,上映時間,演員等,把用戶問問題看成是隨機事件,則用戶問評分的問題就是隨機事件的其中一種情況, x 泛指與隨機事件相關的因素,這里做為概率的條件, P(c|x) 條件 x 下,c 出現的概率,比如 P(“評分”|“功夫這部電影評分怎么樣?”)就是表示問題“功夫這部電影評分怎么樣?”的意圖是“評分”的概率, P(x|c) 知出現 c 情況的條件下,條件 x 出現的概率,后驗概率,可以根據歷史資料計算得出, P(c) 不考慮相關因素,c 出現的概率, P(x) 不考慮相關因素,x 出現的概率, 由推導程序可以得到 P(c|x) = P(c)P(x|c)/P(x) 假設我們有電影領域問題和所屬意圖分類的資料集,那么P(c(i))=c(i)出現的次數/所有情況出現的總次數,(例如:c(i)可能是‘評分’意圖或者‘上映時間’意圖); 根據特征條件獨立假設的樸素思想可以得出如下式子: p(x|c) = Πp(xi|c) (1<=i<=d),d 為屬性的個數 至此得到樸素貝葉斯的具體公式:(這里的 c 就是 c(i))
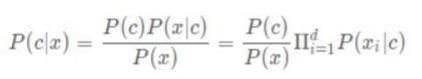
利用該公式進行分類的思想就是計算所有的 p(c(i)|x),然后取值(概率)最大的 c(i)做為所屬分類,用公式表達如下:
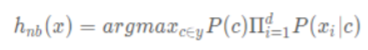
h 是基于樸素貝葉斯演算法訓練出來的 hypothesis(假設),它的值就是貝葉斯分類器對于給定的 x 因素下,最可能出現的情況c,y 是 c 的取值集合,這里去掉了 P(x)是因為它和 c 的概率沒有關系,不影響取最大的 c, 樸素貝葉斯直觀上理解,就是和樣本屬性以及樣本類別的出現頻率有關,利用已有的樣本屬性和樣本類別計算出的各個概率,來代入新的樣本的算式中算出屬于各類別的概率,取出概率最大的做為新樣本的類別, 所以為了計算準確,要滿足如下幾個條件: ? 各類別下的訓練樣本數量盡可能均衡 ? 各訓練樣本的屬性取值要覆寫所有可能的屬性的值 ? 引入拉普拉斯修正進行平滑處理,
- 多項式樸素貝葉斯 再選擇樸素貝葉斯分類的時候,我們使用了one-hot的思想來構建句向量,其中的值都是0或1的離散型特征,所以使用多項式模型來計算 p(xi|c)會更合適(對于連續性的值,選用高斯模型更合適):
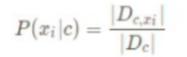
Dc 表示訓練集 D 中第 c 類樣本組成的集合,外加兩條豎線 表示集合的元素數量; Dc,xi 表示 Dc 中第 i 個特征上取值為 xi 的樣本組成的集 合, 為避免出現某一維特征的值 xi 沒在訓練樣本中與 c 類別同時出 現過,導致后驗概率為 0 的情況,會做一些平滑處理:
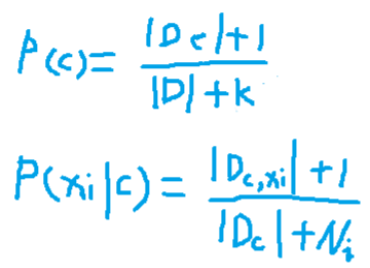
K表示總的類別數; Ni表示第 i 個特征可能的取值的數量,
- 萊文斯坦距離 chatterbot的默認語意匹配演算法采用的就是萊文斯坦距離,該演算法又稱Levenshtein距離,是編輯距離的一種,指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數,允許的編輯操作包括將一個字符替換成另一個字符,插入一個字符,洗掉一個字符,例如將kitten轉成sitting: kitten(k→s)sitten (e→i)sittin (→g)sitting 該演算法的邏輯清晰簡潔,但做為聊天機器人的語意匹配演算法還是太簡單了,所以我們并沒有選擇使用,具體原因在《手把手教你打造聊天機器人(三) 設計篇》中已經詳細介紹,這里不再贅述,
本文是"手把手教你打造聊天機器人"系列的最后一篇,介紹了我們打造的聊天機器人的相關演算法原理,下一篇會對本系列做一個總結,
ok,本篇就這么多內容啦~,感謝閱讀O(∩_∩)O,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/114559.html
標籤:其他
上一篇:基于密度的網頁串列抽取
下一篇:leetcode——二分