作者|LAKSHAY ARORA
編譯|Flin
來源|analyticsvidhya
介紹
你上一次學習新的Python技巧是什么時候?作為資料科學家,我們習慣于使用熟悉的庫并每次都呼叫相同的函式,現在該打破舊的慣例了!
Python不僅限于Pandas,NumPy和scikit-learn(盡管它們在資料科學中絕對必不可少)!我們可以使用大量的Python技巧來改進代碼,加速資料科學任務并提高撰寫代碼的效率,
更重要的是,學習我們可以在Python中做的新事情真的非常有趣!我喜歡玩各種不同的程式包和函式,每隔一段時間,就會有一個新的花樣吸引我,我將其融入我的日常作業,

因此,我決定在一個地方整理我最喜歡的Python技巧——本文!此串列的范圍從加快基本資料科學任務(如預處理)到在同一Jupyter Notebook中獲取R和Python代碼不等,有大量的學習任務在等著我們,讓我們開始吧!
Python和資料科學世界的新手?這是一門精妙而全面的課程,可幫助你同時入門:
- 應用機器學習——從入門到專業
- https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional
1. zip:在Python中合并多個串列
通常我們最侄訓寫出復雜的for回圈以將多個串列組合在一起,聽起來很熟悉?那么你會喜歡zip函式的,這個zip函式的目的是“創建一個迭代器,從每個iterable中聚合元素”,
讓我們通過一個簡單的示例來了解如何使用zip函式并組合多個串列:
https://id.analyticsvidhya.com/auth/login/?next=https://www.analyticsvidhya.com/blog/2019/08/10-powerful-python-tricks-data-science

看到合并多個串列有多容易了嗎?
2. gmplot:在Google Maps的資料集中繪制GPS坐標
我喜歡使用Google Maps資料,想想看,它是最豐富的資料應用程式之一,這就是為什么我決定從這個Python技巧開始的原因,
當我們想查看兩個變數之間的關系時,使用散點圖是非常好的,但是如果變數是一個位置的經緯度坐標,你會使用它們嗎?可能不會,最好把這些點標在真實的地圖上,這樣我們就可以很容易地看到并解決某個特定的問題(比如優化路線),
gmplot提供了一個令人驚嘆的界面,可以生成HTML和JavaScript,將我們想要的所有資料呈現在Google Maps之上,讓我們來看一個如何使用gmplot的例子,
安裝gmplot
!pip3 install gmplot
在Google地圖上繪制位置坐標
你可以在此處下載此代碼的資料集,
- https://drive.google.com/file/d/1VS292bhx_caAamNGY1bRrAySABMNSAhH/view?usp=sharing
讓我們匯入庫并讀取資料:
import pandas as pd
import gmplot
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv('3D_spatial_network.csv')
data.head()
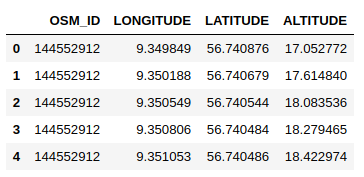
# latitude and longitude list
latitude_list = data['LATITUDE']
longitude_list = data['LONGITUDE']
# center co-ordinates of the map
gmap = gmplot.GoogleMapPlotter( 56.730876,9.349849,9)
# plot the co-ordinates on the google map
gmap.scatter( latitude_list, longitude_list, '# FF0000', size = 40, marker = True)
# the following code will create the html file view that in your web browser
gmap.heatmap(latitude_list, longitude_list)
gmap.draw( "mymap.html" )
上面的代碼將生成HTML檔案,你可以看到Google地圖上繪制了緯度和經度坐標,熱圖以紅色顯示具有高密度點的區域,很酷吧?
