寫在前面: 博主是一名大資料行業的追夢人,昵稱來源于《愛麗絲夢游仙境》中的Alice和自己的昵稱,作為一名互聯網小白,
寫博客一方面是為了記錄自己的學習歷程,一方面是希望能夠幫助到很多和自己一樣處于起步階段的萌新,由于水平有限,博客中難免會有一些錯誤,有紕漏之處懇請各位大佬不吝賜教!個人小站:http://alices.ibilibili.xyz/ , 博客主頁:https://alice.blog.csdn.net/
盡管當前水平可能不及各位大佬,但我還是希望自己能夠做得更好,因為一天的生活就是一生的縮影,我希望在最美的年華,做最好的自己!
最近公司有一個需求,需要決議Kylin上某個Cube的JSON格式的資料,并輸出到Excel檔案中,
我們先來看看這個Cube內部都有些什么?
這里我以其中一個JSON檔案為例
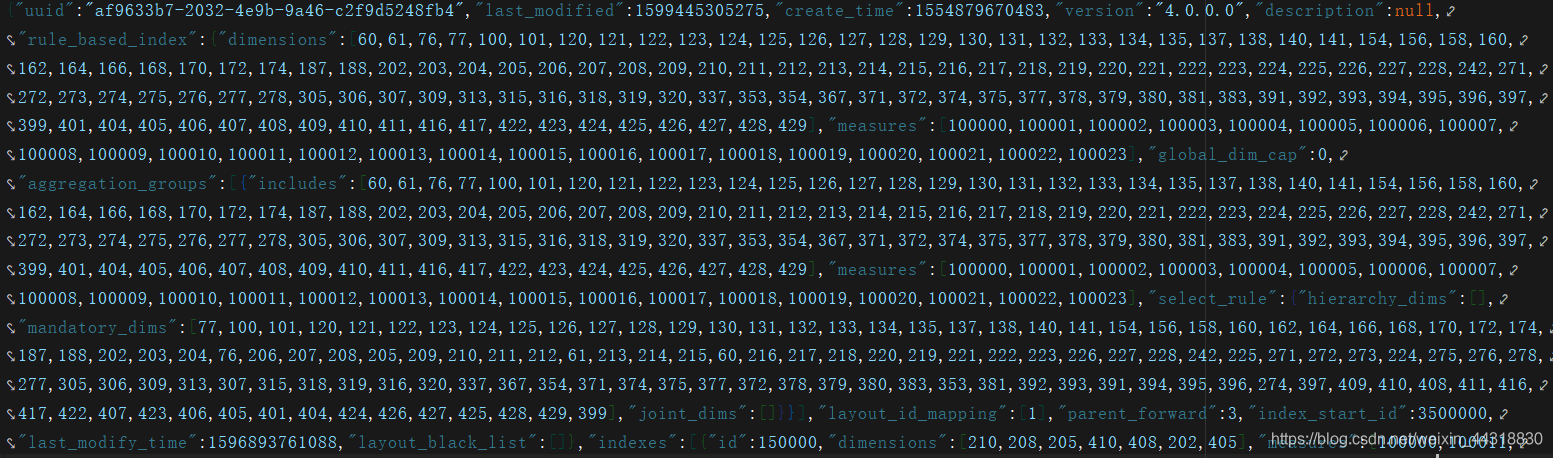
是不是JSON內部的層級關系有點混亂,沒關系,我們將里面的內容放到網頁上去決議看看,
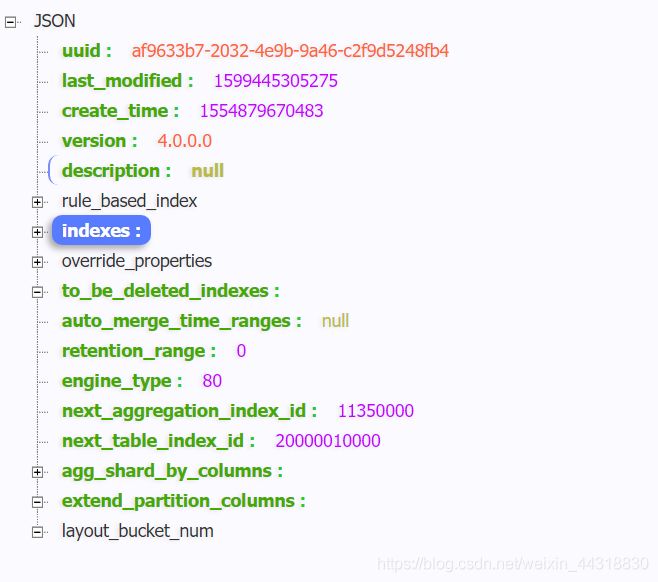
我們想要操作的是 key值為 indexes下的陣列,并對 key = layouts 下的 id 和col_order集合 拿出來,并對col_order集合中的元素做一個過濾,只獲取其中 < 100000的元素,并將其輸出到 Excel 檔案中,
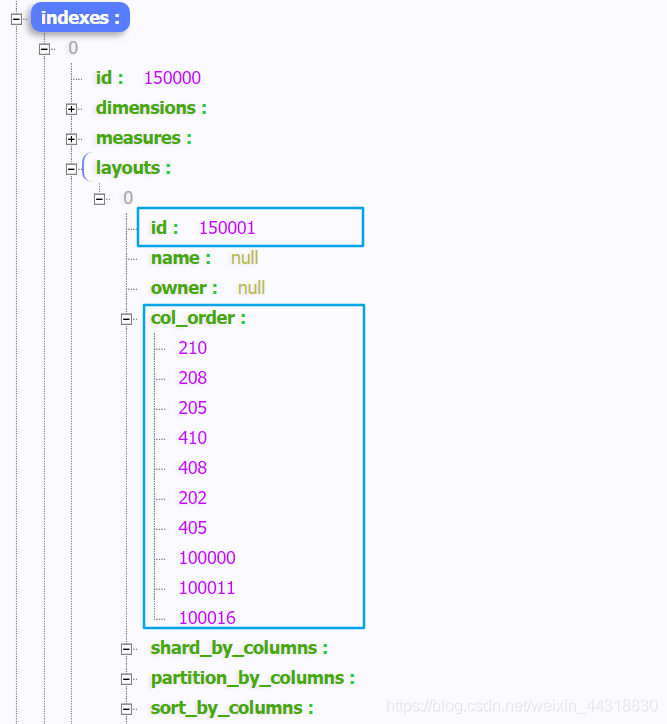
現在似乎需求已經看懂了,那我們就開始上手代碼吧,

首先我們先創建一個 Maven 專案,因為涉及到JSON的決議,我們先在Pom中匯入相關坐標:
<dependencies>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20090211</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
然后我們創建一個ParseJson類,在main方法中,我們先定義好動態引數,
// 輸入路徑
String fileIntputPath = "G:\\idea arc\\ParseJson\\src\\main\\resources\\test.json";
// 輸出路徑
String fileOutputPath = "G:\\idea arc\\ParseJson\\src\\main\\resources\\writeTest2.xlsx";
// 限制大小
int limitNumber = 100000;
因為我們需要根據 指定的輸入路徑 去本地讀取 JSON資料,所以我們還需要寫一個方法,
/**
* 讀取指定檔案路徑的內容
* @param filePath 檔案路徑
* @return 檔案內容
*/
private static String readJsonFile(String filePath) {
String jsonStr = "";
try {
File jsonFile = new File(filePath);
FileReader fileReader = new FileReader(jsonFile);
Reader reader = new InputStreamReader(new FileInputStream(jsonFile),"utf-8");
int ch = 0;
StringBuilder sb = new StringBuilder();
while ((ch = reader.read()) != -1) {
sb.append((char) ch);
}
fileReader.close();
reader.close();
