前言
大家好,這里是《齊姐聊演算法》系列之 LRU 問題,
在講這道題之前,我想先聊聊「技術面試究竟是在考什么」這個問題,
技術面試究竟在考什么
在人人都知道刷題的今天,面試官也都知道大家會刷題準備面試,代碼大家都會寫,那面試為什么還在考這些題?那為什么有些人代碼寫出來了還掛了?
大家知道美國的大廠面試 80%是在考演算法,這其實是最近 5-10 年以谷歌、雅虎為首才興起的;國內大廠對于演算法的考察雖然沒有這么狂熱,但也越來越重視了,
那么演算法面試真的只是在考演算法嗎?顯然不是,本質上考的是思考問題的方式,分析、解決問題的能力,以及和同事溝通交流的能力,看你能否主動推進去解決問題,
答題思路
套路就是:
clarify 問題 分析思路、時空復雜度、分析哪里可以優化、如何優化 寫代碼 run test cases
雖說是套路,但何嘗不是一個高效的作業方式?
那拿到一個問題,首先應該是去 clarify 這個問題,因為作業就是如此,不像在刷題網站做題什么都給你定義好了,面試官通常都不會一次性給你所有條件,而是需要你思考之后去問他,那通過這個環節,面試官就知道了你遇到問題是怎么去思考的,你考慮的是否全面,怎么去和別人溝通的,今后和你一起作業的狀態是怎樣的,
就像我們平時作業時,需要和 product manager 不斷的 clarify 需求,特別是沒定義清楚的部分,反反復復的討論,也是磨刀不誤砍柴工,那這個程序,在我司可能就要 1-2 周,不會很著急的就開始,否則努力錯了方向就是南轅北轍,得不償失,那么面試時也是一樣,代碼都寫完了面試官說這不是我想問的,那時候已經沒時間了,買單的是我們自己,
第二點分析思路就是重中之重了,也是本文的核心,會以 LRU Cache 這到經典題為例,展示我是如何思考、分析的,
第三點寫代碼,沒什么好說的,終究是需要落到實處的,
第四點跑測驗,很多同學可能會忘,所以如果你能主動提出 run test cases,過幾個例子檢驗一下,是很好的,
一來是給自己一個修正的機會,因為有很多 bug 是你跑兩個例子就能發現的,那即使有點 bug 你沒發現,只要你做完了這一步,面試官當場也沒發現的話,那面試結束后面試官雖然會拍照留念,但也不會閑的無聊再自己打到電腦上跑的; 二來是展示你的這種意識,跑測驗的意識,這種意識是很重要的,
有些人說每道題我都做出來了,為什么還是掛了?那照著這四點對比一下,看看是哪個環節出了問題,
常考不衰的原因
另外這道題為什么各大公司都喜歡考呢?
一是因為它能夠多方面、多維度的考察 candidate:這道題考察的是基本功,考對資料結構理解使用,考能不能寫出 readable 的代碼,一場 45 分鐘-60 分鐘的面試,如何摸清楚 candidate 的真實水平,也是不容易的啊,
二是因為這道題可難可易,可以簡單到像 Leetcode 上那樣把 API 什么的都已經定義好了,也可以難到把 System Design 的內容都包含進來,聊一下 Redis 中的近似 LRU 演算法,
所以 follow up 就可以無限的深入下去,如果面試官想問的你都能回答的頭頭是道,那 strong hire 自然跑不掉,那有些同學只會到第一層或者第二層,面試是優中選優的程序,其他同學會的比你多,溝通交流能力又好,自然就是別人拿 offer 了,
那今天就以這道題為例,在這里淺談一下我的思考程序,為大家拋磚引玉,歡迎在留言區分享你的想法,
LRU Cache
LRU 是什么
LRU = Least Recently Used 最近最少使用
它是一種快取逐出策略 cache eviction policies[1]
LRU 演算法是假設最近最少使用的那些資訊,將來被使用的概率也不大,所以在容量有限的情況下,就可以把這些不常用的資訊踢出去,騰地方,
比如有熱點新聞時,所有人都在搜索這個資訊,那剛被一個人搜過的資訊接下來被其他人搜索的概率也大,就比前兩天的一個過時的新聞被搜索的概率大,所以我們把很久沒有用過的資訊踢出去,也就是 Least Recently Used 的資訊被踢出去,
舉個例子:我們的記憶體容量為 5,現在有 1-5 五個數,

我們現在想加入一個新的數:6
可是容量已經滿了,所以需要踢出去一個,
那按照什么規則踢出去,就有了這個快取逐出策略,比如:
FIFO (First In First Out)這個就是普通的先進先出,LFU (Least Frequently Used)這個是計算每個資訊的訪問次數,踢走訪問次數最少的那個;如果訪問次數一樣,就踢走好久沒用過的那個,這個演算法其實很高效,但是耗資源,所以一般不用,LRU (Least Recently Used)這是目前最常用了,
LRU 的規則是把很長時間沒有用過的踢出去,那它的隱含假設就是,認為最近用到的資訊以后用到的概率會更大,
那我們這個例子中就是把最老的 1 踢出去,變成:

不斷迭代...
