作者|Jerin Paul
編譯|Flin
來源|towardsdatascience
這是一個繁忙的市場場景;七月的烈日在頭頂上照耀,炎熱的天氣并沒有阻止顧客的到來,在人群不知情的情況下,一個懷有惡意的人藏在他們中間,他披著一層正常的外衣,走著去實作他的邪惡目的,
在一個角落里,一個監控攝像頭會定期掃描這個區域,這時它會瞥見這個家伙,它會立刻認出看到的每一張臉,而且碰巧這家伙是一個通緝犯,幾毫秒之內,他附近的警察就得到了警報,他們開始著手消除這一威脅,
這個故事曾經出現在科幻小說中,但現在情況大不相同了,事實上,中國使用人工智能監控工具來監視本國公民,智能手機的創造者也在積極地使用人臉識別來驗證手機用戶的身份,
人臉識別有很多不同的應用程式,不管你希望它用于什么目的,在本文中,我將指導你創建一個自定義的人臉識別程式,你將建立一個小應用程式,可以在視頻剪輯或網路攝像頭中識別你選擇的人臉,

就像你看到的那樣,這就是我們要得到的效果圖,
在本文中,我們將建立一個自定義的人臉識別程式,這篇文章很容易理解,同時也讓你對這個機器學習專案的理論知識方面有所啟發,
這是一個全面的、互動性強的人臉識別初學指南,接下來,我們將創建一個自定義的人臉識別程式,該程式能夠檢測和識別視頻或實時網路攝像頭中的人臉,
目錄
專業提示:如果你想快速完成任務,請跳過理論部分,直接進入第2部分,
-
Facenet
i. Facenet是什么?
ii. Facenet是如何作業的?
iii. 三重損失
-
我們開始構建吧!
i. 先決條件
ii. 下載資料
iii. 下載Facenet
iv. 對齊
v. 獲得預先訓練的模型
vi. 用我們的資料訓練模型
vii. 在視頻源上測驗我們的模型
-
缺點
-
結論
-
參考文獻
Facenet
在這個專案中,我們將使用一個名為Facenet的系統來為我們做人臉識別程式,
Facenet是什么?
Facenet是由Florian Schroff、Dmitry Kalenichenko和James Philbin構建的系統,他們也為此寫了一篇論文,
它直接從人臉影像中學習影像到歐式空間上點的映射,其中距離直接對應于人臉相似度的度量,一旦創建了這些嵌入,就可以使用這些嵌入作為特征來完成人臉識別和驗證等程序,
Facenet是如何作業的?
Facenet使用卷積層直接從人臉的像素學習,該網路在一個大資料集上進行訓練,以實作對光照、姿態和其他可變條件的不變性,該系統是在 Labelled Faces in the wild(http://vis-www.cs.umass.edu/lfw/) 資料集上訓練的,這個資料集包含13000多張從網路上收集的不同人臉的圖片,每個人臉都有一個名字(標簽),
Facenet從影像中創建128維嵌入,并將其插入特征空間,這樣,無論成像條件如何,相同身份之間的特征距離要盡可能的小,而不同身份之間的特征距離要盡可能的大,下圖描述了模型體系結構:
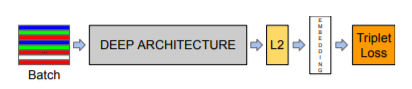
模型結構:模型包含一個批處理輸入層、一個深入學習架構和一個L2層,這就產生了人臉嵌入,
三重損失
該系統采用一種特殊的損失函式,稱為三重損失,三重損失使同一身份的影像之間的L2距離最小,使不同特征的人臉影像之間的L2距離最大,
該系統采用三重損失,更適合于人臉驗證,使用三重損失的動機是它鼓勵將一個身份的所有影像投影到嵌入空間中的一個點上,
三重損失:學習前后
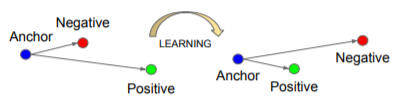
創作者們設計了一種高效的三重選擇機制,可以一次巧妙地選擇三幅影像,這些影像有以下三種型別:
-
錨:一個隨機的人的圖,
-
正圖:同一個人的另一張圖,
-
負圖:另一個人的圖,
測量了兩個歐幾里德距離:一個是錨和正圖之間的距離,我們稱之為A;另一個是錨和負圖之間的距離,我們稱之為B,訓練程序旨在減少A并使B最大化,這樣相似的影像彼此靠近,不同的影像在嵌入空間中會隔得很遠,
開始構建!