jsonStr = sb.toString();
return jsonStr;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
有了讀取檔案內容的方法,我們就可以在接下來自己書寫一個決議 JSON 檔案的方法了,根據剛在網頁上展示的層級關系圖,我們不難得出寫出以下代碼:
// 呼叫方法,獲取到指定路徑的檔案內容
String str = readJsonFile(filePath);
// 呼叫 JSON 庫的內容,獲取到決議的物件
JSONObject jsonObject = JSON.parseObject(str);
// 獲取到 indexes 陣列
JSONArray jsonArray = jsonObject.getJSONArray("indexes");
for (Object o : jsonArray) {
JSONArray layouts = ((JSONObject) o).getJSONArray("layouts");
for (Object layout : layouts) {
int id = ((JSONObject) layout).getIntValue("id");
JSONArray colOrder = ((JSONObject) layout).getJSONArray("col_order");
// 定義一個 StringBuilder,用于保存每次累加的結果
StringBuilder stringBuilder = new StringBuilder();
// 定義一個欄位 size 保存原來陣列的長度
int size = colOrder.size();
// 呼叫自己寫的靜態方法,獲取到滿足需求的陣列長度
int greaterThanlakh = getGreaterThan(colOrder, size,limitNumber);
// 定義一個欄位保存每次回圈的次數
int loopCount = 0;
for (Object o1 : colOrder) {
// 每回圈一次,loopCount數值+1
loopCount ++;
// 將其轉換成 int 型別的數字
int number = Integer.parseInt(o1.toString());
if(number < 100000){
if (loopCount==greaterThanlakh){
stringBuilder.append(number);
}else{
stringBuilder.append(number).append(",");
}
}
}
}
}
}
在這個程序中,因為涉及到判斷一個陣列中,元素沒有被過濾的個數,所以又自己寫的一個功能方法,
/**
* 計算出元素中小于100000的元素個數
* @param jsonArray JSON陣列
* @param size JSON陣列的容量大小
* @param limitNumber 過濾條件
* @return 小于100000的元素個數
*/
private static int getGreaterThan (JSONArray jsonArray,int size,int limitNumber){
// 定義一個變數保存陣列中 > 100000 的元素個數
int numberCount = 0;
for (Object o : jsonArray) {
int number = Integer.parseInt(o.toString());
if (number >= limitNumber){
numberCount ++;
}
}
return size - numberCount;