Cache 是什么?
簡單理解就是:把一些可以重復使用的資訊存起來,以便之后需要時可以快速拿到,
那至于它存在哪里就不一定了,最常見的是存在記憶體里,也就是 memory cache,但也可以不存在記憶體里,
使用場景就更多了,比如 Spring 中有 @Cacheable 等支持 Cache 的一系列注解,上個月我在作業中就用到了這個 annotation,當然是我司包裝過的,大大減少了 call 某服務器的次數,解決了一個性能上的問題,
再比如,在進行資料庫查詢的時候,不想每次請求都去 call 資料庫,那我們就在記憶體里存一些常用的資料,來提高訪問性能,
這種設計思想其實是遵循了著名的“二八定律”,在讀寫資料庫時,每次的 I/O 程序消耗很大,但其實 80% 的 request 都是在用那 20% 的資料,所以把這 20% 的資料放在記憶體里,就能夠極大的提高整體的效率,
總之,Cache 的目的是存一些可以復用的資訊,方便將來的請求快速獲得,
LRU Cache
那我們知道了 LRU,了解了 Cache,合起來就是 LRU Cache 了:
當 Cache 儲存滿了的時候,使用 LRU 演算法把老家伙清理出去,
思路詳解
說了這么多,Let's get to the meat of the problem!
這道經典題大家都知道是要用 HashMap + Doubly Linked List,或者說用 Java 中現成的 LinkedHashMap,但是,為什么?你是怎么想到用這兩個資料結構的?面試的時候不講清楚這個,不說清楚思考程序,代碼寫對了也沒用,
和在作業中的設計思路類似,沒有人會告訴我們要用什么資料結構,一般的思路是先想有哪些 operations,然后根據這些操作,再去看哪些資料結構合適,
分析 Operations
那我們來分析一下對于這個 LRU Cache 需要有哪些操作:
首先最基本的操作就是能夠從里面讀資訊,不然之后快速獲取是咋來的; 那還得能加入新的資訊,新的資訊進來就是 most recently used 了; 在加新資訊之前,還得看看有沒有空位,如果沒有空間了,得先把老的踢出去,那就需要能夠找到那個老家伙并且洗掉它; 那如果加入的新資訊是快取里已經有的,那意思就是 key 已經有了,要更新 value,那就只需要調整一下這條資訊的 priority,它已經從那次被寵幸晉升為貴妃了~
找尋資料結構
那第一個操作很明顯,我們需要一個能夠快速查找的資料結構,非 HashMap 莫屬,還不了解 HashMap 原理和設計規則的在公眾號內發訊息「HashMap」,送你一篇爆款文章;
可是后面的操作 HashMap 就不頂用了呀,,,
來來來,我們來數一遍基本的資料結構:
Array, LinkedList, Stack, Queue, Tree, BST, Heap, HashMap
在做這種資料結構的題目時,就這樣把所有的資料結構列出來,一個個來分析,有時候不是因為這個資料結構不行,而是因為其他的資料結構更好,
怎么叫更好?忘了我們的衡量標準嘛!時空復雜度,趕緊復習遞回那篇文章,公眾號內回復「遞回」即可獲得,
那我們的分析如下:
Array, Stack, Queue 這三種本質上都是 Array 實作的(當然 Stack, Queue 也可以用 LinkedList 來實作,,),一會插入新的,一會洗掉老的,一會調整下順序,array 不是不能做,就是得 O(n) 啊,用不起,
BST 同理,時間復雜度是 O(logn).