3. category_encoders:使用15種不同的編碼方案對分類變數進行編碼
我們在早期資料科學資料集中面臨的最大障礙之一 —— 我們應該如何處理分類變數?我們的機器眨眼間就可以處理數字,但是處理類別卻是一個完全不同的問題,
一些機器學習演算法可以自己處理分類變數,但是我們需要將它們轉換為數值變數,為此,category_encoders是一個了不起的庫,提供了15種不同的編碼方案,
讓我們看看如何利用這個庫,
安裝 category-encoders
!pip3 install category-encoders
將分類資料轉換為數值資料
import pandas as pd
import category_encoders as ce
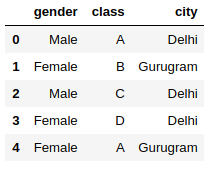
# create a Dataframe
data = https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'gender' : ['Male', 'Female', 'Male', 'Female', 'Female'],
'class' : ['A','B','C','D','A'],
'city' : ['Delhi','Gurugram','Delhi','Delhi','Gurugram'] })
data.head()
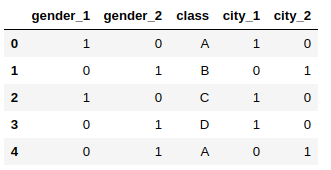
# One Hot Encoding
# create an object of the One Hot Encoder
ce_OHE = ce.OneHotEncoder(cols=['gender','city'])
# transform the data
data = https://www.cnblogs.com/panchuangai/p/ce_OHE.fit_transform(data)
data.head()
category_encoders支持大約15種不同的編碼方法,例如:
- 哈希編碼
- LeaveOneOut編碼
- 順序編碼
- 二進制編碼
- 目標編碼
所有編碼器都與 sklearn-transformers 完全兼容,因此可以輕松地在你現有的腳本中使用它們,另外,category_encoders支持NumPy陣列和Pandas資料幀,你可以在此處閱讀有關category_encoders的更多資訊,
- https://github.com/scikit-learn-contrib/categorical-encoding
4. progress_apply:監視你花費在資料科學任務上的時間
你通常花費多少時間來清理和預處理資料?資料科學家通常花費60~70%的時間來清理資料這一說法是正確的,對我們來說,追蹤這一點很重要,對嗎?
我們不想花費數天的時間來清理資料,而忽略其他資料科學步驟,這是progress_apply 函式使我們的研究更加輕松的地方,讓我演示一下它是如何作業的,
讓我們計算所有點到特定點的距離,并查看完成此任務的進度,你可以在此處下載資料集,
- https://drive.google.com/file/d/1VS292bhx_caAamNGY1bRrAySABMNSAhH/view?usp=sharing
import pandas as pd
from tqdm._tqdm_notebook import tqdm_notebook
from pysal.lib.cg import harcdist
tqdm_notebook.pandas()
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv('3D_spatial_network.csv')
data.head()
# calculate the distance of each data point from # (Latitude, Longitude) = (58.4442, 9.3722)
def calculate_distance(x):
return harcdist((x['LATITUDE'],x['LONGITUDE']),(58.4442, 9.3722))
data['DISTANCE'] = data.progress_apply(calculate_distance,axis=1)
你會看到跟蹤我們的代碼進度有多么容易,簡單,高效,
5. pandas_profiling:生成資料集的詳細報告
我們花了很多時間來理解我們得到的資料,這很公平——我們不想在不了解我們正在使用的模型的情況下直接跳入模型構建,這是任何資料科學專案中必不可少的步驟,
pandas_profiling 是一個Python軟體包,可減少執行初始資料分析步驟所需的大量作業,該軟體包只需一行代碼即可生成有關我們資料的詳細報告!
