python獲取網頁狀態碼時,執行如下代碼,網頁可以打開
def getStatusCode(url):
urllib3.disable_warnings()
r = requests.get(url,verify=False)
return r.status_code
driver.get("https://xxxxxxxxxx/")
sleep(3)
print(getStatusCode(driver.current_url))
狀態碼回傳403,網上找了資料添加了header,如下:
def getStatusCode(url):
urllib3.disable_warnings()
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
r = requests.get(url,verify=False,headers = header)
return r.status_code
driver.get("https://xxxxxxx/")
sleep(3)
print(getStatusCode(driver.current_url))
狀態碼為200了,請教一下各位,這是為什么,我這邊要獲取很多網頁的狀態碼,總不能一個一個的獲取header吧
uj5u.com熱心網友回復:
header肯定是要帶的啊,帶個通用型的headeruj5u.com熱心網友回復:
403 forbidden,這是一個主動拒絕,你被發現了。headers 只是一個爬蟲基礎,不需要一個一個復制,除了有比較特殊的驗證外的,一般get請求都不會有非常多的限制,只需要 user-agent就可以了。有太多的方法構建一個headers可以給你看一下后臺中一個沒有headers的爬蟲和正常瀏覽器的區別,隨便就能看出你的身份,你猜我會不會給你過
這是爬蟲
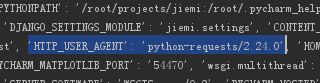
這個是正常瀏覽器

uj5u.com熱心網友回復:
你要是爬百度還得在header里加個Acceptuj5u.com熱心網友回復:
因為你沒有把爬蟲偽裝成普通用戶爬取,最好就是把你要爬取的網頁的headers給寫完全,這樣就不會出現問題,因為每個網頁說需要的東西不一樣。轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/11776.html