Heap 即便可以,也是 O(logn).
LinkedList,有點可以哦,按照從老到新的順序,排排站,洗掉、插入、移動,都可以是 O(1) 的誒!但是洗掉時我還需要一個 previous pointer 才能刪掉,所以我需要一個 Doubly LinkedList.
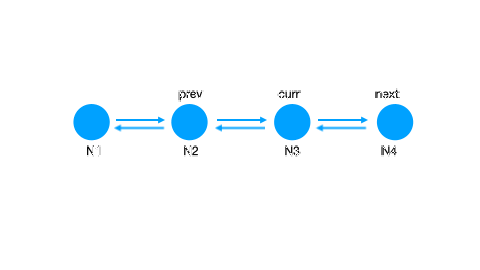
那么我們的資料結構敲定為:
HashMap + Doubly LinkedList
定義清楚資料結構的內容
選好了資料結構之后,還需要定義清楚每個資料結構具體存盤的是是什么,這兩個資料結構是如何聯系的,這才是核心問題,
我們先想個場景,在搜索引擎里,你輸入問題 Questions,谷歌給你回傳答案 Answer,
那我們就先假設這兩個資料結構存的都是 <Q, A>,然后來看這些操作,如果都很順利,那沒問題,如果有問題,我們再調整,
那現在我們的 HashMap 和 LinkedList 長這樣:
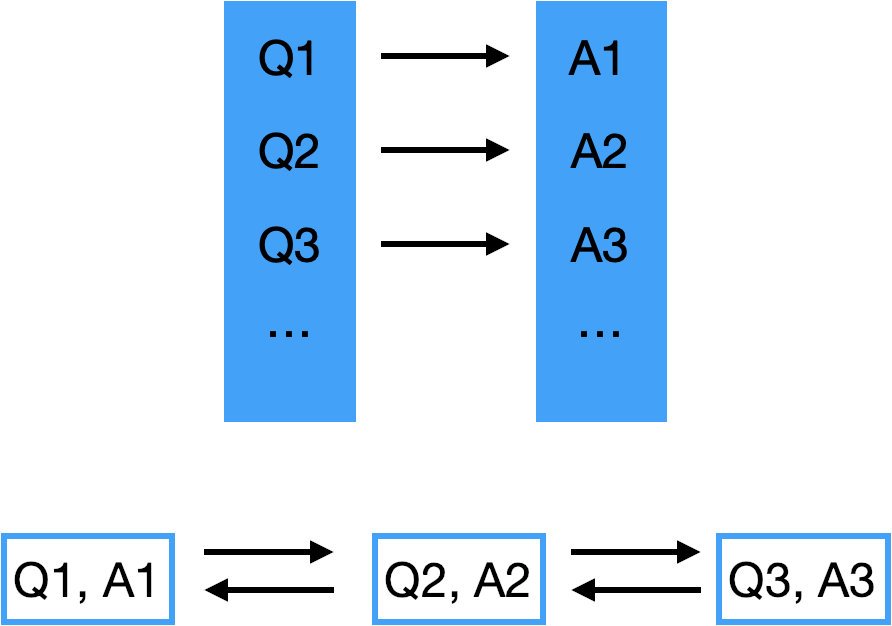
然后我們回頭來看這四種操作:
操作 1,沒問題,直接從 HashMap 里讀取 Answer 即可,O(1);
操作 2,新加入一組 Q&A,兩個資料結構都得加,那先要判斷一下當前的快取里有沒有這個 Q,那我們用 HashMap 判斷,
如果沒有這個 Q,加進來,都沒問題; 如果已經有這個 Q,HashMap 這里要更新一下 Answer,然后我們還要把 LinkedList 的那個 node 移動到最后或者最前,因為它變成了最新被使用的了嘛,
可是,怎么找 LinkedList 的這個 node 呢?一個個 traverse 去找并不是我們想要的,因為要 O(n) 的時間嘛,我們想用 O(1) 的時間操作,
那也就是說這樣記錄是不行的,還需要記錄 LinkedList 中每個 ListNode 的位置,這就是本題關鍵所在,
那自然是在 HashMap 里記錄 ListNode 的位置這個資訊了,也就是存一下每個 ListNode 的 reference,
想想其實也是,HashMap 里沒有必要記錄 Answer,Answer 只需要在 LinkedList 里記錄就可以了,
之后我們更新、移動每個 node 時,它的 reference 也不需要變,所以 HashMap 也不用改動,動的只是 previous, next pointer.