}
現在我們已經獲取到了每一個id ,以及它所對應小于 100000 的 col_order陣列中的元素,那么我們就應該開始考慮一下,如何將這些值輸出到Excel檔案中,

可能熟悉Java的朋友能馬上想起來 POI
poi 組件是由Apache提供的組件包,主要職責是為我們的Java程式提供對于office檔案的相關操作,
但是像菌這樣的小白,一看到這些常用的類,還不嚇得原地昏厥,

所以說,這輩子都不可能用的,但是需求還沒完全實作,我們該怎么辦呢?
正當本菌一籌莫展之際,突然在經友人的提醒下,想起了在GitHub上一個神奇的倉庫,
https://github.com/looly/hutool
可以看到,目前該開源專案,已經斬獲了 15.3k Star,
該倉庫中包含了對大部分常用功能的代碼封裝,
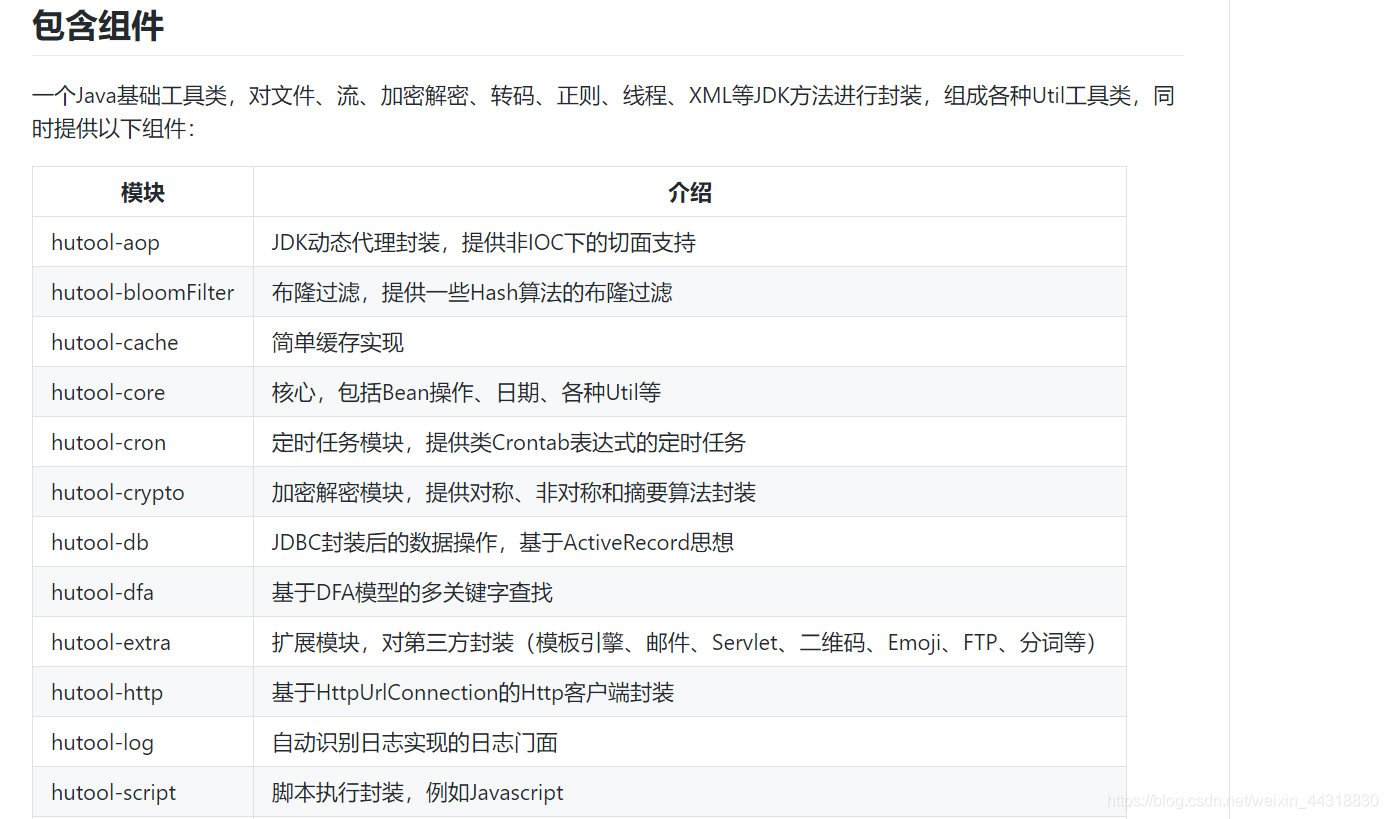
根據作者介紹,Hutool 的存在就是為了減少代碼搜索成本,避免網路上參差不齊的代碼出現導致的bug,
關于 Hutool 在 maven 專案中的使用也非常簡單,我們只需要在專案的pom.xml的dependencies中加入以下內容:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.4.1</version>
</dependency>
關于更多 Hutool 的具體使用,我們可以去參考 中文手冊
因為我們需要參考如何生成Excel,我們可以定位到這個位置

這里我將它的使用例子貼出來:
使用例子
1、將行列物件寫出到Excel
我們先定義一個嵌套的List,List的元素也是一個List,內層的一個List代表一行資料,每行都有4個單元格,最終list物件代表多行資料,
List<String> row1 = CollUtil.newArrayList("aa", "bb", "cc", "dd");
List<String> row2 = CollUtil.newArrayList("aa1", "bb1", "cc1", "dd1");
List<String> row3 = CollUtil.newArrayList("aa2", "bb2", "cc2", "dd2");
List<String> row4 = CollUtil.newArrayList("aa3", "bb3", "cc3", "dd3");
List<String> row5 = CollUtil.newArrayList("aa4", "bb4", "cc4", "dd4");
List<List<String>> rows = CollUtil.newArrayList(row1, row2, row3, row4, row5);
然后我們創建ExcelWriter物件后寫出資料:
//通過工具類創建writer
ExcelWriter writer = ExcelUtil.getWriter("d:/writeTest.xlsx");
//通過構造方法創建writer
//ExcelWriter writer = new ExcelWriter("d:/writeTest.xls");
//跳過當前行,既第一行,非必須,在此演示用
writer.passCurrentRow();
//合并單元格后的標題行,使用默認標題樣式
writer.merge(row1.size() - 1, "測驗標題");
//一次性寫出內容,強制輸出標題
writer.write(rows, true);
//關閉writer,釋放記憶體
writer.close();
運行一下程式,我們觀察案例代碼實作的效果,打開 writeTest.xlsx