最精彩的部分開始了!我們可以使用Facenet為我們自己選擇的人臉創建嵌入,然后訓練支持向量機(Support Vector Machine)使用這些嵌入并進行分類,讓我們開始建立一個自定義的人臉識別程式吧!
你可以看看這個專案的Github存盤庫,因為它包含了一個自定義資料集和用于在視頻中檢測人臉的腳本,
- Github存盤庫
- https://github.com/AssiduousArchitect/face-recognition
先決條件
在開始之前,請確保你的系統上安裝了以下庫:
- tensorflow==1.7
- scipy
- scikit-learn
- opencv-python
- h5py
- matplotlib
- Pillow
- requests
- psutil
下載資料
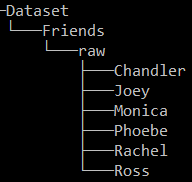
在這個專案中,我們將創建一個人臉識別程式,將能夠識別90年代情景喜劇《老友記》的核心人物,如果你想識別一組不同的人臉,那么就用你的影像來代替,只需確保遵循類似的目錄結構——為要識別的每個身份創建一個檔案夾,并將這些檔案夾存盤在名為“raw”的檔案夾中,
資料集目錄:注意每個角色如何擁有自己對應的檔案夾
在每個檔案夾里放上人物的照片,請注意,每張圖片只有一張清晰可見的臉,盡管只需要很少的影像,我還是為每個角色添加了20個影像,每個檔案夾都有相同數量的圖片,你可以從這里下載我創建的《老友記》的資料集,順便說一下,這是“Chandler”檔案夾的樣子:
下載Facenet
現在已經結束收集資料了,請繼續下載Facenet repo,下載并提取它,并將“Dataset”檔案夾放入其中,
- Facenet repo下載地址
- https://github.com/davidsandberg/facenet
對齊
該模型的一個問題是它可能會漏掉一些人臉標志,為了解決這個問題,我們必須將資料集中的所有影像對齊,使眼睛和嘴唇在所有圖片中顯示在同一位置,我們將使用M.T.C.N.N.(多任務C.N.N.)來執行相同的操作,并將所有對齊的影像存盤在名為processed的檔案夾中,
打開終端/命令提示符并導航到Facenet目錄,然后運行align_dataset_mtcn.py以及以下引數,
python src/align_dataset_mtcnn.py \
./Dataset/Friends/raw \
./Dataset/Friends/processed \
--image_size 160 \
--margin 32 \
--random_order \
--gpu_memory_fraction 0.25
運行此命令將對齊所有影像并將其存盤在各自的檔案夾中,然后將所有內容存盤在“processed”檔案夾中,下圖將向你介紹對齊的作業原理:

所有影像都被裁剪并與標準的160x160像素影像對齊,
獲得預先訓練的模型
現在,為了在你自己的影像上訓練模型,你需要下載預先訓練的模型,請從這里下載,
- https://drive.google.com/file/d/1EXPBSXwTaqrSC0OhUdXNmKSh9qJUQ55-/view
在Facenet根目錄中創建一個名為“Models”的檔案夾,下載完成后,將zip檔案的內容解壓縮到名為“facenet”的目錄中,并將此檔案夾放在“Models”檔案夾中,
這個模型是在LFW資料集上訓練的,因此所有的人臉嵌入都存盤在這些檔案中,這使我們有機會凍結影像,并在我們自己的影像上訓練它,這樣做會將我們提供的所有人臉嵌入到維度空間中,
用我們的資料訓練模型
我們都準備好了!我們有一個預先訓練好的模型,我們的自定義資料集已經對齊并準備好了,現在,是時候訓練模型了!