那再一想,其實 LinkedList 里也沒必要記錄 Question,反正 HashMap 里有,
這兩個資料結構是相互配合來用的,不需要記錄一樣的資訊,
更新后的資料結構如下:
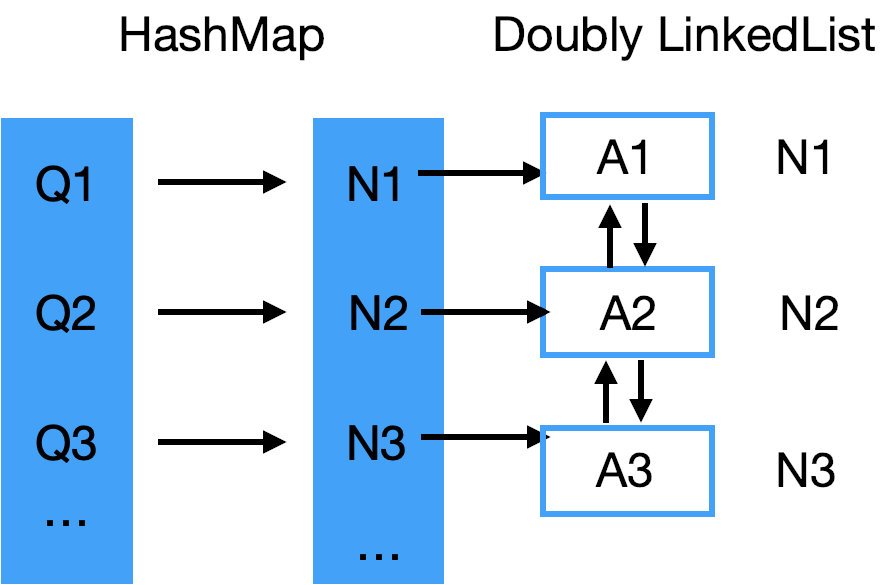
這樣,我們才分析出來用什么資料結構,每個資料結構里存的是什么,物理意義是什么,
那其實,Java 中的 LinkedHashMap 已經做了很好的實作,但是,即便面試時可以使用它,也是這么一步步推匯出來的,而不是一看到題目就知道用它,那一看就是背答案啊,
有同學問我,如果面試官問我這題做沒做過,該怎么回答?
答:實話實說,
真誠在面試、作業中都是很重要的,所以實話實說就好了,但如果面試官沒問,就不必說,,,
其實面試官是不 care 你做沒做過這道題的,因為大家都刷題,基本都做過,問這個問題沒有意義,只要你能把問題分析清楚,講清楚邏輯,做過了又怎樣?很多做過了題的人是講不清楚的,,,
總結
那我們再總結一下那四點操作:
第一個操作,也就是 get() API,沒啥好說的;
二三四,是 put() API,有點小麻煩:
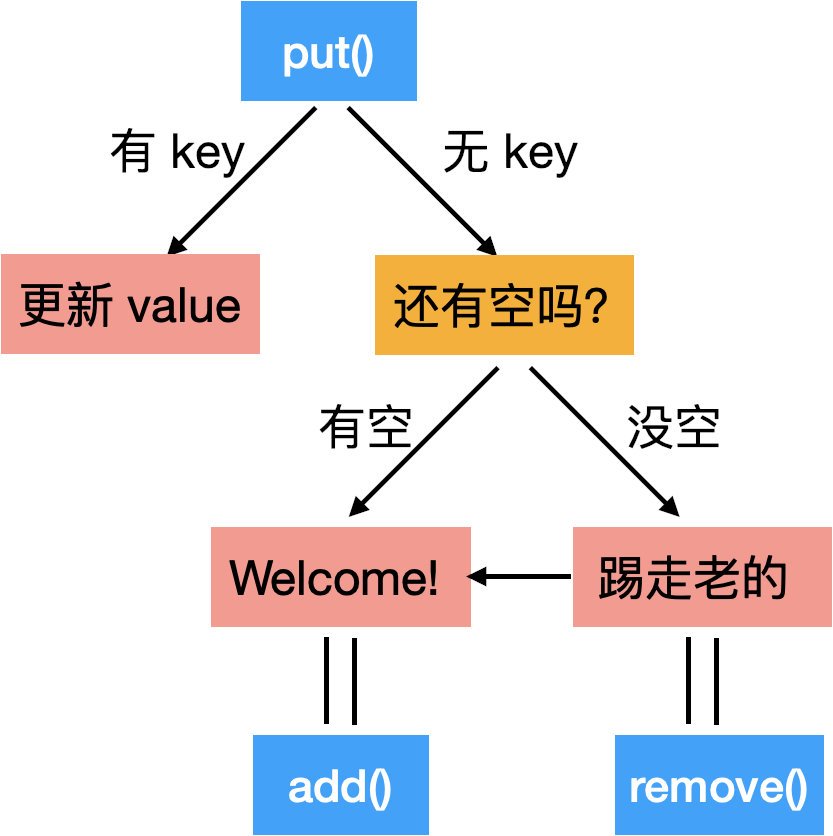
畫圖的時候邊講邊寫,每一步都從 high level 到 detail 再到代碼,把代碼模塊化,
比如“Welcome”是要把這個新的資訊加入到 HashMap 和 LinkedList 里,那我會用一個單獨的 add() method 來寫這塊內容,那在下面的代碼里我取名為 appendHead(),更精準; “踢走老的”這里我也是用一個單獨的 remove() method 來寫的,
當年我把這圖畫出來,面試官就沒讓我寫代碼了,直接下一題了...
那如果面試官還讓你寫,就寫唄,,,
class LRUCache {
// HashMap: <key = Question, value = ListNode>
// LinkedList: <Answer>
public static class Node {
int key;
int val;
Node next;
Node prev;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
Map<Integer, Node> map = new HashMap<>();
private Node head;
private Node tail;
private int cap;
public LRUCache(int capacity) {
cap = capacity;
}
public int get(int key) {
Node node = map.get(key);
if(node == null) {
return -1;
} else {
int res = node.val;
remove(node);
appendHead(node);
return res;
}
}
public void put(int key, int value) {
// 先 check 有沒有這個 key
Node node = map.get(key);
if(node != null) {
