題目描述:
給定一個字串,請你找出其中不含有重復字符的 最長子串 的長度,
示例 1:
輸入: "abcabcbb"
輸出: 3
解釋: 因為無重復字符的最長子串是
"abc",所以其長度為 3,
示例 2:
輸入: "bbbbb"
輸出: 1
解釋: 因為無重復字符的最長子串是
"b",所以其長度為 1,
示例 3:
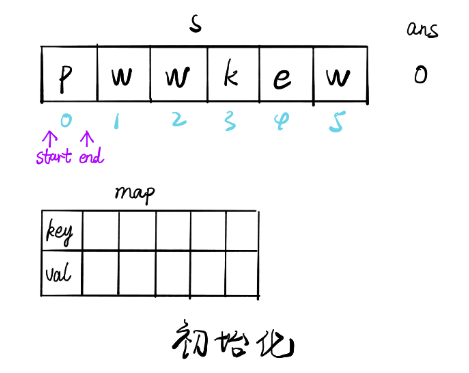
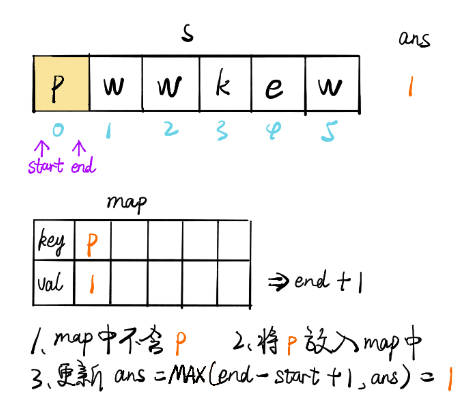
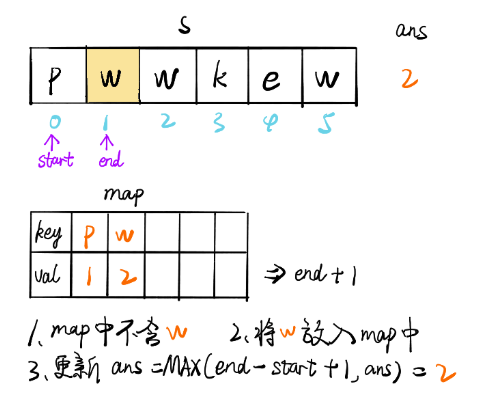
輸入: "pwwkew"
輸出: 3
解釋: 因為無重復字符的最長子串是 "wke",所以其長度為 3,
請注意,你的答案必須是 子串 的長度,"pwke" 是一個子序列,不是子串,子串:串中任意個連續的字符組成的子序列稱為該串的子串
方法一:暴力法
題目更新后由于時間限制,會出現 TLE(超時),
思路
逐個檢查所有的子字串,看它是否不含有重復的字符,
關鍵點
假設我們有一個函式 boolean allUnique(String substring) ,如果子字串中的字符都是唯一的,它會回傳 true,否則會回傳 false, 我們可以遍歷給定字串 s 的所有可能的子字串并呼叫函式 allUnique,
如果事實證明回傳值為 true,那么我們將會更新無重復字符子串的最大長度的答案,
現在讓我們填補缺少的部分:
1.為了列舉給定字串的所有子字串,我們需要列舉它們開始和結束的索引,
2.要檢查一個字串是否有重復字符,我們可以使用集合,我們遍歷字串中的所有字符,并將它們逐個放入set中,
在放置一個字符之前,我們檢查該集合是否已經包含它,如果包含,我們會回傳false,回圈結束后,我們回傳true,
代碼
class Solution {
public int lengthOfLongestSubstring(String s) {
//字串長度
int n = s.length();
//值為最長子串的長度
int ans = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j <= n; j++) {
if (allUnique(s, i, j)) {
//更新ans的值,取最大
ans = Math.max(ans, j - i);
}
}
}
return ans;
}
/**
* 求最長無重復字符的最長子串
*
* @param s 字串長度
* @param start 字串當前開始位置
* @param end 字串當前結束位置
* @return ture或false,決定要不要進入上面的if回圈,end也很重要,當遍歷完當前end的值之后,都沒有重復的,return true;
*/
public boolean allUnique(String s, int start, int end) {
Set<Character> set = new HashSet<>();
for (int i = start; i < end; i++) {
//第i個字符在字串中內容
Character ch = s.charAt(i);
//Set集合是否包含字串ch
if (set.contains(ch)) {
return false;
}
//如果不包含,就往set集合里添加ch字串
set.add(ch);
}
return true;
}
}
復雜度:
時間復雜度:O (n3)
方法二:滑動視窗
什么是滑動視窗?
其實就是一個佇列,比如例題中的abcabcbb,進入這個佇列(視窗)為abc 滿足題目要求,當再進入a,佇列變成了abca,這時候不滿足要求,所以,我們要移動這個佇列!