python src/classifier.py TRAIN \
./Dataset/Friends/processed \
./Models/facenet/20180402-114759.pb \
./Models/Friends/Friends.pkl \
--batch_size 1000
執行上述命令將加載預先訓練的模型并啟動訓練程序,訓練結束后,新影像的嵌入將匯出到/Models/Friends/中,
由于我們使用的是預先訓練的模型和相對較少的影像數量,因此訓練程序很快就結束了,
在視頻源上測驗我們的模型
為了測驗我們的模型,我使用的是來自《老友記》的視頻,你可以用自己的視頻來代替,甚至可以用攝像頭,在本節中,我們將撰寫腳本,以便于在視頻源中進行人臉識別,
導航到“src”檔案夾并創建一個新的python腳本,我給它起名 faceRec.py,
接下來,我們匯入所有必需的庫,
此腳本只接受一個引數,即視頻檔案的路徑,如果沒有提到路徑,那么我們將通過網路攝像頭傳輸視頻,因此,引數的默認值為0,
我們將初始化一些變數,請確保根據檔案夾結構更改路徑,
加載自定義分類器,
設定Tensorflow圖,然后加載Facenet模型,使用GPU將加快檢測和識別程序,
設定輸入和輸出張量,
pnet、rnet和onet是M.T.C.N.N.的組成部分,將用于檢測和對齊人臉,
接下來,我們將創建一個集合和一個來跟蹤檢測到的每個角色的集合,
設定視頻捕獲物件,
因此,如果在運行程式時未將VIDEO_PATH作為引數傳遞,則它將假定默認值為0,如果發生這種情況,視頻捕獲物件將從網路攝像機流式傳輸視頻,
然后逐幀捕獲視頻,并且由檢測人臉模塊在這些幀中檢測人臉,找到的人臉數存盤在faces\u found變數中,
如果找到人臉,那么我們將迭代每個人臉并將邊界框的坐標保存在變數bb中,
然后提取、裁剪、縮放、重塑這些人臉并輸入字典,
我們將使用該模型來預測人臉的身份,我們提取最佳類概率或置信度,這是衡量我們的模型是如何確定預測的身份屬于給定的臉,
最后,我們將在人臉周圍畫一個邊界框,并在邊界框旁邊寫下預測的身份和置信度,如果置信度低于某個閾值,我們將把名字填為未知,
一定要放一個except陳述句,這將確保成功忽略拋出的任何錯誤,確保放置except陳述句,這樣做有助于我們忽略錯誤,
except: pass
顯示視頻并在程序結束后關閉視頻顯示視窗,因為每一幀都要經過大量的處理,所以視頻回放可能會很慢,
恭喜你,你的耐心得到了回報!我們已經完成了腳本,準備好了!快速啟動并執行以下命令以啟動人臉識別程式,請確保將要測驗的視頻的路徑作為引數傳遞,或將其留空以從網路攝像機流式傳輸視頻,
python src/faceRec.py --path ./Dataset/Friends/friends.mp

好吧,這個系統還不完善,還有一些缺點,
缺點
-
系統總是試圖將每個人臉都匹配到一個給定的身份中,如果螢屏上出現新人臉,系統將為其分配一個或另一個身份,這個問題可以通過仔細選擇一個閾值來解決,
-
身份的混淆,在上面的gif中,你可以觀察到Joey和Chandler之間的預測有時是如何波動的,而且,置信度得分也很低,使用更多影像訓練模型將解決此問題,
-
無法在一定距離識別人臉(如果距離很遠使得人臉看起來很小),
結論
無論是判斷你的員工是否出席或在野外尋找違法者,人臉識別技術可以證明是一個真正的保障,這個專案包括創建一個人臉識別程式,可以識別你選擇的人臉,你創建了一個自定義資料集,訓練了模型,并撰寫了腳本以在視頻剪輯上運行人臉識別系統,然而,也有一些缺點,但我們的系統功能還是比較完整的,
參考文獻
https://arxiv.org/abs/1503.03832
原文鏈接:https://towardsdatascience.com/s01e01-3eb397d458d
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/115096.html
標籤:其他