import pandas as pd
import pandas_profiling
# read the dataset
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv('add-your-data-here')
pandas_profiling.ProfileReport(data)
我們可以看到,僅用一行代碼,就得到了資料集的詳細報告:
- 警告,例如: Item_Identifier具有高基數:1559個不同的值警告
- 所有類別變數的頻率計數
- 數字變數的分位數和描述統計
- 相關圖
6. grouper:對時間序列資料進行分組
現在誰不熟悉Pandas?它是最流行的Python庫之一,廣泛用于資料操作和分析,我們知道Pandas有驚人的能力來操縱和總結資料,
我最近在研究一個時間序列問題,發現Pandas有一個我以前從未使用過的 Grouper 函式,我開始對它的使用感到好奇,
事實證明,這個Grouper函式對于時間序列資料分析是一個非常重要的函式,讓我們試試這個,看看它是如何作業的,你可以在這里下載此代碼的資料集,
- https://drive.google.com/file/d/1UXHlP2TcenRFQJi5ZoaFtWpRuSU6AwQk/view?usp=sharing
import pandas as pd
data = https://www.cnblogs.com/panchuangai/p/pd.read_excel('sales-data.xlsx')
data.head()
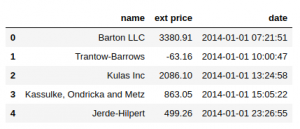
現在,處理任何時間序列資料的第一步是將date列轉換為DateTime格式:
data['date'] = pd.to_datetime(data['date'])
假設我們的目標是查看每個客戶的每月銷售額,我們大多數人都在這里嘗試寫一些復雜的東西,但這是Pandas對我們來說更有用的地方,
data.set_index('date').groupby('name')["ext price"].resample("M").sum()
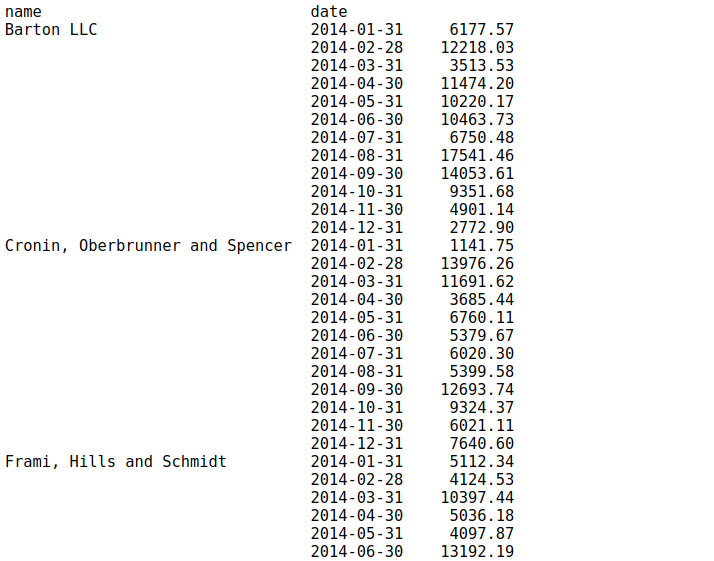
我們可以通過groupby語法使用一種簡單的方法,而不必再進行重新索引,我們將為這個函式添加一些額外的內容,提供一些關于如何在date列中對資料分組的資訊,它看起來更干凈,作業原理完全相同:
data.groupby(['name', pd.Grouper(key='date', freq='M')])['ext price'].sum()
7. unstack:將索引轉換為Dataframe的列
我們剛剛看到了grouper如何幫助對時間序列資料進行分組,現在,這里有一個挑戰——如果我們想將name列(在上面的示例中是索引)作為dataframe的列呢,
這就是unstack函式變得至關重要的地方,讓我們對上面的代碼示例應用unstack函式并查看結果,
data.groupby(['name', pd.Grouper(key='date', freq='M')])['ext price'].sum().unstack()
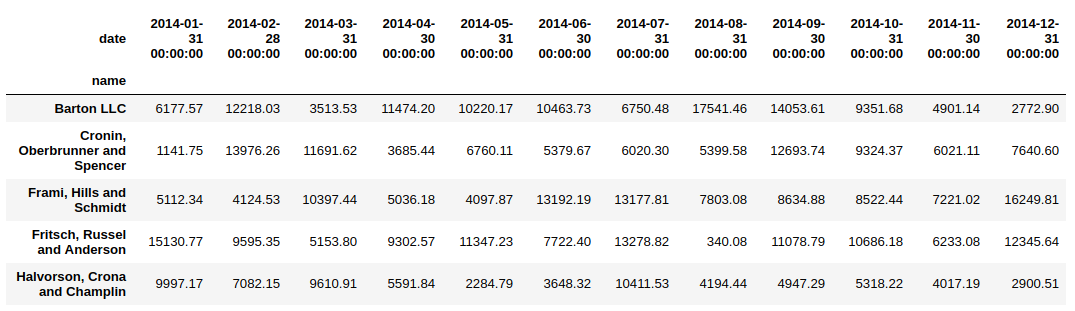
非常有用!注意:如果索引不是MultiIndex,則輸出將是Series,
8.%matplotlib Notebook:Jupyter Notebook中的互動式繪圖
我是matplotlib庫的超級粉絲,它是我們在Jupyter Notebook中用來生成各種圖形的最常見的可視化庫,
要查看這些繪圖,我們通常在匯入matplotlib庫時使用一行——%matplotlib inline,這很好用,它呈現了Jupyter Notebook中的靜態圖,
只需將行 %matplotlib替換為 %matplotlib notebook,就可以看到神奇的效果了,你將在你的 Notebook得到可調整大小和可縮放的繪圖!
