背景
今天優化了一個,join關聯查的陳述句,需要優化join的陳述句,那我們肯定得了解他的一個執行程序,正所謂知己知彼,百戰百勝!!
join的查詢演算法
1. Simple Nested-Loop Join(簡單的嵌套回圈連接)
- 簡單嵌套回圈演算法的查詢程序是嵌套查詢,這個關聯查詢陳述句首先不能確定那個是驅動表,因為使用join的話,mysql的優化器會自己進行索引的選擇(這也時一般情況下DBA不讓join查詢的原因之一),如果a 和 b欄位 在都沒有索引的情況下就會出現這種演算法查詢,
- 查詢程序:先在t1表中將符合條件的欄位a一條查出來然后遍歷t2表遍歷回圈,(但是在mysql中并沒有使用到這個演算法)
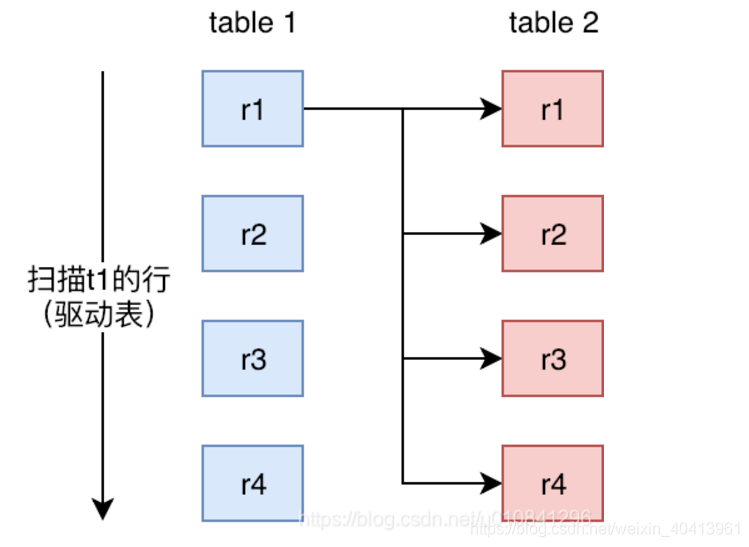
select * from t1 join t2 on t1.a = t2.b
2. Index Nested-Loop Join(索引嵌套回圈連接)
- 在使用了straight_join的意思就是我們明確指出t1是驅動表,t2被驅動表,
- 查詢程序:從t1中拿出一條資料,然后再從t2中使用索引b進行匹配,如果b是個覆寫索引且包含我們所需要的的欄位那這就不用進行回表查詢, 但是如果這些欄位沒有包含全部,那這就得再進行一次回表查詢,那如果驅動表的欄位有索引的話,那查詢的演算法是否一樣呢,其實也是一樣的只不過是驅動表先查走索引,然后再去掃描被驅動表,
- 那么上面的兩種情況我們應該如何選擇那個為驅動表呢,有索引的還沒索引的表呢?我個人覺得這還真不一定,如果一個表只是作為查詢的條件而不要表的欄位且這個表有關聯欄位的索引
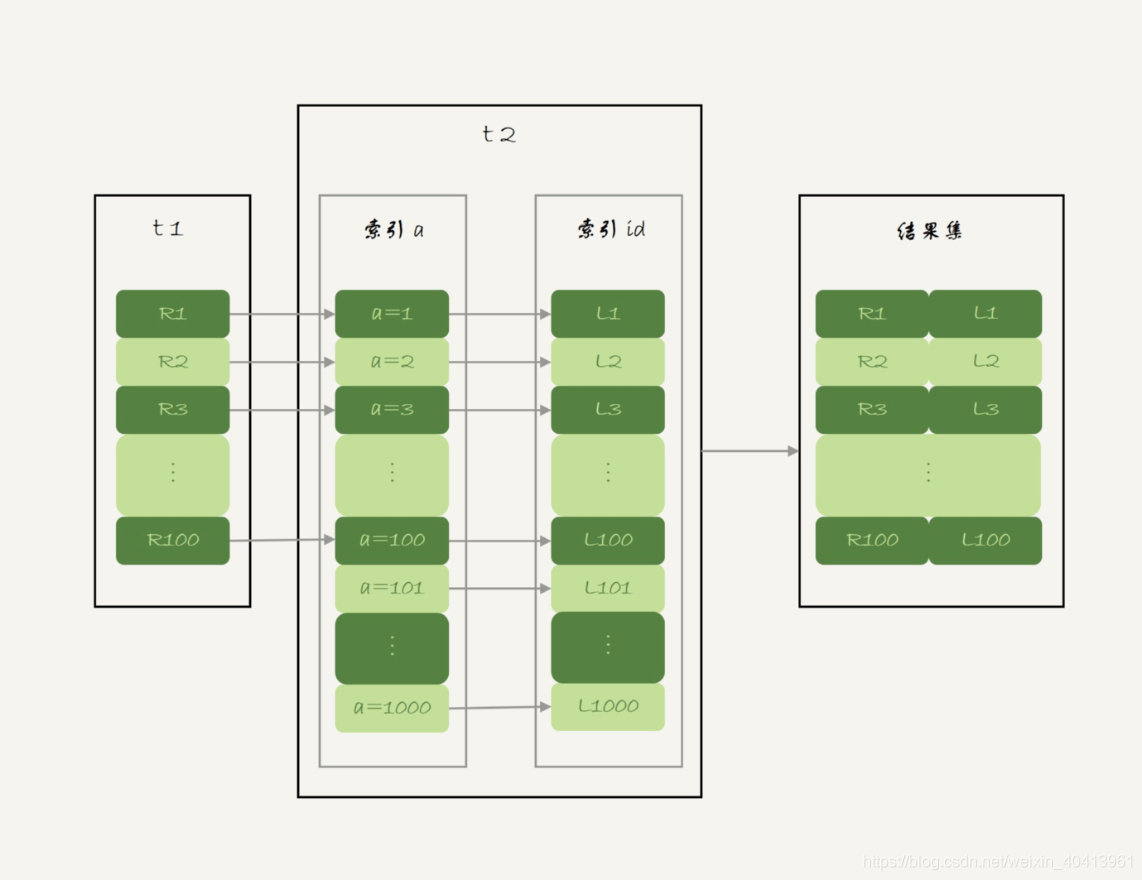
select * from t1 straight_join t2 on t1.a = t2.b(t2中的表欄位有索引)
3. Block Nested-Loop Join(快取塊嵌套回圈連接)
-
剛說的 Simple Nested-Loop Join 演算法在MySQl中沒有使用,那要是兩張表的關聯欄位都沒有使用索引的話,那mysql是如何處理的呢?那就是使用Block Nested-Loop Join這個演算法
-
查詢程序:把表 t1 的資料讀入執行緒記憶體 join_buffer 中,由于我們這個陳述句中寫的是 select *,因此是把整個表 t1 放入了記憶體;掃描表 t2,把表 t2 中的每一行取出來,跟 join_buffer 中的資料做對比,滿足 join 條件的,作為結果集的一部分回傳,

-
但是這個joinbuffer 的大小是有限的,當這個joinbuffer放滿了不能一次性完成查詢的時候的策略是進行多次查詢
- 掃描表 t1,順序讀取資料行放入 join_buffer 中,放完第 88 行 join_buffer 滿了,繼續第 2 步;