node.val = value;
// 把這個node放在最前面去
remove(node);
appendHead(node);
} else {
node = new Node(key, value);
if(map.size() < cap) {
appendHead(node);
map.put(key, node);
} else {
// 踢走老的
map.remove(tail.key);
remove(tail);
appendHead(node);
map.put(key, node);
}
}
}
private void appendHead(Node node) {
if(head == null) {
head = tail = node;
} else {
node.next = head;
head.prev = node;
head = node;
}
}
private void remove(Node node) {
// 這里我寫的可能不是最 elegant 的,但是是很 readable 的
if(head == tail) {
head = tail = null;
} else {
if(head == node) {
head = head.next;
node.next = null;
} else if (tail == node) {
tail = tail.prev;
tail.next = null;
node.prev = null;
} else {
node.prev.next = node.next;
node.next.prev = node.prev;
node.prev = null;
node.next = null;
}
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
總結
?
那再回到面試上來,為什么很多面試是以演算法考察為主的?這樣的面試道理何在?演算法題面試真的能衡量一個人的作業能力嗎?(當然了,對于有些作業經驗的人還會考察系統設計方面的內容,)
這是我一直在思考的問題,作業之后愈發覺得,這樣的面試真的是有效的,
因為我們需要的是能夠去解決未知的問題的能力,知識可能會被遺忘,但是思考問題的方式方法是一直跟隨著我們的,也是我們需要不斷提高的,那么在基本功扎實的前提下,有正確的方法和思路做指引,nothing is impossible.

如果你喜歡這篇文章,記得給我點贊留言哦~你們的支持和認可,就是我創作的最大動力,我們下篇文章見!
我是小齊,紐約程式媛,終生學習者,每天晚上 9 點,云自習室里不見不散!
更多干貨文章見我的 Github: https://github.com/xiaoqi6666/NYCSDE
?
?
參考資料
Cache replacement policies: https://en.wikipedia.org/wiki/Cache_replacement_policies
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/117919.html
標籤:其他
上一篇:GadgetWide Tool
下一篇:人臉特征點標記