%matplotlib notebook
import matplotlib.pyplot as plt
# scatter plot of some data # try this on your dataset
plt.scatter(data['quantity'],data['unit price'])
只需更改一個字,我們就可以獲取互動式繪圖,從而可以在繪圖中調整大小和縮放,
9. %% time:檢查特定Python代碼塊的運行時間
解決一個問題可以有多種方法,作為資料科學家,我們對此非常了解,計算成本在行業中至關重要,尤其是對于中小型組織而言,你可能希望選擇最好的方法,以在最短的時間內完成任務,
實際上,在Jupyter Notebook中檢查特定代碼塊的運行時間非常容易,
只需添加%% time命令來檢查特定單元格的運行時間:
%%time
def myfunction(x) :
for i in range(1,100000,1) :
i=i+1
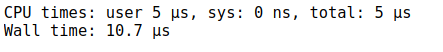
在這里,我們有CPU時間和Wall時間,CPU時間是CPU專用于某個行程的總執行時間或運行時間,Wall時間是指時鐘從流程開始到“現在”之間經過的時間,
10:rpy2:R和Python在同一個Jupyter Notebook中!
R和Python是資料科學世界中最好的和最受歡迎的兩種開源編程語言,R主要用于統計分析,而Python提供了一個簡單的介面,可將數學解決方案轉換為代碼,
這是個好訊息,我們可以在一個Jupyter Notebook中同時使用它們!我們可以利用這兩個生態系統,為此,我們只需要安裝rpy2,
因此,現在暫時擱置R與Python的爭論,并在我們的Jupyter Notebook中繪制ggplot級圖表,
!pip3 install rpy2
我們可以同時使用兩種語言,甚至可以在它們之間傳遞變數,
%load_ext rpy2.ipython
%R require(ggplot2)
import pandas as pd
df = pd.DataFrame({
'Class': ['A', 'A', 'A', 'V', 'V', 'A', 'A', 'A'],
'X': [4, 3, 5, 2, 1, 7, 7, 5],
'Y': [0, 4, 3, 6, 7, 10, 11, 9],
'Z': [1, 2, 3, 1, 2, 3, 1, 2]
})
%%R -i df
ggplot(data = https://www.cnblogs.com/panchuangai/p/df) + geom_point(aes(x = X, y= Y, color = Class, size = Z))
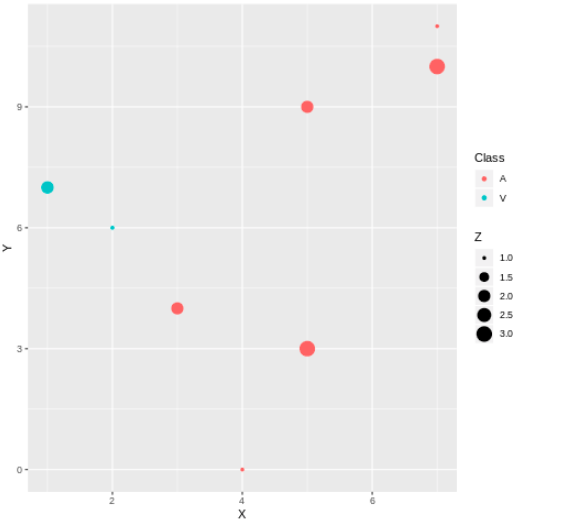
在這里,我們用Python 創建了一個資料框df,并使用它創建了一個使用R的ggplot2庫(geom_point函式)的散點圖,
尾注
這是我必不可少的Python技巧集合,我喜歡在日常任務中使用這些軟體包和功能,老實說,我的作業效率提高了,這使在Python中作業比以往更加有趣,
除了這些之外,你還有什么想讓我知道的Python技巧嗎?在下面的評論部分中告訴我,我們可以交換想法!
而且,如果你是Python的初學者和資料科學的新手,那么你真的應該查看我們全面且暢銷的課程:
- 應用機器學習–從入門到專業
- https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional/
原文鏈接:https://www.analyticsvidhya.com/blog/2019/08/10-powerful-python-tricks-data-science/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/115069.html
標籤:其他
上一篇:python函式式編程
下一篇:創建自己的人臉識別程式