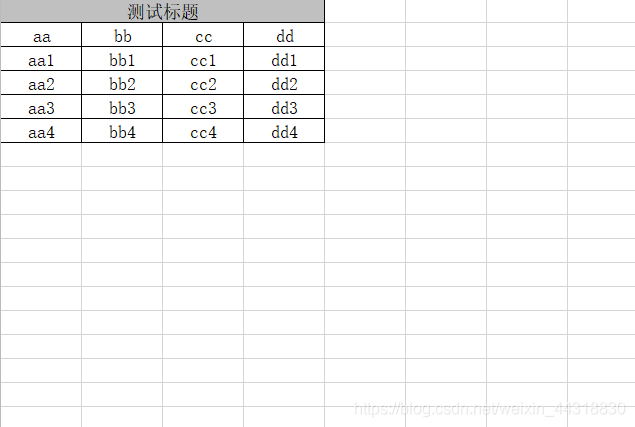
可謂是非常的 nice,我們只需要根據案例代碼所給的提示把我們之前的代碼 "完善"一下就好了,
但是還需要注意一點的就是,
Hutool-poi是針對Apache POI的封裝,因此需要用戶自行引入POI庫,Hutool默認不引入,到目前為止,Hutool-poi支持:
- Excel檔案(xls, xlsx)的讀取(ExcelReader)
- Excel檔案(xls,xlsx)的寫出(ExcelWriter)
如果我們想要輸出Excel,推薦引入poi-ooxml,這個包會自動關聯引入poi包,且可以很好的支持Office2007+的檔案格式
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
如果需要使用Sax方式讀取Excel,需要引入以下依賴:
<dependency>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
<version>${xerces.version}</version>
</dependency>
說明 hutool-4.x的poi-ooxml 版本需高于
3.17(別問我3.8版本為啥不行,因為3.17 > 3.8 ) hutool-5.x的poi-ooxml 版本需高于4.1.2xercesImpl版本高于2.12.0
引入后即可使用Hutool的方法操作Office檔案了,下面貼出正式的代碼:
package com.czxy;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.poi.excel.ExcelUtil;
import cn.hutool.poi.excel.ExcelWriter;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.io.*;
import java.util.List;
/**
* @Author: Alice菌
* @Date: 2020/9/7 18:27
* @Description:
*/
public class ParseJson {
public static void main(String[] args) throws Exception {
// 輸入路徑
//String fileIntputPath = "G:\\idea arc\\ParseJson\\src\\main\\resources\\test.json";
String fileIntputPath = args[0];
// 輸出路徑
//String fileOutputPath = "G:\\idea arc\\ParseJson\\src\\main\\resources\\writeTest2.xlsx";
String fileOutputPath = args[1];
// 限制大小
//int limitNumber = 100000;
int limitNumber = Integer.parseInt(args[2]);
strWriteToJSONObject(fileIntputPath,fileOutputPath,limitNumber);
}
/**
* 讀取指定檔案路徑的內容
* @param filePath 檔案路徑
* @return 檔案內容
*/
private static String readJsonFile(String filePath) {
String jsonStr = "";
try {
File jsonFile = new File(filePath);
