import requests
from lxml import etree
import re
# 1.確定url地址
url = 'https://maoyan.com/news?showTab=3&offset=16'
# 1.2設定ua
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# 2.請求
html_str = requests.get(url,headers=ua).text
# 3.刪選(xpath,正則運算式)
dom = etree.HTML(html_str)
movie_names = dom.xpath('//h4[@class="video-name one-line"]/a[@href]/text()')
movie_urls = dom.xpath('//h4[@class="video-name one-line"]/a[@href]/@href')
print(movie_names)
print(movie_urls)
for movie_name,movie_url in zip(movie_names,movie_urls):
if '《' in movie_name:
movie_name = movie_name.replace('《',' ')
movie_id_string = requests.get(movie_url).text
mp4_url = re.search('source src="https://bbs.csdn.net/topics/(.*)" type',movie_id_string).group(1)
print(mp4_url)
mp4 = requests.get(mp4_url).content
# 4.保存
with open('./movieResult/%s.mp4'%movie_name,'wb') as file:
file.write(mp4)
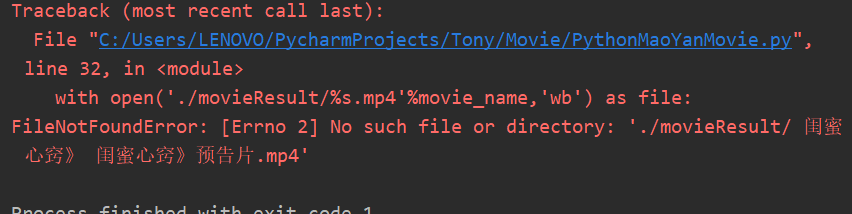
uj5u.com熱心網友回復:
結果中沒看到有?啊,不懂你的意思uj5u.com熱心網友回復:
看了下,你這個是./movieResult/%s.mp4'%movie_name的目錄不存在,改成r'c:\%s.mp4'%movie_name 測驗可行uj5u.com熱心網友回復:
是因為你打開了這個檔案導致python沒有權限,所以會冒這個錯uj5u.com熱心網友回復:
改成c:\……沒有權限,我改到D盤就可以了,謝謝uj5u.com熱心網友回復:
感謝感謝轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/11781.html
上一篇:Python初學者編程習題問題