如何移動?
我們只要把佇列的左邊的元素移出就行了,直到滿足題目要求!一直維持這樣的佇列,找出佇列出現最長的長度時候,求出解!
當然滑動視窗的尺寸可以是固定也可以是動態的
思路
通過使用 HashSet 作為滑動視窗,我們可以用 O(1) 的時間來完成對字符是否在當前的子字串中的檢查,
回到我們的問題,我們使用HashSet將字符存盤在當前視窗[i,j)( 最初 = i )中,然后我們向右側滑動索引j,如果它不在HashSet中,我們會繼續滑動,直到si]已經存在于HashSet中,此時,我們找到的沒有重復字符的最長子字串將會以索引 i 開頭,如果我們對所有的i這樣做,就可以得到答案,
代碼
public class Solution {
public int lengthOfLongestSubstring(String s) {
//字串長度
int n = s.length();
Set<Character> set = new HashSet<>();
//定義ans為最長子串的長度,如果j的值沒有在set出現過end++,知道出現start++,滑動視窗
int ans = 0, start = 0, end = 0;
//如果start和end<n就一直遍歷,直到start和end都小于n
while (start < n && end < n) {
//判斷Set集合是否包含end下標對應的字串
if (!set.contains(s.charAt(end))){
//如果set里沒有,則把j下標對應的字串存進set集合, end執行完本句后+1
set.add(s.charAt(end++));
//因為end++,所有滑動視窗向后移動,并更新ans的值
ans = Math.max(ans, end - start);
}
else {
//移除Set集合start下標對應的字串,start++,最后全部移除
set.remove(s.charAt(start++));
}
}
return ans;
}
}
復雜度
時間復雜度:O(2n)=O(n),在最糟糕的情況下,每個字符將被i和j訪問兩次,
空間復雜度:O(min(m,n)),與之前的方法相同,滑動視窗法需要O(k)的空間,其中k表示Set的大小,而Set的大小取決于字串n的大小以及字符集/字母m的大小,
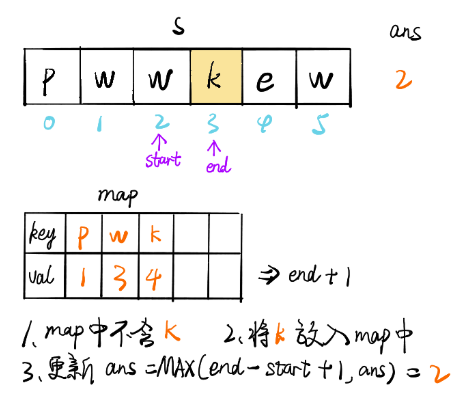
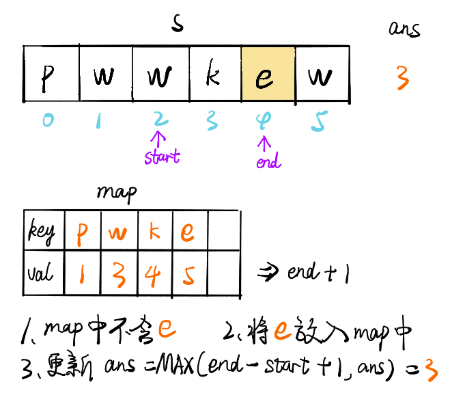
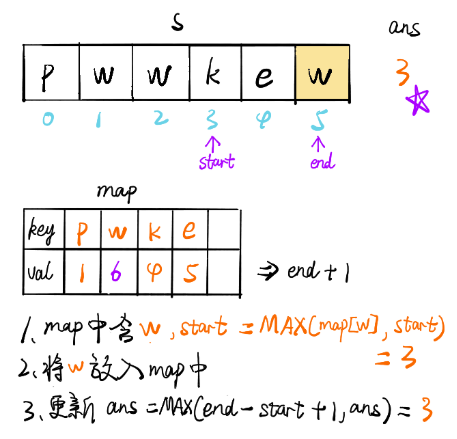
方法三:優化的滑動視窗
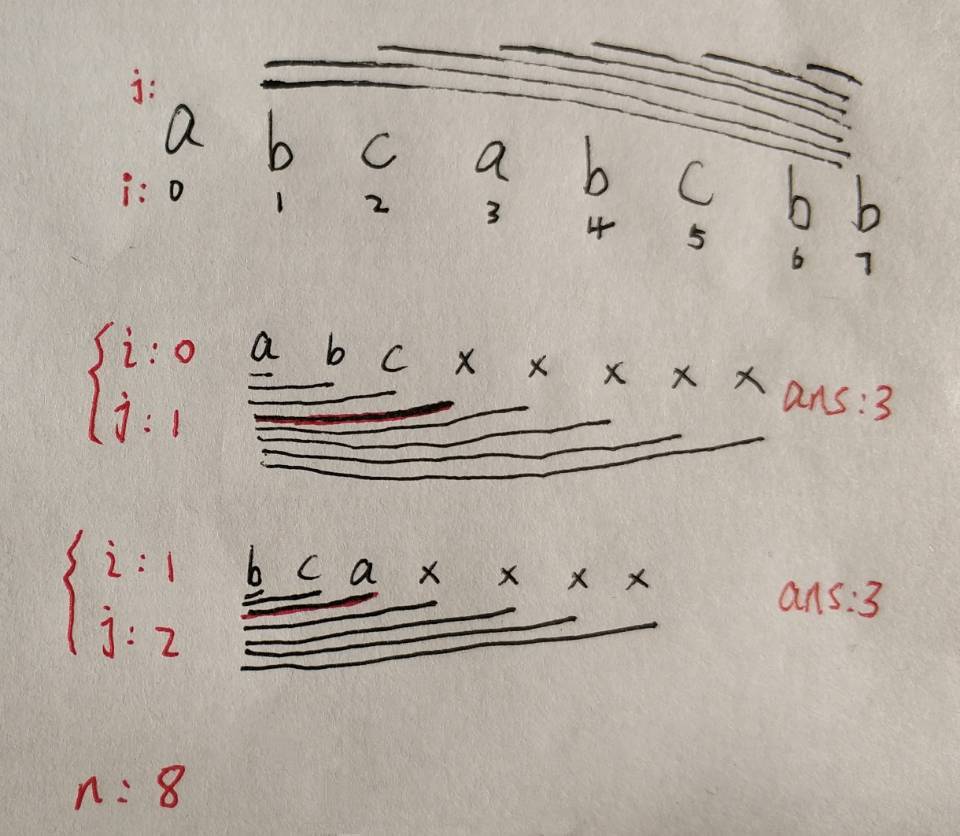
上述的方法最多需要執行2n個步驟,事實上,它可以被進一步優化為僅需要n個步驟,我們可以定義字符到索引的映射,而不是使用集合來判斷一個字符是否存在,當我們找到重復的字符時,我們可以立即跳過該視窗,