FileReader fileReader = new FileReader(jsonFile);
Reader reader = new InputStreamReader(new FileInputStream(jsonFile),"utf-8");
int ch = 0;
StringBuilder sb = new StringBuilder();
while ((ch = reader.read()) != -1) {
sb.append((char) ch);
}
fileReader.close();
reader.close();
jsonStr = sb.toString();
return jsonStr;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
private static void strWriteToJSONObject(String filePath,String fileOutPut,int limitNumber) throws Exception {
// 呼叫方法,獲取到指定路徑的檔案內容
String str = readJsonFile(filePath);
// 呼叫 JSON 庫的內容,獲取到決議的物件
JSONObject jsonObject = JSON.parseObject(str);
// 獲取到 indexes 陣列
JSONArray jsonArray = jsonObject.getJSONArray("indexes");
//如果需要輸出到 txt 文本中,則使用下面這種方式
//FileWriter fw = new FileWriter(fileOutPut, true);
//BufferedWriter bw = new BufferedWriter(fw);
//初始化一個集合,用于存盤所有需要輸出到Excel的列
List<List<String>> rows = CollUtil.newArrayList();
for (Object o : jsonArray) {
JSONArray layouts = ((JSONObject) o).getJSONArray("layouts");
for (Object layout : layouts) {
int id = ((JSONObject) layout).getIntValue("id");
JSONArray colOrder = ((JSONObject) layout).getJSONArray("col_order");
// 定義一個 StringBuilder,用于保存每次累加的結果
StringBuilder stringBuilder = new StringBuilder();
// 定義一個欄位 size 保存原來陣列的長度
int size = colOrder.size();
// 呼叫自己寫的靜態方法,獲取到滿足需求的陣列長度
int greaterThanlakh = getGreaterThan(colOrder, size,limitNumber);
// 定義一個欄位保存每次回圈的次數
int loopCount = 0;
for (Object o1 : colOrder) {
// 每回圈一次,loopCount數值+1
loopCount ++;
// 將其轉換成 int 型別的數字
int number = Integer.parseInt(o1.toString());
if(number < 100000){
if (loopCount==greaterThanlakh){
stringBuilder.append(number);