- 掃描表 t2,把 t2 中的每一行取出來,跟 join_buffer 中的資料做對比,滿足 join 條件的,作為結果集的一部分回傳;清空 join_buffer;
- 繼續掃描表 t1,順序讀取最后的 12 行資料放入 join_buffer 中,繼續執行第 2 步,
- 就這樣回圈進行得到最后的結果集回傳,
4. Batched Key Access
- NLJ 演算法是先從驅動表讀出一行的資料,再去被驅動表去匹配資料,但是要是兩張表的資料量太大的時候就會出現性能問題,資料庫的演算法優化中有一個MRR優化,其核心思想是進行順序讀,這個順序讀能快的原因就是,mysql索引的存盤方式是以資料頁的形式,每個資料頁的大小是16kb,可以算一下能存盤的資料有多少,如果你是順序讀的話,那就會減少資料頁間的切換,也就是減少的IO操作了,不用多次進行訪問磁盤能提高不少的效率,那要是能讓NLJ能進行順序讀,且能進行批量匹配,那這不就是會快的起飛嗎?
- 這個時候BKA演算法來了,這個演算法是在資料庫版本在5.7以后出現的,也就是對BNL演算法的優化版本,查詢程序是批量讀出驅動表的資料存入buffer中再者進行批量匹配(且這個關聯id是排好序的),然后進行批量匹配查詢,
4. 驅動表的選擇
- 為了高效使用上面所提到的三種join演算法,這就涉及到了驅動表的選擇,
- 如果是 Index Nested-Loop Join 演算法,應該選擇小表做驅動表;如果是 Block Nested-Loop Join 演算法:在 join_buffer_size 足夠大的時候,是一樣的;在 join_buffer_size 不夠大的時候(這種情況更常見),應該選擇小表做驅動表,
- 所以一般遵循的規則就是選擇小表作為驅動表,這里的小表并非是指資料量小的表,而是在進行where條件后進行join buffer里面的資料量少的表,
5. 日常使用
- 其實在我們平常的關聯查詢中,一般都是使用的是主鍵索引與另一個表的唯一索引做關聯的,所以使用到的關聯查詢都是有索引的所以說大都是使用的是Index Nested-Loop Join(5.6版本之前)或者 BKA,所以在平時優化的時候主要還是看where條件,而并非是性能是浪費在了表關聯上,我們在查詢驅動表的時候直接過濾掉了一大部分,然后有根據主鍵id去直接查,這join性能能差嗎?所以平時的優化還是主要是驅動表的選擇和驅動表的查詢性能,驅動表選擇小表,驅動表的索引盡量的ok,
總結
- 講了四種演算法的大概查詢程序
- mysql 3種查詢演算法,有索引 BKA(join buffer) NLJ 沒有索引 BLN (join buffer)
- 驅動表的選擇,選擇小的驅動表(參與joinbuffer資料量少的)
- 日常優化join SQL主要還是驅動表的選擇和驅動表的索引優化
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/116412.html
標籤:其他
上一篇:MySQL8.0基礎操作