也就是說,如果s[j]在[i,j)范圍內有與j重復的字符,我們不需要逐漸增加i,我們可以直接跳過[i,j門范圍內的所有元素,并將i變為j+1,
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
//創建map視窗
Map<Character, Integer> map = new HashMap<>();
//定義不重復子串的開始位置為 start,結束位置為 end
for (int end = 0, start = 0; end < n; end++) {
if (map.containsKey(s.charAt(end))) {
// 隨著 end 不斷遍歷向后,會遇到與 [start, end] 區間內字符相同的情況,
// map.get(s.charAt(end)此時將字符作為 key 值,獲取其 value 值// 修改start值為之前重復字符位置之后的位置
// 此時[start,end]區間內不存在重復字符
// start更新時進行比較是因為map里key放的是所有遍歷過的字符,而不僅僅是視窗里的字符,
// 所以現在的字符如果跟視窗外的字符(也就是以前的字符)重復了,start應該保持原樣
例如 abcdefcma 到第二個c的時候 i變成了 3,但到第二個 a的時候如果取第一個a的位置,而不是a和當前i的最大值, i就變成了1,左側索引左移
start = Math.max(map.get(s.charAt(end)), start);
}
//比對當前無重復欄位長度和儲存的長度,選最大值并替換
//end-start+1是因為此時i,end索引仍處于不重復的位置,end還沒有向后移動,取的[start,end]長度,+1因為索引從1開始
//無論是否更新 start,都會更新其 map 資料結構和結果 ans,
ans = Math.max(ans, end - start + 1);
// 將當前字符為key,value 值為字符位置 +1
// 加 1 表示從字符位置后一個才開始不重復,不然就把最后一個數給替換了
map.put(s.charAt(end), end + 1);
}
return ans;
}
}
復雜度
時間復雜度:O(n),索引j將會迭代n次,
空間復雜度(HashMap):O(min(m,n)),與之前的方法相同,
空間復雜度(Table):O(m),m是字符集的大小,
畫解
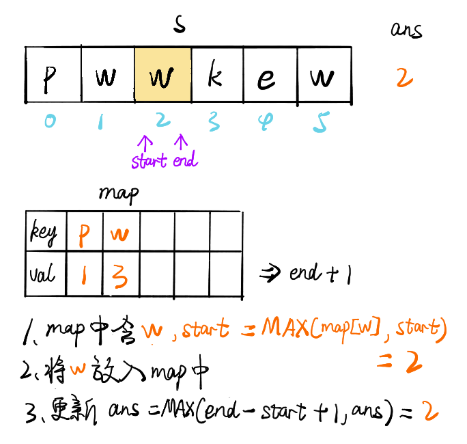
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/117897.html
標籤:其他
上一篇:怎么買華為服務