}else{
stringBuilder.append(number).append(",");
}
}
}
List<String> row = CollUtil.newArrayList(id+"",stringBuilder.toString());
rows.add(row);
}
}
OutToExcel(rows,fileOutPut);
}
/**
* 計算出元素中小于100000的元素個數
* @param jsonArray JSON陣列
* @param size JSON陣列的容量大小
* @param limitNumber 過濾條件
* @return 小于100000的元素個數
*/
private static int getGreaterThan (JSONArray jsonArray,int size,int limitNumber){
// 定義一個變數保存陣列中 > 100000 的元素個數
int numberCount = 0;
for (Object o : jsonArray) {
int number = Integer.parseInt(o.toString());
if (number >= limitNumber){
numberCount ++;
}
}
return size - numberCount;
}
public static void OutToExcel(List<List<String>> rows,String fileOutPut){
for (List<String> row : rows) {
System.out.println(row);
}
System.out.println("fileOutPath:"+fileOutPut);
//通過工具類創建writer
ExcelWriter writer = ExcelUtil.getWriter(fileOutPut);
//通過構造方法創建writer
//ExcelWriter writer = new ExcelWriter("d:/writeTest.xls");
//跳過當前行,既第一行,非必須,在此演示用
//writer.passCurrentRow();
//合并單元格后的標題行,使用默認標題樣式
//writer.merge(row1.size() - 1, "測驗標題");
//一次性寫出內容,強制輸出標題
writer.write(rows, true);
//關閉writer,釋放記憶體
writer.close();
}
}
細心的朋友們可能已經發現,博主已經將 main 方法中的變數替換成了引數,主要的目的就是可以將代碼打包到Linux上運行,就像這樣,
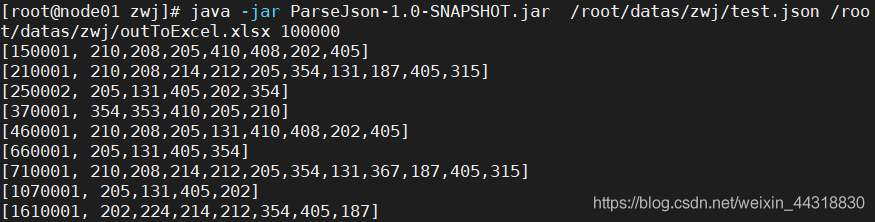
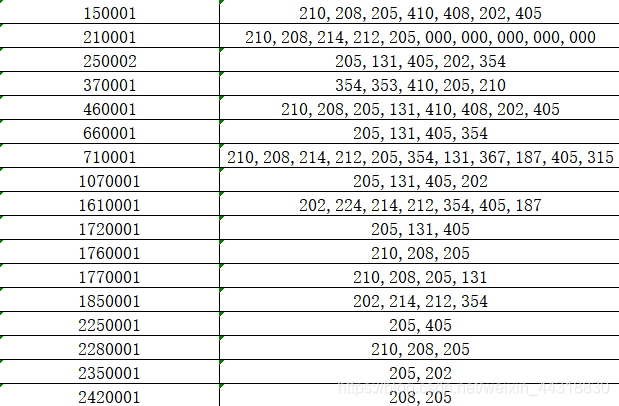
這里我們打開 outToExcel.xlsx 檔案,看下效果,
小結
本篇博客,博主主要為大家介紹了如何通過Json去決議Cube中的資料,并將需要的資料輸出到Excel當中,菌著重為大家安利了一款非常實用的工具庫——hutool,希望大家都能在不斷探索的程序中,發現一些新鮮好玩的東西,
如果以上程序中出現了任何的紕漏錯誤,煩請大佬們指正😅
受益的朋友或對大資料技術感興趣的伙伴記得點贊關注支持一波🙏
希望我們都能在學習的道路上越走越遠😉

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/11718.html
標籤:其他
上一篇:Element-ui Cascader級聯選擇器在IE11上滾動條怎么去掉?
下一篇:注解及反射的使用